浏览器原理 21 # DOM树:JavaScript是如何影响DOM树构建的?
Posted 凯小默
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浏览器原理 21 # DOM树:JavaScript是如何影响DOM树构建的?相关的知识,希望对你有一定的参考价值。
说明
浏览器工作原理与实践专栏学习笔记
什么是 DOM
从网络传给渲染引擎的 html 文件字节流是无法直接被渲染引擎理解的,需要将其转化为渲染引擎能够理解的内部结构,这个结构就是 DOM。
在渲染引擎中,DOM 有三个层面的作用:
- 页面:DOM 是生成页面的基础数据结构
- javascript 脚本:DOM 提供给 JavaScript 脚本操作的接口,通过这套接口,JavaScript 可以对 DOM 结构进行访问,从而改变文档的结构、样式和内容
- 安全:DOM 是一道安全防护线,过滤一些不安全的内容
DOM 树如何生成
在渲染引擎内部,有一个叫 HTML 解析器(HTMLParser)的模块,它的职责就是负责将 HTML 字节流转换为 DOM 结构。
HTML 解析器(HTMLParser)
Q:HTML 解析器是等整个 HTML 文档加载完成之后开始解析的,还是随着 HTML 文档边加载边解析的?
A:HTML 解析器并不是等整个文档加载完成之后再解析的,而是网络进程加载了多少数据,HTML 解析器便解析多少数据。
详细过程:
- 网络进程接收到响应头之后,会根据响应头中的
