BicycleGAN详解与实现
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BicycleGAN详解与实现相关的知识,希望对你有一定的参考价值。
BicycleGAN详解与实现
使用BicyleGAN进行多样化图像转换
Pix2pix 和 CycleGAN 是非常的流行GAN,不仅在学术界有许多变体,同时也有许多基于此的应用。但是,它们都有一个缺点——图像的输出看起来几乎总是相同的。例如,如果我们要执行斑马到马的转换,被转换的同一马的照片将始终具有相同的外观和色调。这是由于GAN固有的特性,它学会过滤了噪声的随机性。为了进行多样化图像转换,本文详解了 BicycleGAN 如何解决此问题以生成更丰富的图像,并利用 Tensorflow2 实现了 BicycleGAN 。
BicyleGAN效果展示
使用 BicyleGAN 可以将一张图片进行多样化的转换,产生不同的样式和色彩:



BicycleGAN架构
在开始实现 BicycleGAN 之前,首先简要介绍一下。第一次听到这个名字,你可能会认为 BicycleGAN 是 CycleGAN 的变体,但其实它与 CycleGAN 无关,反而它是对 pix2pix 的一种改进。
pix2pix 是一对一映射,其中给定输入的输出始终相同。当试图将噪声添加到生成器输入时,网络会忽略噪声,并且在输出图像中并不会产生变化。因此,需要寻找一种方法,强制生成器不得忽略噪声,而是使用噪声来生成多样化的图像,即一对多映射。
下图是 BicycleGAN 相关的模型和配置。图(a)是推理的配置,图像A与噪声相结合以生成图像
B
^
\\hat B
B^,可以将此看作是 cGAN 。在BicyleGAN中,形状为(256, 256, 3)的图像A是条件,而从潜在编码
z
z
z 采样的噪声为大小为8的一维向量。图(b)是 pix2pix + 噪声 的训练配置。而 图(c) 和 图(d) 的两个配置由 BicycleGAN 训练时使用:
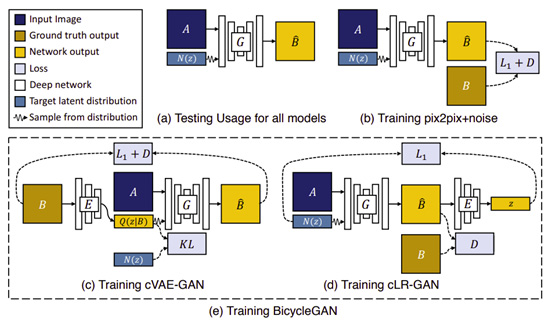
简而言之,BicycleGAN 可以找到潜在编码z与目标图像B之间的关系,因此生成器可以在给定不同的z时学会生成不同的图像
B
^
\\hat B
B^。如上图所示,BicycleGAN 通过组合 cVAE-GAN 和 cLR-GAN 这两种模型来做到这一点。
cVAE-GAN
VAE-GAN 的作者认为,
L
1
L_1
L1损失并不是衡量图像视觉质量的良好指标。例如,如果图像向右移动几个像素,则人眼看起来可能没有什么不同,但会导致较大的
L
1
L_1
L1损失。因此使用 GAN 的鉴别器来学习目标函数,以判断伪造的图像是否真实,并使用 VAE 作为生成器,生成的图像更清晰。如果忽略上图(c)中的图像
A
A
A,那就是 VAE-GAN ,由于以
A
A
A 为条件,其成为条件 cVAE-GAN 。训练步骤如下:
VAE将真实图片 B B B 编码为多元高斯分布的潜在编码,然后从它们中采样以创建噪声输入,此流程是标准的VAE工作流程;- 使用图像 A A A 作为条件及从潜矢量 z z z 采样的噪声用于生成伪图像 B ^ \\hat B B^.
