算法设计与分析 实验五 图论——桥
Posted 上山打老虎D
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法设计与分析 实验五 图论——桥相关的知识,希望对你有一定的参考价值。
桥
一、实验目的与要求
1、实验基本要求:
(1) 掌握图的连通性。
(2) 掌握并查集的基本原理和应用。
2、实验亮点:
(1) 实现了基准算法与高效算法
(2) 完成了基准算法与高效算法在不同数据下的比较分析。并给出合理的解释
(3) 每种算法均有清晰的算法流程图以及算法伪代码
(4) 结合理论分析,提出了更优的优化方案,进一步提高算法效率
(5) 使用了编译优化进一步降低程序的时间消耗
二、实验内容与方法
- 实现上述基准算法。
- 设计的高效算法中必须使用并查集,如有需要,可以配合使用其他任何数据结构。
- 用图2的例子验证算法正确性。
- 使用文件 mediumG.txt和largeG.txt 中的无向图测试基准算法和高效算法的性能,记录两个算法的运行时间。
- 设计的高效算法的运行时间作为评分标准之一。
- 提交程序源代码。
- 实验报告中要详细描述算法设计的思想,核心步骤,使用的数据结构。
三、实验步骤与过程
(一)基准算法
1、算法思想:
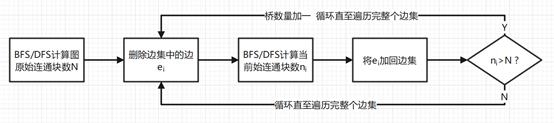
①桥的判定与查找:
根据桥的定义,我们可以知道,一条边
e
e
e是桥,当且仅当删除边
e
e
e后,图的连通块数量会增加。因此,我们很容易可以想到一种比较朴素的算法,即枚举整个边集,并依次检查在删除每条边后连通块数量是否增加即可。
②连通块的计数:
通过对数据结构课程的学习,我们可以知道,可以通过深度优先搜索(DFS)与广度优先搜索(BFS)两种方式遍历整个图,而遍历过程中调用的搜索次数即为图的连通块个数。
③具体算法实现:
a. 首先,对整张图调用DFS/BFS获取整张图的连通块个数
N
N
N
b. 遍历边集,对于每条边
e
i
e_i
ei,首先在图中删除边
e
i
e_i
ei
c. 再次调用DFS/BFS获取整张图的连通块个数
n
i
n_i
ni
d. 若
n
i
>
N
n_i>N
ni>N,则
e
i
e_i
ei为桥;若
n
i
=
N
n_i=N
ni=N,则
e
i
e_i
ei不为桥
e. 恢复
e
i
e_i
ei,在图中移除边
e
(
i
+
1
)
e_(i+1)
e(i+1),并跳转到b,直至遍历完整个边集
④算法流程图:
2、时间复杂度分析:
不妨设图中顶点个数为
n
n
n,边个数为
e
e
e。使用邻接表对边集进行遍历的时间复杂度为
O
(
e
)
O(e)
O(e)。一次 BFS 遍历需遍历所有点,时间复杂度为
O
(
n
+
e
)
O(n+e)
O(n+e)。又因为一共需要进行
e
e
e次 BFS 操作,因此算法的总时间复杂度为:
T
=
O
(
e
)
×
O
(
n
+
e
)
=
O
(
e
2
+
e
n
)
T=O(e)×O(n+e)=O(e^2+en)
T=O(e)×O(n+e)=O(e2+en)
对于稀疏图,有
e
∝
n
e∝n
e∝n,则该算法时间复杂度可表示为
O
(
n
2
)
O(n^2 )
O(n2);对于稠密图,有
e
∝
n
2
e∝n^2
e∝n2,则该算法时间复杂度可表示为
O
(
n
4
)
O(n^4 )
O(n4)。
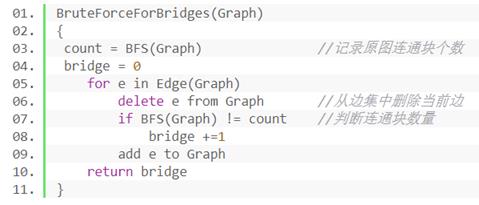
3、编程实现:
伪代码如下:
(二)高效算法
1、数据结构介绍:
(1)并查集:
