百度AI攻坚战:PaddlePaddle中国突围 Posted 2021-04-01 AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百度AI攻坚战:PaddlePaddle中国突围相关的知识,希望对你有一定的参考价值。
出品 | AI科技大本营(ID:rgznai100)
2013年,百度开始研发深度学习框架PaddlePaddle,搜索、凤巢CTR预估上线DNN模型。
2016年,在百度世界大会上,百度宣布PaddlePaddle开源,标志着国产开源深度学习平台的诞生。
时间来到2019,人工智能已经进入商业落地的关键节点。
今年4月,在WaveSummit深度学习开发者峰会上,时任百度高级副总裁的王海峰为PaddlePaddle的战略地位进行了定调,并表示深度学习已经推动人工智能进入工业大生产阶段,而深度学习框架则是智能时代的操作系统。
这一年对PaddlePaddle来说是至关重要的一年。国外强敌林立,PaddlePaddle的突围战开始从国外转向国内,除了给自己取了个中文名“飞桨”,还宣布重金投入和补贴,争抢中国AI开发者。
时隔半年,百度再次召开WaveSummit+深度学习开发者峰会,此时王海峰已经升任为百度首席技术官,PaddlePaddle的全景图也越来越越完善,也越来越清晰。
在短短的半年时间里,PaddlePaddle全新发布和重要升级21个产品,重点聚焦在两大方面:
1、平台易用性全方位提升,进一步降低了开发和训练部署的门槛;
2、更多强大的功能,让产业应用落地的更加便捷,真正解决产业应用的痛点。
这些新产品和新升级囊括了面向产业应用场景的四大端到端开发套件、融合数据和知识的预训练结合迁移学习的飞桨Master模式、端侧推理引擎Paddle Lite 2.0、EasyDL专业版、前沿技术工具组件等等。
比如全新发布端侧推理引擎Paddle Lite 2.0版本,打通端到端部署全流程,提升易用性,广泛的硬件支持。在原有的工具组件基础上,还全新发布3项深度学习前沿技术工具组件:联邦学习PaddleFL、图神经网络PGL和多任务学习PALM。
全新发布EasyDL专业版为算法工程师提供一站式AI开发平台。PaddleHub 则支持飞桨Master模式。所谓Master(大师)模式,指的是:算力+数据和知识+算法=产业级预训练模型,产业级预训练模型+迁移学习工具平台构成Master的核心,可以用于多种行业场景。
可以看到,PaddlePaddle正在全面开放自己的AI能力,助力产业升级,这也契合了李彦宏在百度开发者大会上提出的产业智能化的概念。
接下来,营长将会从PaddlePaddle平台的整体框架出发,按照核心框架、基础模型库、端到端开发套件、工具组件和服务平台几大板块,为读者介绍完整的PaddlePaddle全景图。
