Paddle-Mobile 百度嵌入式深度学习框架
Posted 陈不2
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Paddle-Mobile 百度嵌入式深度学习框架相关的知识,希望对你有一定的参考价值。
本篇内容介绍嵌入式深度学习的应用场景、Paddle-Mobile的特性优势以及使用开发方法,预计阅读时间4分钟
嵌入式深度学习有哪些应用
深度学习技术已经在互联网的诸多方向产生影响,关于深度学习和神经网络的讨论越来越多。深度学习技术在近几年得到飞速发展,各种互联网产品都争相应用深度学习技术,产品对深度学习的引入也更进一步地影响人们的生活。随着移动设备被广泛使用,在移动互联网产品应用深度学习和神经网络技术已经成为必然趋势。在移动端应用深度学习技术能够做出哪些惊艳的体验,是值得大家关注的首要问题。接下来我们来看下图像搜索中的一个功能,实时翻译。
实时翻译
打开简单搜索APP里左下角的图像搜索,设置好限定翻译垂类和语种,只要用手机对准想要翻译的文字的场景,就能够实时地给出翻译结果,并且将翻译结果完美地融合到你所看到的场景中。我们可以看到翻译结果的字体颜色以及贴图的背景色,都与真实场景是完全一致的。同时,即使你的手机移动或抖动,你所看到的整个融合后的翻译结果也依然是稳定的。
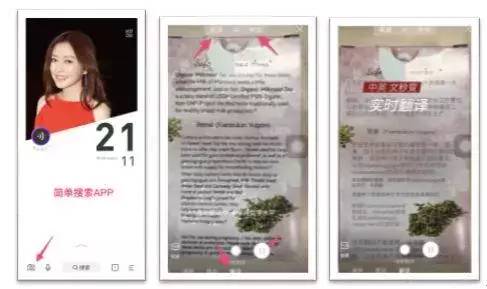
这个功能就应用到了前面提到的移动端深度学习技术,当然也用到了很多的计算机视觉相关技术,包括tracking、背景色处理等功能。
技术实现:第一点就是需要对文字进行背景色和前景色的提取,这里的颜色用来对翻译结果进行渲染,增强现实感;第二点就是提取文字区域的角点并进行光流追踪,这一步主要是用来实时更新翻译结果贴图的位置信息,随着手机移动,我们需要让翻译结果贴图始终贴合在他应该出现的位置。这里除了需要更新位置信息,我们还需要对翻译结果贴图进行透视变换,因为我们手机还会有旋转以及三维坐标系上各种角度的变化,这一步的透视变换就是为了得到一个透视变换矩阵,然后作用于翻译贴图,让贴图有同样的角度变化,大大增强了现实感。第三点就是对识别到的文字进行翻译,获取翻译结果。
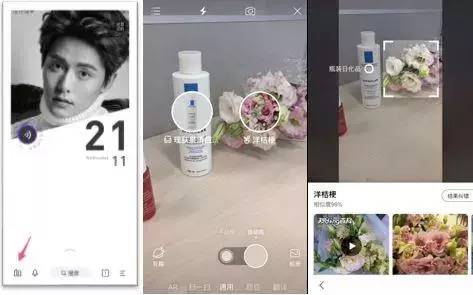
视频流式搜索
这一功能基于业界首创的本地“多目标识别+粗分类识别”相结合的实时识别模型,第一次大规模使用移动端GPU进行深度学习计算。目前简单搜索的ios端已经可以体验,2018年底将会上线百度APP的android版。
实时检测取景框内的多个主体,并通过毫秒级响应的粗分类识别能力,快速告知用户各主体粗分类,从而帮助用户快速筛选拟识别主体。在出现识别结果后会标记多个目标,用户点击任何一个目标后都会快速出现搜索结果。
移动端深度学习遇到的问题
相比PC端,移动端设备的运算能力通常比较弱小,并且由于移动端的CPU需要将功耗指标维持在很低的水平,给性能指标的提升带来了制约。
Paddle-Mobile作为百度深度学习平台PaddlePaddle下的子项目,致力于嵌入式平台的深度学习预测。训练任务由 PaddlePaddle 在服务器端进行,Paddle-Mobile则破除深度学习落地嵌入式移动端平台的障碍。
Paddle-Mobile设计和PaddlePaddle保持了高度一致,能够直接运行PaddlePaddle新版训练的模型。同时针对嵌入式平台做了大量优化。嵌入式平台计算资源有限,体积敏感,用户过程中更加要求实时,所以我们必须针对各种嵌入式平台挖掘极限性能。
Paddle-Mobile的优势
目前支持 Linux-arm,IOS,Android,DuerOS 平台的编译和部署。它的最上层是一套非常简洁的预测 API,服务于百度众多 APP。
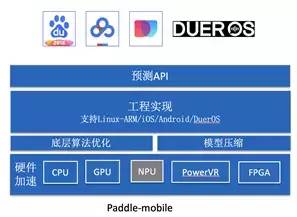
