数据挖掘原理与实践 第四章作业
Posted 喵喵喵喵要抱抱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘原理与实践 第四章作业相关的知识,希望对你有一定的参考价值。
P147
4.2
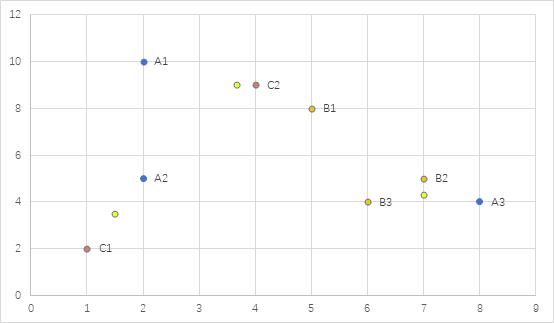
假设数据挖掘的任务是将如下的8个点(用 (x,y) 代表位置)聚类为三个簇:A1 (2,10),A2(2,5),A3(8,4),B1(5,8),B2(7,5),B3(6,4),C1(1,2),C2(4,9)。距离函数是 Euclidean 函数。假设初始我们选择 A1、B1 和 C1 为每个簇的中心,用 k-means 算法来给出。
(1) 在第一次循环执行后的三个簇中心。
(2) 最后的三个簇中心及簇包含的对象。
Euclidean 为欧式距离,该距离公式如下:
初始选择A1、B1和C1为每个簇的中心:
第一轮
P1(2,10):A1(2,10)
P2(5,8):B1(5,8),A3(8,4),B2(7,5),B3(6,4),C2(4,9)
P3(1,2):C1(1,2),A2(2,5)
对应中心分别是(2,10),(6,6),(1.5,3.5)
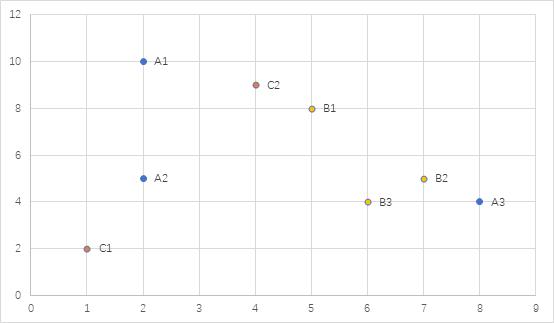
第二轮
P1(2,10):A1(2,10),C2(4,9)
P2(6,6):A2(2,5),C1(1,2)
P3(1.5,3.5):B1(5,8),A3(8,4),B2(7,5),B3(6,4)
对应中心分别是(3,9.5),(1.5,3.5),(6.5,5.25)
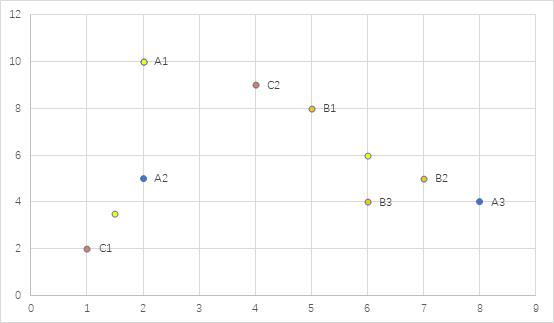
第三轮
P1(3,9.5):A1(2,10),B1(5,8),C2(4,9)
P2(1.5,3.5):A2(2,5),C1(1,2)
P3(6.5,5.25): A3(8,4),B2(7,5),B3(6,4)
对应中心分别是(3.67,9),(1.5,3.5),(7,4.33)
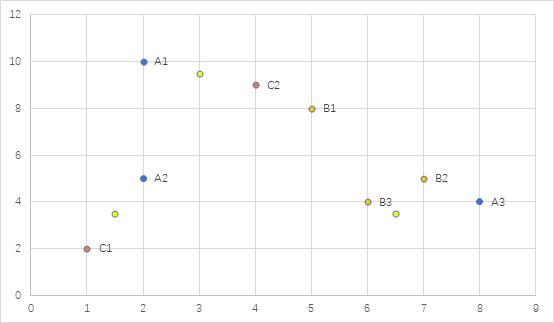
第四轮
P1(3.67,9):A1(2,10),B1(5,8),C2(4,9)
P2(1.5,3.5):A2(2,5),C1(1,2)
P3(7,4.33): A3(8,4),B2(7,5),B3(6,4)
对应中心分别是(3.67,9),(1.5,3.5),(7,4.33)
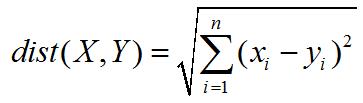
答:
(1)在第一次循环执行后的三个簇中心为:(2,10),(6,6),(1.5,3.5);
(2)最后的三个簇中心及簇包含的对象为{A1(2,10),B1(5,8),C2(4,9)},{A3(8,4),B2(7,5),B3(6,4)},{C1(1,2),A2(2,5)};
4.3
聚类被广泛地认为是一种重要的数据挖掘方法,有着广泛的应用。对如下每种情况给出一个应用例子。
(1) 采用聚类作为主要的数据挖掘方法的应用。
(2) 采用聚类作为预处理工具,为其它数据挖掘任务作数据准备的应用。
答:
(1) 如电子商务网站中的客户群划分。根据客户的个人信息、消费习惯、浏览行为等信息,计算客户之间的相似度,然后采用合适的聚类算法对所有客户进行类划分;基于得到的客户群信息,相关的店主可以制定相应的营销策略,如交叉销售,根据某个客户群中的其中一个客户的购买商品推荐给另外一个未曾购买此商品的客户。
(2) 如电子商务网站中的推荐系统。电子商务网站可以根据得到的客户群,采用关联规则或者隐马尔科夫模型对每个客户群生成消费习惯规则,检测客户的消费模式,这些规则或模式可以用于商品推荐。其中客户群可以通过聚类算法来预先处理获取得到。
4.6
总SSE是每个属性的SSE之和。如果对于所有的簇,某变量的 SSE 都很低,这意味什么?如果只对一个簇很低呢?如果对所有的簇都很高?如果仅对一个簇高呢?如何使用每个变量的 SSE 信息改进聚类?
