张伟伟-层次2 利用百度API进行通用文字识别
Posted ZHW_AI课题组
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了张伟伟-层次2 利用百度API进行通用文字识别相关的知识,希望对你有一定的参考价值。
作者介绍
张伟伟,男,西安工程大学电子信息学院,2019级硕士研究生,张宏伟人工智能课题组。
研究方向:机器视觉与人工智能。
电子邮件:2430290933@qq.com
API介绍
配置环境
pip install baidu-aip
支持多种语种识别(丹麦语、荷兰语、马来语、瑞典语、印尼语、波兰语、罗马尼亚语、土耳其语、希腊语、匈牙利语),并将字库从1w+扩展到2w+,能识别所有常用字和大部分生僻字。
调用过程
- 1.首先打开百度智能云官网注册登录。
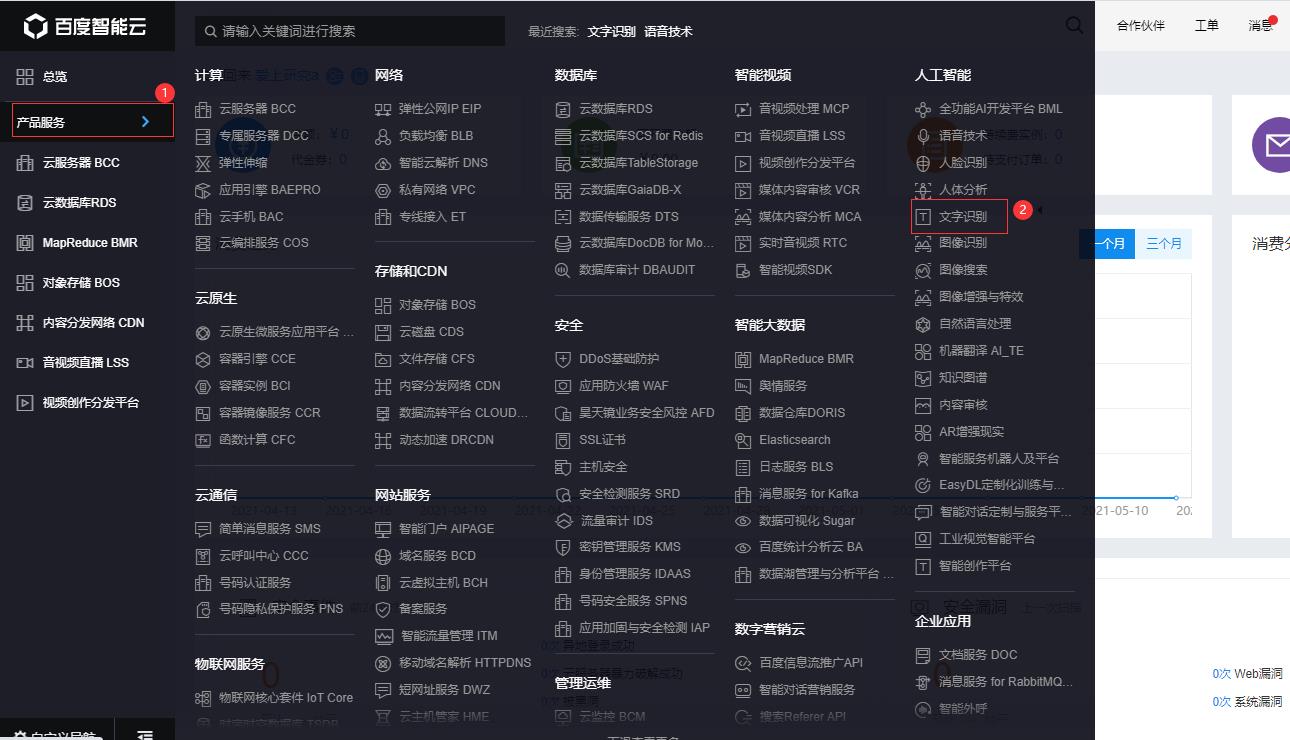
- 2 登录之后选择文字识别服务
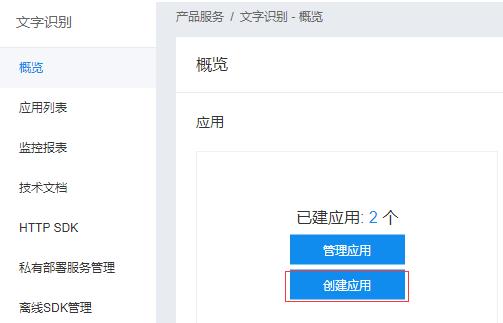
- 3 点击创建应用
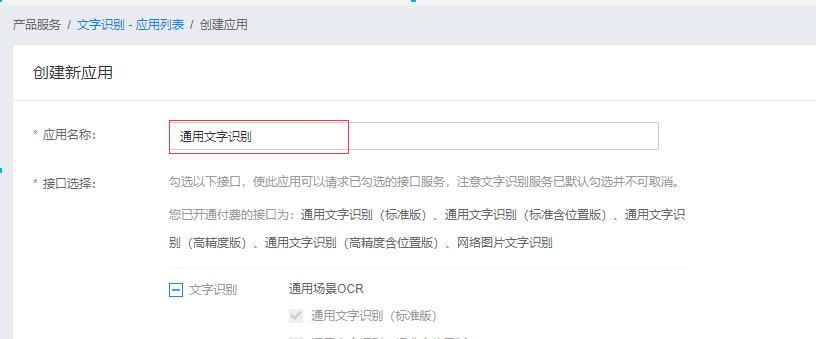
- 4 创建并填写应用相关信息
例如,填写应用名称为“通用文字识别”。
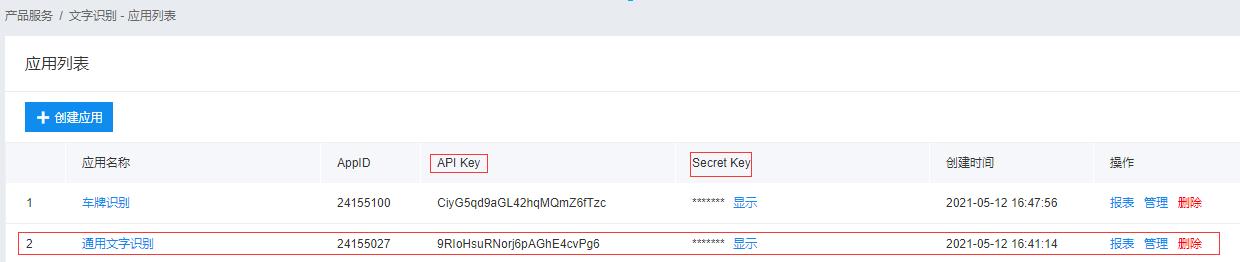
- 5 应用相关信息填写完成后点击“返回应用列表”,即可查看已创建好的应用,得到API Key 与Secret Key。
代码实现
使用如下代码,例如建立名为Text_me.py。使用示例代码前,请记得替换其中的API Key 与Secret Key。代码中os.chdir(“D:/wenzi/testdir”) ,需要改为自己识别图片的目录。例如博主转换的图片目录为"D:/wenzi/testdir"。
#-*- coding: UTF-8 -*-
#前提是python已安装aip库--》pip install baidu-aip
import os
from aip import AipOcr
import json
# APP_ID = '你注册账号创建应用后得到的APPID'
# API_KEY = '你注册账号创建应用后得到的API_KEY'
# SECRET_KEY = '你注册账号创建应用后得到的SECRET_KEY '
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
aipOcr = AipOcr(APP_ID, API_KEY, SECRET_KEY)
os.chdir("D:/wenzi/testdir") #你需要转换的图片目录