我们来看一下Paddle-Mobile 的架构。首先是底层针对各种硬件平台的优化,包括 CPU(主要是移动端的 ARM CPU), GPU (包括 ARM的Mali,高通的Andreno以及苹果自研的GPU),另外还有华为的NPU,powerVR,FPGA 等平台。 NPU 目前仍在合作中,未来会直接支持。在这一层,我们会针对各种平台实现优化后的算子,也称为 kernel,他们负责最底层的运算。
算法优化与模型压缩
算法优化包括降低算法本身复杂度,比如某些条件下的卷积操作,可以使用复杂度更低的 Winograd 算法,以及我们后面会提到的kernel融合等思想。
为了带来更高的计算性能和吞吐,端芯片通常会提供低位宽的定点计算能力。目前Paddle-Mobile已初步具备在ARM CPU上进行8bit定点预测的功能,在我们测试的模型中8bit定点通常会带来20%~50%的性能提升。
多软硬件覆盖
目前Paddle-Mobile已经实现和进行中的能力如下
1.ARM CPU
ARM CPU计算深度学习任务是最基本通用的技术,使用也较为广泛。但是由于CPU计算能力相对偏弱,还要承担主线程的UI绘制工作,在APP中使用CPU计算深度学习计算任务压力较大。我们针对ARM CPU做了大量优化工作,但是随着硬件不断发展未来专有AI芯片和GPU将更加适合做这项任务。
2.IOS GPU
IOS GPU使用metal支持直接编写,支持的系统范围向下到了IOS 9。这比coreml支持的范围有所扩大。目前该代码也已全面开放在Github。
3.Mali GPU
Mali GPU在华为等主流机型中广泛存在,我们使用了OpenCL对Mali GPU做了Paddle模型支持。在较高端的Mali GPU上已经可以得到非常高的性能。
4.Andreno GPU
Andreno GPU是高通设计的端侧GPU,同样基于OpenCL对其进行了优化实现。其高性能、低功耗的优势在Paddle-Mobile框架运行时得到了验证。
5.FPGA ZU系列
该项工作代码已经可以运行,在Github同样可以找到相关代码。对于ZU9和ZU5等开发板完全支持。FPGA的计算能力较强,深度学习功能可以在Github找到,感兴趣的工程师们可以去了解。
6.H5网页版深度学习支持
Paddle-Mobile正在实现底层基于WebGL的网页版深度学习框架。我们使用了ES6。后续会使用WebAssembly和WebGL并行融合的设计,在性能上进一步提高。该功能近期也会在Github开源,欢迎关注。
7.树莓派、RK3399等开发板
树莓派、RK3399系列等硬件在开发者中被大量用及,Paddle-Mobile同样做了支持,解决了很多问题,目前在其平台上的cpu版本一键编译即可完美运行。
体积小
Paddle-Mobile从设计之初就深入考虑到移动端的包体积的问题,cpu实现中没有外部依赖。
在编译过程中,如果该网络不需要的op是完全不会被打入的。同时编译选项优化也为体积压缩提供了帮助。Protobuf是主流框架使用的格式协议,如果放弃对Protobuf支持将给开发者带来转换模型的工作量,于是Paddle-Mobile团队将Protobuf生成文件重新精简逐行重写,拿到了一个只有几十k增长的protobuf体积。为开发者带来了一键运行的可行能力。
除了二进制体积,我们对代码体积极力避免过大,整个仓库的代码体积也非常小。
高性能CPU优化
针对 ARM CPU,我们会使用 ARM 汇编来实现 kernel 计算。在卷积神经网络中,卷积操作是耗时占比最大的部分,可能会占80%到0%。而卷积操作通常可以转化为两个矩阵的乘法,如何来优化通用矩阵乘法GEMM就是成为了关键中的关键。
Paddle-Mobile主要使用了以下技术
SIMD NEON优化技术
片上缓存命中优化
矩阵合理分块
Pld汇编指令优化
循环展开
重排流水线
GPU优化