content-type字段来判断文件的类型是不是 HTML 类型的文件 - 如果
content-type的值是text/html,表明是 HTML 类型的文件,然后为该请求选择或者创建一个渲染进程。 - 网络进程和渲染进程之间会建立一个共享数据的管道,网络进程接收到字节流后就往这个管道里面放
- 而渲染进程则从管道的另外一端不断地读取数据,并同时将读取的数据给 HTML 解析器。
- HTML 解析器会动态接收字节流,并将其解析为 DOM。
字节流转换为 DOM:
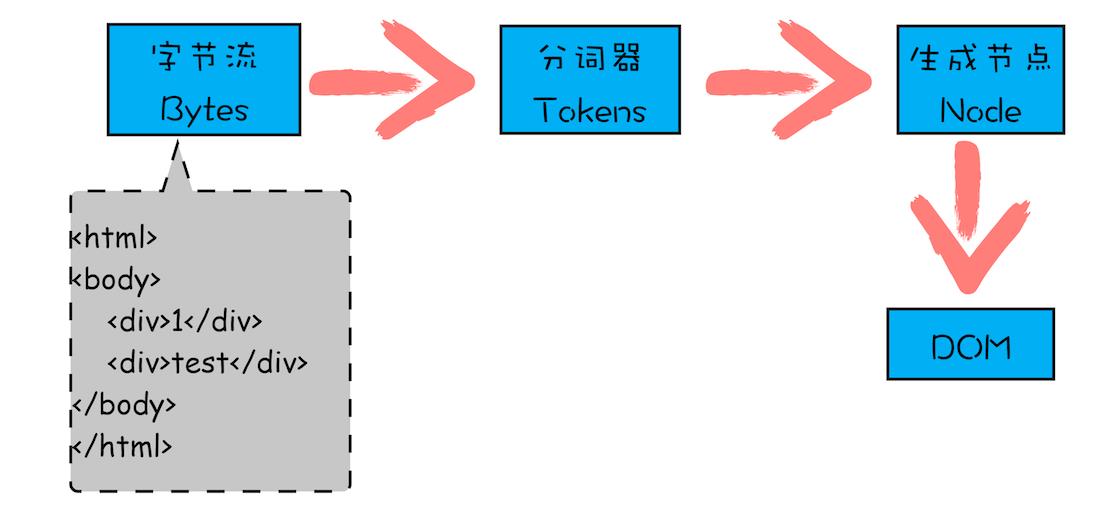
第一个阶段,通过分词器将字节流转换为 Token。
HTML 解析器维护了一个 Token 栈结构,该 Token 栈主要用来计算节点之间的父子关系。
生成的 Token 压到这个栈的规则:
- 如果压入到栈中的是
StartTag Token,HTML 解析器会为该 Token 创建一个 DOM 节点,然后将该节点加入到 DOM 树中,它的父节点就是栈中相邻的那个元素生成的节点。 - 如果分词器解析出来是
文本 Token,那么会生成一个文本节点,然后将该节点加入到 DOM 树中,文本 Token 是不需要压入到栈中,它的父节点就是当前栈顶 Token 所对应的 DOM 节点。 - 如果分词器解析出来的是
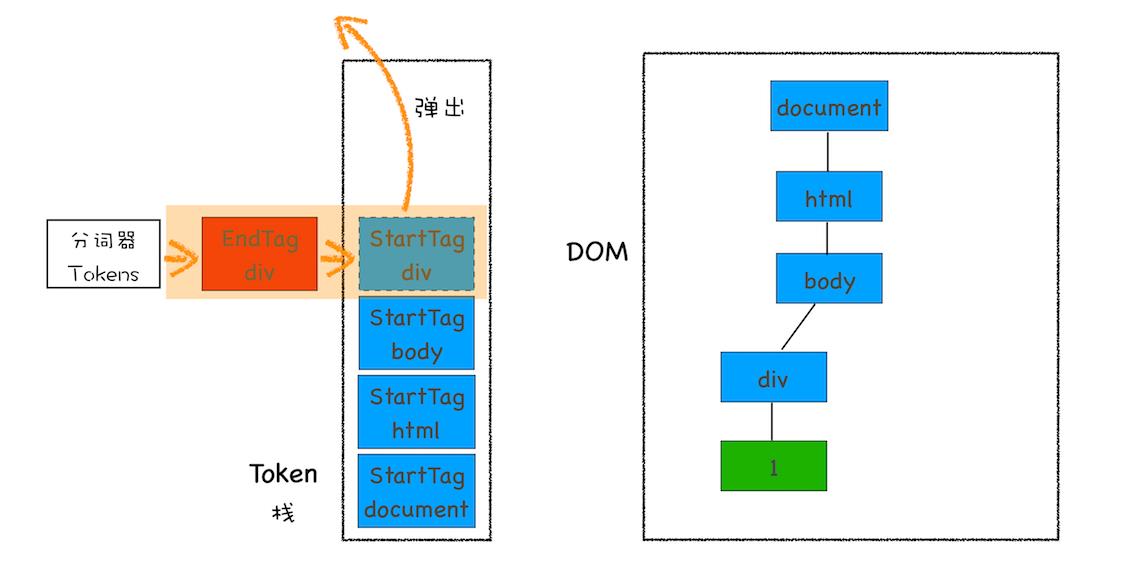
