重磅 | PaddlePaddle之后,百度开源深度学习硬件基准DeepBench
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重磅 | PaddlePaddle之后,百度开源深度学习硬件基准DeepBench相关的知识,希望对你有一定的参考价值。
选自Baidu Research
机器之心编译
参与:李亚洲、老红、吴攀
谷歌、微软、Facebook 等传统的人工智能技术巨头之外,百度近来也加入到了技术开源的浪潮之中,继 PaddlePaddle 之后,百度又宣布开源了一项深度学习基准 DeepBench。
1.DeepBench
DeepBench 是一个开源的基准工具,用来测量深度神经网络训练中的基础操作的表现。使用神经网络库,这些操作在不同的硬件平台被执行。如今测试基准工具 DeepBench 在 github 上已经开源。
DeepBench 的主要目标是 benchmark 对深度学习在不同硬件平台上而言很重要的运算。尽管深度学习背后的基础计算已经被很好的理解了,但在实践中它们被使用的方式惊人的不同。例如,矩阵相乘运算基于被相乘矩阵的大小和 Kernel 实现,可能是 compute-bound,也可能是 bandwidth-bound, 或者 occupancy-bound。因为每个深度学习模型带着不同的参数使用这些运算,面向深度学习硬件和软件的优化空间还是很大的,也是不足的。
DeepBench 试图解决这个问题,「在被用于训练深度神经网络时,在基础运算上哪种硬件提供最好的表现?」我们在低层次上详细说明了这些运算,建立深度学习处理器的团队很适合在硬件模拟中使用 DeepBench。
1.1 DeepBench 适合用在哪里?
深度学习生态系统包含不同的模块。我们想要强调 DeepBench 适合用于该生态系统的哪部分。在下面的图表中,描述了关于深度学习的软件和硬件组件。在最顶端是百度的 PaddlePaddle、Theano、TensorFlow、Torch 等这样的深度学习框架,这些框架使得我们能够建立深度学习模型。它们包含层(layer)这样的基础建筑模块,可通过不同的方式连接从而创造模型。为了训练这些模型,框架使用英伟达的 cuDNN 和英特尔的 MKL 这样的基础神经网络库。这些库执行矩阵相乘这样的用来训练深度学习模型的运算。最后,在英伟达 GPU 或英特尔 Xeon Phi 处理器这样的硬件上训练这些模型。
DeepBench 使用神经网络库 benchmark 基础运算在不同硬件上的表现。它对建立应用的深度学习框架或深度学习模型没用。我们不能测量使用 DeepBench 训练整个模型所需要的时间。为不同应用建立的模型的表现特性彼此间差别很大。因此,我们要 benchmark 涉及到深度学习模型训练中的潜在运算。benchmark 这些运算有助于提高硬件供应商的 意识,也有助于软件开发者了解深度学习训练的瓶颈。
1.2 方法论
DeepBench 包括一系列的基础操作(稠密矩阵相乘、卷积和通信)以及一些循环层类型。在开源的代码中有一个 Excel 表格描述了所有的大小。
前向和后向的运算都会被测试。该基准的第一代版本将注重在 32 位浮点算法中的训练表现。未来的版本可能扩展到注重推理工作负载(inference workloads)和更低精度的算法。
即使存在更快的独立库或公开了更快的结果,我们也将使用供应商提供的库。大部分用户将默认使用供应商提供的库,而且这种库更代表用户的体验。
1.3. Entry
我们正在释放在 4 个硬件平台上的结果:英伟达的 TitanX、M40、TitanX Pacal 和英特尔的 Knights Landing。硬件供应商或独立用户可运行大致的基准,并将结果输入到表格中。
2. 运算的类型
2.1 稠密矩阵相乘
稠密矩阵相乘存在于大部分深度神经网络中。它们被用于执行全连接层和 vanilla RNN,以及为其他类型的循环层建立基石。有时它们也被用作快速执行新类层(在这里面自定义的代码不存在)的方式。
