Flink Sink JDBC 源码分析
Posted OfNull
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink Sink JDBC 源码分析相关的知识,希望对你有一定的参考价值。
使用举例
说明:以下所有都基于Flink1.11版本 代码都精简过了
简单栗子
public class mysqlSinkExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.fromElements("a", "b", "c", "d");
//执行参数
JdbcExecutionOptions executionOptions = JdbcExecutionOptions.builder().withBatchIntervalMs(500L).withBatchSize(10000).build();
//数据库连接参数
JdbcConnectionOptions connectionOptions = (new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()).withUrl("jdbcurl").withDriverName("db.driver").withUsername("db.username").withPassword("monitor.db.password").build();
//sql
final String sql = "INSERT INTO letter (name) VALUES (?)";
//输出
source.addSink(JdbcSink.sink(
sql,
(st, r) -> {
st.setString(1, r);
},
executionOptions,
connectionOptions
));
env.execute("sink mysql");
}
}
上面需求就是将元素 "a" "b" "c" "d" 写入 letter 表!可以看到我们有配置
-
JdbcExecutionOptions 执行参数 -
batchIntervalMs :每次批量写入最小间隔时间 -
batchSize :批量写入的数据大小 -
maxRetries : 插入发生异常重试次数 注意:只支持 SQLException 异常及其子类异常重试 -
JdbcConnectionOptions 连接参数配置 -
sql 写入的sql语句 -
里面还有一个 labmbda 函数实现它 本身是一个消费型labmbda函数 -
PreparedStatement :第一个参数 -
第二参数是元素 如代码中的a b c ...
产生思考
当我们写入数据成功时候,会不会想一些其他的问题 ?
如何实现批量写入的?
批量写入是不是会产生数据延迟?
我想转实时写入怎么配置?
数据会丢失吗?
源码
看源码之前看一张核心类关联图,请记住这三个核心类,后面都穿插着他们身影。
工厂类 JdbcSink
我们是通过 JdbcSink.sink(...) 构造一个 SinkFunction 提供给Flink输出数据!
-- org.apache.flink.connector.jdbc.JdbcSink
public class JdbcSink {
public static <T> SinkFunction<T> sink(
String sql,
JdbcStatementBuilder<T> statementBuilder,
JdbcExecutionOptions executionOptions,
JdbcConnectionOptions connectionOptions) {
return new GenericJdbcSinkFunction<>( // todo GenericJdbcSinkFunction
new JdbcBatchingOutputFormat<>( // todo JdbcBatchingOutputFormat 批量写出处理类
new SimpleJdbcConnectionProvider(connectionOptions), //todo Jdbc连接包装类
executionOptions, //todo 执行参数类 如重试次数 最大等待时间 最大等待条数
context -> {