训练中的数据流为
B
−
>
z
−
>
B
^
B->z->\\hat B
B−>z−>B^ ( 图(c) 中的实线箭头),总的损失函数由三个损失组成:
- L G A N V A E \\mathcal L_{GAN}^{VAE} LGANVAE:对抗损失
- L 1 V A E \\mathcal L_1^{VAE} L1VAE: L 1 L_1 L1重建损失
- L K L \\mathcal L_{KL} LKL: K L KL KL散度损失
cLR-GAN(Conditional Latent Regressor GAN)
在 cVAE-GAN 中,对真实图像B进行编码,以提供潜在矢量的真实样本并从中进行采样。但是, cLR-GAN 的处理方式有所不同,其首先使用生成器从随机噪声中生成伪图像
B
^
\\hat B
B^ ,然后对伪图像
B
^
\\hat B
B^ 进行编码,最后计算其与输入随机噪声差异。
前向计算步骤如下:
- 首先,类似于
cGAN,随机产生一些噪声,然后串联图像A以生成伪图像 B ^ \\hat B B^。 - 之后,使用来自
VAE-GAN的同一编码器将伪图像 B ^ \\hat B B^ 编码为潜矢量。 - 最后,从编码的潜矢量中采样 z ^ \\hat z z^ ,并用输入噪声 z z z 计算损失。
数据流为
z
−
>
B
^
−
>
z
^
z-> \\hat B -> \\hat z
z−>B^−>z^ ( 图(d) 中的实线箭头),有两个损失:
- L G A N \\mathcal L_{GAN} LGAN:对抗损失
-
L
1
l
a
t
e
n
t
\\mathcal L_1^{latent}
L1latent:噪声
N(z)与潜在编码之间的 L 1 L_1 L1 损失
通过组合这两个数据流,在输出和潜在空间之间得到了一个双映射循环。 BicycleGAN 中的 bi 来自双映射(双向单射),这是一个数学术语,简单来说其表示一对一映射,并且是可逆的。在这种情况下,BicycleGAN 将输出映射到潜在空间,并且类似地从潜在空间映射到输出。总损失如下:
l
o
s
s
B
i
c
y
c
l
e
=
L
G
A
N
V
A
E
+
L
G
A
N
+
λ
L
1
V
A
E
+
λ
l
a
t
e
n
t
L
1
l
a
t
e
n
t
+
λ
K
L
loss_{Bicycle}=\\mathcal L_{GAN}^{VAE}+\\mathcal L_{GAN}+λ\\mathcal L_1^{VAE}+λ_{latent}\\mathcal L_1^{latent}+λ_{KL}
lossBicycle=LGANVAE+LGAN+λL1VAE+λlatentL1latent+λKL
在默认配置中,
λ
=
10
λ = 10
λ=10、
λ
l
a
t
e
n
t
=
0.5
λ_{latent} = 0.5
λlatent=0.5、
λ
l
a
t
e
n
t
=
0.01
λ_{latent} = 0.01
λlatent=0.01。
BicycleGAN实现
BicycleGAN 中有三种类型的网络——生成器,鉴别器和编码器。为 cVAE-GAN 和 cLR-GAN 使用单独的鉴别器可以提高图像质量,因此我们将使用四个网络-生成器,编码器和两个鉴别器。
在生成器中插入潜在编码
将潜在编码插入到生成器中有两种方法,如下图所示:
- 与输入图像进行级联;
- 将其插入到生成器的下采样路径中的其他层中。
 实验发现前者效果很好。
实验发现前者效果很好。
有多种方法可以将不同形状的输入和条件结合起来。 BicycleGAN 使用的方法是多次重复潜在编码然后与输入图像连接。
在 BicycleGAN 中,潜在编码长度为8,我们从噪声分布中提取了8个样本,每个样本重复H×W次以形成形状为 (H, W, 8) 的张量。换句话说,在8个通道中,其 (H,W) 特征图都是相同的。以下代码显示了潜在编码的拼接和连接:
input_image = layers.Input(shape=image_shape, name='input_image')
input_z = layers.Input(shape=(self.z_dim,), name='z')
z = layers.Reshape((1,1, self.z_dim))(input_z)
z_tiles = tf.tile(z, [self.batch_size, self.input_shape[0], self.input_shape[1], self.z_dim])
x = layers.Concatenate()([input_image, z_tiles])
下一步是创建两个模型,即 cVAE-GAN 和 cLR-GAN,以合并网络并创建前向信息流。
cVAE-GAN
下面创建 cVAE-GAN 模型的代码,前向计算的实现:
images_A_1 = layers.Input(shape=input_shape, name='ImageA_1')
images_B_1 = layers.Input(shape=input_shape, name='ImageB_1')
z_encode, self.mean_encode, self.logvar_encode = self.encoder(images_B_1)
