分布式事务DevOps
Posted 基本功修炼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务DevOps相关的知识,希望对你有一定的参考价值。
分布式事务
订单与选课需求分析
订单支付流程学成在线的课程分为免费和收费两种。对于收费课程,用户需提交订单并完成支付方可在线学习。
提交订单及支付流程如下:
1、用户提交订单需要先登录系统
2、提交订单,订单信息保存到订单数据库
3、订单支付,调用微信支付接口完成支付
4、完成支付,微信支付系统通知学成在线支付结果
5、学成在线接收到支付结果通知,更新支付结果
提交订单流程:
1、用户进入课程详情页面
2、点击“立即购买”,打开订单确认信息

3、点击“确认无误,提交订单”
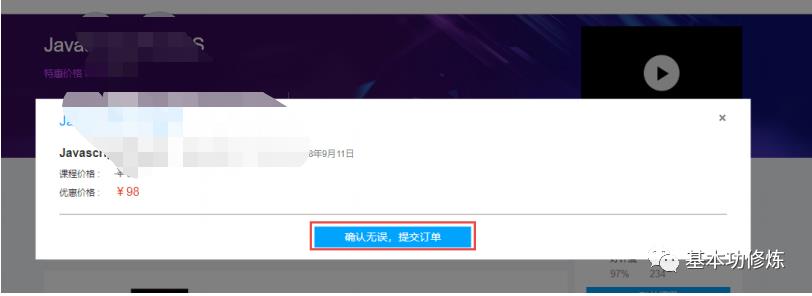
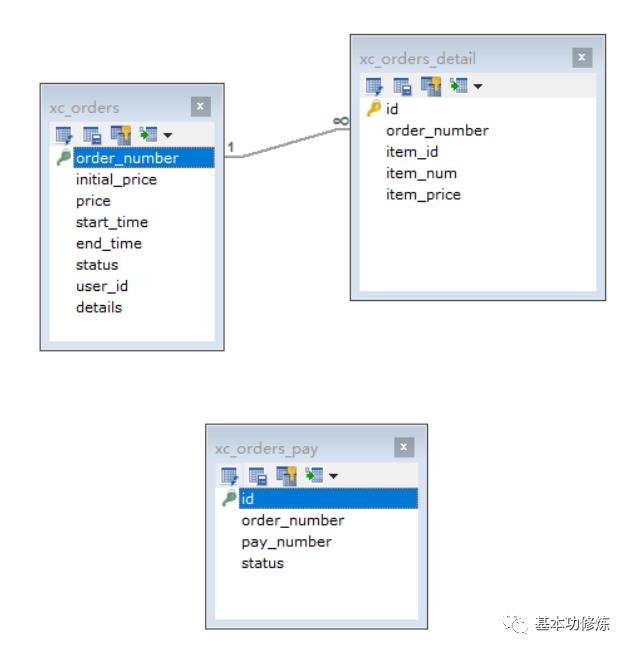
订单提交成功,向订单数据库的xc_orders订单表保存一条记录,向xc_orders_detail订单明细表保存一条或多条记录,向订单支付表插入一条记录。
4、订单提交成功自动进入订单支付页面
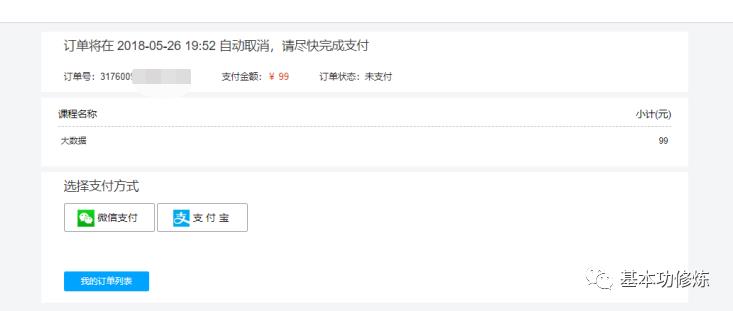
5、点击“微信支付”打开二维码
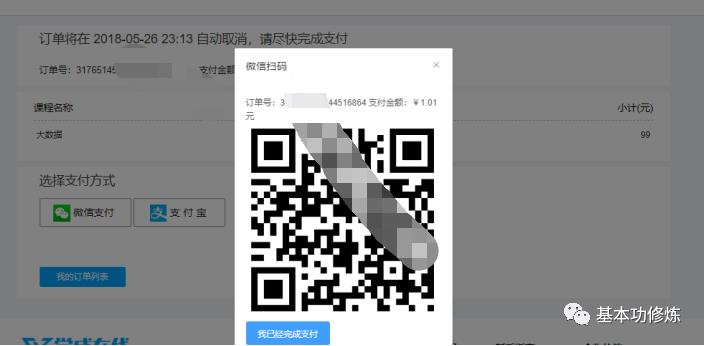
6、用手机扫码支付,支付完成,点击“完成支付”
支付完成,收到微信支付系统的支付完成通知或请求微信查询支付已完成,更新学成在线订单支付表中的支付状态字段
自动选课需求
支付成功即完成订单,订单完成之后系统需自动添加选课
下图是微信支付、学成在线订单服务、学成在线学习服务交互图:
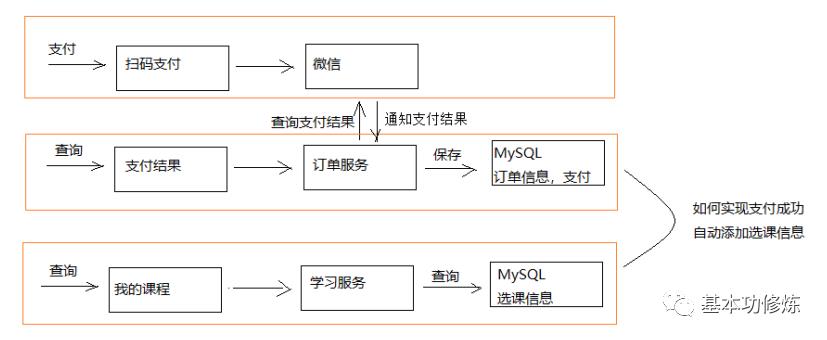
1、用户支付完成,微信支付系统会主动通知学成在线支付结果,学成在线也可主动请求微信支付查询订单的支付结果。最终得到支付结果后将订单支付结果保存到订单数据库中
2、订单支付完成系统自动向选课表添加学生选课记录
3、选课记录添加完成学习即可在线开始学
分布式事务
问题描述根据上边的自动选课的需求,分析如下:
用户支付完成会将支付状态及订单状态保存在订单数据库中,由订单服务去维护订单数据库。而学生选课信息在学习中心数据库,由学习服务去维护学习中心数据库的信息。下图是系统结构图:
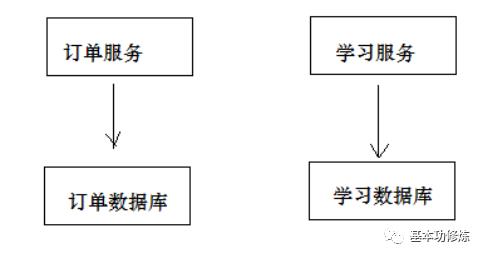
如何实现两个分布式服务(订单服务、学习服务)共同完成一件事即订单支付成功自动添加学生选课的需求,这里的关键是如何保证两个分布式服务的事务的一致性。
尝试解决上边的需求,在订单服务中远程调用选课接口,伪代码如下:

上边的逻辑说明:
1、更新支付表状态为本地数据库操作
2、远程调用选课接口为网络远程调用请求
3、为保存事务上边两步操作由spring控制事务,当遇到Exception异常则回滚本地数据库操作
问题如下:
1、如果更新支付表失败则抛出异常,不再执行远程调用,此设想没有问题
2、如果更新支付表成功,网络远程调用超时会拉长本地数据库事务时间,影响数据库性能
3、如果更新支付表成功,远程调用添加选课成功(选课数据库commit成功),最后更新支付表commit失败,此时出现操作不一致
上边的问题涉及到分布式事务控制
什么是分布式事务
1、什么是分布式系统?
部署在不同结点上的系统通过网络交互来完成协同工作的系统。比如:充值加积分的业务,用户在充值系统向自己的账户充钱,在积分系统中自己积分相应的增加。充值系统和积分系统是两个不同的系统,一次充值加积分的业务就需要这两个系统协同工作来完成。
2、什么是事务?
事务是指由一组操作组成的一个工作单元,这个工作单元具有原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)。
原子性:执行单元中的操作要么全部执行成功,要么全部失败。如果有一部分成功一部分失败那么成功的操作要全部回滚到执行前的状态。
一致性:执行一次事务会使用数据从一个正确的状态转换到另一个正确的状态,执行前后数据都是完整的。
隔离性:在该事务执行的过程中,任何数据的改变只存在于该事务之中,对外界没有影响,事务与事务之间是完全的隔离的。只有事务提交后其它事务才可以查询到最新的数据。
持久性:事务完成后对数据的改变会永久性的存储起来,即使发生断电宕机数据依然在。
3、什么是本地事务?
本地事务就是用关系数据库来控制事务,关系数据库通常都具有ACID特性,传统的单体应用通常会将数据全部存储在一个数据库中,会借助关系数据库来完成事务控制。
4、什么是分布式事务?
在分布式系统中一次操作由多个系统协同完成,这种一次事务操作涉及多个系统通过网络协同完成的过程称为分布式事务。这里强调的是多个系统通过网络协同完成一个事务的过程,并不强调多个系统访问了不同的数据库,即使多个系统访问的是同一个数据库也是分布式事务,如下图:
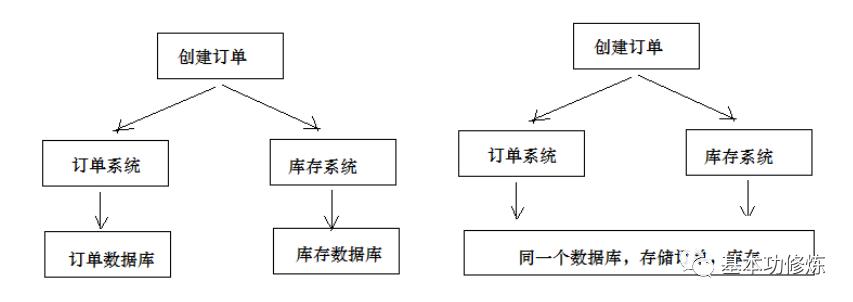
另外一种分布式事务的表现是,一个应用程序使用了多个数据源连接了不同的数据库,当一次事务需要操作多个数据源,此时也属于分布式事务,当系统作了数据库拆分后会出现此种情况
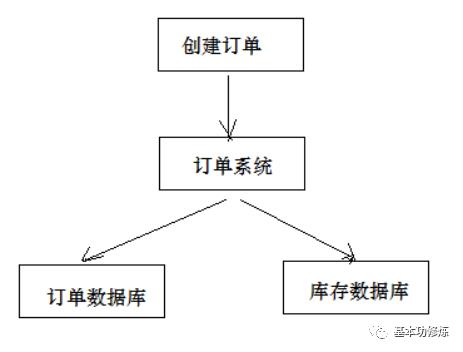
上面两种分布式事务表现形式以第一种据多
5、分布式事务有哪些场景?
1)电商系统中的下单扣库存电商系统中,订单系统和库存系统是两个系统,一次下单的操作由两个系统协同完成
2)金融系统中的银行卡充值在金融系统中通过银行卡向平台充值需要通过银行系统和金融系统协同完成
3)教育系统中下单选课业务在线教育系统中,用户购买课程,下单支付成功后学生选课成功,此事务由订单系统和选课系统协同完成
4)SNS系统的消息发送在社交系统中发送站内消息同时发送手机短信,一次消息发送由站内消息系统和手机通信系统协同完成
CAP理论
如何进行分布式事务控制?CAP理论是分布式事务处理的理论基础,了解了CAP理论有助于我们研究分布式事务的处理方案
CAP理论是:分布式系统在设计时只能在一致性(Consistency)、可用性(Availability)、分区容忍性(PartitionTolerance)中满足两种,无法兼顾三种。
通过下图理解CAP理论:
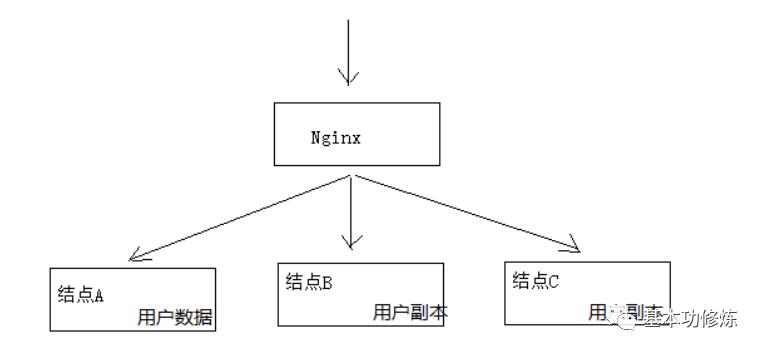
一致性(Consistency):服务A、B、C三个结点都存储了用户数据,三个结点的数据需要保持同一时刻数据一致性
可用性(Availability):服务A、B、C三个结点,其中一个结点宕机不影响整个集群对外提供服务,如果只有服务A结点,当服务A宕机整个系统将无法提供服务,增加服务B、C是为了保证系统的可用性
分区容忍性(PartitionTolerance):分区容忍性就是允许系统通过网络协同工作,分区容忍性要解决由于网络分区导致数据的不完整及无法访问等问题。
分布式系统不可避免的出现了多个系统通过网络协同工作的场景,结点之间难免会出现网络中断、网延延迟等现象,这种现象一旦出现就导致数据被分散在不同的结点上,这就是网络分区。
分布式系统能否兼顾C、A、P?
在保证分区容忍性的前提下一致性和可用性无法兼顾,如果要提高系统的可用性就要增加多个结点,如果要保证数据的一致性就要实现每个结点的数据一致,结点越多可用性越好,但是数据一致性越差。
所以,在进行分布式系统设计时,同时满足“一致性”、“可用性”和“分区容忍性”三者是几乎不可能的
CAP有哪些组合方式?
1、CA:放弃分区容忍性,加强一致性和可用性,关系数据库按照CA进行设计。
2、AP:放弃一致性,加强可用性和分区容忍性,追求最终一致性,很多NoSQL数据库按照AP进行设计。
说明:这里放弃一致性是指放弃强一致性,强一致性就是写入成功立刻要查询出最新数据。追求最终一致性是指允许暂时的数据不一致,只要最终在用户接受的时间内数据一致即可。
3、CP:放弃可用性,加强一致性和分区容忍性,一些强一致性要求的系统按CP进行设计,比如跨行转账,一次转账请求要等待双方银行系统都完成整个事务才算完成。
说明:由于网络问题的存在CP系统可能会出现待等待超时,如果没有处理超时问题则整理系统会出现阻塞。
总结:
在分布式系统设计中AP的应用较多,即保证分区容忍性和可用性,牺牲数据的强一致性(写操作后立刻读取到最新数据),保证数据最终一致性。比如:订单退款,今日退款成功,明日账户到账,只要在预定的用户可以接受的时间内退款事务走完即可。
解决方案
两阶段提交协议(2PC)
为解决分布式系统的数据一致性问题出现了两阶段提交协议(2PhaseCommitmentProtocol),两阶段提交由协调者和参与者组成,共经过两个阶段和三个操作,部分关系数据库如Oracle、mysql支持两阶段提交协议,本节讲解关系数据库两阶段提交协议。
参考:
2PC:https://en.wikipedia.org/wiki/Two-phase_commit_protocol
2PC协议流程图:
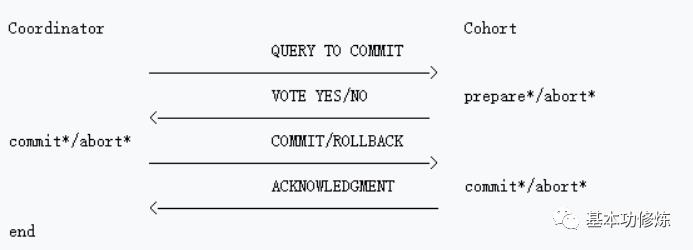
1)第一阶段:准备阶段(prepare)
协调者通知参与者准备提交订单,参与者开始投
协调者完成准备工作向协调者回应Yes
2)第二阶段:提交(commit)/回滚(rollback)阶段
协调者根据参与者的投票结果发起最终的提交指令
如果有参与者没有准备好则发起回滚指令
一个下单减库存的例子:
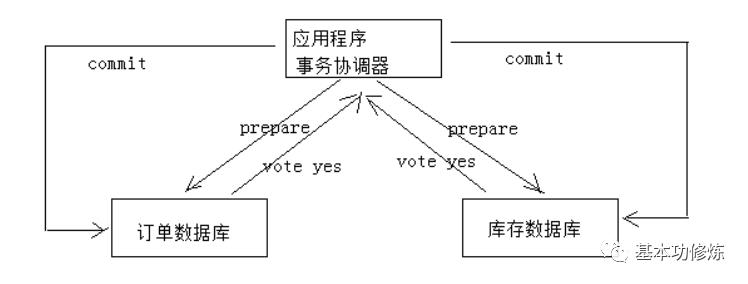
1、应用程序连接两个数据源
2、应用程序通过事务协调器向两个库发起prepare,两个数据库收到消息分别执行本地事务(记录日志),但不提交,如果执行成功则回复yes,否则回复no
3、事务协调器收到回复,只要有一方回复no则分别向参与者发起回滚事务,参与者开始回滚事务