PaddlePaddle是一个全面的开源开放平台,包含核心的开发、训练、部署框架,以及非常丰富的模型库。基于这个模型库,PaddlePaddle可以覆盖很多经典的应用场景,开发者可以进行二次开发,或者直接使用。在这个模型库的基础之上,PaddlePaddle还提供了端到端的开发套件,聚焦在人工智能领域的常见任务和场景。在端到端开发套件之上是一整套的工具组件,这些工具组件可以帮助开发者解决更多人工智能应用当中的问题。之后是服务平台,在这个服务平台上,开发者不仅可以基于算力做更多的人工智能应用开发,也可以在PaddlePaddle的实训平台上进行学习。同时,PaddlePaddle还提供很多部署的工具链,方便开发者部署自己的应用。
首先看一下核心框架。一个深度学习开源框架包含几个非常关键的环节:一是算法开发,开发环节API的易用性、功能的完备性至关重要;二是训练,算法开发完成之后,需要有非常大规模的数据进行高速训练,提升研发效率;三是要把算法模型真正部署到应用场景中,需要一系列的部署工具,通过这些部署的链条进一步落地。
首先是开发框架易用性的全面提升,PaddlePaddle最近在GitHub上发布了核心框架的V1.6版本,里面包含了非常多的细节功能。
1)丰富的算子库:开发一个算法,计算的基本算子需要进一步完善和全面,目前PaddlePaddle已经支持AI领域几乎所有的模型。
2)简单高效的API接口:API接口是面向开发者最直接的一层,开发者需要更加方便便捷的API接口,主要体现在以下两个层面:
一是数据层。在真正的开发过程中,数据的IO非常关键,也是在开发深度学习应用时非常关键的环节。这次PaddlePaddle把IO接口做了全面梳理,易用性大幅提升。同时,IO的速度一直以来也是PaddlePaddle的优势,工业级IO的发布可以让开发者有更好的体验。
二是分布式训练的易用性。现在数据规模非常大,开发者往往需要进行分布式训练,单台机器无法完成。这种情况下,一个单机的应用程序如何快速地改成一个分布式训练的程序非常关键。利用升级后的PaddlePaddle平台,开发者只需要很少量的代码开发,就能够把一个单机的程序快速变成一个分布式训练的程序。
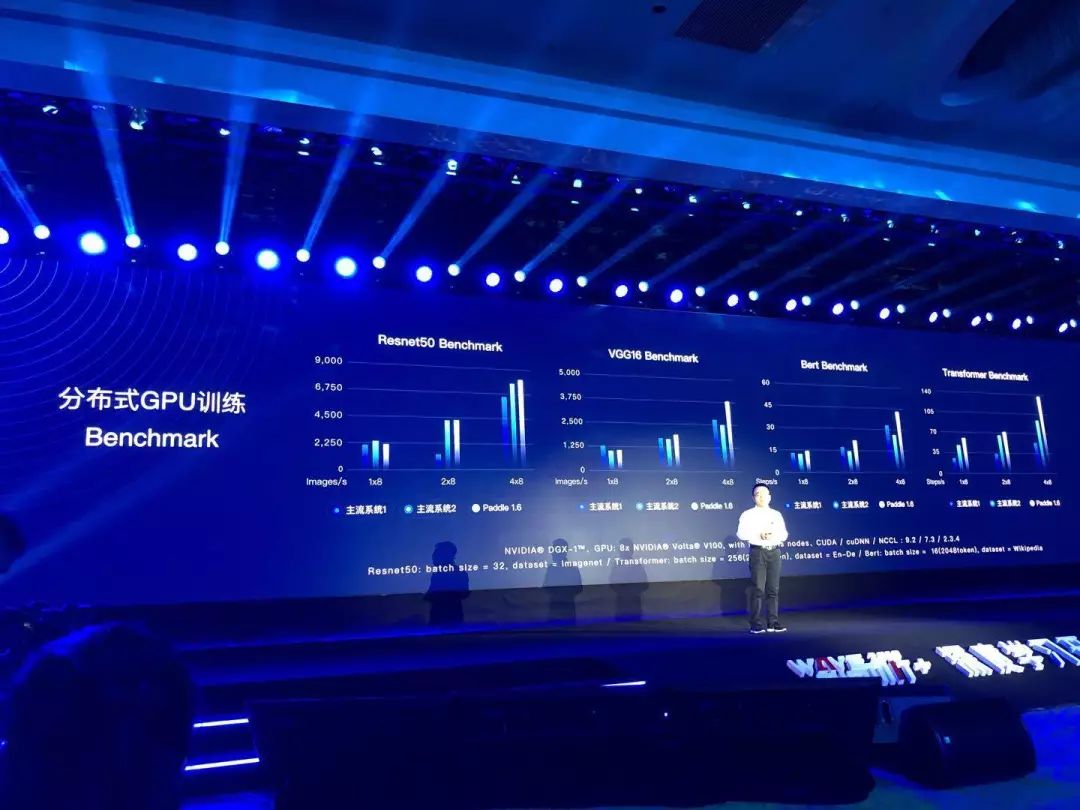
PaddlePaddle把工业领域常用的分布式训练的模型做了Benchmark。开发者可以很方便地找到快速把一个单机的程序变成一个分布式训练程序的程式,并且找到应用最为广泛的一些算法模型,用分布式来进行实现。在这里新增5行代码就能实现高效的GPU并行训练。
3)PaddlePaddle一直在不断完善开发文档的内容。PaddlePaddle一直提供中英双语的文档,这次PaddlePaddle对中文文档进行了非常多的升级和完善,尤其是API文档。
除了深度学习框架的易用性,性能也是开发者非常关注的。性能可以体现在速度、内存管理上。PaddlePaddle平台的开发非常关注这两点,通过这个Benchmark,可以看到PaddlePaddle在这些方面取得的新进展。
首先是基于GPU的分布式训练。在GPU设备上,利用PaddlePaddle可以快速地做分布式训练的Benchmark。可以看到,PaddlePaddle的分布式训练有非常好的扩展性,跟其他框架相比,可以真正带来效率上的提升。
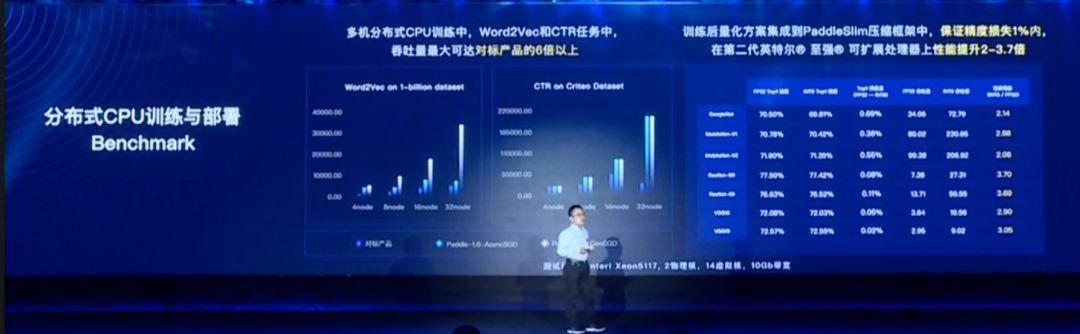