Preconditions.checkState(
!context.getExecutionConfig().isObjectReuseEnabled(),
"objects can not be reused with JDBC sink function");
return JdbcBatchStatementExecutor.simple( //todo 返回的就是这个 SimpleBatchStatementExecutor 这里封装了 最终写入逻辑
sql,
statementBuilder,
Function.identity());
},
JdbcBatchingOutputFormat.RecordExtractor.identity()
));
}
根据此图结合看一下 核心类关系图!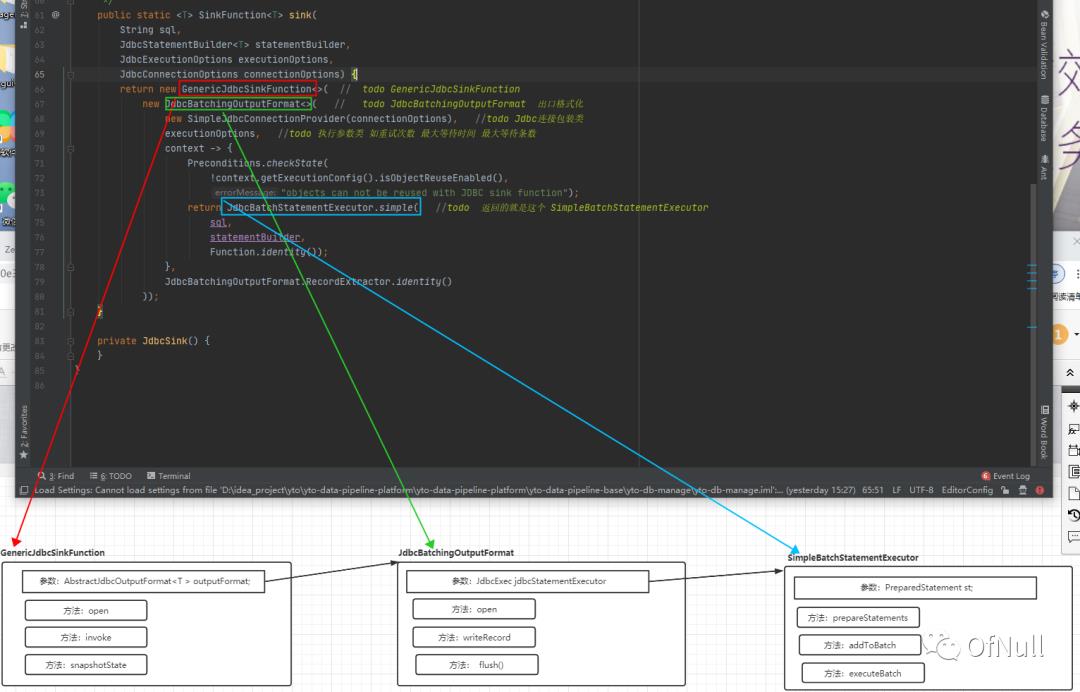 这里我们不用去理解具体每个类作用,但是必须知道通过工厂构造出一个 GenericJdbcSinkFunction !
这里我们不用去理解具体每个类作用,但是必须知道通过工厂构造出一个 GenericJdbcSinkFunction !
数据处理:GenericJdbcSinkFunction
Flink官方提供了 RichSinkFunction 供我们完成数据输出!它有两个接口供下游处理!open 函数初始化方法 在实际处理数据之前仅会调用一次 invoke 每进来一条数据都会调用一次
open(Configuration parameters)
invoke(T value, Context context)
作
我们再来看看 GenericJdbcSinkFunction 实现 RichSinkFunction 之后具体干了什么?
public class GenericJdbcSinkFunction<T> extends RichSinkFunction<T> {
private final AbstractJdbcOutputFormat<T > outputFormat;
public GenericJdbcSinkFunction(@Nonnull AbstractJdbcOutputFormat<T> outputFormat) {
this.outputFormat = Preconditions.checkNotNull(outputFormat);
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
RuntimeContext ctx = getRuntimeContext();
outputFormat.setRuntimeContext(ctx);
outputFormat.open(ctx.getIndexOfThisSubtask(), ctx.getNumberOfParallelSubtasks());
}
@Override
public void invoke(T value, Context context) throws IOException {
outputFormat.writeRecord(value);
}
}
简化代码发现:open执行时候会去调用 outputFormat.open(...) invoke 也只是调用了 outputFormat.writeRecord(value)
那么outputFormat是具体那个类实现? 回到构造工厂可以看到 里面构造了 JdbcBatchingOutputFormat
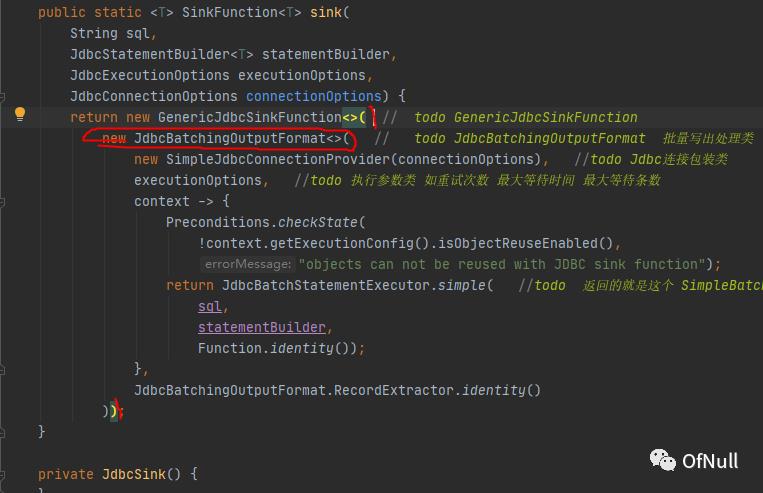
这个时候可以理解: AbstractJdbcOutputFormat
初始化:JdbcBatchingOutputFormat#Open
public class JdbcBatchingOutputFormat extend AbstractJdbcOutputFormat{
private transient JdbcExec jdbcStatementExecutor;
@Override
public void open(int taskNumber, int numTasks) throws IOException {
//初始化jdbc连接
super.open(taskNumber, numTasks);
// todo 创建执行器 SimpleBatchStatementExecutor