4、事务协调器收到回复,全部回复yes,此时向参与者发起提交事务。如果参与者有一方提交事务失败则由事务协调器发起回滚事务。
2PC的优点:实现强一致性,部分关系数据库支持(Oracle、MySQL等)。
缺点:整个事务的执行需要由协调者在多个节点之间去协调,增加了事务的执行时间,性能低下。
解决方案有:springboot+AtomikosorBitronix
3PC主要是解决协调者与参与者通信阻塞问题而产生的,它比2PC传递的消息还要多,性能不高。详细参考3PC:https://en.wikipedia.org/wiki/Three-phase_commit_protocol
事务补偿(TCC)
TCC事务补偿是基于2PC实现的业务层事务控制方案,它是Try、Confirm和Cancel三个单词的首字母,含义如下:
1、Try检查及预留业务资源完成提交事务前的检查,并预留好资源
2、Confirm确定执行业务操作对try阶段预留的资源正式执行
3、Cancel取消执行业务操作对try阶段预留的资源释放
下边用一个下单减库存的业务为例来说明:
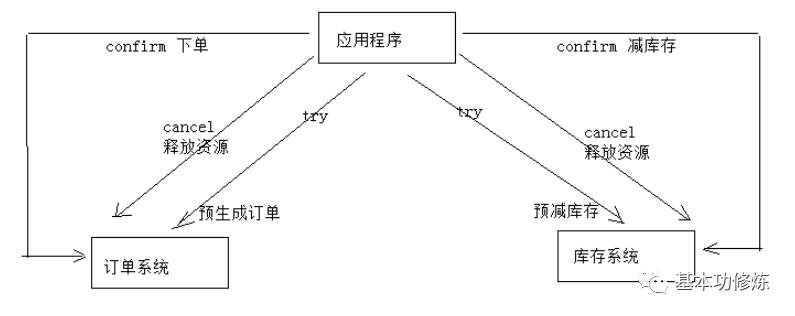
1、Try
下单业务由订单服务和库存服务协同完成,在try阶段订单服务和库存服务完成检查和预留资源。订单服务检查当前是否满足提交订单的条件(比如:当前存在未完成订单的不允许提交新订单)。库存服务检查当前是否有充足的库存,并锁定资源。
2、Confirm
订单服务和库存服务成功完成Try后开始正式执行资源操作。订单服务向订单写一条订单信息。库存服务减去库存。
3、Cancel
如果订单服务和库存服务有一方出现失败则全部取消操作。订单服务需要删除新增的订单信息。库存服务将减去的库存再还原。
优点:最终保证数据的一致性,在业务层实现事务控制,灵活性好。
缺点:开发成本高,每个事务操作每个参与者都需要实现try/confirm/cancel三个接口。
注意:TCC的try/confirm/cancel接口都要实现幂等性,在为在try、confirm、cancel失败后要不断重试。
什么是幂等性?
幂等性是指同一个操作无论请求多少次,其结果都相同。
幂等操作实现方式有:
1、操作之前在业务方法进行判断如果执行过了就不再执行。
2、缓存所有请求和处理的结果,已经处理的请求则直接返回结果。
3、在数据库表中加一个状态字段(未处理,已处理),数据操作时判断未处理时再处理。
消息队列实现最终一致
本方案是将分布式事务拆分成多个本地事务来完成,并且由消息队列异步协调完成,如下图:下边以下单减少库存为例来说明:
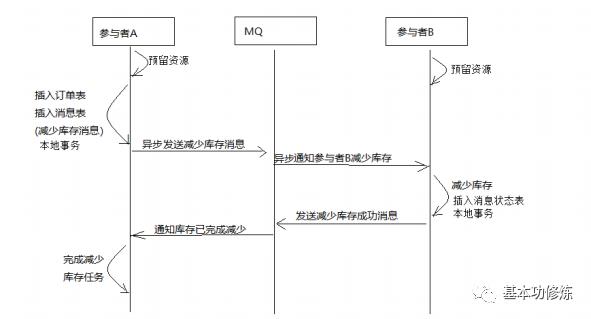
1、订单服务和库存服务完成检查和预留资源
2、订单服务在本地事务中完成添加订单表记录和添加“减少库存任务消息”
3、由定时任务根据消息表的记录发送给MQ通知库存服务执行减库存操作
4、库存服务执行减少库存,并且记录执行消息状态(为避免重复执行消息,在执行减库存之前查询是否执行过此消息)
5、库存服务向MQ发送完成减少库存的消息
6、订单服务接收到完成库存减少的消息后删除原来添加的“减少库存任务消息”
实现最终事务一致要求:预留资源成功理论上要求正式执行成功,如果执行失败会进行重试,要求业务执行方法实现幂等
优点:
由MQ按异步的方式协调完成事务,性能较高。
不用实现try/confirm/cancel接口,开发成本比TCC低
缺点:
此方式基于关系数据库本地事务来实现,会出现频繁读写数据库记录,浪费数据库资源,另外对于高并发操作不是最佳方案
自动添加选课方案
搭建环境
根据自动选课需求,为了更好的分析解决方案,这里搭建订单工程及数据库。
创建订单工程
导入资料下的xc-service-manage-order工程
创建订单数据库
1、创建订单数据库xc_order(MySQL)
导入xc_order.sql
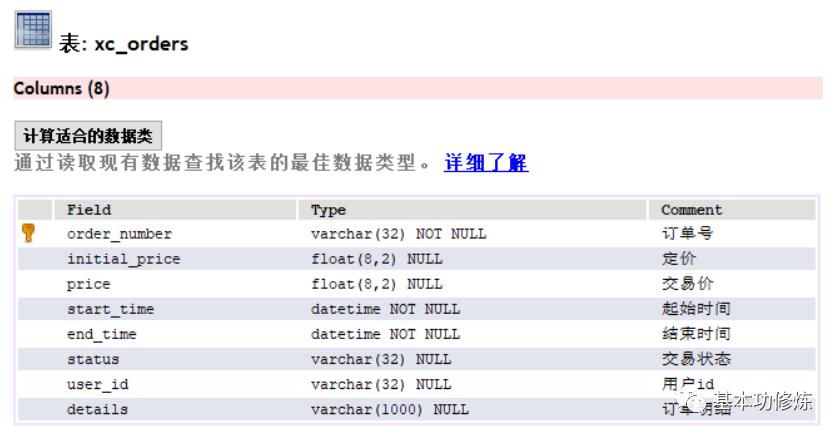
1)xc_orders:订单主表
记录订单的主要信息
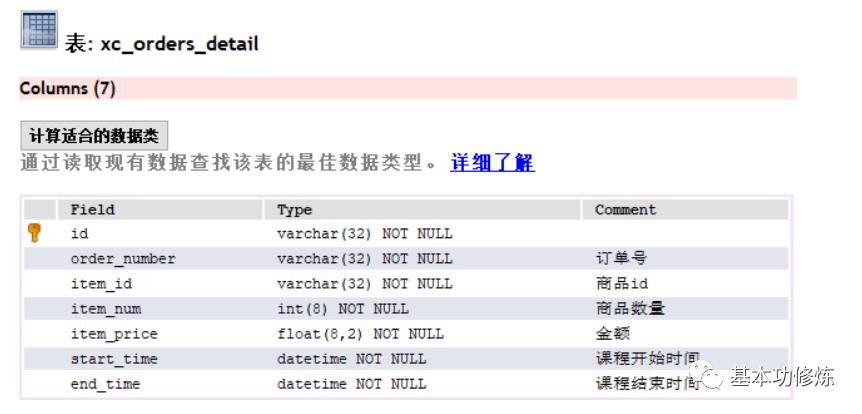
2)xc_orders_details:订单明细表
记录订单的明细信息
3)xc_orders_pay:订单支付表
记录订单的支付状态
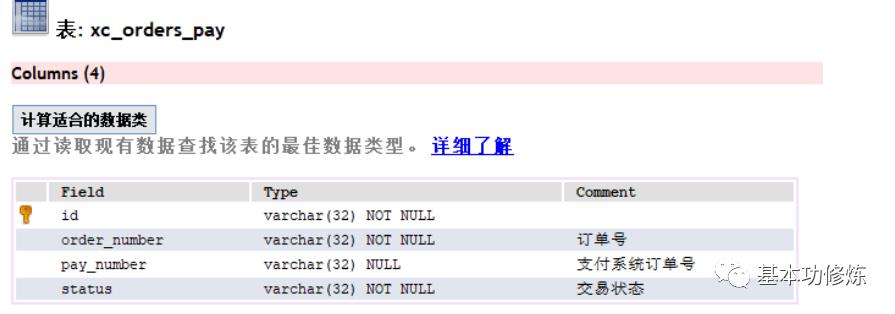
2、向xc_order数据库导入xc_order_task.sql
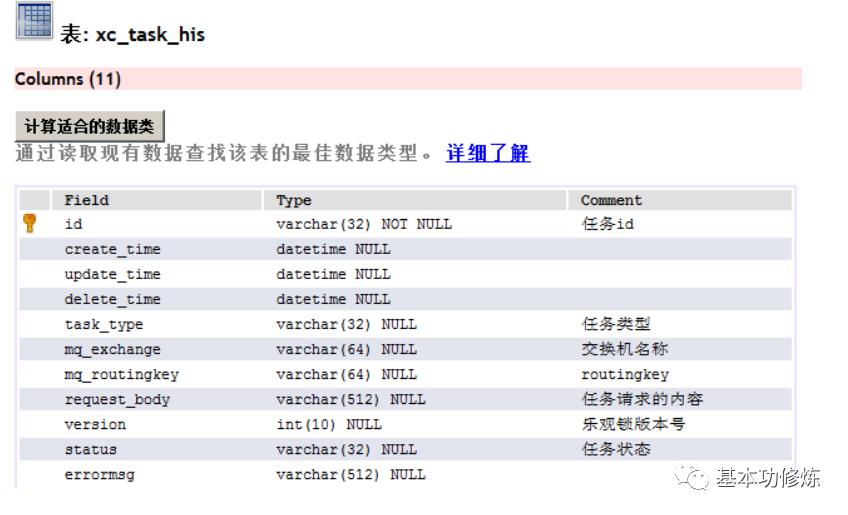
待处理任务表:
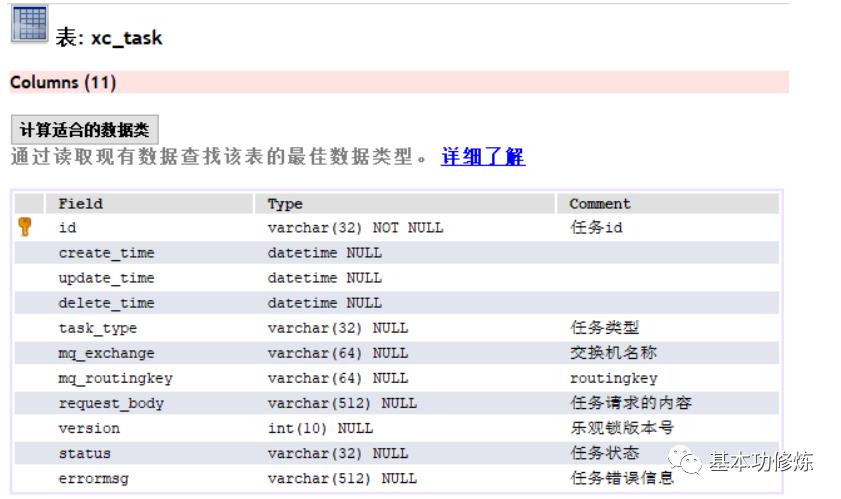
在任务表中包括了交换机的名称、路由key等信息为了是将任务的处理做成一个通用的功能。
考虑分布式系统并发读取任务处理任务的情况发生项目使用乐观锁的方式解决并发问题。
已完成任务表:
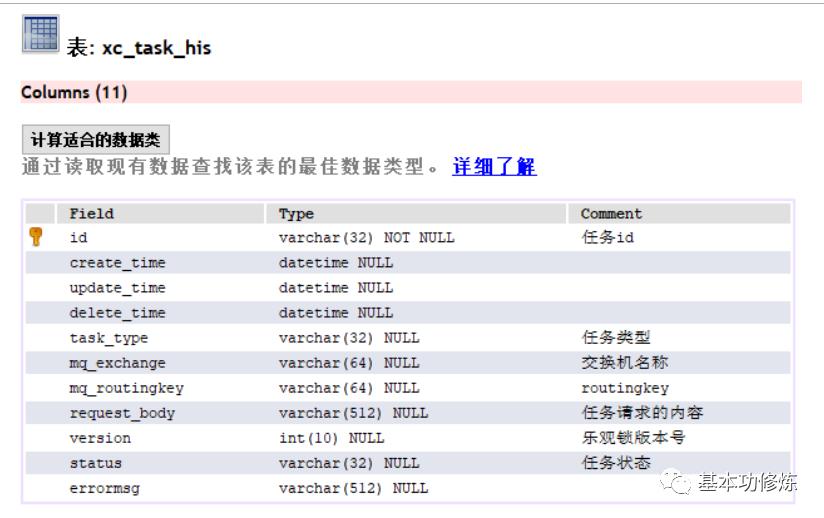
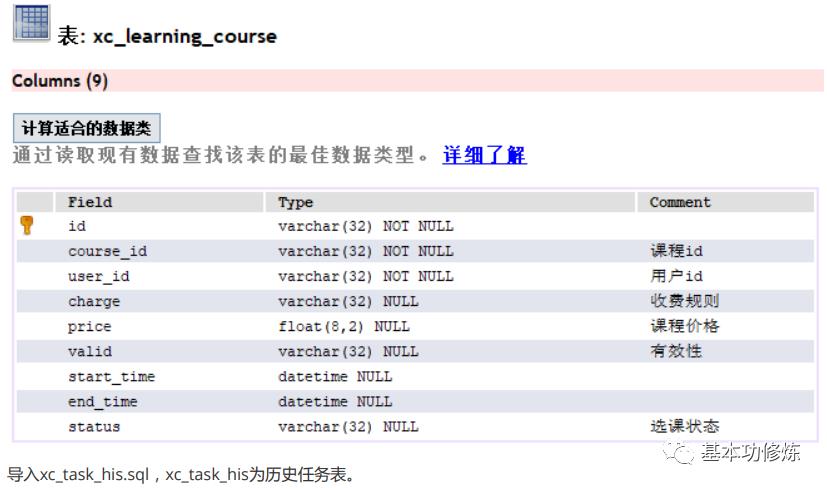
创建选课数据库
创建xc_learning数据库,导入xc_learning.sql,xc_learning_course为学生选课表
解决方案
本项目综合考虑选择基于消息的分布式事务解决方案,解决方案如下图:
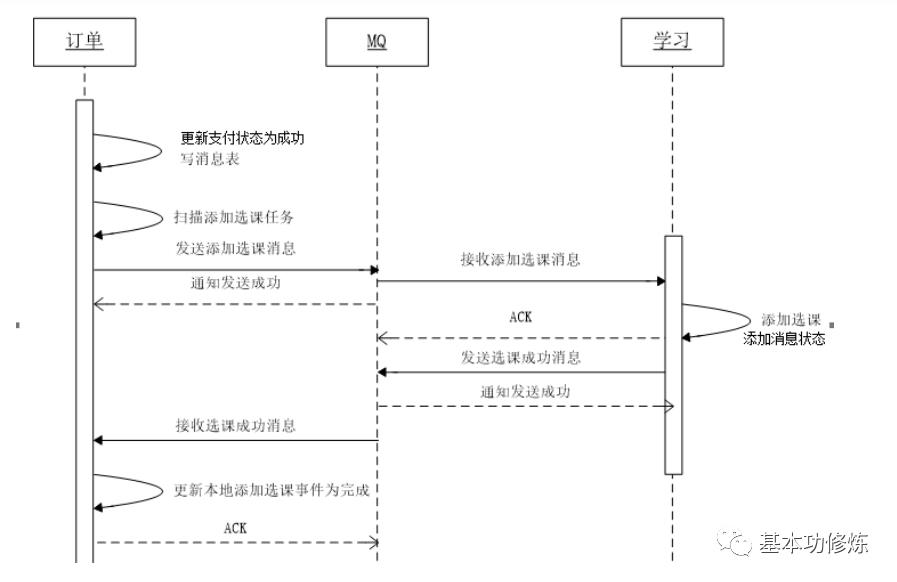
1、支付成功后,订单服务向本地数据库更新订单状态并向消息表写入“添加选课消息”,通过本地数据库保证订单状态和添加选课消息的事务。
2、定时任务扫描消息表,取出“添加选课任务“并发向MQ
3、学习服务接收到添加选课的消息,先查询本地数据库的历史消息表是否存在消息,存在则说明已经添加选课,否则向本地数据库添加选课,并向历史消息表添加选课消息。这里选课表和历史消息表在同一个数据库,通过本地事务保证。
4、学习服务接收到添加选课的消息,通过查询消息表判断如果已经添加选课也向MQ发送“完成添加选课任务的消息”,否则则添加选课,完成后向MQ发送“完成添加选课任务的消息”,
5、订单服务接收到完成选课的消息后删除订单数据库中消息表的“添加选课消息”,为保证后期对账将消息表的消息先添加到历史消息表再删除消息,表示此消息已经完成。
SpringTask定时任务
需求分析
根据分布式事务的研究结果,订单服务需要定时扫描任务表向MQ发送任务。
本节研究定时任务处理的方案,并实现定时任务扫描任务表并向MQ发送消息。实现定时任务的方案如下:
1、使用jdk的Timer和TimerTask实现可以实现简单的间隔执行任务,无法实现按日历去调度执行任务
2、使用Quartz实现Quartz是一个异步任务调度框架,功能丰富,可以实现按日历调度
3、使用SpringTask实现Spring3.0后提供SpringTask实现任务调度,支持按日历调度,相比Quartz功能稍简单,但是在开发基本够用,支持注解编程方式。本项目使用SpringTask实现任务调度。
SpringTask串行任务3
编写任务类
在Springboot启动类上添加注解:@EnableScheduling
新建任务测试类TestTask,编写测试方法如下:

测试:
1、测试fixedRate和fixedDelay的区别
2、测试串行执行的特点
cron表达式
cron表达式包括6部分:
秒(0~59)分钟(0~59)小时(0~23)月中的天(1~31)月(1~12)周中的天(填写MON,TUE,WED,THU,FRI,SAT,SUN,或数字1~71表示MON,依次类推)
特殊字符介绍:
“/”字符表示指定数值的增量
“*”字符表示所有可能的值
“-”字符表示区间范围
","字符表示列举
“?”字符仅被用于月中的天和周中的天两个子表达式,表示不指定值
例子:
0/3*****每隔3秒执行
00/5****每隔5分钟执行
000***表示每天0点执行
0012?*WEN每周三12点执行
01510?*MON-FRI每月的周一到周五10点15分执行
01510?*MON,FRI每月的周一和周五10点15分执行
串行任务测试
参考task1方法的的定义方法,再定义task2方法,此时共用两个任务方法

通过测试发现,两个任务方法由一个线程串行执行,task1方法执行完成task2再执行。
SpringTask并行任务
需求分析
在项目通常是需要多个不同的任务并行去执行
本节实现SpringTask并行执行任务的方法
配置异步任务
创建异步任务配置类,需要配置线程池实现多线程调度任务

将@EnableScheduling添加到此配置类上,SpringBoot启动类上不用再添加@EnableScheduling
测试
通过测试发现两个任务由不同的线程在并行执行,互不影响
订单服务定时发送消息
需求分析
定时任务发送消息流程如下:
1、每隔1分钟扫描一次任务表
1、定时任务扫描task表,一次取出多个任务,取出超过1分钟未处理的任务
2、考虑订单服务可能集群部署,为避免重复发送任务使用乐观锁的方式每次从任务列表取出要处理的任务
3、任务发送完毕更新任务发送时间
关于任务表的添加:正常的流程是订单支付成功向更新订单支付状态并向任务表写入“添加选课任务”。
目前订单支付功能没有开发,采用手动向任务表添加任务。
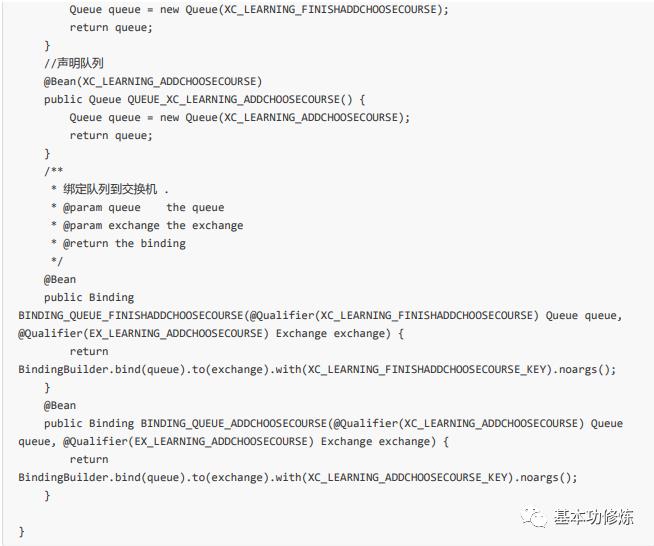
RabbitMQ配置向
RabbitMQ声明两个队列:添加选课、完成选课,交换机使用路由模式,代码如下:

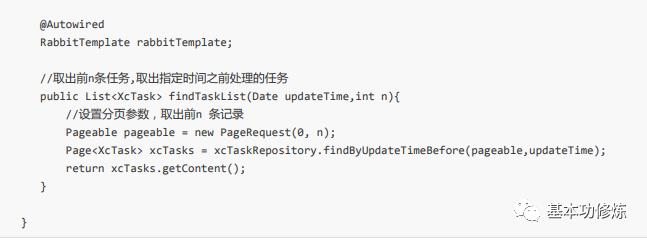
查询前N条任务
Dao
在XcTaskRepository中自定义方法如下:

Service

编写任务类
编写任务类,每分钟执行任务,启动订单工程,观察定时发送消息日志,观察rabbitMQ队列中是否有消息,代码如下:
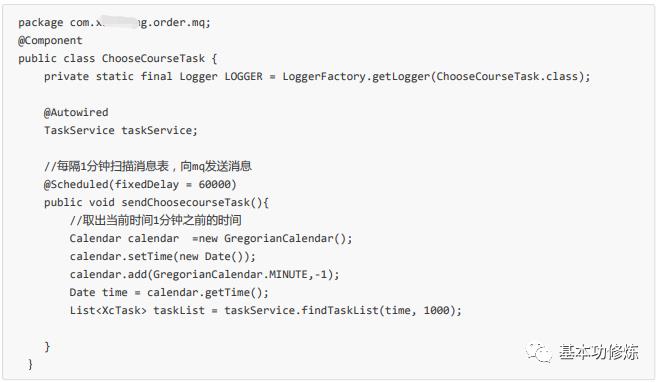
启动工程,测试读取任务列表的功能。
定时发送任务
Dao
添加更新任务方法:

Service
添加发送消息方法:

编写任务类
编写任务类,每分钟执行任务,启动订单工程,观察定时发送消息日志,观察rabbitMQ队列中是否有消息,代码如下:
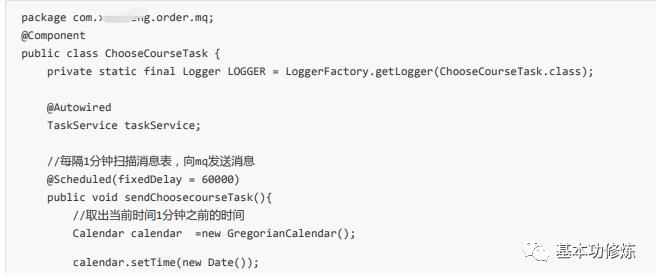
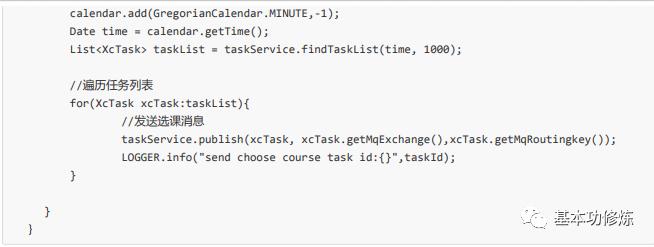
乐观锁取任务
考虑订单服务将来会集群部署,为了避免任务在1分钟内重复执行,这里使用乐观锁,实现思路如下:
1)每次取任务时判断当前版本及任务id是否匹配,如果匹配则执行任务,如果不匹配则取消执行。
2)如果当前版本和任务Id可以匹配到任务则更新当前版本加
1、在Dao中增加校验当前版本及任务id的匹配方法、

2、在service中增加方法,使用乐观锁方法校验任务

3、执行任务类中修改
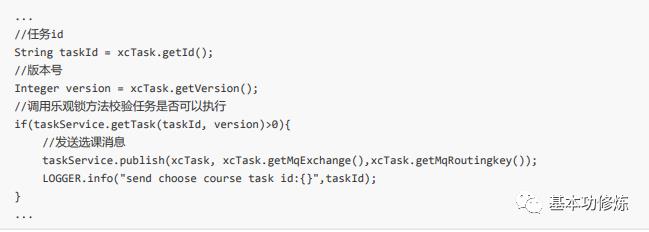
自动添加选课开发
学习服务添加选课
需求分析
学习服务接收MQ发送添加选课消息,执行添加选课操作
添加选课成功向学生选课表插入记录、向历史任务表插入记录、并向MQ发送“完成选课”消息
RabbitMQ配置
学习服务监听MQ的添加选课队列,并且声明完成选课队列,配置代码同订单服务中RabbitMQ配置
Dao
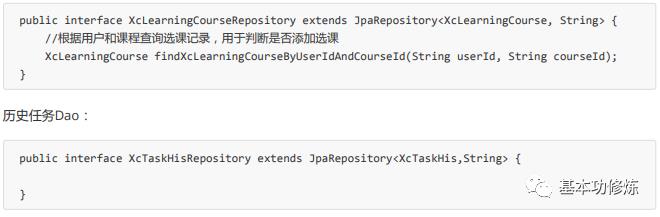
学生选课Dao:
Service
1、添加选课方法
向xc_learning_course添加记录,为保证不重复添加选课,先查询历史任务表,如果从历史任务表查询不到任务说明此任务还没有处理,此时则添加选课并添加历史任务
在学习服务中编码如下代码:


接收添加选课消息
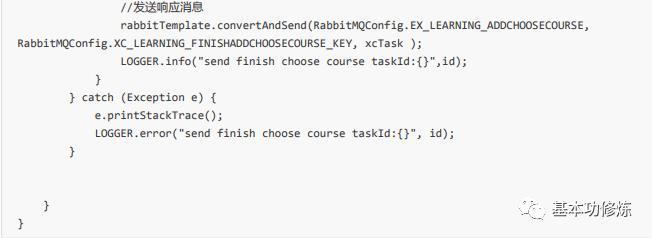
接收到添加选课的消息调用添加选课方法完成添加选课,并发送完成选课消息
在com.xuecheng.learning.mq包下添加ChooseCourseTask类

订单服务结束任务
需求分析
订单服务接收MQ完成选课的消息,将任务从当前任务表删除,将完成的任务添加到完成任务表
Dao
1、删除xc_task
2、添加xc_task_his
定义过程略
Service
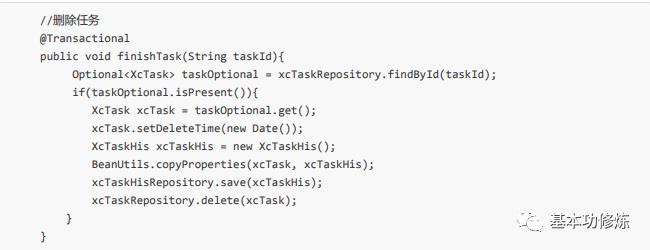
在TaskService中定义删除任务方法
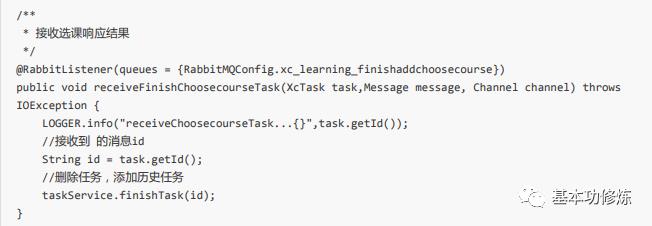
接收完成选课消息
在com.***g.manage_order.mq包下ChooseCourseTask类中添加receiveChoosecourseTask,接收完成选课任务消息并进行处理
集成测试
测试流程如下:
1、手动向任务表添加一条任务
2、启动rabbitMQ.
3、启动订单服务、选课服务
4、观察日志是否添加选课成功
完成任务后将xc_task任务移动到xc_task_his表中
完成任务后在选课表中多了一条学生选课记录
测试消息重复消费:
1、手动向任务表添加一条任务
2、启动rabbitMQ.
3、先启动订单表,等待消息队列是否积累了多个消息
4、再启动选课服务,观察是否重复添加选课
DevOps
DevOps介绍
什么是DevOps
DevOps是Development和Operations两个词的缩写,引用百度百科的定义:

DevOps是一种方法或理念,它涵盖开发、测试、运维的整个过程。DevOps是提高软件开发、测试、运维、运营等各部门的沟通与协作质量的方法和过程,DevOps强调软件开发人员与软件测试、软件运维、质量保障(QA)部门之间有效的沟通与协作,强调通过自动化的方法去管理软件变更、软件集成,使软件从构建到测试、发布更加快捷、可靠,最终按时交付软件
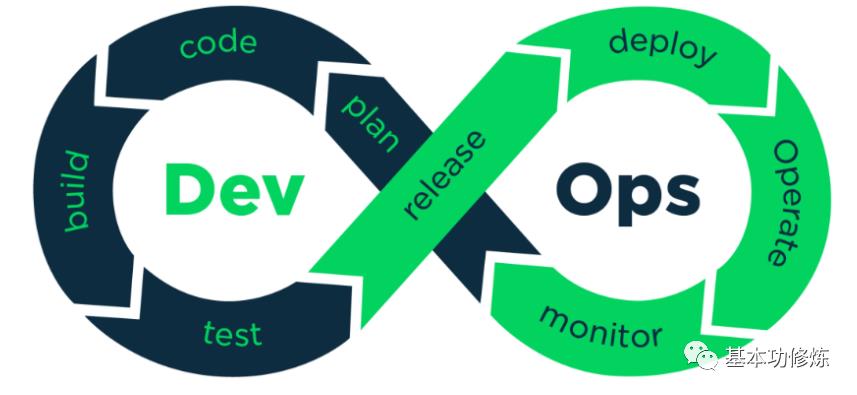
DevOps工具链
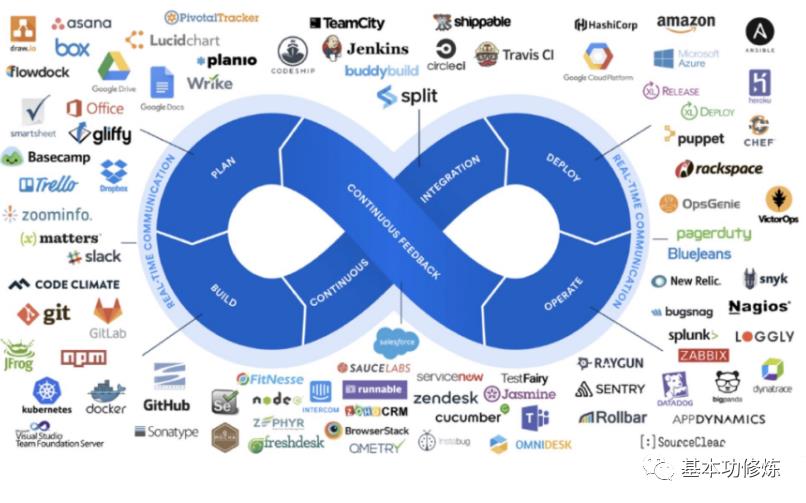
DevOps兴起于2009年,近年来由于云计算、互联网的发展,促进了DevOps的基础设施及工具链的发展,涌现了一大批优秀的工具,这些工具包括开发、测试、运维的各各领域,例如:GitHub、Git/SVN、Docker、Jenkins、Hudson、Ant/Maven/Gradle、Selenium、QUnit、JMeter等。下图是DevOps相关的工具集:
Git/GitLab
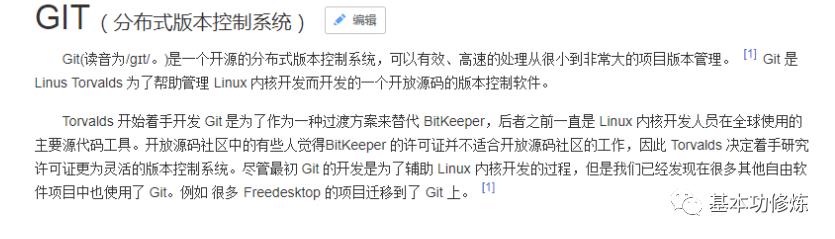
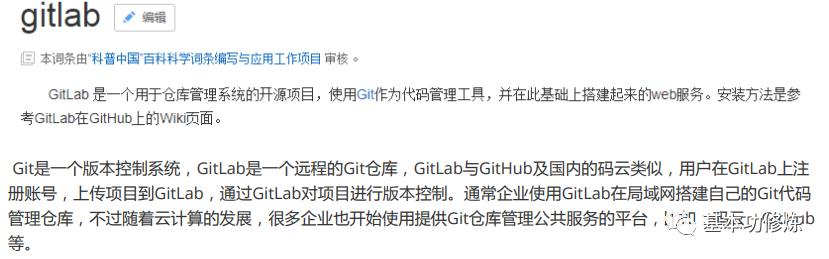
Git与GitLab介绍
引用百度百科中对Git和GitLab的描述:
安装Git及GitLab
个人电脑上安装Git,过程略
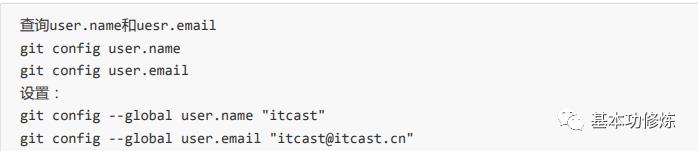
注意:Git安装完成需配置user.name和user.email
在Linux服务器上安装GitLab,安装方法见“GitLab安装文档”
注意:个人测试Git版本控制推荐建议直接使用GitHub或码云,两者提供免费创建项目的功能
在GitLab创建项目
进入GitLab首页:http://192.168.101.64:8889,点击“NewProject”创建新项目
输入项目信息,提交
使用Git管理项目
在Idea中集成Git,并用Git管理学成在线项目
设置Git
在开发电脑安装Git,并在Idea中设置Git
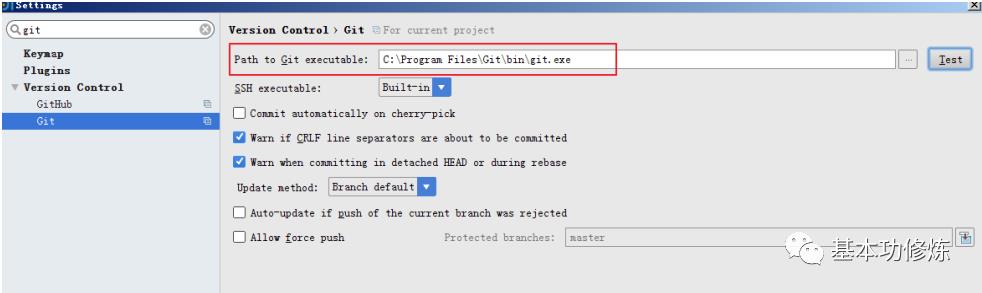
设置修改代码后父级目录颜色变化:
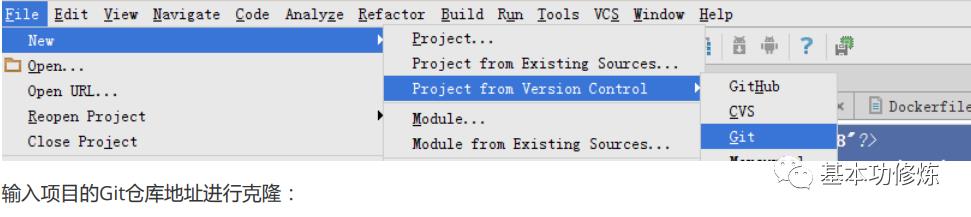
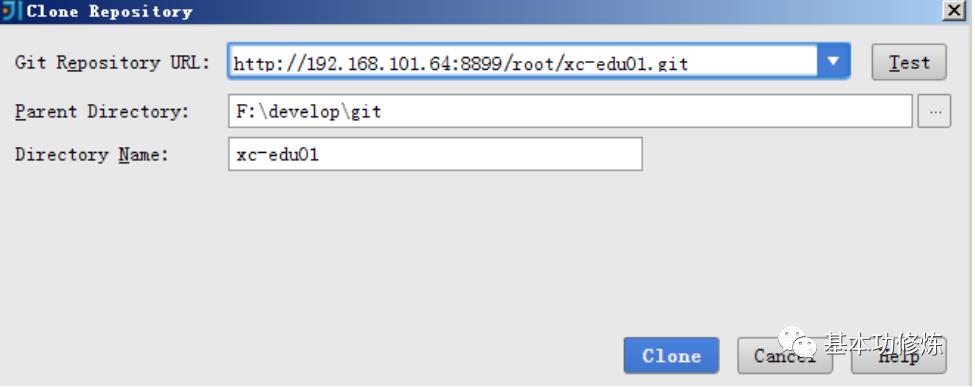
从GitLab检出项目
打开idea,按下图菜单指示从GitLab克隆项目:
提交代码到GitLab
1、在工程根目录创建.gitignore
此文件中记录了在提交代码时哪些文件或目录被忽略

2、代码修改后文件的颜色会出现变化:
首先执行添加文件到暂存区:
再执行commit提交文件到本地仓库
最终代码确认无误可以提交到远程仓库
Docker
虚拟化技术
问题描述
互联网的发展使软件业发生了巨大的变化,其中一个显著的变化是软件的规模越来越大,基于微服务架构的软件在生产部署时遇到了这样的挑战:
1、微服务的开发语言、操作系统、依赖库等环境配置不同,如何快速安装、迁移、配置软件?
2、一个软件由若干微服务组成,如何快速批量部署微服务?
3、如何有效的利于计算机资源?
针对前两个问题的思考:
传统的软件部署流程是:安装操作系统-->安装依赖软件/库-->安装软件(微服务)-->配置软件-->最终软件上线运行,面对大量的微服务及微服务集群,使用此方案不仅效率低下,而且还可能会出现环境兼容问题,显然此方案不适合用在微服务部署。
设想:如果有一项技术可以快速的将软件及所需要的各种环境配置打包、批量复制将会解决以上问题。
针对第三个问题的思考:在一台计算机只安装一个微服务对计算机资源极大的浪费,如果安装多个微服务就可以有效的利于计算机资源,但是对于批量软件的安装部署还是会面临1、2问题。
设想:在一台计算机安装多个微服务,使用一种技术将微服务打包、复制部署,并且微服务之间隔离互不影响。
虚拟化技术引用百度百科
(https://baike.baidu.com/item/%E8%99%9A%E6%8B%9F%E5%8C%96/547949)