其次是基于CPU的训练。GPU训练更多是在图像领域或者复杂的文本处理领域,很多的推荐场景还在用基于CPU的分布式训练。比如经典的Word2Vec的计算,通过百度自研的GUSGD方法,它的扩展性跟其他的框架相比有非常显著的领先优势,吞吐量可以达到对标产品的6倍以上。GUSGD为什么有这样的效果?因为Word2Vec模型的计算比较简单,大量的时间都在通信,GUSGD基于这个特点设计了一套全新的优化的方法,把计算和通信之间的Balance问题解决得很好,从而使整个吞吐有大幅的提升。
开发完成之后是部署,这个环节涉及的工作非常多。首先要适配不同的硬件,最新的PaddlePaddle新增了对于华为NPU的适配,以及对于边缘设备上FPGA的适配。同时,PaddlePaddle很快还会进一步发布跟寒武纪和比特大陆的适配工具。此外,硬件的加速在部署环节也非常关键的,它关系到部署推理的性能。再上面就是核心的Paddle Serving、Paddle Lite框架层。把底层硬件的细节屏蔽掉,开发者只需要关注这些接口就可以真正部署应用。此外,真实的应用当中都有非常苛刻的环境限制和要求,所以模型压缩非常重要。
可以看到,整个开发过程中,开发者需要先开发算法,然后进行训练,最后得到模型。这个模型在最终部署之前往往会进行量化、剪枝、蒸馏等处理,尤其是在移动设备端,开发者往往需要进一步压缩模型的体积。然后就是Serving,把它真正部署成一个服务,能够在线提供负载均衡等能力,真正作为一项服务使用。而PaddlePaddle可以打通端到端的全流程,方便开发者一站式完成全部任务。
PaddleSlim的上一个版本已经支持剪枝、量化、蒸馏等方法,这次的升级重点主要体现在自动化网络结构设计方面。通过这种自动化网络结构的方法,可以根据硬件的特点,把硬件作为其中的一个约束条件进行搜索。比如开发者在基于某个硬件做部署时,既想保证精度,又要保证速度,把模型压缩的足够小,就可以利用PaddlePaddle的自动化网络结构搜索技术。PaddlePaddle这次升级也提供了更丰富的模型支持,同时把训练、压缩和部署全流程进行了打通,并保证了足够的性能。
https://github.com/PaddlePaddle/models/tree/develop/PaddleSlim
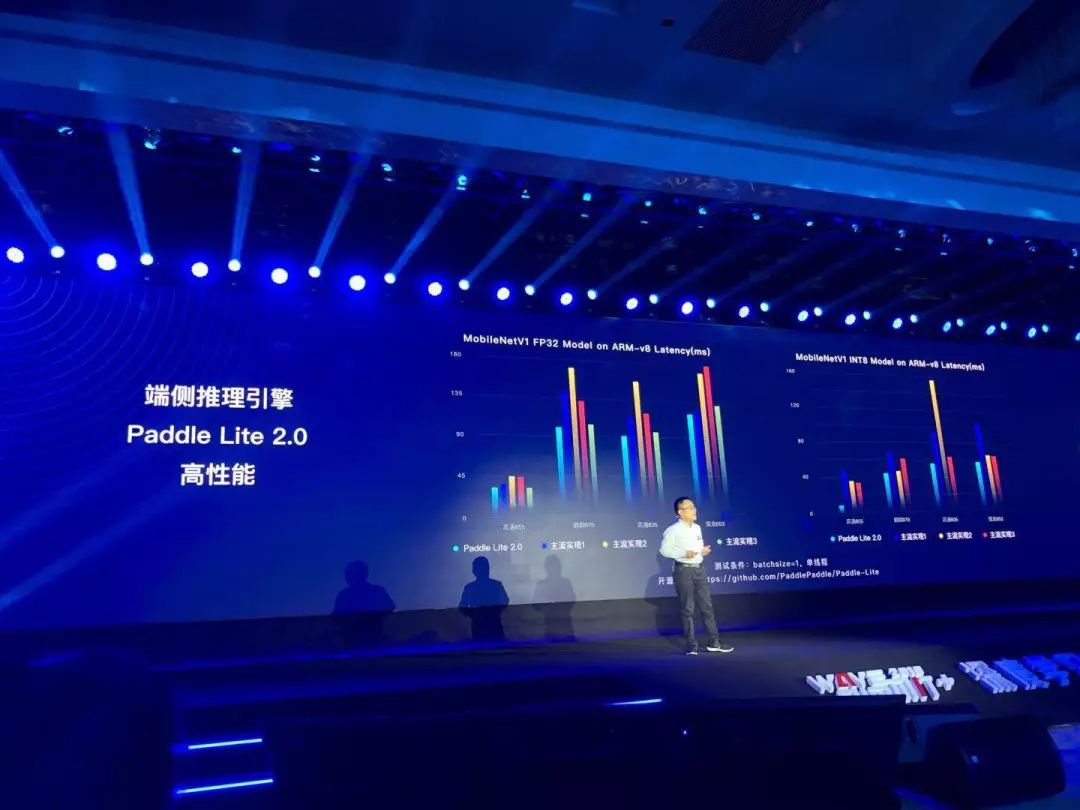
Paddle Lite 2.0的编译、硬件适配能力和易用性都得到了大幅的提升,它有几个重要的特点:
一是高易用性。在移动端或边缘设备上开发应用程序涉及到非常多的设备环境的连调工作,PaddlePaddle提供了大量的事例代码以及操作指南,方便开发者在不同的设备场景上进行快速部署。
二是广泛的硬件支持。PaddlePaddle目前已经支持8种主流的硬件,同时新增了华为的NPU和边缘设备的FPGA。并且Paddle Lite 的设计非常便于硬件扩展。比如你有一个新的硬件,只要在Paddle Lite里新增这个硬件相关的Kernel即可,它跟其他的框架设计是高度解耦的。
三是性能。这是Paddle Lite一个显著的优势,其性能优势不仅仅是在FP32这种场景下,在移动端已经广泛普及的INT8上,领先优势则更加明显。