jdbcStatementExecutor = createAndOpenStatementExecutor(statementExecutorFactory);
// todo 如果 配置输出到jdbc最小间隔不等于0 且最小条数不是1 就创建一个固定定时线程池
if (executionOptions.getBatchIntervalMs() != 0 && executionOptions.getBatchSize() != 1) {
this.scheduler = Executors.newScheduledThreadPool(
1,
new ExecutorThreadFactory("jdbc-upsert-output-format"));
this.scheduledFuture = this.scheduler.scheduleWithFixedDelay(
() -> {
synchronized (JdbcBatchingOutputFormat.this) {
if (!closed) {
try {
// todo 批量缓存的数据都写到jdbc
flush();
} catch (Exception e) {
flushException = e;
}
}
}
},
executionOptions.getBatchIntervalMs(),
executionOptions.getBatchIntervalMs(),
TimeUnit.MILLISECONDS);
}
}
}
其实这里就干了三件事情: 第一件事:super.open(taskNumber, numTasks)就是调用了抽象父类中 AbstractJdbcOutputFormat的open方法
public abstract class AbstractJdbcOutputFormat{
protected transient Connection connection;
protected final JdbcConnectionProvider connectionProvider;
@Override
public void open(int taskNumber, int numTasks) throws IOException {
try {
establishConnection();
} catch (Exception e) {
throw new IOException("unable to open JDBC writer", e);
}
}
protected void establishConnection() throws Exception {
//创建jdbc连接
connection = connectionProvider.getConnection();
}
}
而这个JdbcConnectionProvider这个类就是在在构造JdbcBatchingOutputFormat构造方法传入的SimpleJdbcConnectionProvider
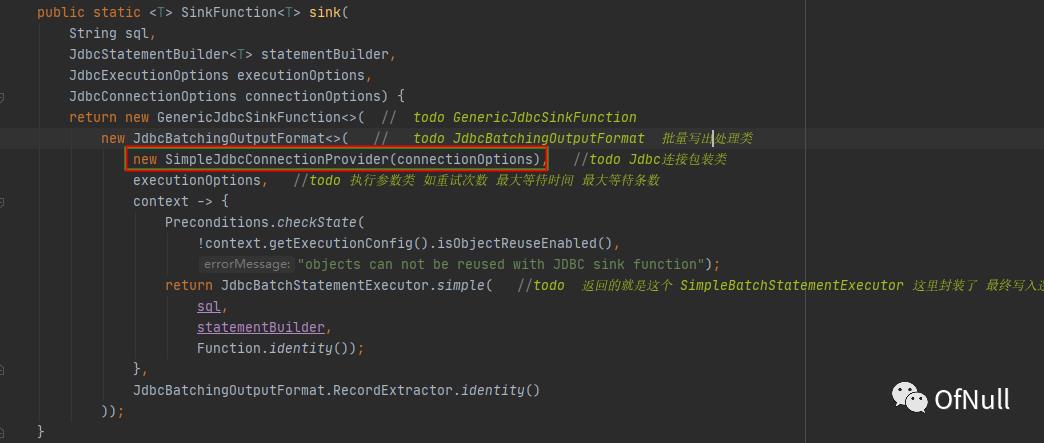
SimpleJdbcConnectionProvider#getConnection 可以看到就是创建了Connection
public class SimpleJdbcConnectionProvider{
private final JdbcConnectionOptions jdbcOptions;
private transient volatile Connection connection;
@Override
public Connection getConnection() throws SQLException, ClassNotFoundException {
if (connection == null) {
synchronized (this) {
if (connection == null) {
Class.forName(jdbcOptions.getDriverName());
if (jdbcOptions.getUsername().isPresent()) {
connection = DriverManager.getConnection(jdbcOptions.getDbURL(), jdbcOptions.getUsername().get(), jdbcOptions.getPassword().orElse(null));
