基于百度Paddle和NI Rio的人工智能自动化数据集训练
Posted 科技创造营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于百度Paddle和NI Rio的人工智能自动化数据集训练相关的知识,希望对你有一定的参考价值。
割裂数据集的人工智能就像男人八岁进了宫,接着上一讲,我们继续来讲讲人工智能自动化数据集的训练。
采用百度的Paddlepaddle,训练起来很是方便。
本项目涉及知识产权,合作洽谈请联系:微信shtuling或邮箱3030160071@qq.com,能够借助此方法解决工业问题,也可以采购相关教具用于教学。
一、背景
近年来,人工智能发展迅猛,应用广泛,促使人工智能的相关教育以及在工业领域的相关应用变得愈发普及。
但是大部分人工智能算法,尤其是深度学习,需要在大量精准的数据集上进行训练,并且学习的效果与训练集的规模和准确度成正比。
目前,经深度学习培训后的学习者能够理解程序和调试参数来改善模型以提高训练准确度,但训练过程中大量调用已有的数据集。
这种做法使得学习者不能参与数据集的取样、处理和建立,缺少了极为重要的一环,导致培训后的学习者缺乏使用深度学习解决实际问题的能力,他们沦为只会调用数据集的调参党,学不能以致用。
然而,生成一个庞大并且准确的数据集往往需要大量的时间与人力成本,这昂贵的时间代价与人力成本妨碍了人工智能的全链条教育,所以开发一种快速而准确地生成数据集的方法是人工智能教育的当务之急。
同时,现在很多生产企业还保留大量的离线式仪器仪表,这些表计无法通过远程、在线采集数据,必须通过派专人值班读数的方式采集数据,而完全更换表计将产生极大成本。
而且,种类繁多的表计都通过通信在线采集数据,由于通信方式的不同,也给数据集生成带来极大麻烦。因此,通过摄像头采集的图像信息去通用地识别各种表计数据,在目前的实际生产环境中也具有重大价值,不需要投入大量资金技改,也无需考虑各表计的数据格式。
然而,各种表计的形式多样,建立数据集训练人工智能模型都需要花费极大精力,根据不同表计自动产生数据集从而训练出识别的人工智能模型,对实际生产也具有重大作用。这使得表记数据实时读取成为可能,为日后的工厂自动化控制打下基础,帮助工厂顺利转型升级。
二、内容
项目简介:
本项目为基于PaddlePaddle的刻度识别自动化模型训练系统,有两个子系统组成。第一个子系统为数据集自动生成系统,第二个系统为基于PaddlePaddle的智能识别系统。
数据集自动生成系统包括:刻度反馈模块、刻度模块、传动模块、图像采集模块。
刻度反馈模块为旋转电位器,刻度模块为表计刻度盘,以旋转电位器的阻值来指示表计刻度盘的状态,电机控制模块通过电机子模块把旋转电位器的阻值调整到一个状态,测量该状态的旋转电位器实际阻值,根据该实际阻值与表计刻度盘的对应关系,得到此状态的表计刻度盘指示数值;图像采集模块启动对表计刻度盘拍照,并对图像的尺寸和光线按照设定进行处理,得到标准统一的图像,并根据旋转电位器实测值对应的刻度盘数值标记该状态的标记刻度盘图像;标记后的表计刻度盘图像成为训练人工智能模型所需数据集的一个元素,以此方法,生成涵盖全部刻度盘信息状态的图像并自动化标记,建立完整数据集。
传动模块包括:电机子模块和电机控制模块,电机控制模块控制电机子模块运动,电机子模块具有双输出端,分别与刻度模块、刻度反馈模块连接。传动模块的电机子模块带动刻度模块和刻度反馈模块运动,电机控制模块根据全面间隔策略不断调整电机子模块运动,从而得到刻度模块每一个刻度状态时的图像。在本项目中,电机控制模块使用NI myRIO开发板。
图像采集模块包括:摄像头、图像采集程序,图像采集程序控制摄像头获得图像、对图像进行归一化处理,并根据刻度反馈模块传递的检测数值转化为刻度模块数值而标记图像。该模块能够调整获取刻度模块图像时的环境照明度,未来还能够调整与刻度模块的角度、距离,以获取且标记不同照明度、角度、距离参数的刻度模块图像,标记刻度数值和参数的刻度模块图像构成深度学习模型训练的数据集。