https://github.com/PaddlePaddle/Paddle-Lite
PaddlePaddle的模型库已经支持自然语言处理、计算机视觉、推荐和语音。这次升级,PaddlePaddle官方支持的模型从60个扩充到了100多个。
PaddleCV在图像分类、生成、检测、视频理解等领域都有新增的模型,并开放了一些最领先的模型。另外,PaddleNLP在语义理解、阅读理解、对话这些场景上也做了开放。PaddleRec和Paddle Speech也都做了进一步的完善和升级。
同时,PaddlePaddle还开源了多个在2019年夺冠的一些算法模型,这里面包括在视频理解上取得冠军的模型。此外,在EMNLP 2019竞赛中获得10项阅读理解冠军的D-NET模型,PaddleNLP也已经支持。
了解更多关于PaddlePaddle模型库的相关知识,请查看《》。
PaddlePaddle在本次峰会上重点发布了4个端到端的开发套件。这些开发套件有哪几个特点?一是真正的工业场景当中性能要足够高,二是开发的时候简洁易用,三是落地的时候足够高效。
这4个套件面向的应用场景非常广泛,也非常集中。一是ERNIE模型,主要用于语义理解;二是PaddleSeg,主要用于图像分割;三是Paddle Detection,主要用于目标检测;四是ElasticCTR,主要用于个性化推荐。
ERNIE开发套件的核心能力在于预训练模型,尤其在中文领域。通过全景图可以看到,ERNIE开发套件有非常多的预训练的模型集,这个预训练的模型集不仅具备通用语义表示的能力,比如词的表示,句子
除了预训练模型,ERNIE开发套件还提供了一系列的工具,包括做迁移学习的Fine-Tuning工具。为了部署更方便,ERNIE提供了快速推理的工具。另外,ERNIE开发套件也提供了针对ERNIE的压缩能力,以及部署需要的Service的能力。在平台层面,开发者可以通过EasyDL平台的算力进一步使用ERNIE相关的模型。它的应用场景非常广泛,适用于各种各样NLP的任务。
ERNIE预训练模型里面有几个比较核心的元素:一是基于海量的数据和知识,二是多任务学习的能力,三是持续学习的过程。什么是持续学习的过程?ERNIE不是一次预训练就结束了,而是一个可持续学习的语义理解框架。通过这种方式,开发者可以不断往里面新增数据,整个模型的表示能力就会变得更强。同时,它还可以持续扩充数据,兼顾更多任务。
ERNIE开发套件的主要特点:支持各类训练任务Fine-tuning,保证极速推理Fast-inference API,兼顾灵活部署ERNIE Service,具备轻量方案ERNIE Tiny。
ERNIE模型在线部署的时候会遇到性能的瓶颈问题,ERNIE开发套件提供了一个轻量化的方案——ERNIE Tiny,包括数据蒸馏和模型蒸馏,通过数据蒸馏可以提升1000倍的速度。
https://github.com/PaddlePaddle/ERNIE
在视觉领域,语义分割有非常广泛应用的场景。这次升级的PaddleSeg包含了18个预训练模型,能够覆盖主流的网络。