EndTag 标签,比如是 EndTag div,HTML 解析器会查看 Token 栈顶的元素是否是 StarTag div,如果是,就将 StartTag div 从栈中弹出,表示该 div 元素解析完成。

第二个和第三个阶段是同步进行的,需要将 Token 解析为 DOM 节点,并将 DOM 节点添加到 DOM 树中。
通过分词器产生的新 Token 就这样不停地压栈和出栈,整个解析过程就这样一直持续下去,直到分词器将所有字节流分词完成。
通过例子理解 DOM 树的生成过程
例子:
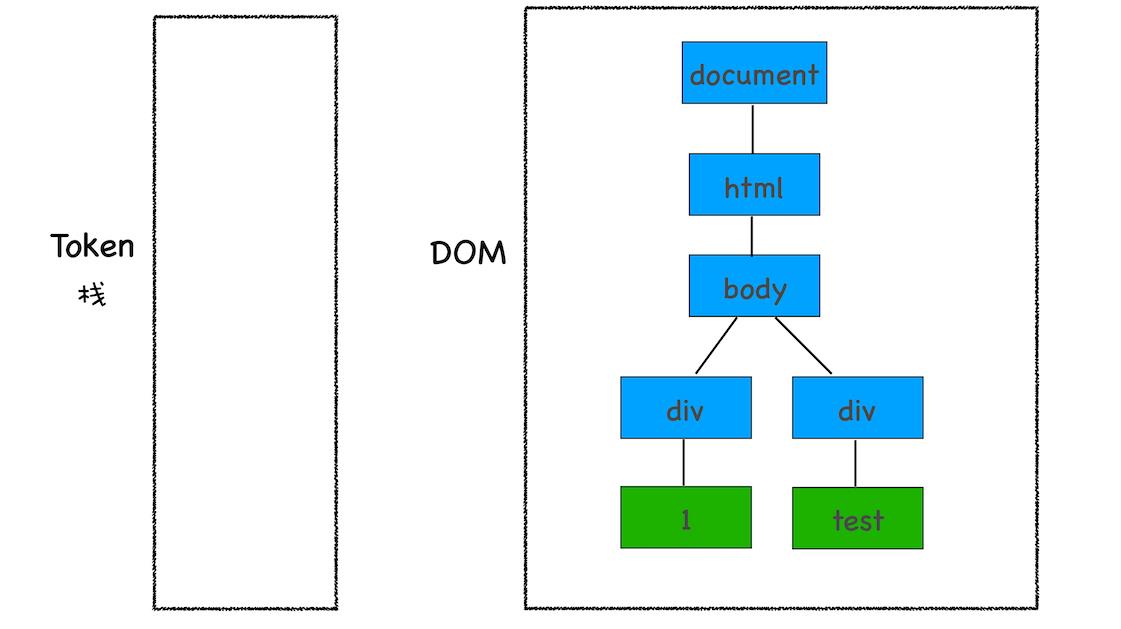
<html>
<body>
<div>1</div>
<div>test</div>
</body>
</html>
根据上面 HTML 解析器的分析
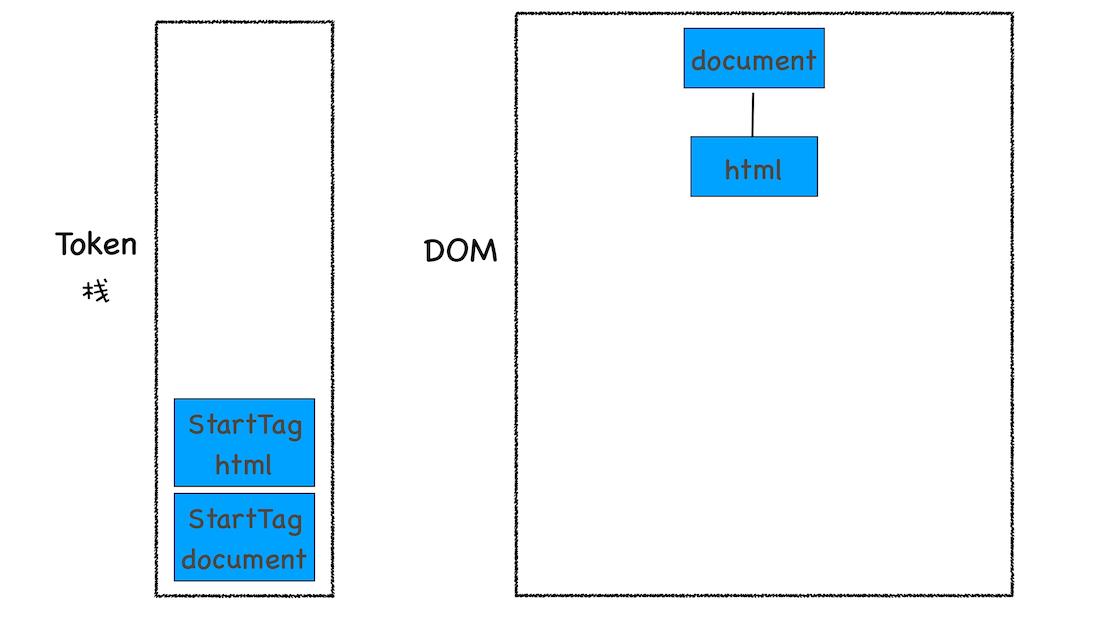
补充说明:HTML 解析器开始工作时,会默认创建了一个根为 document 的空 DOM 结构,同时会将一个 StartTag document 的 Token 压入栈底。然后经过分词器解析出来的第一个 StartTag html Token 会被压入到栈中,并创建一个 html 的 DOM 节点,添加到 document 上:
1、解析到 StartTag html 时的状态
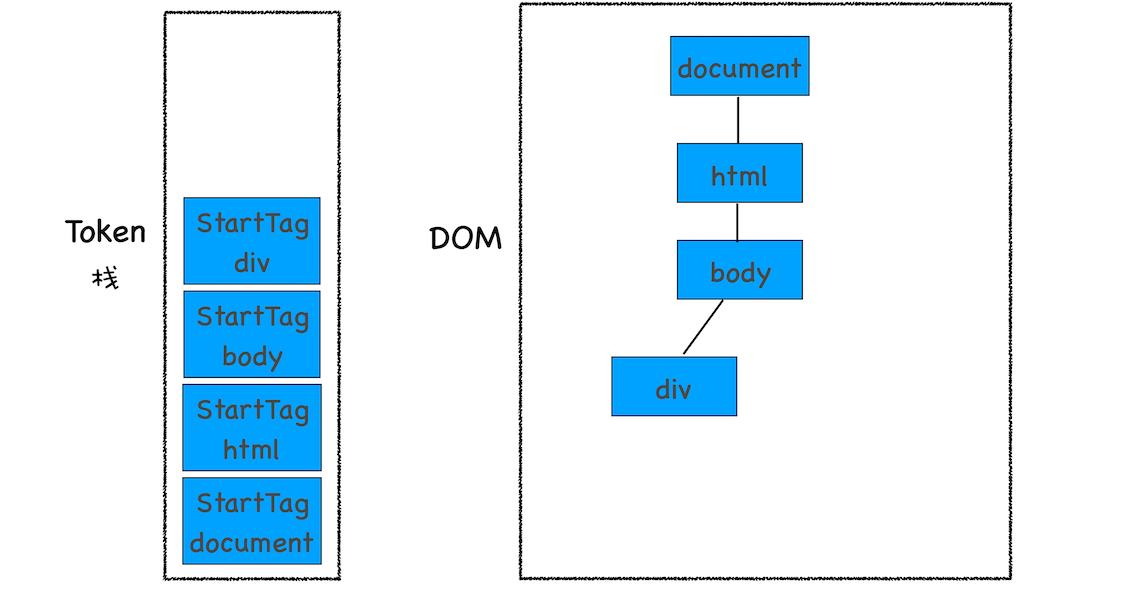
2、解析到 StartTag div 时的状态
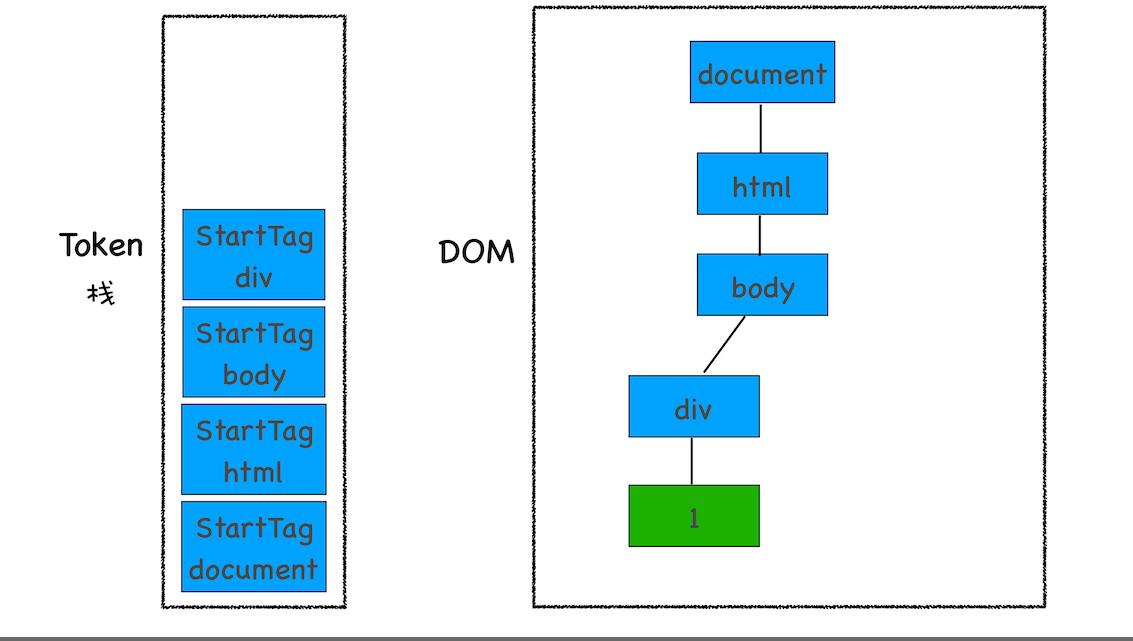
