业界首个视频识别与定位工具集PaddleVideo重磅更新
Posted 飞桨PaddlePaddle
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了业界首个视频识别与定位工具集PaddleVideo重磅更新相关的知识,希望对你有一定的参考价值。
飞桨 (PaddlePaddle) 致力于让深度学习技术的创新与应用更简单。7 月初,随着 Paddle Fluid 1.5 版本的发布,国内业界首个视频识别与定位工具集 PaddleVideo 也迎来了重磅更新。
PaddleVideo 在实际工业界可以形成很多具体应用,包括:视频精彩片段预测、关键镜头定位、视频剪辑等任务,例如定位 NBA 篮球赛视频中扣篮镜头,电视剧中的武打镜头等。如下图所示:
本文末尾,为广大算法和开发同学准备了 PaddleVideo 模型实战的应用案例,视频剪辑、素材拼接和标题生成工作完全是程序模型自动完成的,极大地减轻了人力剪辑的工作量,效果也还不错。不过,在看具体模型具体应用之前,让我们可以先来了解一下 PaddleVideo。
1.PaddleVideo 是什么?
PaddleVideo 是飞桨在计算机视觉领域为用户提供的模型库 PaddleCV 中的视频识别与定位部分的模型库。PaddleVideo 的全部模型都是开源的,用户可以一键式快速配置模型完成训练和评测。
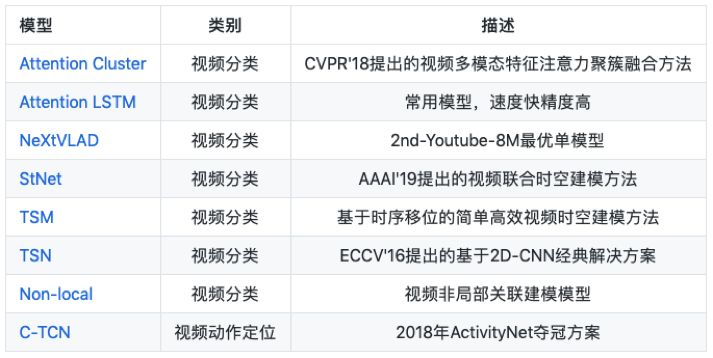
PaddleVideo 目前视频分类和动作定位模型包括:
2.重磅更新内容详解
本次重磅更新要点如下:
增加动作定位模型 C-TCN,该模型是 2018 年 ActivityNet 夺冠方案。
增加已发布的模型骨干网络,Non-local 模型增加 ResNet101 和 l3d 网络结构
优化已经发布的分类模型,NeXtVLAD 训练速度提升 60%,TSM 训练速度领先同类框架 39%
首先是动作定位模型 C-TCN。在介绍模型前,需要了解一下 ActivityNet。
ActivityNet 是目前视频理解领域影响力最大的赛事,与每年的顶级学术会议 CVPR 一起召开。在 2019 年的竞赛中,百度公司计算机视觉团队获得视频动作提名、视频动作检测两项任务的冠军,并在新增任务 EPIC-Kitchens 动作识别挑战赛中获两项测试集冠军(Seen kitchens 和 Unseen kitchens)。这已是百度视觉团队连续三年在 ActivityNet 相关赛事中斩获冠军。
了解了 ActivityNet 比赛的含金量,我们快来看一下第 1 条更新:C-TCN 模型。
2.1.动作定位模型 C-TCN
问题背景:定位视频中特定类别的时序动作片段的动作起始时间和终止时间点并正确识别动作类别。
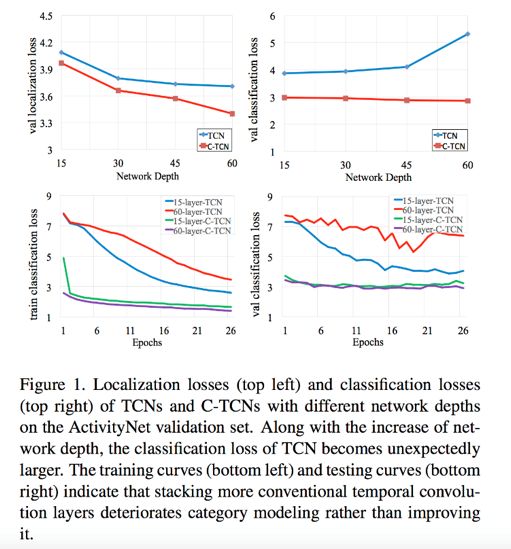
研究现状:当前的主流做法是将视频特征 (时间维度 T*C 单帧图像特征维度) 沿着时间维度做一维卷积设计各种网络结构 1D-TCN,我们实验发现随着网络加深之后网络的分类 loss 较浅层网络结构会差很多,也就是说类别信息在 1D 时序卷积网络中会随着网络变深而慢慢丢失,如下图所示。因此,我们设计了 C-TCN,2D 的保留类别信息的卷积,并且实验证明了 C-TCN 的有效性。