PaddleSeg提供了全面的数据增强能力。因为在视觉领域,数据非常关键,尤其是数据的预处理对整体效果的影响非常大。模型框架层面,PaddleSeg提供了几乎所有的主流网络。在部署的环节,PaddleSeg提供了大量的辅助工具,方便开发者部署语义分割的技术和模型。
PaddleSeg的几个主要特性:一、10+中数据增强策略提升了模型的鲁棒性;二、PaddleSeg几乎覆盖了主流的模型;三,性能得到了了全方位的提升;四,部署能力更加强大。跟一些主流的模型的对比,不管是单卡还是双卡上,训练的速度、利用率、显存的占用,以及可以训练的Max Batch Size,PaddleSeg都有显著的优势。
PaddleSeg的应用场景非常广泛,包括智能工业、智能图像、智能农业等等。利用PaddleSeg,模型部署后的预测性能比其他同类产品要提升20%以上。
https://github.com/PaddlePaddle/PaddleSeg
图像分割和检测有非常密切的关联性。Paddle Detection发布了60多个预训练模型,并且包括多个在以往竞赛当中夺冠的算法模型。它提供了一整套的检测框架,方便开发者适配、调整算法。另外,Paddle Detection提供了大量的组块化模块,调整起来非常非常方便。
此外,Paddle Detection提供了非常多的小模型,所谓的小模型就是它能够在移动设备上跑得足够快。更多的小模型可以方便开发者在移动端设备使用目标检测功能。
Paddle Detection也跟PaddleSlim、PaddleLite的能力全面打通,开发者可以对检测模型进行快速压缩,并且适配到移动端设备,最后进行应用。
性能方面,用YOLOv3模型进行测试,Paddle Detection实现的速度是对标产品1.4倍。另外它的显存占用更少,降低了30%。
车流的识别、安防监控等都非常依赖于目标检测技术,因此Paddle Detection有非常广泛的应用场景。
https://github.com/PaddlePaddle/PaddleDetection
CTR预估模型在工业场景当中应用非常多,而且跟资源调度有非常紧密的关联。因此ElasticCTR目前跟Kuberflow和华为的Volcano进行了深度集成,并在分布式训练的环节提供了全异步的参数服务器技术,实现超大规模的CTR预估能力的工业化部署。ElasticCTR还提供了高性能的KV预估以及一键部署功能,方便开发者真正使用ElasticCTR的能力。
性能方面,在大规模的数据场景中,ElasticCTR能够进行快速更新,并且工业级部署的性能是对标产品的13倍。
https://www.paddlepaddle.org.cn/documentation/docs/zh/1.6/user_guides/howto/training/deploy_ctr_on_baidu_cloud_cn.html
刚才介绍了框架层、模型层以及开发套件,接下来介绍几个重要的工具组件。
首先是PaddleHub。PaddleHub集成了预训练模型和迁移学习的工具,这次的升级增加了两个核心能力:一是自动化调参,基于一键自动超参搜索;二是进一步夯实了一键模型化服务的能力,开发者可以很容易把自己想要用的模型快速变成服务。