①数据结构简介:
并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题。常常在使用中以森林来表示。
②常见操作:
对于并查集,常见操作有查找与合并两种操作。
查询
查询即查询当前两元素是否在同一集合中。通过递归层层向上访问,直至访问到根节点,若两元素根节点相同,则两元素在同一集合中。否则不在同一集合中。
合并
合并即将两不在同一集合中的两个子集合合并为一个集合。只需先通过查询,查询出一个集合的根节点,并修改根节点指向另一集合即可。
③路径压缩
高效算法主要利用了并查集一个很重要的特性:路径压缩。
最简单的并查集在查找上效率实际上不高,随着路径的加长,递归向上的查询深度增加导致时间消耗加大。不妨采用路径压缩的方法,把沿途的节点的父节点直接设为其根节点。这样可以大大的降低并查集查询操作过程中的递归向上的查询深度,从而在大规模数据集下极大的缩短算法在查找所用的时间。

(2)向量:
向量(vector)是一个封装了动态大小数组的顺序容器。可以简单的认为,向量是一个能够存放任意类型的动态数组,支持对序列内的任意元素进行快速直接访问(使用下标)。
vector 容器一方面可以动态的分配空间,比一般的数组更合理使用空间;另外它有很多基本函数,如push_back()函数类似队列中的push()函数,size()可以直接返回当前容器长度。因为 vector 可以更方便的使用函数调用和管理空间,高效算法构建邻接表就通过 vector 实现。
对于大数据量级下的图结构,如果使用临近矩阵进行存储,会造成内存溢出,因此也必须使用邻接表进行存储。
而且,对于本实验中探究的问题而言,需要用到dfs或bfs搜索,使用邻接表进行搜索的时间复杂度也小于使用邻接矩阵的时间复杂度。
2、引入最近公共祖先(Least Common Ancestors,LCA)
在一棵没有环的树上,除根节点外每个节点都有其父节点和祖先节点,最近公共祖先就是两个节点在这棵树上深度最大的公共祖先节点。寻找两个节点的最近公共节点即根据两个节点的深度分别向树根方向查找,当查找到第一个相同节点时,该节点即为两个节点的最近公共祖先。
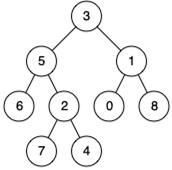
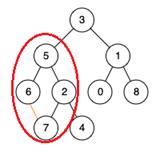
例如,对于上图中的二叉树,6与7的最近公共祖先(LCA)为5。
3、算法思想:
基准算法中,我们判断桥的方法为遍历整个边集判断是否为桥。但算法效率十分低下。不妨换种思路,使用排除法,排除所有不是桥的边,剩下的即为桥。
依据桥的定义以及图论的知识,我们可以知道,除了根据判断删除一条边后是否连通块数量增加与否的方式来判断是否为桥。我们也可以通过桥的等价意义,即,判断一条边是否在环上,进行桥的判断。再由图论知识可知,树是边数最小的无环图,并且当向树上添加任意一条顶点都在树上的边,必定会形成环。
又因为桥必定不在环上,因此除了图的生成树外上的边,其他的边一定不是桥(即桥一定存在于图的生成树上)。
基于这一想法,可以先构建生成树,再枚举不在生成树上的所有边,并根据最近公共祖(LCA)排除加入这些边后生成的环所在的边,最后剩下的边即为桥。
例如,对于如下的图,如果加入了边
(
6
,
7
)
(6,7)
(6,7)则
{
2
,
5
,
6
,
7
}
\\{2,5,6,7\\}
{2,5,6,7}成环,则
(
2
,
5
)
,
(
2
,
7
)
,
(
5
,
6
)
,
(
6
,
7
)
(2,5),(2,7),(5,6),(6,7)