3、解析出第一个文本 Token 时的状态
4、元素弹出 Token 栈示意图
5、最终解析结果
JavaScript 是如何影响 DOM 生成的
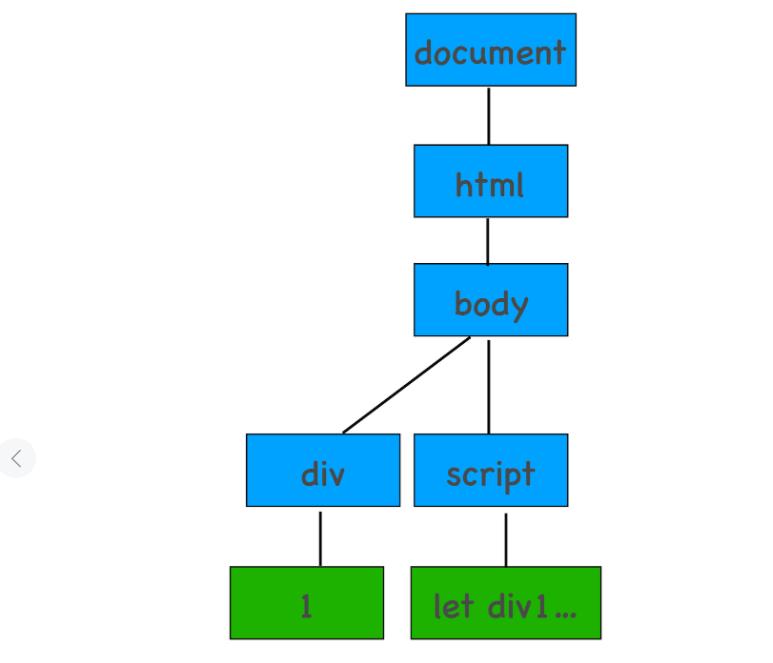
例子1:
<html>
<body>
<div>1</div>
<script>
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang'
</script>
<div>test</div>
</body>
</html>
执行脚本时 DOM 的状态:HTML 解析器会暂停工作,JavaScript 引擎介入,并执行 script 标签中的代码
例子2:页面中引入 JavaScript 文件
//foo.js
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang'
<html>
<body>
<div>1</div>
<script type="text/javascript" src='foo.js'></script>
<div>test</div>
</body>
</html>
执行到 JavaScript 标签时,暂停整个 DOM 的解析,执行 JavaScript 代码,而这里需要先进行 JavaScript 文件的下载,这个过程会阻塞 DOM 解析。
优化 JavaScript 线程阻塞 DOM 的方法:
预解析操作