当执行 GEMM 运算 A * B = C 时,A 和 B 中的一个或两个都能被随意的换位。描述一个矩阵问题的常用术语是 triple(M,N,K), 该术语描述了矩阵的大小。
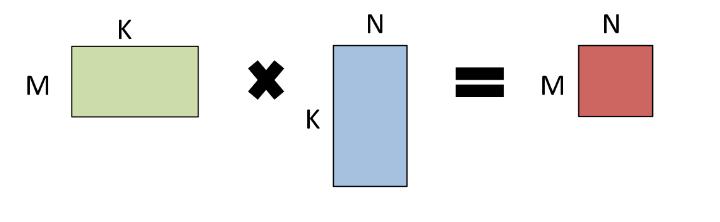
2.2 卷积
卷积构成了网络中在图像和视频操作上的绝大多数的浮点计算,也构成了语音和自然语言模型网络中的主要部分,从模型表现角度来看,它可能也是唯一最重要的层。
卷积有 4 或 5 维的输入和输出,为这些维提供了大量可能的排序。在改基准的第一代版本,我们只考虑了在 NCHW format 中的表现,即数据是在图像、特征映射、行和列中展示的。
有很多计算卷积的技术对不同大小的过滤器和图像来说都是很好的选择,包括:direct approaches、基于矩阵相乘的方法、基于 FFT 的方法以及基于 Winograd 的方法。在该基准的第一代版本,我们没考虑不同方法的准确率,因为普遍共识是 32 位浮点计算对它们每个方法而言都是足够准确的。
2.3 循环层(recurrent layers)
循环层总是由之前的运算与一元(unary)或二元(binary)运算这样的简单计算结合而成的——这些简单运算不是计算密集型的,通常只需占据总体运算时间的一小部分。然而,在循环层中,GEMM 和卷积运算相对较小,所以这些更小运算的成本变得有极大影响。如果开始计算就有一个很高的固定成本,那上述内容就尤其准确。也可以为循环矩阵使用额外的存储格式,因为转换成一个新的存储格式的成本可被分摊到循环计算的许多步骤上。如果能做到这一点,那么从一个自定格式转换或转换成一个自定义格式的时间应该被包含在整体时间之内。
在一个时间步骤内和跨序列的时间步骤上,这些因素会导致很多优化的可能性,因此测定运算的原始性能并不一定能够代表整个循环层的的性能。在这样的基准上,我们仅关注一个循环层,即使还存在其它更多的优化机会(如果考虑它们的层叠(stack))。
输入的计算不应该被包含在用于循环层计算的时间内,因为其可以作为一个大的乘法计算,然后被实际的循环运算所消化。所以在 h_t = g(Wx_t + Uh_t-1) 中,Wx_t 对于所有 t 的计算时间不应被包含在循环层的时间内。
反向计算应该在考虑权重而非输入的基础上计算更新(update)。所有的循环工作完成以计算权重更新,所以同时考虑输入来计算更新会掩盖我们想要测定的内容。
vanilla RNN 的非线性应该是一个 ReLU。LSTM 的内在非线性应该是标准运算——门(gate)是 S 型函数,激活(activation)是双曲正切函数。LSTM 不应该有窥视孔连接(peephole connections)。
2.4. All-Reduce
现在的神经网络通常在多 GPU 或多系统与 GPU 并行的情况下训练,这主要有两个技术分类:同步和异步。同步技术依赖于保持参数和所有模型实例的同步,它通常要保证在优化步骤执行前,所有模型实例有一些梯度的备份。最简单运行这些计算结果的 Message Passing Interface (MPI) 被称为 All-Reduce。有很多可以执行 All-Reduce 的方法,我们可以依靠数字的排列、数据的大小和网络的拓扑结构来执行。这种基准测试的方式在执行时是没有限制的,所以它的结果是不确定的。异步的方法则非常的不同,在这个版本的基准测试中我们不会测试这些方法。
为了评估 All-Reduce,我们使用了下面的库和基准:NVIDIA's NCCL Ohio State University (OSU) Benchmarks
NCCL 库包括一组标准的通信程序。这个库支持在单个节点任意数量的 GPU 运行,并且它能在单个或多个进程中运行,但 NCC 程序不支持多节点下的 All-Reduce。为了能够在多节点下评估 All-Reduce,我们使用了 OSU 下的 benchmark。我们在三个执行过程中 (NCCL single process, NCCL MPI, OpenMPI) 报告了最短的延迟。
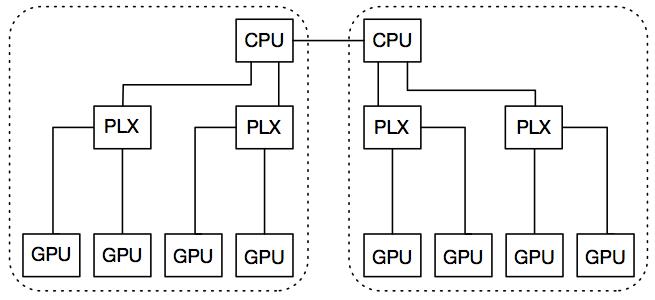