(2,5),(2,7),(5,6),(6,7)一定不为桥。
4、算法实现:
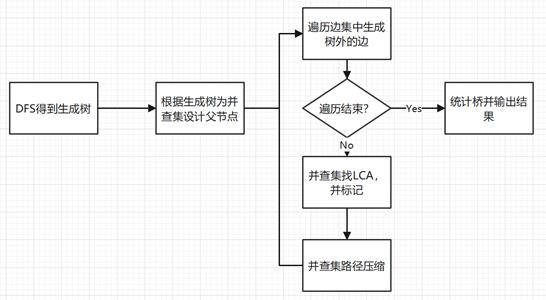
本算法的实现主要分成三大核心部分:生成树的构建,环的搜索与桥的标记与路径压缩。下面进行一一介绍:
①生成树的构建:
图的生成树的构建可以先使用 DFS 遍历,并在DFS 遍历时根据得到的生成树中边前驱与后继的关系为并查集设置好各个节点的父节点。
②环的搜索与桥的标记:
在LCA示意图中,最底层顶点的祖先有很多,树根事实上也是所有点的祖先,但是当两个顶点向上经过的边被共同经过了两次,这条边就不一定是桥(如下图)。
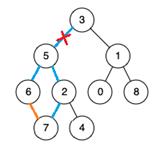
因此我们需要引入最近公共祖先来保证向上寻找祖先时每条边只被经过一次。并将这些在环中的边标记为非桥即可。因为已经得到了生成树,对边的标记可以通过对点数组的操作来实现。
③路径压缩:
在②中向上递归查找最近公共祖先(LCA)时,我们不难发现,对于一些递归深度比较深的节点,需要多次递归才能找到最近公共祖先(LCA),并且,对于一些层数比较深的节点而言,在递归过程中需要沿着其父节点(或祖父节点,祖祖父节点…)的递归路径进行递归,这些路径都是完全一样的,从而造成了很多无用的向上递归。因此,可以借助并查集对路径进行压缩,降低层数比较深的节点的最近公共祖先(LCA)递归时间。
即,我们可以将已经确定不是桥的边在并查集中的父节点直接设置为它的最近公共祖先(LCA)。这部分不会对后续桥判断的正确性产生任何影响,但会大大提高搜索的效率。将这些后继节点的父节点都设置为最近公共祖先(LCA),代表将这些边压缩。当对其他边向上递归搜索最近公共祖先(LCA)时,可以直接获取结果。通过并查集进行路径压缩大大提高了搜索的效率。
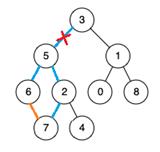
仍然以LCA的示意图为例,当在图中加入边
(
6
,
7
)
(6,7)
(6,7)时,
(
2
,
5
)
,
(
2
,
7
)
,
(
5
,
6
)
,
(
6
,
7
)
(2,5),(2,7),(5,6),(6,7)
(2,5),(2,7),(5,6),(6,7)一定不为桥。并且可以直接将7节点的父节点,直接设置为他的最近公共祖先(LCA)即5。故当再次递归向上查找某节点的最近公共祖先(LCA)时,如果经过了7节点,可以直接获得答案5,而避免递归经过
(
2
,
7
)
,
(
2
,
5
)
(2,7),(2,5)
(2,7),(2,5)这两条边。路径得到压缩,算法得到优化。
④算法流程图:
5、时间复杂度分析:
不妨设图中顶点个数为
n
n
n,边个数为
e
e
e,DFS构建生成树时间复杂度为
O
(
n
+
e
)
O(n+e)
O(n+e),为并查集设置父节点时间复杂度为
O
(
n
)
O(n)
O(n) ;一次查找最近公共祖先最差情况下要查找n次,时间复杂度为
O
(
n
)
O(n)
O(n) ,一次路径压缩最差情况与查找对应,时间复杂度也为
O
(
n
)
O(n)
O(n) 。总共需要执行(
e
−
n
0
e-n_0
e−n0)次查找(
n
0
n_0
n0为生成树边数)),因此算法的总时间复杂度为:
T
=
O
(
n
+
e
)
+
O
(
n
)
+
(
e
−
n
0
)
×
O
(
n
)
=
O
(
e
n
)
T=O(n+e)+O(n)+(e-n_0 )×O(n)=O(en)
T=O(n+e)+O(n)+(e−n0)×O(n)=O(en)
与基准算法相比,一次查找公共祖先只需