} else {
connection = DriverManager.getConnection(jdbcOptions.getDbURL());
}
}
}
}
return connection;
}
}
第二件事:createAndOpenStatementExecutor(statementExecutorFactory) 创建执行器 SimpleBatchStatementExecutor
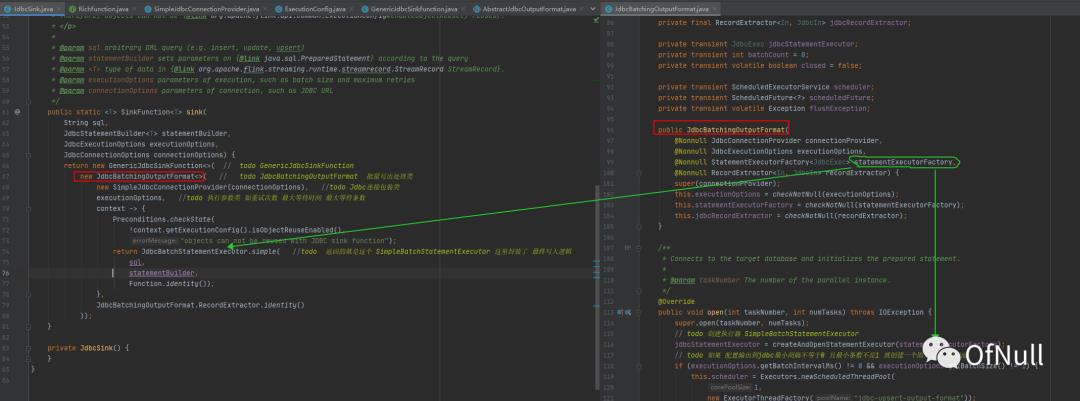
然后调用 SimpleBatchStatementExecutor#prepareStatements(connection) 初始化了 PreparedStatement st
第二件事:根据条件判断是否创建固定定时启动线程池!这个线程池会根据你配置的时间定时启动去执行 flush 方法!这个 flush 方法主要作用定时将缓存的数据触发jdbc写入!
扩展一下:为什么还要判断 executionOptions.getBatchSize() != 1 呢?你想如果最大推送大小只有一条那就是来一条写入jdbc一条那么定时去触发写入就没啥意义了!如果想要实时写入那么也就是来一条我立马写入到jdbc。这个时候在flink内部不会有延迟的!
处理数据:JdbcBatchingOutputFormat#writeRecord
每条数据进来每次都会进入一下逻辑 我们宏观先看一遍 有个印象再来看细节
-
GenericJdbcSinkFunction#invoke -
SimpleBatchStatementExecutor#addToBatch -
JdbcBatchingOutputFormat#flush -
SimpleBatchStatementExecutor#executeBatch -
JdbcBatchingOutputFormat#writeRecord
设计思路:
我们想要实现批量写入,那就必须要有批量数据,可是我们数据一条条进来是不是先得有个容器容纳这些批量数据?当容器到达一定的数据量我们就得批量写出去,然后清空容器,再重新装数据。
flink的实现:
JdbcBatchingOutputFormat#writeRecord
@Override
public final synchronized void writeRecord(In record) throws IOException {
//写入数据之前发现有之前存在异常 就抛出异常 结束写入!否则则继续写入。
checkFlushException();
try {
//将数据添加到容器
addToBatch(record, jdbcRecordExtractor.apply(record));
//计数器 统计容器已经有多少数据了
batchCount++;
//判断计数器是不是达到 指定容量
if (executionOptions.getBatchSize() > 0
&& batchCount >= executionOptions.getBatchSize()) {
flush(); //达到就执行批量输出jdbc
}
} catch (Exception e) {
throw new IOException("Writing records to JDBC failed.", e);
}
}
JdbcBatchingOutputFormat#addToBatch 如何批量写入容器
protected void addToBatch(In original, JdbcIn extracted) throws SQLException {
//这个jdbcStatementExecutor 前面说了就等于 SimpleBatchStatementExecutor
jdbcStatementExecutor.addToBatch(extracted);
}
SimpleBatchStatementExecutor#addToBatch
class SimpleBatchStatementExecutor<T, V>{
private final List<V> batch;
SimpleBatchStatementExecutor(...) {
...