fake_B_encode = self.generator([images_A_1, z_encode])
encode_fake = self.discriminator_1(fake_B_encode)
encode_real = self.discriminator_1(images_B_1)
kl_loss = - 0.5 * tf.reduce_sum(1 + self.logvar_encode - tf.square(self.mean_encode) - tf.exp(self.logvar_encode))
self.cvae_gan = Model(inputs=[images_A_1, images_B_1], outputs=[encode_real, encode_fake, fake_B_encode, kl_loss])
我们在模型中使用了
K
L
KL
KL 散度损失。由于可以直接根据均值和对数方差来计算 kl_loss ,而无需在训练步骤中传入外部标签,因此更加简单有效。
cLR-GAN
下面是 cLR-GAN 的实现,前向计算的实现:
images_A_2 = layers.Input(shape=input_shape, name='ImageA_2')
images_B_2 = layers.Input(shape=input_shape, name='ImageB_2')
z_random = layers.Input(shape=(self.z_dim,), name='z')
fake_B_random = self.generator([images_A_2, z_random])
_, mean_random, _ = self.encoder(fake_B_random)
random_fake = self.discriminator_2(fake_B_random)
random_real = self.discriminator_2(images_B_2)
self.clr_gan = Model(inputs=[images_A_2, images_B_2, z_random],
outputs=[random_real, random_fake, mean_random])
现在,我们现在已经定义了模型,下一步是实现训练步骤。
训练步骤
两种模型一起进行训练,但是具有不同的图像对。因此,在每个训练步骤中,我们两次获取数据,每个模型一次,这是通过创建数据管道来完成的,该数据管道将调用两次以加载数据:
images_A_1, images_B_1 = next(data_generator)
images_A_2, images_B_2 = next(data_generator)
self.train_step(images_A_1, images_B_1, images_A_2, images_B_2)
我们可以使用两种不同的方法来执行训练。一种是使用优化器和损失函数定义和编译Keras模型,然后调用 train_on_batch() 来执行训练步骤,这种方法在定义明确的模型上效果很好。此外,我们也可以使用 tf.GradientTape 来更好地控制梯度更新。BicycleGAN 有两个模型,它们共享一个生成器和一个编码器,但是我们需要使用损失函数的不同组合来更新它们的参数,这使 train_on_batch 方法在不修改原始设置的情况下不可行。因此,我们使用 tf.GradientTape 将这两个模型的生成器和鉴别器组合为一个训练步骤,如下所示:
- 第一步是执行前向传递并收集两个模型的输出:
def train_step(self, images_A_1, images_B_1, images_A_2, images_B_2):
z = tf.random.normal((self.batch_size, self.z_dim))
real_labels = tf.ones((self.batch_size, self.patch_size, self.patch_size, 1))
fake_labels = tf.zeros((self.batch_size, self.patch_size, self.patch_size, 1))
with tf.GradientTape() as tape_e, tf.GradientTape() as tape_g, tf.GradientTape() as tape_d1, tf.GradientTape() as tape_d2:
encode_real, encode_fake, fake_B_encode, kl_loss = self.cvae_gan([images_A_1, images_B_1])
random_real, random_fake, mean_random = self.clr_gan([images_A_2, images_B_2, z])
- 接下来,我们通过反向梯度传播更新鉴别
以上是关于BicycleGAN详解与实现的主要内容,如果未能解决你的问题,请参考以下文章
在Tomcat的安装目录下conf目录下的server.xml文件中增加一个xml代码片段,该代码片段中每个属性的含义与用途