Nvidia 8 GPU 系统的拓扑结构
每个节点都有两个 GPU 插槽,而每个插槽都有一个 PCIe root complex。每个节点都有两个 GPU 插槽,而每个插槽都有一个 PCIe root complex。每一套插槽都有两个 PLX 开关,它们通过 16 个 PCIe v3 的 lanes 各自连接到 CPU 插槽中。每个 PLX 插槽有两个 GPU,所有的 GPU 通过 16 个 PCIe v3 的 lanes 进行同时通信。这两个 CPU 插槽通过 Intel 的 QPI 连接,而跨界点的互联则是通过 InfiniBand FDR。下图显示了一个原理图的节点,在图中,所有的设备均由同一个虚线框内的 PCL root 连接。
英特尔 Xeon Phi 和 Omni-Path 系统的拓扑结构
MPI_AllReduce 时间是在英特尔 Xeon Phi 7250 处理器上测定的——在英特尔内部的带有 fat-tree 拓扑的 Intel® Omni-Path Architecture (Intel® OPA) series 100 fabric 结构的 Endeavor 集群上,使用了 Intel MPI 5.1.3.181。
3. 结果
在这部分,我们记录了一些运算的表现。下面这些结果是随机挑选的,它们只是为了演示几个应用的运算表现。下面的结果仅包括了特定操作和参数下最快的处理器的时间和浮点运算速度。完整的结果可以在库里查看。
这些软件库(例如 cuDNN 和 OpenMPI)和一些硬件系统的细节同样在 github 的库里适用。如有问题,请随时和我们联系。
一旦更多硬件平台的结果被发现可以适用,它们都会被加到库里面来。我们也欢迎所有硬件厂商为此贡献结果。
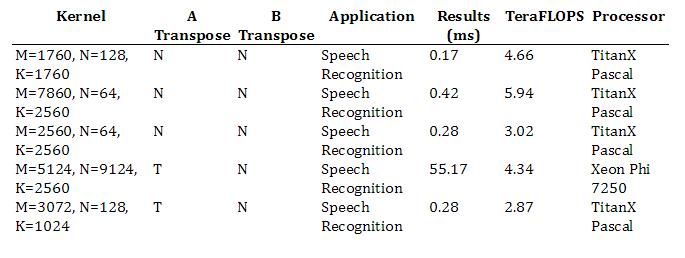
3.1. GEMM Results
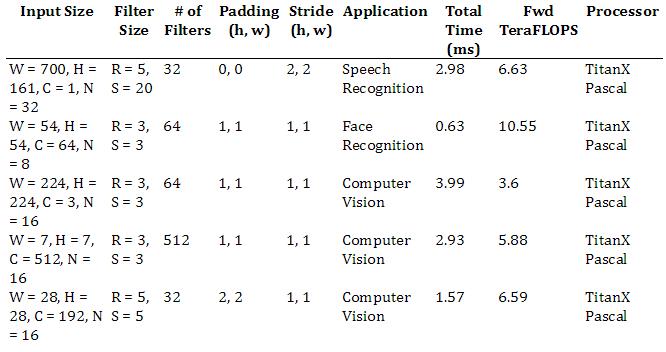
3.2. Convolution Results
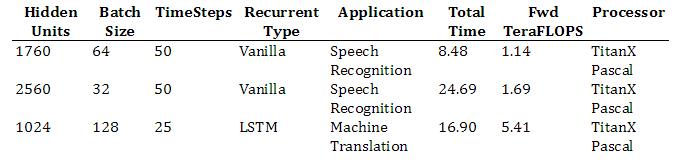
3.3. Recurrent Ops Results
周期性的操作内核仅能在 NVIDIA 的硬件上运行,而周期性的标准检查程序也将很快可以在 Intel 的硬件上运行。在今年十月份我们将会得到这些结果。
3.4. All-Reduce Results
因为我们仅仅只有一个 Pascal GPU,所有我们不能在 NVIDIA's TitanX Pascal GPU 运行 All-Reduce benchmark。
我们欢迎来自各界的贡献,具体体现在如下两个方面:
1. 深度学习研究者/工程师:如果你是一个正在从事新的深度学习应用的研究者或者工程师,你可能会在训练你的模型的时候有不同的运算结果和工作量。而我们对于那些能够逆向影响你模型表现(速度)的底层运算结果非常感兴趣。请将这些运算结果和工作量反馈给我们。
2. 硬件供应商:我们也非常愿意接受来自其他硬件硬件供应商的贡献。我们对 benchmark results 的接受态度十分开放,无论你是大公司还是基于深度学习训练的小型创业公司,都请将你们的 benchmark results 反馈给我们!
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@almosthuman.cn
投稿或寻求报道:editor@almosthuman.cn
广告&商务合作:bd@almosthuman.cn
以上是关于重磅 | PaddlePaddle之后,百度开源深度学习硬件基准DeepBench的主要内容,如果未能解决你的问题,请参考以下文章
重磅|百度宣布PaddlePaddle和Kubernetes 兼容:开发者可便捷做大规模深度学习训练
重磅百度开源分布式深度学习平台,挑战TensorFlow (教程)
百度飞桨重磅推出端侧推理引擎Paddle Lite 支持更多硬件平台
专访百度 PaddlePaddle 开源平台负责人王益:国产深度学习平台是如何帮助开发者快速开发 AI 产品的?