层次3 DCGAN动漫图像生成
Posted ZHW_AI课题组
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了层次3 DCGAN动漫图像生成相关的知识,希望对你有一定的参考价值。
层次3 DCGAN动漫图像生成
作者介绍
张伟伟,男,西安工程大学电子信息学院,2019级硕士研究生,张宏伟人工智能课题组。
研究方向:机器视觉与人工智能。
电子邮件:2430290933@qq.com
项目简介
随着二次元文化逐渐走进大众视野,各种动漫作品所塑造的角色已经成为一种特殊的文化符号。但是,由于动漫本身复杂的性质,其对于制作成本,质量,创意都有较高的要求,导致动漫行业频频出现投入高,收益低的现象。由于生成对抗网络(GAN)在图像生成领域和视频生成领域具有巨大的发展潜力,许多研究者尝试从GAN入手,实现动漫图像的自动生成,为创作者带来了灵感,还节省了巨额创作开支。生成对抗网络(GAN)的理念由Goodfellow于2014年提出的,它的发展历程只有七年,却对人工智领域带来了极大的冲击,是目前火热的研究方向之一。
运行环境
程序可自动判断是使用GPU版本运行还是GPU运行。
电脑:windows10
处理器:Intel® Core™ i7-4702HQ CPU @ 2.20GHz 2.20 GHz
显卡:NVIDIA GTX950
内存:16G
pytorch版本:pytorch1.1.0
python版本:python3.6
程序运行内存占用:10G(可根据电脑配置调整batchsize大小调整内存占用)
程序运行时间:epoch =25 耗时30分钟左右
本教程需要提前在以前教程配置的环境中安装的包:
pip install opencv-python
GAN简介
论文参考:
-
-
2015年《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》.
GAN的应用
GAN是一种无监督生成模型,可以被用来生成图像、音频,图像转换,图像翻译,风格迁移等等。
图像转换

图像翻译

图像超分辨

风格迁移

GAN的原理
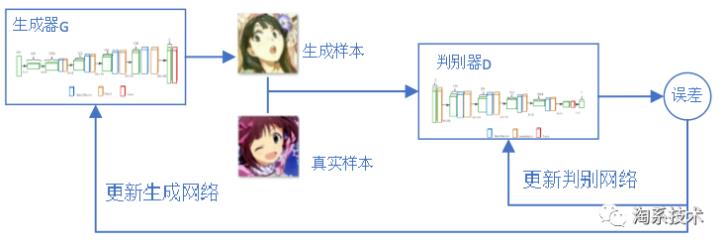
GAN网络全称generative adversarial network,翻译为生成式对抗网络,是一种机器学习方法。其中在GAN网络中,有两个模型——生成模型( generative model G),判别模型(discriminative model D)。GAN的主要灵感来源于博弈论中零和博弈的思想,对于神经网络而言就是通过生成网络G(Generator)和判别网络D(Discriminator)不断博弈主要目的是学习真实世界的真实数据的分布,用于创造以假乱真的数据。下图为GAN的简单图示:
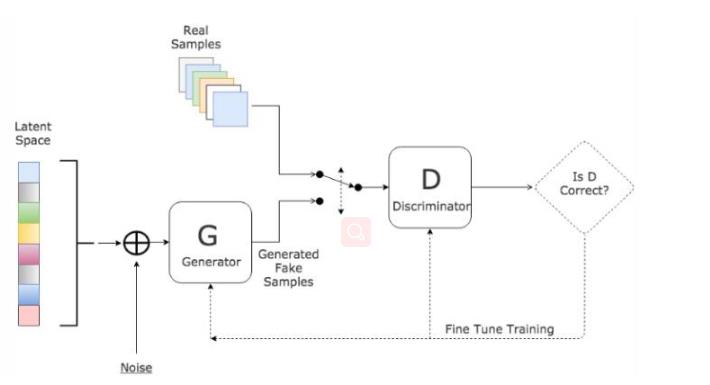
- G是一个生成式的网络,它接收一个随机的噪声z(随机数),通过这个噪声生成图像。
- D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
- 训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量辨别出G生成的假图像和真实的图像。这样,G和D构成了一个动态的“博弈过程”,最终的平衡点即纳什均衡点。
GAN的特点
GAN采用的是一种无监督的学习方式训练,相比其他所有模型, GAN可以产生更加清晰,真实的样本;相比较传统的模型,他存在两个不同的网络,而不是单一的网络,并且训练方式采用的是对抗训练方式(比如图片风格迁移,超分辨率,图像补全,去噪,避免了损失函数设计的困难)。但是,训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.我们还没有找到很好的达到纳什均衡的方法,GAN存在训练不稳定、梯度消失、模式崩溃的问题(目前发展已经有各种避免的方法)
DCGAN简介
DCGAN将GAN与CNN相结合,奠定后几乎所有GAN的基本网络架构。DCGAN极大地提升了原始GAN训练的稳定性以及生成结果质量。
相比于GAN的改进:
(1)使用卷积和去卷积代替池化层
(2)在生成器和判别器中都添加了批量归一化操作
(3)去掉了全连接层,使用全局池化层替代
(4)生成器的输出层使用Tanh 激活函数,其他层使用RELU
(5)判别器的所有层都是用LeakyReLU 激活函数
DCGAN网络结构
生成器网络结构
如下图,噪声Z(维度为100)传入网络之后,经过全连接变成维度16384,接着reshape成441024(441024 = 16384)的特征图。