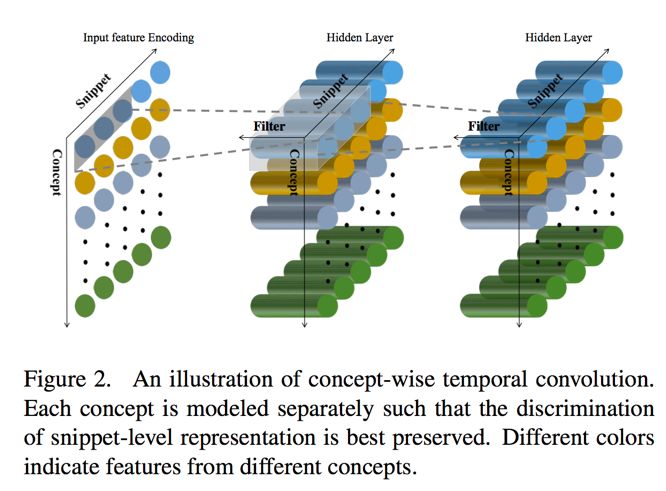
CTCN 卷积的过程如下图:
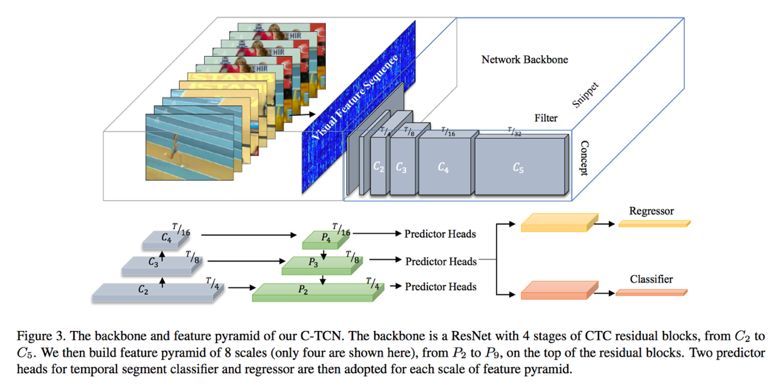
用 SSD+FPN 框架加入了 CTCN 后,整个网络结构如下图:
在 THUMOS14 和 ActivityNet1.3 上都取得了较好的结果,如下图:
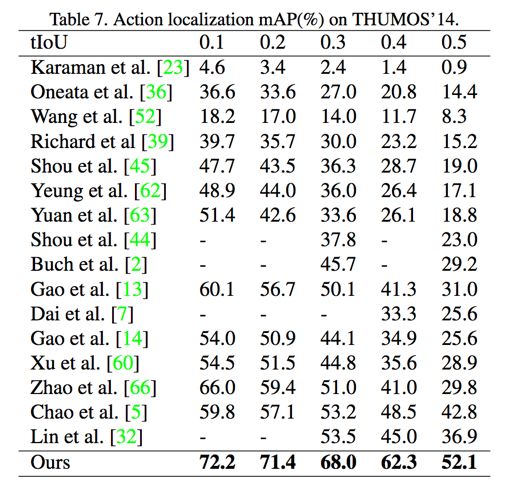
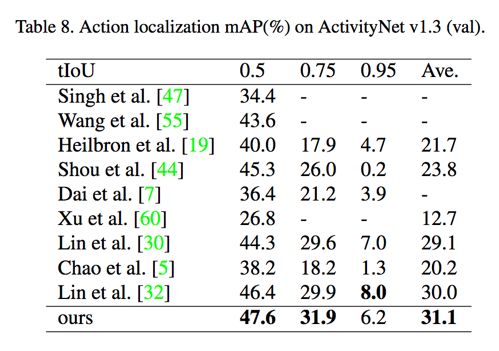
2.2.Non-local 模型增加 ResNet101 和 l3D 网络结构
具体来说,开发者选 Non-local 这个模型,之前版本只提供了最简单的网络结构,Resnet50 + C2D,此次版本更新,增加了两个复杂一些的网络结构:Resnet50 + I3D,和 Resnet101 + C2D。
这里给大家解释一下 Non-local 模型的意思。
在 CVPR 2018 收录的论文里有一篇叫《Non-local Neural Networks》。论文中,作者提出了 non-local operation 来解决 CNN 网络中的 long-range dependencies 问题。在论文中, 作者提出了 non-local operation 作为一种通用的神经网络的 building block 来捕捉基于 long-range 的依赖关系。受到经典的 non-local means 方法的启发, non-local operation 会将某一位置的响应当做是一种从特征图谱所有位置的加权和来计算。
该 building block 可以插入到现在计算机视觉的许多模型当中, 进而可以提升分类, 检测,分割等视觉任务的性能表现。
在 PaddleVideo 模型库中 Non-local 模型专门用于视频分类任务。
还有第 3 条更新: 优化已经发布的分类模型,NeXtVLAD 训练速度提升 60%,TSM 训练速度领先同类框架 39%。
2.3.NeXtVLAD 训练速度提升 60%,TSM 训练速度领先同类框架 39%
以上的速度提升是指在同样的硬件配置下,训练速度比之前有了很大的提升。经过此次更新,NeXtVLAD 模型训练速度比 TensorFlow 快约 1.88 倍。采用的优化方法是将数据预处理部分浮点数相关的运算转移到 GPU 上使用 Paddle Op 进行计算,而 CPU 上则使用 uint8 数据类型,可以大幅减小从 CPU 到 GPU 数据拷贝的开销。
3.模型训练、测试和推断
接下来,教大家如何使用 PaddleVideo 中模型,以本次重磅更新的模型 C-TCN 为例子。
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/PaddleVideo?fr=gzh
通过 gitclone 命令下载代码到本地。代码结构说明如下:

3.1.数据准备
C-TCN 模型使用 ActivityNet 1.3 数据集,具体下载方法请参考官方下载说明(http://activity-net.org/index.html)。在训练此模型时,需要先对 mp4 源文件抽取 RGB 和 Flow 特征,然后再用训练好的 TSN 模型提取出抽象的特征数据,并存储为 pickle 文件格式。我们将会提供转化后的数据下载链接。转化后的数据文件目录结构为:

同时需要下载如下几个数据文件:Activity1.3_train_rgb.listformat,Activity1.3_val_rgb.listformat,labels.txt,est_val_label.list,val_duration_frame.list,并放到 dataset/ctcn 目录下。
3.2.模型训练
数据准备完毕后,可以通过如下两种方式启动训练:

从头开始训练,使用上述启动脚本程序即可启动训练,不需要用到预训练模型。
可下载已发布模型通过--resume 指定权重存放路径进行 finetune 等开发。
训练策略:
采用 Momentum 优化算法训练,momentum=0.9。
权重衰减系数为 1e-4。
学习率在迭代次数达到 9000 的时候做一次衰减。
3.3.模型评估
可通过如下两种方式进行模型评估:

使用 scripts/test/test_ctcn.sh 进行评估时,需要修改脚本中的--weights 参数指定需要评估的权重。
若未指定--weights 参数,脚本会下载已发布模型进行评估。
运行上述程序会将测试结果保存在 json 文件中,使用 ActivityNet 官方提供的测试脚本,即可计算 MAP。
3.4.模型推断
可通过如下命令进行模型推断:

模型推断结果存储于 CTCN_infer_result.pkl 中,通过 pickle 格式存储。
若未指定--weights 参数,脚本会下载已发布模型进行推断。
以上也是 PaddleVideo 中所有模型的具体使用方法。
4.典型案例
PaddleVideo 目前已经在典型领域有一些实际应用,我们来看一个实际的视频剪辑集锦;案例:《伤心镜头集锦:看谁最能打动人心》
好啦,本期飞桨 PaddleVideo 的介绍就告一段落啦。如果有兴趣的同学,可以加入官方 QQ 群,您将遇上大批志同道合的深度学习同学。
飞桨官方 QQ 群:432676488
如果您想详细了解更多飞桨的相关内容,请参阅以下文档或点击文末阅读原文。
以上是关于业界首个视频识别与定位工具集PaddleVideo重磅更新的主要内容,如果未能解决你的问题,请参考以下文章
空间音频技术与生态发展高峰论坛成功举办,业界首个Audio Vivid创作工具花瓣三维声亮相
空间音频技术与生态发展高峰论坛成功举办,业界首个Audio Vivid创作工具花瓣三维声亮相