百度深度学习开源框架PaddlePaddle发布新版API,简化深度学习编程
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百度深度学习开源框架PaddlePaddle发布新版API,简化深度学习编程相关的知识,希望对你有一定的参考价值。
新智元推荐
新智元启动新一轮大招聘:COO、执行总编、主编、高级编译、主笔、运营总监、客户经理、咨询总监、行政助理等 9 大岗位全面开放。
简历投递:jobs@aiera.com.cn HR 微信:13552313024
新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。加盟新智元,与人工智能业界领袖携手改变世界。
PaddlePaddle是百度于2016年9月开源的一款分布式深度学习平台,为百度内部多项产品提供深度学习算法支持。为了使PaddlePaddle更加易用,我们已经做了一系列的工作,包括使用Kubernetes集群管理系统来进行部署与运行。
今天,我们很高兴地发布新API的Alpha版0.10.0rc1,以及《深度学习入门教程》。目前教程包括八个示例程序,均可以在Jupyter Notebook上运行,即用户可以通过网页浏览文档并运行程序。
使用新API,PaddlePaddle的程序代码将大幅缩短。下图对比展示了一个卷积神经网络在旧API(图左半边)和新API(图右半边)的效果。
新API能达到如此显著的代码简化效果,有以下三个关键的设计思想。
我们的设计原则是:让用户在神经网络中表达和解决实际的问题,并用更加灵活的方式来描述新的深度学习算法。因此,新模型包含以下几部分概念:
模型(model)是一个或多个拓扑结构的组合。
拓扑结构(topology)是一系列层的表达式。
层(layer)可以是任何类型的计算函数,包括损失(cost)函数。
有些层有梯度参数,有些层没有,大多数损失函数没有参数。
在一些拓扑结构中,层与层之间共享参数。
对于多个拓扑结构间存在参数共享的情况,PaddlePaddle能自动找出并创建这些参数。
下面,通过两个例子来展示我们的一些设计思想。
假设我们要学习一个文本词向量f,训练样本是“对查询Q来说,搜索结果A比B更准确”,任务目标是:sim(f(A), f(Q)) > sim(f(B), f(Q)),也就是f(A)和f(Q)的相似度,大于f(B)和f(Q)的相似度。为了学习f,我们构建了一个三分支的网络结构:

这里的模型实际上是x -> f,但我们需要重复三次来学习f,以下伪代码展示了如何构建这样一个模型:

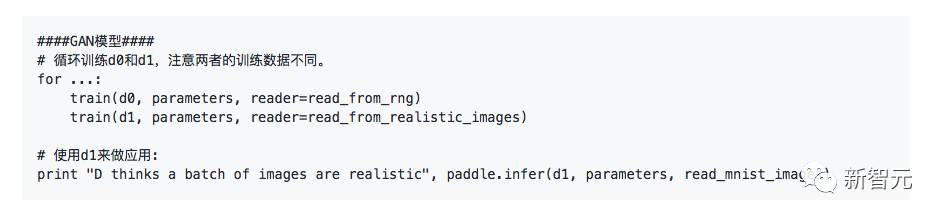
假设GAN模型包含两个拓扑结构d0和d1,d0和d1之间共享了参数。因此在训练过程中,更新一个拓扑结构的参数时可能需要同时更新另一个。如果使用旧API,用户将不得不访问非常底层的API,这部分API接口通常相对晦涩,且文档不全。而使用新API,GAN模型仅需几十行即可,伪代码如下:

在工业届的AI应用中,数据加载部分通常需要大量的源代码。为了减轻用户的这部分工作量,新API的数据接口设计包含几个部分:
reader:从本地、网络、分布式文件系统等读取数据,也可随机生成数据,并返回一个或多个数据项。reader creator:一个返回reader的函数。reader decorator:装饰器,可组合一个或多个reader。batch reader:与reader类似,但可批量返回一个或多个数据项。
下面展示了一个随机生成数据,并返回单个数据项的reader creator函数:

新API还有助于数据加载操作的复用。例如,我们定义两个reader,分别是impressions()和clicks(),前者用于读取搜索引擎的日志流数据,后者用于读取点击流数据;然后,我们可以通过预定义的reader decorator缓存并组合这些数据,再对合并后的数据进行乱序操作:

如果我们希望只使用数据集中的前5000个样本来进行小型实验,代码如下:

此外,我们发布了paddle.datasets包,为教程中的八个示例程序都提供了预定义好的数据加载接口。第一次调用时会自动下载公共数据集并进行预处理,之后的调用则会从本地缓存中自动读取。
PaddlePaddle是一个诞生在工业界的系统,从一开始就强调支持分布式训练。但在编写分布式程序时,旧API暴露了很多用户不需要知道的细节。另外,PaddlePaddle的C++代码中的训练过程是一个for循环结构,不能跑在交互式的Jupyter Notebook上。因此,我们发布了新API,提供了一些更高层次的接口,如train(训练接口)、test(测试接口)和infer(应用接口)。这些新API既能在本地运行,将来也支持在Kubernets集群上运行分布式作业。
以上述的三分支模型和GAN模型为例,下面展示train和infer的使用思路。

我们会持续优化新API,上述设计思想的具体实现会在0.10.0版中完成,同时也欢迎您的评论、反馈和代码贡献!
1.PaddlePaddle’s New API Simplifies Deep Learning Programs.
2.PaddlePaddle Design Doc.
3.PaddlePaddle Python Data Reader Design Doc.
这本书脱胎于PaddlePaddle Team的线上教材《深度学习入门》,包括新手入门、识别数字、图像分类、词向量、情感分析、语义角色标注、机器翻译、个性化推荐等内容。
以下是《深度学习入门》一书的目录:
在线阅读:http://book.paddlepaddle.org/index.html
以上是关于百度深度学习开源框架PaddlePaddle发布新版API,简化深度学习编程的主要内容,如果未能解决你的问题,请参考以下文章