SSE(和方差):The sum of squares due to error
描述拟合数据和原始数据对应点的误差的平方和
SSE越接近于0,说明模型选择和原数据拟合更好,数据预测也越好。
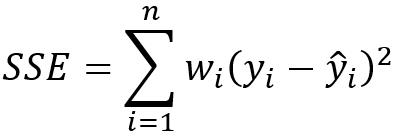
答:
(1) 如果对于所有的簇,某属性的SSE都很低,那么该属性值变化不大,本质上等于常量,对数据的分组没什么用处。
(2) 如果某属性的SSE只对一个簇很低,那么该属性有助于该簇的定义。
(3) 如果对于所有的簇,某属性的SSE都很高,那么意味着该属性是噪声属性。
(4) 如果某属性的SSE仅对一个簇很高,那么该属性与定义该簇的属性提供的信息不一致。在少数情况下,由该属性定义的簇不同于由其他属性定义的簇,但是在某些情况下,这也意味着该属性不利于簇的定义。
(5) 消除簇之间具有小分辨力的属性,比如对于所有簇都是低或高SSE的属性,因为他们对聚类没有帮助。对于所有簇的SSE都高且相对其他属性来说SSE也很高的属性特别麻烦,因为这些属性在SSE的总和计算中引入了很多的噪声。
4.7
使用基于中心、邻近性和密度的方法,识别图 4-19 中的簇。对于每种情况指出簇个数,并简要给出理由。注意,明暗度或点数指明密度。如果有帮助,假定基于中心即 K 均值,基于邻近性即单链,而基于密度为 DBSCAN。
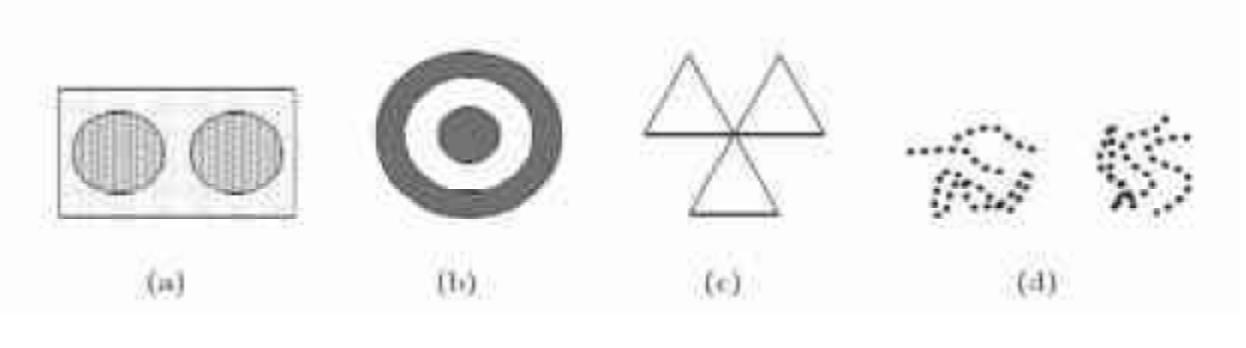

答:
a) 基于中心的方法有2个簇。矩形区域被分成两半,同时2个簇里都包含了噪声数据;基于邻近性的方法有1个簇。因为两个圆圈区域受噪声数据影响而形成一个簇;基于密度的方法有2个簇,每个圆圈区域代表一个簇,而噪声数据会被忽略。
b) 基于中心的方法有1个簇,该簇包含图中的一个圆环和一个圆盘;基于邻近性的方法有2个簇,外部圆环代表一个簇,内层圆盘代表一个簇;基于密度的方法有2个簇,外部圆环代表一个簇,内层圆盘代表一个簇。
c) 基于中心的方法有3个簇,每个三角形代表一个簇;基于邻近性的方法有1个簇,三个三角形区域会联合起来因为彼此相互接触;基于密度的方法有3个簇,每个三角形区域代表一个簇。即使三个三角形相互接触,但是所接触的区域的密度比三角形内的密度小。
d) 基于中心的方法有2个簇。两组线被分到两个簇里;基于邻近性的方法有5个簇。相互缠绕的线被分到一个簇中;基于密度的方法有2个簇。这两组线定义了被低密度区域所分割的两个高密度的区域。
以上是关于数据挖掘原理与实践 第四章作业的主要内容,如果未能解决你的问题,请参考以下文章