dirs = os.listdir()
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
options = {}
options["language_type"] = "CHN_ENG"
options["detect_direction"] = "true"
options["detect_language"] = "true"
options["probability"] = "true"
print('开始处理,共'+str(len(dirs))+"张图片。")
flag=0
T = 0 #统计处理图片成功的数量
for filePath in dirs:
if filePath.split('.')[-1]=='txt':continue
flag+=1
print('正在处理第'+str(flag)+'张图片')
try:
result = aipOcr.basicGeneral(get_file_content(filePath), options)
except BaseException as e:
print(e)
else:
try:
with open(filePath.split('.')[0]+'.txt','w',encoding='utf-8') as f:
for i in result['words_result']:
f.write(i['words']+'\\n')
T += 1
except BaseException as e :
print(e)
else:
print('处理完成')
print('{}全部处理完成!{}'.format("="*30,"="*30))
print('处理成功的图片有{}张,处理失败的图片有{}张'.format(T,len(dirs)-T))
运行和识别结果
- 运行结果
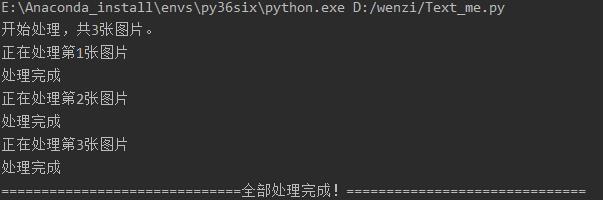
- 识别结果
例如,一次可以处理多张有文字的图片,我们无法复制,可以使用此方法实现一种OCR的效果,并且可以识别各种图片的信息,车票等写入Text文件中。一下展示部分识别结果:
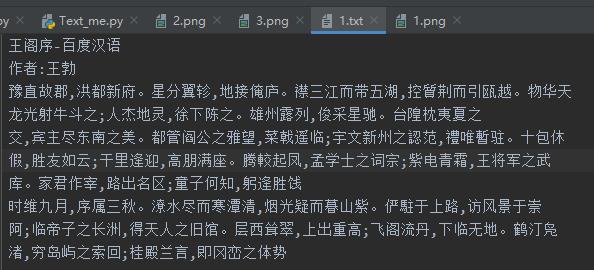
- 待识别的图片1

- 识别为text文本的结果。
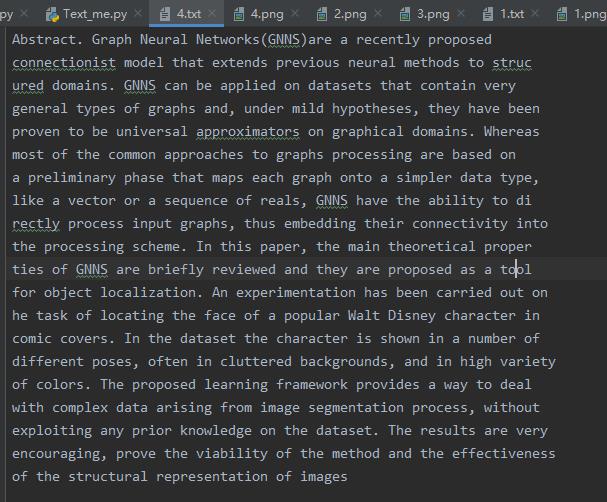
- 待识别的图片2

- 识别为text文本的结果。
以上是关于张伟伟-层次2 利用百度API进行通用文字识别的主要内容,如果未能解决你的问题,请参考以下文章