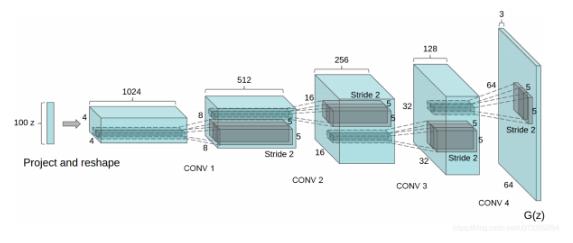
DCGAN 的判别器和生成器都使用了卷积神经网络(CNN)来替代GAN 中的多层感知机。
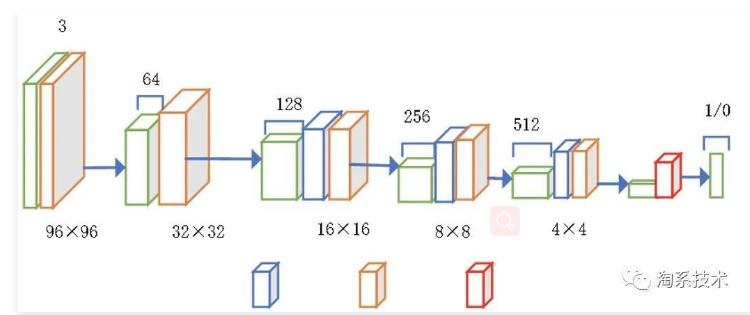
判别器网络结构
DCGAN损失函数
GAN的损失函数:
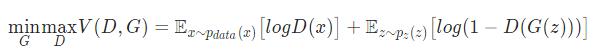
损失函数是一种非负实数函数,可以评估模型的预测值与真实值不一致的程度。两者差距减少,概率分布越接近,差距增加,概率差异越高,在Pytorch中可以通过导入torch.nn包来使用。Pytorch中提供许多损失函数,每一种函数都有其特性,例如:MSELoss是一种均方误差损失函数,使用梯度下降算法,一般常用于解决股票预测、房价预测等回归类问题;SmoothL1Loss是一种稳定的损失函数,也被用于解决回归问题,它的函数曲线光滑可以避免梯度爆炸的问题;BCELoss是CrossEntropyLoss的一个特例,常用于解决分类问题。在本课题中我们需要,判断样本的输出是真实图片还是生成图片,所以本课题选择BCELoss作为损失函数,它在 PyTorch 中的定义如公式2.1所示:
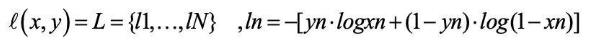
DCGAN的训练和超参数
- 算法流程

- 训练
- 训练步骤
- 更新判别器网络的时候,不更新生成器网络,更新生成器网络的时候,不更新判别器网络
- 生成器网络就是不断的学习将噪声(噪声是一个固定分布,比如正态分布,或者高斯分布)转化图片,这样以来,我们在生成图片的时候,只需取同样的分布就可以生成图片
- 训练超参数
批大小:batch_size = 10
学习率:learning_rate = 0.0002
噪声维度: nz = [batch_size,100,1,1]
训练次数:epoch = 25
Adam:beta1 = 0.5 ---- beta2 =0.999 - 训练所使用的的优化器
在DCGAN的训练过程中,可以通过优化器最小化损失函数,一般分为一阶优化算法和二阶优化算法。本课题选用Adam优化程序调整超参数,它结合了 AdaGrad 和 RMSProp 算法最优的性能,不仅可以计算每个参数的自适应学习率,还可以通过训练数据的不断迭代使网络权重自动更新,相较于其他几种算法而言Adam算法实现简单、对计算机资源占用率较低,收敛速度也更快。
Adam算法有一些重要参数,其中params表示用于优化的可以迭代参数或定义参数组;lr表示学习率,可以调节权重的更新比例,影响网络的收敛速度,在Pytorch源码中定义如下:
torch.optim.Adam(params,lr=a,betas=(b,c),eps=d, weight_decay=e)
DCGAN生成动漫图像的代码实现
DCGAN生成动漫图片的主要流程
从一维的噪声向量z经过生成器生成的 “假样本” 与数据集中 “真样本“” 输入判别器中,判别器首先计算D_loss,先更新判别器参数,然后计算G_loss,用于更新生成器参数。误差损失函数采用BCE损失函数,使用Adam优化器更新判别器和生成器的网络参数。
数据集概述
本教程将选取了一部分动漫数据集(下文中有代码和选取的部分数据集的链接)(原数据集共51223张图片),原数据集百度网盘链接,提取码2021.
截取后的数据集(已包含在项目文件中)大小为15.5M,约2000张动漫图片(真样本),图片的分辨率为3 * 96 * 96(CHW.使用标准的DCGAN网络结构。以下为训练集的部分图片:
例如,我的训练集路径为:D:/DCGAN/smalldata/,后续会用到。
本实验考虑到计算资源的问题,采用了2000张图片作为训练集,测试时产生100张漫画图片。训练轮数为25轮(epoch = 25),电脑配置为NVIDIA GTX 950,使用GPU版本的Pytorch进行训练,训练耗时30分钟,内存占用10G(根据电脑配置情况,可以调整batch_size大小降低内存占用),测试时生成图片2s 左右。
数据集和代码的百度网盘链接(约10M): https://pan.baidu.com/s/1GDZCfEYAQSAtRa84xwmZ7Q
提取码:2021
各个层级目录的作用:
bitmaps_epoch25----保存测试时生成的图片目录
smalldata---------------数据集存放的文件夹
pkl -----------------------权值文件保存目录