this.batch = new ArrayList<>();
}
@Override
public void addToBatch(T record) {
batch.add(valueTransformer.apply(record));
}
}
可以看到内部使用一个ArrayList容器容纳待写入的元素, valueTransformer 这里的就是record数据进去record数据出来,没有做什么处理!系统留下的扩展!
系统批量写入jdbc时机?
有三个他们都调用了 JdbcBatchingOutputFormat#flush
-
JdbcBatchingOutputFormat#writeRecord 写入元素时候判断批量条数达到阈值调用 -
JdbcBatchingOutputFormat#open 上面讲了open里面启动一个定时调度器会调用 -
GenericJdbcSinkFunction#snapshotState 还有一个发生checkPoint时候会调用
JdbcBatchingOutputFormat#flush 方法解析
@Override
public synchronized void flush() throws IOException {
checkFlushException();
//循环判断是否小于最大重试次数
for (int i = 1; i <= executionOptions.getMaxRetries(); i++) {
try {
//执行jdbc批量写入 然后将统计数据条数值重置为0 跳出循环结束
attemptFlush();
batchCount = 0;
break;
} catch (SQLException e) {
LOG.error("JDBC executeBatch error, retry times = {}", i, e);
if (i >= executionOptions.getMaxRetries()) {
throw new IOException(e); //如果循环次数达到最大重试次数 就抛出异常
}
try {
//验证 连接是否有效 无效会重新生成connection和PreparedStatement
if (!connection.isValid(CONNECTION_CHECK_TIMEOUT_SECONDS)) {
connection = connectionProvider.reestablishConnection();
jdbcStatementExecutor.closeStatements();
jdbcStatementExecutor.prepareStatements(connection);
}
} catch (Exception excpetion) {
LOG.error(
"JDBC connection is not valid, and reestablish connection failed.",
excpetion);
throw new IOException("Reestablish JDBC connection failed", excpetion);
}
try {
Thread.sleep(1000 * i);
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
throw new IOException(
"unable to flush; interrupted while doing another attempt",
e);
}
}
}
}
protected void attemptFlush() throws SQLException {
//这个jdbcStatementExecutor 前面说了就等于 SimpleBatchStatementExecutor
jdbcStatementExecutor.executeBatch();
}
SimpleBatchStatementExecutor#executeBatch
@Override
public void executeBatch() throws SQLException {
if (!batch.isEmpty()) {
for (V r : batch) {
parameterSetter.accept(st, r);
st.addBatch();
}
st.executeBatch();
batch.clear();
}
}
这个parameterSetter.accept(st, r) 方法就是调用我例子里面的
st = PreparedStatement r = 每一个元素
这里执行批量写入,然后清空ArrayList容器!
总结
-
JdbcExecutionOptions 可以配置 批量写入间隔时间 最大写入数量 和 异常容错次数(只支持sql异常) -
JdbcConnectionOptions 可以配置数据库的连接参数 -
关闭定时写入可以把 BatchIntervalMs设置为0 -
实时写入可以把 BatchSize 设置为1 -
间隔时间 或者 最大写入数 或者 触发检查点的时候 这三个地方 会触发写入批量写入jdbc -
未开启检查点可能会丢失数据的,开启了检查点需要保证数据库幂等性插入因为可能会重复插入!
以上是关于Flink Sink JDBC 源码分析的主要内容,如果未能解决你的问题,请参考以下文章