为了提升易用性,PaddleHub的API采用了高层封装,包含迁移任务、迁移策略和数据处理等,方便开发者使用,在解决了开发效率的问题的同时,保持了灵活性。
https://github.com/PaddlePaddle/PaddleHub
此次峰会上,PaddlePaddle发布三个新的工具组件:一是PALM多任务学习组件,ERNIE模型里面用到的一个核心能力就是多任务学习,通过多任务学习,把多个任务的表示层进行共享,从而提升整个模型的效率;二是PGL图神经网络,在数据量非常大的情况下,也有非常好的模型建模能力,利用这种图神经网络,能够解决原来很多模型无法解决的问题;三是PaddleFL联邦学习。
PALM底层有很多基础的模块,包括一些预置的网络、学习任务和数据处理。同时PAML上层还有组装层,因为多任务学习需要很好的组装和调度。这也意味着,PALM已经替开发者做好了底层的工作。在运行环节,PALM提供了高效的运行和快速部署的能力,使得多任务学习在真正的实践任务当中可以应用的更广。目前,开发者只需要20行左右的代码,就可以同时训练多个任务来提升模型效果,比如文本分类等。
https://github.com/PaddlePaddle/PALM
图神经网络的应用越来越广泛,尤其是在推荐场景,它的建模能力更加强大。这次PaddlePaddle正式发布了PGL 1.0版本,它有几个主要特性:一是高效,它充分利用了PaddlePaddle核心框架的LoD-Tensor(Level-of-Detail Tensor)进行消息聚合,使得速度有非常大的提升;二是易用性,PGL在接口的设计上进行了大量的工作,方便开发者使用;三是算法模型非常丰富;四是规模非常大,可以支持分布式的图引擎,支持10亿节点、百亿巨图的训练,PALM其实跟PaddlePaddle的分布式训练是一脉相承的,图的规模跟分布式训练的扩展能力有非常大的关系。
https://github.com/PaddlePaddle/PGL
联邦学习是针对数据隔离、数据安全等问题的一种解决手段。面向深度学习任务做联邦学习,有很多特有的挑战。PaddleFL主要是面向深度学习进行设计,包括几个比较重要的方面:一是联邦学习的策略,目前PaddleFL集成了比较多的横向、纵向联邦学习策略;另外,PaddleFL也集成了多种训练方法。它的应用场景非常多,目前百度已经开始在推荐场景中开始尝试使用联邦学习。
https://github.com/PaddlePaddle/PaddleFL
PARL这次也有重要的升级,包括并行训练的接口、文档、算法等。强化学习在机器人控制领域有非常多的应用,利用强化学习做自动控制,有非常显著的优势,可以真正做自动控制。
https://github.com/PaddlePaddle/PARL
服务平台
PaddlePaddle的全景图里面还有一层非常关键,就是全面的服务平台,这个服务平台给开发者提供了很多额外的价值。
在经典版的基础上,PaddlePaddle这次新增了EasyDL专业版,开发者可以利用EasyDL的算力开发自己的AI模型。同时百度还面向零售等场景定制了EasyDL行业版。