data_helper.py--------训练时读取文件目录,此文件主要需要修改数据集文件目录
train.py -----------------训练程序
test.py-------------------测试程序
程序中有详细的注释说明,需要修改的主要是一些路径,路径尽量使用反斜杠(/)。这里将含有程序的三个文件train.py 和test.py和data_helper.py在博客中展示:
train.py
import torch
import torch.nn as nn
import numpy as np
import torch.nn.init as init
import data_helper
from torchvision import transforms
import time
import os
import cv2
# 需要修改的地方:权值文件存放的路径改为自己想存放的路径,例如放在与train.py同级目录的pkl_new(新建)文件夹中
pkl_dir = "./pkl_new/"
if not os.path.exists(pkl_dir): os.makedirs(pkl_dir)
# 需要修改的地方:数据集文件路径 data_helper.py中的解压后的数据集路径
#程序自动判断是使用GPU还是CPU设备
device = torch.device("cuda:0" if (torch.cuda.is_available()) else "cpu")
trans = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((.5, .5, .5), (.5, .5, .5))
]
)
# 本教程中需要修改的超参数
G_LR = 0.0002 #生成器的学习率
D_LR = 0.0002 #判别器的学习率
BATCHSIZE = 10 #batch_size的大小,可根据电脑内存进行修改
EPOCHES = 25 #训练次数(epoch)的数目
#使用正态分布初始化权重参数
def init_ws_bs(m):
if isinstance(m, nn.ConvTranspose2d):
init.normal_(m.weight.data, std=0.2)
init.normal_(m.bias.data, std=0.2)
#定义生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.deconv1 = nn.Sequential(
nn.ConvTranspose2d( # stride(input_w-1)+k-2*Padding
in_channels=100,
out_channels=64 * 8,
kernel_size=4,
stride=1,
padding=0,
bias=False,
),
nn.BatchNorm2d(64 * 8),
nn.ReLU(inplace=True),
)
self.deconv2 = nn.Sequential(
nn.ConvTranspose2d( # stride(input_w-1)+k-2*Padding
in_channels=64 * 8,
out_channels=64 * 4,
kernel_size=4,
stride=2,
padding=1,
bias=False,
),
nn.BatchNorm2d(64 * 4),
nn.ReLU(inplace=True),
)
self.deconv3 = nn.Sequential(
nn.ConvTranspose2d( # stride(input_w-1)+k-2*Padding
in_channels=64 * 4,
out_channels=64 * 2,
kernel_size=4,
stride=2,
padding=1,
bias=False,
),
nn.BatchNorm2d(64 * 2),
nn.ReLU(inplace=True),
)
self.deconv4 = nn.Sequential(
nn.ConvTranspose2d( # stride(input_w-1)+k-2*Padding
in_channels=64 * 2,
out_channels=64 * 1,
kernel_size=4,
stride=2,
padding=1,
bias=False,
),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
)
self.deconv5 = nn.Sequential(