CPU 和 GPU 的结构有着明显的区别, CPU每个核心仅有一个ALU算数逻辑单元,几个核心共享L2缓存。而 GPU 通常会有很多个ALU计算单元, 成百上千个计算单元并行计算。这种并行是非常适合于深度学习中的计算。Paddle-Mobile充分利用了手机平台的GPU对主流GPU几乎是全覆盖,包含了ios和android两大阵营中的GPU实现。未来,Paddle-Mobile将会以GPU为主,CPU为辅的思路发展。
另外,CPU 和 GPU 并不是用的同一块内存,大量数据计算时会有较大差异。因此我们使用了占用内存更小的数据类型。
内核融合
如今较为常见的深度学习框架都会将模型抽象为由一些基本运算单元组成的有向无环图,这些基本运算单元包括常见的卷积、池化以及各种激活函数等,在真正执行时这些OP会调用更底层的内核函数 kernel 来完成运算。通常情况下,一个复杂的模型会包含上千个OP,而这些OP在调用kerenl时都会产生内存IO。内核融合可以将一序列顺序执行的OP kernel进行合并,从而减少内存IO次数,并充分利用CPU的流水线技术。此外内核融合也可以降低计算复杂度,比如Convolution和Batch Normalization的融合。
如何使用&如何参与开发
Paddle-Mobile经过了多次版本迭代,CPU和GPU版本都运行在几亿级用户的百度APP和简单搜索APP。如此量级的APP产品的验证是对靠性的例证。同时Paddle-Mobile也在和华为合作,HiAI平台的深度实现会在后继放出。
支持的模型
目前Paddle-Mobile已经在多个平台有不同模型覆盖,下表表示目前已经支持的模型范围。空白区域也是接下来会补齐的模型。
模型获取
深度学习技术离不开模型支持,Paddle-Mobile支持的是PaddlePaddle模型规范。模型的获取主要通过以下途径获得。
1. 如果你只是用来测试,对效果要求不高。测试模型和测试图片下载如下:
http://mms-graph.bj.bcebos.com/paddle-mobile%2FmodelsAndImages.zip
2. 若想有更好的效果独立训练模型,可以直接使用Paddle Fluid训练,该方式最为可靠,推荐方式。
3. 如果你手中的模型是其他框架训练的模型,需要进模型转换才可以运行。比如将caffe的模型转为Paddle Fluid的模型可以参考如下链接:
https://github.com/PaddlePaddle/models/tree/develop/fluid/image_classification/caffe2fluid
编译及开发
Paddle-Mobile框架所需要的测试模型已经在github完全免费公布,为开发者进一步使用提供便利。由于大量UI工程师对性能和底层优化有一定困扰,Paddle-Mobile的编译过程极其简单。以Android平台为例。在安装好cmake和ndk以后进入项目根目录,直接可以如下命令编译:
cd tools
sh build.sh android如果我们已经明确自己的模型,同时想要更小的体积可以:
`sh build.sh android googlenet`这样就不会打入开发者不需要的依赖,体积进一步减小。
设计文档,主要分为IOS、Android、FPGA、arm_linux等文档,在Readme和
https://github.com/PaddlePaddle/paddle-mobile
首页中都有相关链接,其中包含大量设计和开发过程所需要的资料。
总结
Paddle-Mobile做为国内全面支持各大平台的移动端深度学习框架,以移动端特点出发,针对性做了大量的优化、平台覆盖工作,并且保持了高性能、体积小等诸多优势。为对中国开发者更友好,中文文档被重点维护,有任何问题都可以到Github发issue。也欢迎相关爱好者加入开发为移动端深度学习的发展贡献力量。
****欢迎一块交流学习~****
喜欢的朋友记得点赞转发分享哦!
以上是关于Paddle-Mobile 百度嵌入式深度学习框架的主要内容,如果未能解决你的问题,请参考以下文章
百度上线深度学习利器Visual DL 通吃各大深度学习框架