EasyDL专业版主要包含以下几个特性:模型更加完善,数据服务更好,部署能力更灵活,而且支持飞桨Master模式,基于预训练模型进行快速的迁移学习和定制。此外,EasyDL提供了完善的数据标注服务,可以节约数据标注的成本,并且支持端云结合部署,以及公有云私有化部署。EasyDL已经成为一个面向AI模型开发和部署的全流程平台。
除了EasyDL,另外一个跟PaddlePaddle关联度非常高的是AI Studio平台。AI Studio是深度学习开发者学习、交流和开发实训的平台。AI Studio包含了大量的学习的课程和开源项目,以及大量的比赛。
EasyEdge平台的目的是为了进一步减少端计算开发者的工作量,降低模型部署的门槛。目前EasyEgde是基于Paddle Lite核心开发框架,提供软硬一体的能力给开发者使用。同时,EasyEdge把很多设备的兼容等问题进行了封装,开发者可以非常便捷地在多种硬件上快速开发。
上个月的乌镇世界互联网大会,百度董事长李彦宏谈到了一个对未来的判断:“人工智能正在驱动数字经济向智能经济进化”。但是百度如何争抢人工智能时代的话语权?
2018 年 7 月,李彦宏在百度AI开发者上喊出了要让“Everyone Can AI”的口号,其实这句口号后面还要加上一个限定——“通过百度的AI平台”。 这也意味着,PaddlePaddle是这场攻坚战中的突破点之一。
在这次峰会上,百度也发布了完整的开发者激励计划:一是10多门课程进行全方位的免费开放;二是百度将辅助100多所高校,进行深度学习教育的培训;三是辅助1000企业,助力AI业务转型;四是发布百万级竞赛奖金,推动各种各样AI竞赛的开展;五是亿级GPU算力资源的支持,支撑开发者更好地使用PaddlePaddle平台。
从个人开发者,到高校开发者,再到企业开发者,一切都是为了壮大PaddlePaddle的生态圈,促进百度的AI落地。
百度AI生态大战的炮声已经响起,这将是一场持久的攻坚战,而PaddlePaddle是这场战役的核心。只有让听到炮声的人呼唤炮火,才能看到PaddlePaddle的突围。
(*本文为AI科技大本营原创文章, 转载 请微 信联系 1092722531 )
12月6-8日,深圳!2019嵌入式智能国际大会,集聚500+位主流AIoT中坚力量,100+位海内外特邀技术领袖!9场技术论坛布道,更有最新芯片和模组等新品展示!点击链接或扫码,输入本群专属购票优惠码CSDNQRSH,即可享受6.6折早鸟优惠,比原价节省1000元,学生票仅售399元。
推荐阅读 以上是关于百度AI攻坚战:PaddlePaddle中国突围的主要内容,如果未能解决你的问题,请参考以下文章
热点荟萃百度推出超级AI PaddlePaddle;2016世界互联网工业大会青岛举行……
钛智能 | 李彦宏:PaddlePaddle不如TensorFlow | ABCD每日必读 · 0826
基于容器的AI系统开发——百度PaddlePaddle解析
大学生为百度PaddlePaddle写书,搞好AI教育要抓这四点
百度世界2017AI技术划重点:PaddlePaddle视觉技术升级
百度×科赛 PaddlePaddle AI 大赛开赛啦