nn.ConvTranspose2d(64, 3, 5, 3, 1, bias=False),
nn.Tanh(),
)
def forward(self, x):
x = self.deconv1(x)
x = self.deconv2(x)
x = self.deconv3(x)
x = self.deconv4(x)
x = self.deconv5(x)
return x
#定义判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d( # batchsize,3,96,96
in_channels=3,
out_channels=64,
kernel_size=5,
padding=1,
stride=3,
bias=False,
),
nn.BatchNorm2d(64),
nn.LeakyReLU(.2, inplace=True),
)
self.conv2 = nn.Sequential(
nn.Conv2d(64, 64 * 2, 4, 2, 1, bias=False, ), # batchsize,16,32,32
nn.BatchNorm2d(64 * 2),
nn.LeakyReLU(.2, inplace=True),
)
self.conv3 = nn.Sequential(
nn.Conv2d(64 * 2, 64 * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.LeakyReLU(.2, inplace=True),
)
self.conv4 = nn.Sequential(
nn.Conv2d(64 * 4, 64 * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 8),
nn.LeakyReLU(.2, inplace=True),
)
self.output = nn.Sequential(
nn.Conv2d(64 * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid() #
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.output(x)
return x
#将生成器和判别器进行实例化并将其放如GPU/CPU中
g = Generator().to(device)
d = Discriminator().to(device)
#初始化权重参数
init_ws_bs(g), init_ws_bs(d)
#定义优化器
g_optimizer = torch.optim.Adam(g.parameters(), betas=(.5, 0.999), lr=G_LR)
d_optimizer = torch.optim.Adam(d.parameters(), betas=(.5, 0.999), lr=D_LR)
#定义损失函数,使用BCE_loss
g_loss_func = nn.BCELoss()
d_loss_func = nn.BCELoss()
#产生标签
label_real = torch.ones(BATCHSIZE).to(device)
label_fake = torch.zeros(BATCHSIZE).to(device)
#得到训练数据的图片
real_img = data_helper.get_imgs()
print("数据集的图片数目:",len(real_img))
#计算程序运行时间
torch.cuda.synchronize()
start = time.time()
#开始训练
for epoch in range(EPOCHES):
# np.random.shuffle(real_img)
count = 0
batch_imgs = []
for i in range(1000): #注意,此处相当于选取了1000张图片作为训练数据集
count = count + 1
batch_imgs.append(trans(real_img[i]).numpy()) # tensor类型#这里经过trans操作通道维度从第四个到第二个了
if count == BATCHSIZE:
count = 0
#真样本转化为张量
batch_real = torch.Tensor(batch_imgs).to(device)
batch_imgs.clear()
d_optimizer.zero_grad()