O
(
n
)
O(n)
O(n),而基准算法中一次 BFS 需要
O
(
n
+
e
)
O(n+e)
O(n+e),因此与基准算法相比,新的算法执行e次查找降低了
e
×
O
(
e
)
e×O(e)
e×O(e) ,即没有了
O
(
e
2
)
O(e^2 )
O(e2)项的时间复杂度,时间优化十分显著。
此外,查找的时间复杂度O(n)是最差情况,对于大数据量级下的查找操作,经过并查集的路径压缩,很快需要查找的节点基本上父节点大部分都已经被设置为最近公共祖先(LCA)。此时,查找的时间会接近
O
(
1
)
O(1)
O(1)。此时有
lim n → ∞ T = O ( e ) \\lim\\limits_{n\\rightarrow\\infty}T=O(e) n→∞limT=O(e)
即对于大数据下的总时间复杂度会十分趋近于 O ( e ) O(e) O(e)。即算法的时间效率得到了极大提升。
6、编程实现:
伪代码如下:
(1)首先进行深度优先搜索
①首先对单个连通块进行深度优先搜索
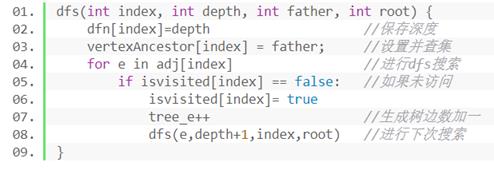
②对整个图进行搜索(利用每个连通块搜索出的森林):
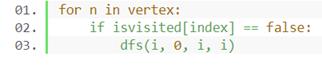
(2)求解最近公共祖先(LCA):

(3)路径压缩:

(三)正确性验证
算法的正确性是算法优化的前提条件,也是必备条件。本题中,使用随机数生成器,并借助哈希函数避免成环的方式,生成了 1 0 4 10^4 104组大小为 1 0 3 10^3 103的稀疏图和稠密图测试数据。经过验证高效算法与基础算法的结果完全一致,这证明,高效算法是正确的。
(四)时间效率对比分析
1、给定数据下时间效率:
①mediumDG.txt:
顶点数:50 边数:147
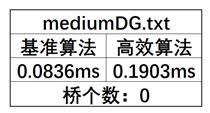
可以看到,对于小数量级的数据,基准算法要比高效算法更快,这是因为在小数据量级下,高效算法中的并查集路径压缩优化并不明显。并且高效算法中使用了大量的STL容器,导致程序有更长的运行时间。
②largeG.txt
顶点数:1000000 边数:7586063
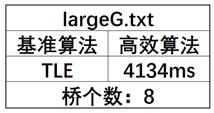
具体结果如下:
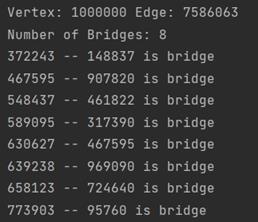
可以看到,对于大数量级的数据,高效算法有很高的效率,这是因为在大数据量级下,高效算法中的并查集路径压缩优化很明显,大幅降低了程序运行的时间。
2、随机数据下的时间效率:
为了保证生成的数据中没有环边,我使用哈希函数完成重边的去除。
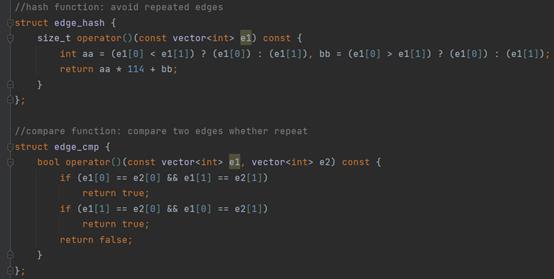
生成多组随机数据,每组数据运行20次并取平均值后做表作图如下:
【稀疏图】

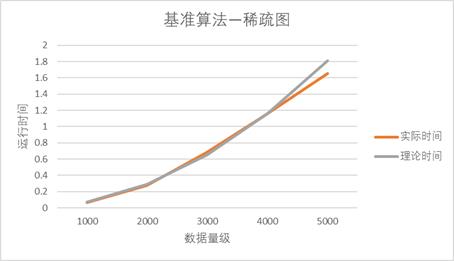
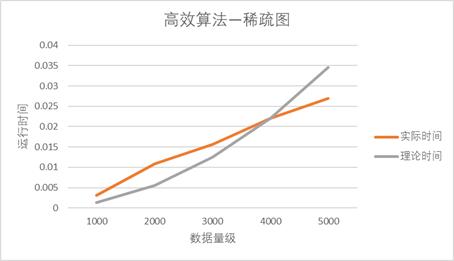
可以看到,对于稀疏图而言,基准算法的时间拟合效果比较好,这是因为基准法在不同数据量级下运行时运行步骤完全一样。因此理论与实际相差不大。
但对于高效算法而言,拟合效果比较差,这是因为高效算法在不用数据量级下,不同测试数据下,算法效率可能不同。并且从图中观察,也可以发现,小数据下的高效算法的实际运行时间比理论时间长,大数据下的高
以上是关于算法设计与分析 实验五 图论——桥的主要内容,如果未能解决你的问题,请参考以下文章