总结:虚拟化技术是对软件基础设施、操作系统、软件等IT资源进行有效的管理,使用户不再受物理资源的限制,提高计算机资源的利用率。虚拟化技术是云计算的基础,例如阿里云的云主机、腾讯云等都应用了虚拟化技术。
虚拟化技术整体上包括两个方面:硬件虚拟化和软件虚拟化,具体分为:网络虚拟化、存储虚拟化、桌面虚拟化、服务器虚拟化等,我们平常说的最多的是服务器虚拟化。
服务器虚拟化就是在同一个物理服务器上运行多个虚拟机,让服务器的cpu、内存、磁盘、I/O等硬件设施为每个虚拟机服务,在每个虚拟机中运行不同的软件,虚拟机之间是隔离状态。
服务器虚拟化主要有两种技术:
1、Hypervisor也叫VMM(virtualmachinemonitor)即虚拟机监视器
Hypervisor是一种将操作系统与硬件抽象分离的方法,实现在宿主机(hostmachine)上能同时运行多个客户机(guestmachine),每个客户机就是一个虚拟机,这些虚拟机高效地分享宿主机的硬件资源。
如下图:

在服务器(宿主机)上安装操作系统,并安装hypervisor虚拟机管理软件,如VMware、VirtualBox等,由hypervisor管理多个虚拟机,每个虚拟机上需要安装客户操作系统、依赖库、应用软件。
2、Containers容器化技术
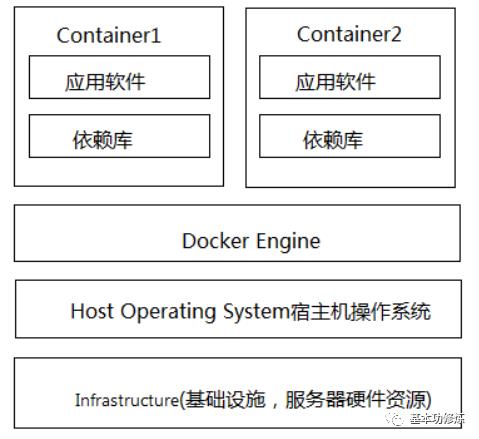
容器技术中docker引擎取代了hypervisor,docker引擎是运行在住宿操作系统上的一个进程,该进程管理了多个docker容器,每个docker容器集成了应用软件、依赖库,容器之间相互隔离。
3、技术对比:
资源占用:
虚拟机由于是独立的操作系统,占用资源比docker多
启动速度:
虚拟机包括操作系统,启动虚拟机相当于启动一个操作系统,容器则不一样,容器中只包括操作系统的内核,启动一个容器实例相当于启动一个进程,容器的启动速度比虚拟机快
体积:
容器包括操作系统内核、软件及依赖库,虚拟机不仅包括软件和依赖库还将完整的操作系统打包进去,虚拟机的体积比容器大的多。
Docker介绍引用百度百科(https://baike.baidu.com/item/Docker)

官网:https://www.docker.com/Docker
包括以下部分:
引用百度百科https://baike.baidu.com/item/Docker
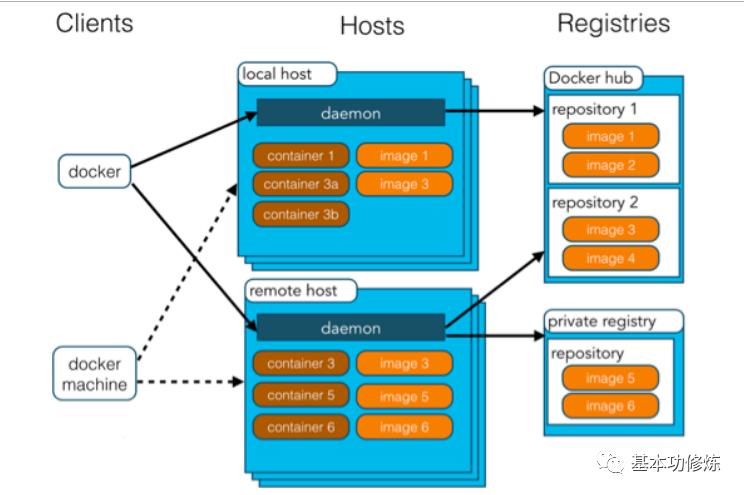
1、Dockerdaemon(Docker守护进程):Docker守护进程是部署在操作系统上,负责支撑DockerContainer的运行以及本地Image的管理
2、Dockerclient:用户不直接操作Dockerdaemon,用户通过Dockerclient访问Docker,Dockerclient提供pull、run等操作命令
3、DockerImage:Docker镜像就是一个只读的模板。例如:一个镜像可以包含一个完整的ubuntu操作系统环境,里面仅安装了Tomcat或用户需要的其它应用程序。镜像可以用来创建Docker容器。Docker提供了一个很简单的机制来创建镜像或者更新现有的镜像,用户甚至可以直接从其他人那里下载一个已经做好的镜像来直接使用
4、DockerContainer:Docker利用容器来运行应用。容器是从镜像创建的运行实例。它可以被启动、开始、停止、删除。每个容器都是相互隔离的、保证安全的平台。打个比方,镜像相当于类,容器相当于对象
5、DockerRegistry:Docker仓库分为公开仓库(Public)和私有仓库(Private)两种形式最大的公开仓库是DockerHub,存放了数量庞大的镜像供用户下载。用户也可以在本地网络内创建一个私有仓库。当用户创建了自己的镜像之后就可以使用push命令将它上传到公有或者私有仓库,这样下次在另外一台机器上使用这个镜像时候,只需要从仓库上pull下来就可以了。
部署微服务到Docker
安装Docker
Docker可以运行MAC、Windows、Centos、DEBIAN、UBUNTU等操作系统上,提供社区版和企业版,本教程基于Centos安装Docker。Centos6对docker支持的不好,使用docker建议升级到centos7。
1、在Centos7上安装Docker
直接通过yum安装即可:
yuminstall-ydocker
启动docker:servicedockerstart
查询docker版本:dockerversion
2、在Centos6上安装Docker
rpm-ivhhttp://dl.Fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
yuminstall-ydocker-io
servicedockerstart
部署流程
本项目微服务采用SpringBoot开发,将每个微服务工程打成Jar包,最终在Docker容器中运行jar,部署流程如下:
1、SpringBoot工程最终打成Jar包
2、创建Docker镜像
3、创建容器
4、启动容器
打包
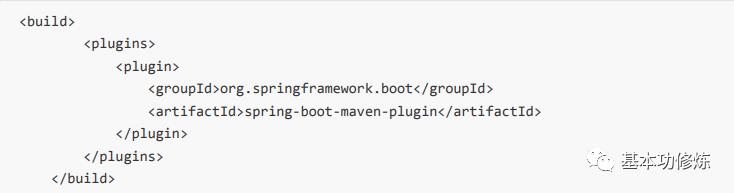
1、使用maven的打包插件:
将下边的插件依赖拷贝到微服务工程中,本例子将学成在线的Eureka工程打包:
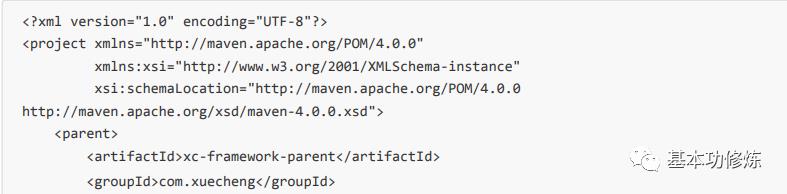
完整的Eureka工程pom.xml文件如下:
2、maven打包
在工程目录运行:mvnclearpackage
或通过IDEA执行clearpackage打包命令
打包成功,如下图:
创建镜像
将上一步的jar包拷贝到Linux服务器,准备创建镜像
测试jar包是否可以运行,执行:java-jarxc-govern-center-1.0-SNAPSHOT.jar
在xc-govern-center-1.0-SNAPSHOT.jar位置编写Dockerfile文件

在Dockerfile文件所在目录执行:dockerbuild-txc-govern-center:1.0-SNAPSHOT.镜像创建成功,查询镜像:

创建容器
基于xc-govern-center:1.0-SNAPSHOT镜像创建容器,容器名称为xc-govern-center-test

容器创建成功,可通过dockerps-a命令查看
启动容器
dockerstartxc-govern-center-test
容器启动完成可以通过dockerps查询正在运行中的容器
停止与删除
要删除的一个镜像重新创建,需要通过如下步骤:
1、停止正在运行的容器
dockerstop容器名
例如:dockerstopxc-govern-center-test
2、删除容器
dockerrm容器名
例如:dockerrmxc-govern-center-test
3、删除镜像
dockerrmi镜像名或镜像Id
例如:dockerrmixc-govern-center:1.0-SNAPSHOT
maven构建镜像
上边构建的过程是通过手工一步一步完成,maven提供docker-maven-plugin插件可完成从打包到构建镜像、构建容器等过程
1、编写pom_docker.xml


2、将Dockerfile文件拷贝到src/main/resource下
3、删除之前创建的xc-govern-center镜像
4、进入工程根目录(pom_docker.xml所在目录)执行