图1为数据集自动生成系统实物图。其中电机子模块采用配置减速结构的直流电机,传动模块的双输出端采用齿轮结构实现,传动模块中的电机子模块和刻度模块、刻度反馈模块以齿轮的方式相连,刻度模块与刻度反馈模块的传动比为10:1;刻度模块的刻度盘具有10x10x5=500个刻度,每个刻度代表数值20;而刻度反馈模块采用10圈旋转电位器,旋转电位器的阻值10kΩ±5%,精度±10Ω,线性±0.25%;旋转电位器的10kΩ阻值与刻度盘的500个刻度一一对应。刻度盘与图像采集模块45度角,环境光照2lux。

图1. 数据集自动生成系统实物图
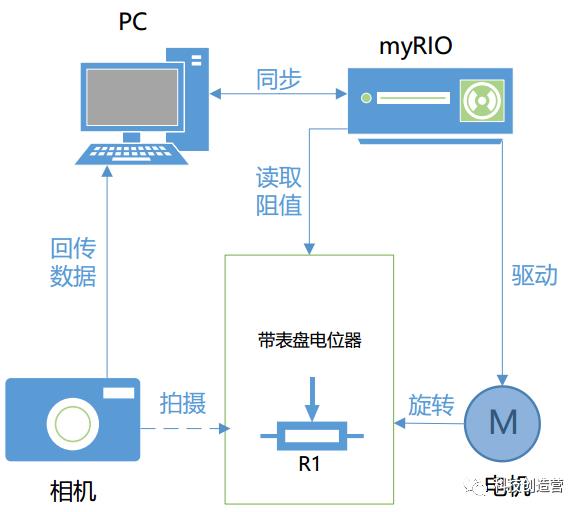
图2. 数据集自动生成系统架构图
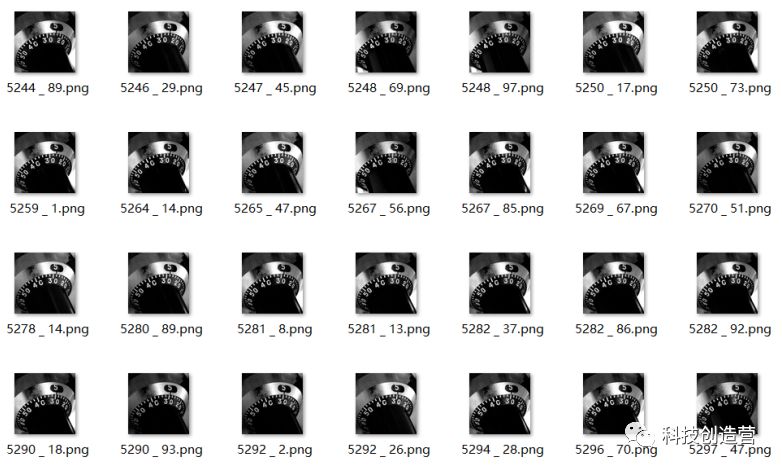
图3. 自动生成数据集展示
智能识别系统基于先前建立的数据集,使用PaddlePaddle平台进行识别训练。
其中深度学习采用LeNet-5卷积神经网络模型,分别对表盘千分位,百分位与二十分位进行识别,再计算合成出最终读数结果。
目前,经过调试后LeNet-5的参数如下:第一层卷积层的卷积核大小为5x5,层数为20层;第二层池化层的池化大小为2,池化步长为2,采用最大值采样;第三层卷积层的卷积核大小为5x5,层数为50层;第四层池化层的池化大小为2,池化步长为2,采用最大值采样;最后使用softmax激活函数的全连接输出层进行分类。此过程同时适用于千分位,百分位与二十分位的识别。
图4. 卷积神经网络架构图
图5. 深度学习表盘读取结果展示
·项目性能:
数据集生成部分:
约0.5s生成一张照片,标定误差范围为±10Ω(其中电位器阻值范围为0~10kΩ,最小分度值为20Ω)。
深度学习训练效果:
以20Ω作为识别的最小分度值,对其进行识别。其中,识别千分位准确率≥97%,百分位准确率≥97%,二十分位准确率≥87%。总体识别准确率≥83%。
·项目优势:
1、自动化。深度学习训练模型所需的数据集以自动化方式生成,在保证一定准确率的情况下实现了自动化,节省大量传统方式中用于标定的时间与人力。
2、高精度。数据集自动标定过程的误差控制在0.2%以内,与人工读数相比更为精准,并且后续可以通过更换精度更高的电位器继续提升精度;能够选择不同照明度、距离、角度参数而自动化生成不同的数据集,并且可以根据训练结果,不断调整训练模型参数优化性能,直到正确识别表计刻度盘的数值。
3、可拓展。在数据自动生成器中,只需改变其中标定过程的拟合函数,即可实现对不同种类与规格的仪器表盘的数据集生成与识别。
4、低成本。在保证基本性能与功能的前提下,整套装置后续成本可控制在千元以内。低成本保证了此装置可以作为教育套件被广泛推广。
5、易部署。以刻度反馈模块检测的数值标记表计刻度盘的图像,利用传动模块构建自动化生成数据集的方式,使得整套装置可以在原有仪器表盘直接安装部署,无需进行大量的更换装备的工作,适合生产企业的设备升级。
6、数字化。各种表计的输出形式不同,数据格式不同,通信方式也不同,而本项目以图像识别的方式代替远程在线读取数据的通信集成方式,实现了仪器仪表读数的数字化。
三、应用前景
对于教育方向:
目前市场上缺少相关的教育套件。
现有的人工智能教育资源大多数是原理讲解或是停留在软件层面的程序编写,集中于训练与预测的环节。
这造成了深度学习最为基础环节
——
数据库生成部分的缺失,而此部分在缺少硬件的情况下很难弥补。
大多数采用了调用现成数据库的方式,如MNIST数据集,然而这种方法无法让学生亲自参与到数据生成环节的学习。
本项目针对这个盲区,开发出了这套低成本,高精度,自动化的数据自动生成装置,将数据集建立过程通过一个轻松的方式实现,补全了人工智能教育的全套教育链。
