数据挖掘原理与实践 第六章作业
Posted 喵喵喵喵要抱抱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘原理与实践 第六章作业相关的知识,希望对你有一定的参考价值。
6.1
为什么离群点挖掘是重要的?
答:离群点是指与大部分其它对象不同的对象,在数据的散布图中,它们远离其它数据点,其属性值显著地偏离期望的或常见的属性值。
(1) 因为离群点可能是度量或执行错误所导致的,例如相对少的离群点可能扭曲一组值的均值和标准差,或者改变聚类算法产生的簇的集合。
(2) 因为离群点本身可能是非常重要的,隐藏着重要的信息,在欺诈检测,入侵检测等方面有着广泛的应用。所以离群点挖掘是非常重要的。
6.3
许多用于离群点检测的统计检验方法是在这样一种环境下开发的:数百个观测就是一个大数据集。我们考虑这种方法的局限性:
(a) 如果一个值与平均值的距离超过标准差的三倍,则检测称它为离群点。对于1000000个值的集合,根据该检验,有离群点的可能性有多大?(假定正态分布);
(b) 一种方法称离群点是具有不寻常低概率的对象。处理大型数据集时,该方法需要调整吗?如果需要,如何调整?
答:
(a) 如果指的是单面的点的距离超过标准差的3倍,那么概率就是0.00135,则有1350个离群点;如果指的是两面的点的距离超过标准差的3倍,那么概率就是0.0027,则有2700个离群点。
(b) 具有百万个对象的数据集中,有成千上万个离群点,我们可以接受它们作为离群点或者降低临界值用以减少离群点。
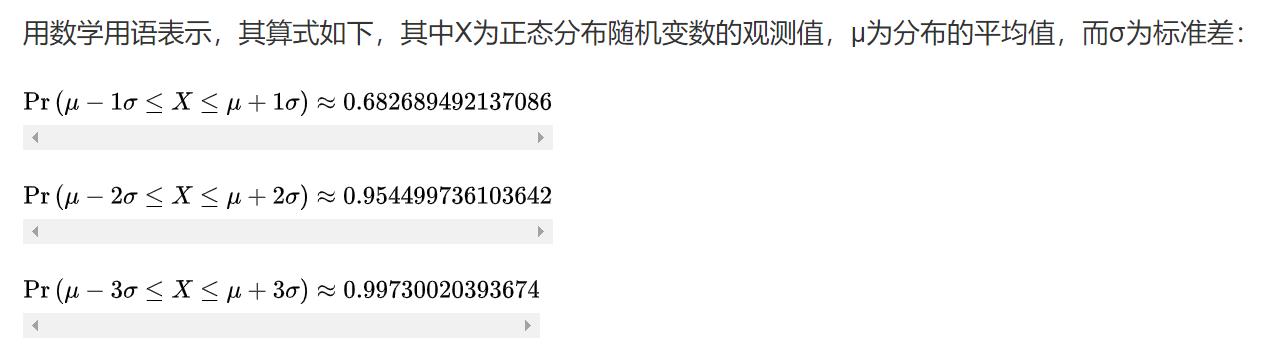
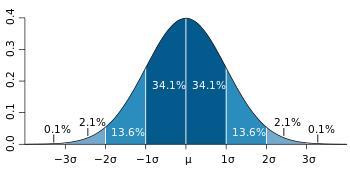
3σ法则:
在正态分布中σ代表标准差,μ代表均值x=μ即为图像的对称轴
三σ原则即为
数值分布在(μ—σ,μ+σ)中的概率为0.6827
数值分布在(μ—2σ,μ+2σ)中的概率为0.9545
数值分布在(μ—3σ,μ+3σ)中的概率为0.9973
可以认为,Y 的取值几乎全部集中在(μ—3σ,μ+3σ)]区间内,
超出这个范围的可能性仅占不到0.3%
6.7
一个数据分析者使用一种离群点检测算法发现了一个离群子集。出于好奇,该分析者对这个离群子集使用离群点检测算法。
(a) 讨论本章介绍的每种离群点检测技术的行为。(如果可能,使用实际数据和算法来做);
(b) 当用于离群点对象的集合时,你认为离群点检测算法将做何反应?
答:
(a) 在某些情况下,以统计学为基础的异常检测技术,在离群子集上使用这将是无效的使用技术,因为这种检测方法的假设将不再成立。对于那些依赖于模型的方法也是如此。以邻近点为基础或者以密度为基础的方法主要取决于特定的技术。如果保留原来的参数,使用距离或密度的绝对阈值的方法会将异常归类为一个异常对象的集合。其他相关方法会将大部分异常归类为普通点或者将一部分归类为异常。
(b) 一个对象是否异常取决于整个对象的集合。因此,期望一种异常检测技术能够辨别一个异常集合,就像原始集合中并不存在这样一个异常集合,这是不合理的。
以上是关于数据挖掘原理与实践 第六章作业的主要内容,如果未能解决你的问题,请参考以下文章