pre_real = d(batch_real).squeeze()
d_real_loss = d_loss_func(pre_real, label_real)
d_real_loss.backward()
#假样本转化为张量
batch_fake = torch.randn(BATCHSIZE, 100, 1, 1).to(device)
img_fake = g(batch_fake).detach()
pre_fake = d(img_fake).squeeze()
d_fake_loss = d_loss_func(pre_fake, label_fake)
d_fake_loss.backward()
#首先,判别器进行梯度更新
d_optimizer.step()
#其次,生成器进行梯度更新
g_optimizer.zero_grad()
batch_fake = torch.randn(BATCHSIZE, 100, 1, 1).to(device)
img_fake = g(batch_fake)
pre_fake = d(img_fake).squeeze()
g_loss = g_loss_func(pre_fake, label_real)
g_loss.backward()
g_optimizer.step()
#打印出LOSS结果
print("epoch: {} \\t imgnum:{} \\t D_loss:{} \\t G_loss:{} \\t".format(epoch,i, \\
(d_real_loss + d_fake_loss).detach().cpu().numpy(), g_loss.detach().cpu().numpy()))
#保存模型的权值文件------------------【权值文件路径需要修改】--------------
torch.save(g, pkl_dir + str(epoch) + "g.pkl")
if(epoch == 0 ):
print("每个enpoch运行时间:", time.time() - start)
print("预估总运行时间(min):", ((time.time() - start) * EPOCHES)/60)
test.py
import torch.nn as nn
import torch
import cv2
import os
# 路径改为反斜杠,在linux和windows中都可使用
pkl_dir = "D:/DCGAN/pkl/25g.pkl"
# 在同目录下建立一个bitmap_epoch10文件夹
test_dir = "bitmaps_epoch10/"
if not os.path.exists(test_dir): os.makedirs(test_dir)
device = torch.device("cuda:0" if (torch.cuda.is_available()) else "cpu")
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.deconv1 = nn.Sequential(
nn.ConvTranspose2d( # stride(input_w-1)+k-2*Padding
in_channels=100,
out_channels=64 * 8,
kernel_size=4,
stride=1,
padding=0,
bias=False,
),
nn.BatchNorm2d(64 * 8),
nn.ReLU(inplace=True),
) # 14
self.deconv2 = nn.Sequential(
nn.ConvTranspose2d( # stride(input_w-1)+k-2*Padding
in_channels=64 * 8,
out_channels=64 * 4,
kernel_size=4,
stride=2,
padding=1,
bias=False,
),
nn.BatchNorm2d(64 * 4),
nn.ReLU(inplace=True),
) # 24
self.deconv3 = nn.Sequential(
nn.ConvTranspose2d( # stride(input_w-1)+k-2*Padding
in_channels=64 * 4,
out_channels=64 * 2,
kernel_size=4,
stride=2,
padding以上是关于层次3 DCGAN动漫图像生成的主要内容,如果未能解决你的问题,请参考以下文章