创建镜像成功,结果如下:
持续集成
持续集成介绍
问题描述传统的软件开发流程如下:
1、项目经理分配模块给开发人员
2、每个模块的开发人员并行开发,并进行单元测试
3、开发完毕,将代码集成部署到测试服务器,测试人员进行测试
4、测试人员发现bug,提交bug、开发人员修改bug
5、bug修改完毕再次集成、测试
问题描述:
1、模块之间依赖关系复杂,在集成时发现大量bug
2、测试人员等待测试时间过长
3、软件交付无法保障
解决上述问题的思考:
1、能否把集成测试时间提前?
2、能否使用自动化工具代替人工集成部署的过程?
什么是持续集成
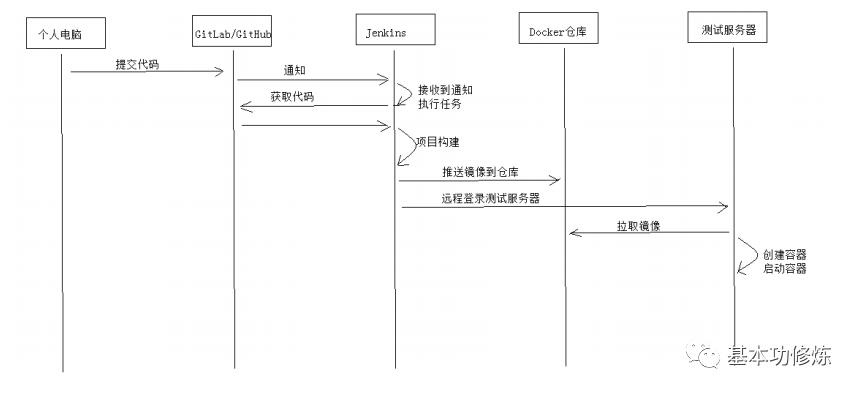
本项目持续集成流程
搭建环境
安装JenkinsJenkins是一个领先的开源自动化服务器,可用于自动化构建,测试,部署软件等相关任务
安装GitLab
GitLab是一个用于仓库管理系统的开源项目,使用Git作为代码管理工具,并在此基础上搭建起来的web服务。
GitLab与GitHub的功能相似,通常企业使用GitLab在局域网搭建自己的Git代码管理仓库
编写Pom.xml
本例子将xc-govern-center工程使用Jenkins进行构建
在xc-govern-center工程根目录编写pom_docker_registry.xml
此文件相比工程原有pom.xml增加了docker-maven-plugin插件,其作用是构建docker镜像并将镜像推送到Docker私有仓库(192.168.101.64:5000)


创建持续集成任务
创建构建任务
创建学成在线的构建任务:
配置git仓库
1、配置git凭证
此凭证用于远程从git仓库克隆工程源代码
输入git仓库的账号和密码,这里如果使用码云,下边需要配置码云的账号和密码
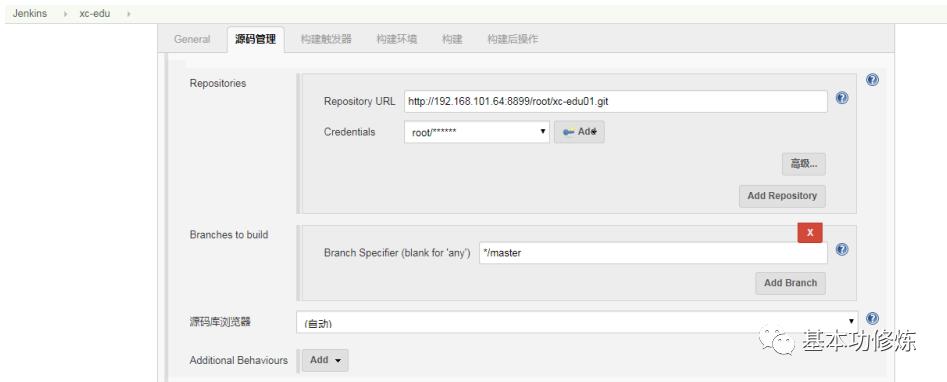
maven构建配置
目标:
使用jenkins重复构建不要产生重复镜像
使用jekins停止容器、删除容器、删除镜像之间进行判断
构建过程分为三步:
本例子以构建xc-govern-center工程为例,其它工程构建方式类似
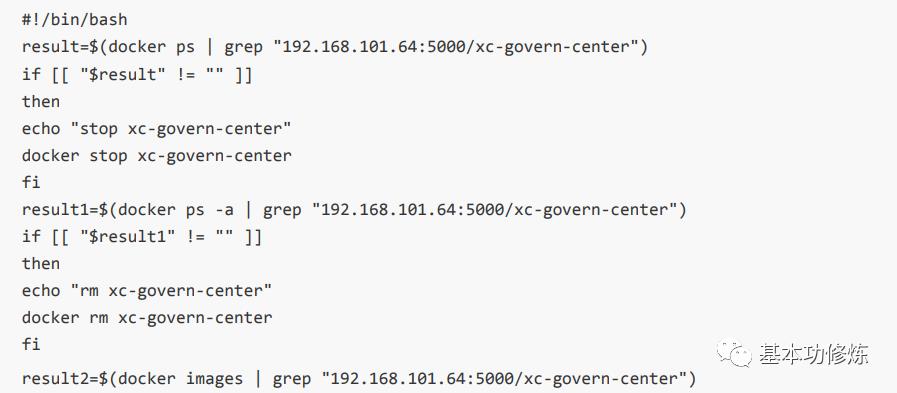
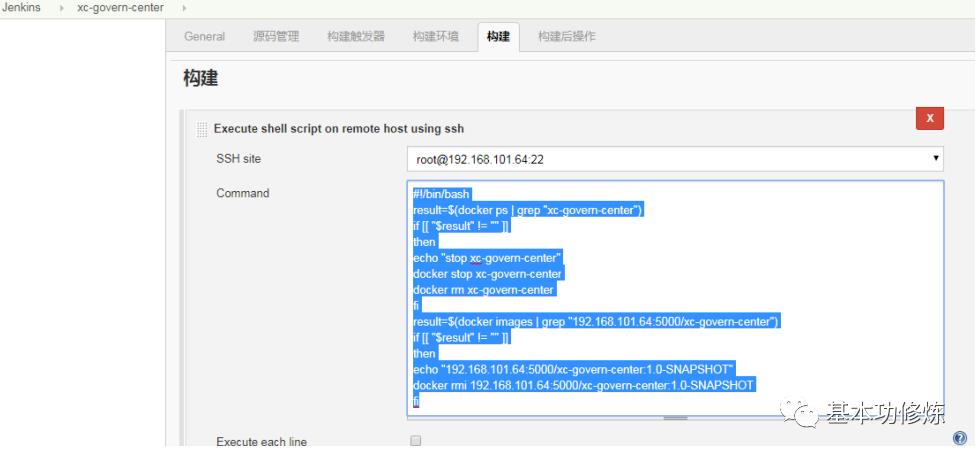
1、使用shell脚本停止容器、删除容器、删除镜像
远程登录192.168.101.64(测试服务器)
停止xc-govern-center容器
删除xc-govern-center容器
删除192.168.101.64:5000/xc-govern-center:1.0-SNAPSHOT镜像
shell脚本如下:

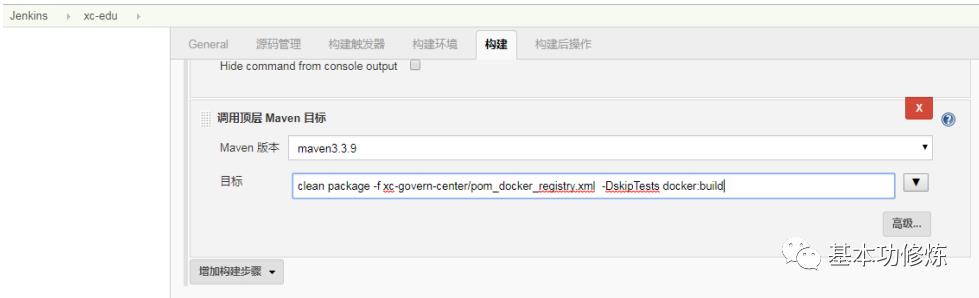
2、执行maven构建:

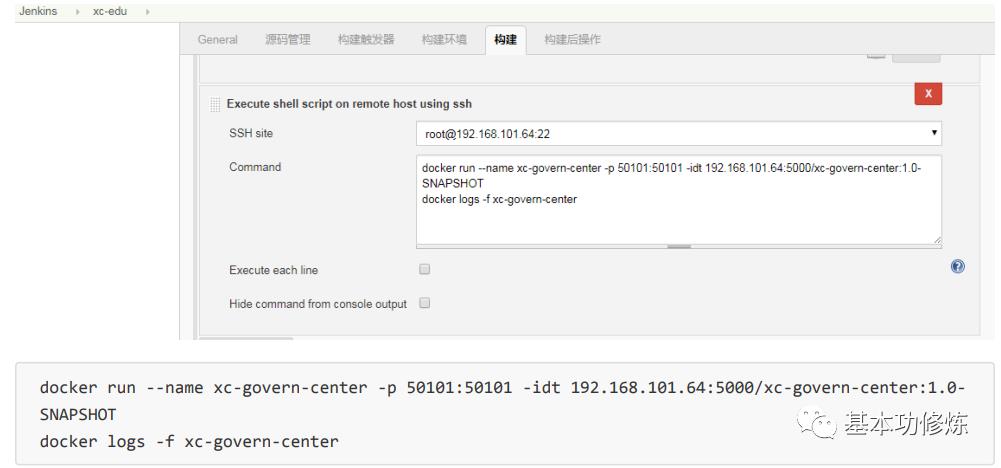
3、拉取镜像,创建容器,启动容器
从docker私有仓库拉取镜像并创建容器,启动容器
显示容器运行日志
执行任务
1、进入任务页面,点击“立即构建”
2、开始构建,查看日志
自动构建
使用Gitlab提供的webhook功能可以实现开发人员将代码push到Git仓库自动进行构建。
1、设置webhook参考“GitLab安装文档”配置webhook
2、在Idea中修改项目代码,push到GitLab
3、Jenkins任务收到GitLab通知自动执行构建
以上是关于分布式事务DevOps的主要内容,如果未能解决你的问题,请参考以下文章