当渲染引擎收到字节流之后,会开启一个预解析线程,用来分析 HTML 文件中包含的 JavaScript、CSS 等相关文件,解析到相关文件之后,预解析线程会提前下载这些文件。
其他策略
- 使用 CDN 来加速 JavaScript 文件的加载
- 压缩 JavaScript 文件的体积
- 将 JavaScript 脚本设置为异步加载,通过 async 或 defer 来标记代码
async 跟 defer 区别:使用 async 标志的脚本文件一旦加载完成,会立即执行;而使用了 defer 标记的脚本文件,需要在
DOMContentLoaded事件之前执行。
<script async type="text/javascript" src='foo.js'></script>
<script defer type="text/javascript" src='foo.js'></script>
补充
渲染引擎还有一个安全检查模块叫 XSSAuditor,是用来检测词法安全的。在分词器解析出来 Token 之后,它会检测这些模块是否安全,比如是否引用了外部脚本,是否符合 CSP 规范,是否存在跨站点请求等。如果出现不符合规范的内容,XSSAuditor 会对该脚本或者下载任务进行拦截。
CSP 规范可以参考文章
以上是关于浏览器原理 21 # DOM树:JavaScript是如何影响DOM树构建的?的主要内容,如果未能解决你的问题,请参考以下文章
根据浏览器渲染引擎工作原理(reflow/repaint),来优化DOM的操作