将本项目应用于人工智能学习的全链条培训教育中,从所要解决的问题开始,囊括了包括数据集的采集、处理、建立和深度学习模型的训练,增强学习者学以致用的能力。
对于工业生产方向:
目前对于大部分的生产企业,存在着大量的传统仪器表盘,而针对这些表盘读数与监控,缺少一种廉价、高效且通用的方法对大量不同表盘进行监控管理。
现有的解决方案有两种,一是对生产仪器进行完全的改造,将所有传统表盘替换为新型的电子测量仪器;
二是雇佣工人进行仪表的实时读数。
对于第一种解决方案,整体更换电子表盘仪器过于昂贵,并且在更新的过程中无法持续进行生产,需要较长时间的停工安装与调试,这些因素使得一般厂商难以承受;
如果使用传统的人工读表方式,会增加工厂所需的人力成本,并且人工读表的过程中存在这误差与误判,降低了生产效率,也为生产带来潜在风险。
本项目针对这种情况,给出了最优的解决方案
——
依托传统仪器表盘,无需进行大规模的设备更新换代,自动建立一个庞大且准确的数据库来训练神经网络,代替了人工进行读表。
以一种低成本、高质量的方案解决了生产企业大量仪器仪表在线读数和数据集成的难题,便于建立自动化流程的识别和监控。
目前,我国人工智能市场规模逐渐扩大,
2018
年产业规模达到
200
亿元以上,近三年的平均增长率均达到
50%
以上,发展势头迅猛。
2017
年,国务院印发《新一代人工智能发展规划》提出,要在中小学阶段设置人工智能相关课程、逐步推广编程教育、建设人工智能学科、培养复合型人才,形成我国人工智能人才高地。
仅教育机器人行业,
2018
年的市场规模就有约
7.5
亿元,且有预测未来将以
15%
的比例增长,在
2019
年人工智能基础学科类教育整体的市场规模将达到
30
亿元左右。
在如此庞大的人工教育市场之下,与之相对的是人工智能教育学科的硬件软件上资源的匮乏。
如之前分析,目前在人工智能机器部分就缺少一种数据集的生成教育模块。
若将本项目融入其他人工智能教育产品体系中,将帮助补全人工智能教育的所有环节,大大提高教育产品的竞争力。
而对于工业生产领域,人工智能也正在进军工业生产领域。
目前全球工业总产值将近
32
万亿美元,
1%
的工业效率提高也将带来
3200
亿美元的收益,并且有分析报告指出人工智能技术的应用将为中国制造的生产效率带来
15~25%
的提升,创造
4~6
万亿元人民币的效益。
目前大多数企业,比如阿里,为生产企业提供了生产数据分析的解决方案,着重于智能工厂模式中的智能排程、智能调度、智能物流、智能采集和智能监控。
现有大多数生产企业、工厂还保有着大量的传统仪表仪器。
本项目便着重于使用一种低成本的方式,对传统的仪器仪表设备进行升级,数字化、自动化、智能化的仪表读数使得生产企业、工厂中的基础设备拥有接入智能云端进行智能管理的可能性。
例如,奉贤特高压直流输电站承担上海电力
1/3
用电供应,
阈值都是进口自
ABB
公司,因为承担重大生成安全重任,监控仪器仪表不能随意改动。
以前,采用人力每半小时抄录一次表计数据,浪费人力资源,且麻烦;
后在仪器仪表外围安装摄像头,值班人员在控制室每隔半小时查看、记录一次数据,仍然很耗费精力,而且记录频率过低。
配套开发此仪器仪表刻度自动识别模型之后,通过读取摄像头能够自动识别读数,一秒钟存储一次数据形成历史信息,且能够设定异常值监控,完全释放了人力资源,仅此一项仪器仪表自动识别读数记录为输电站每年节约人力成本
100
万元。
对于电力生产相关公司,如电厂、变电站、配电站等,一直承担重要生产运行任务,监控仪器仪表不能随意更换,只能通过摄像头获得图像实现在线监测手段,仅上海电力公司就能够每年就能够节约人力成本
2000
万元,且提高了监控频率和有效性。
水务、煤炭、燃气及大量生产工厂等安全运行单位都有此种需求,市场空间广泛,提升经济效益和安全性。
以上是关于基于百度Paddle和NI Rio的人工智能自动化数据集训练的主要内容,如果未能解决你的问题,请参考以下文章