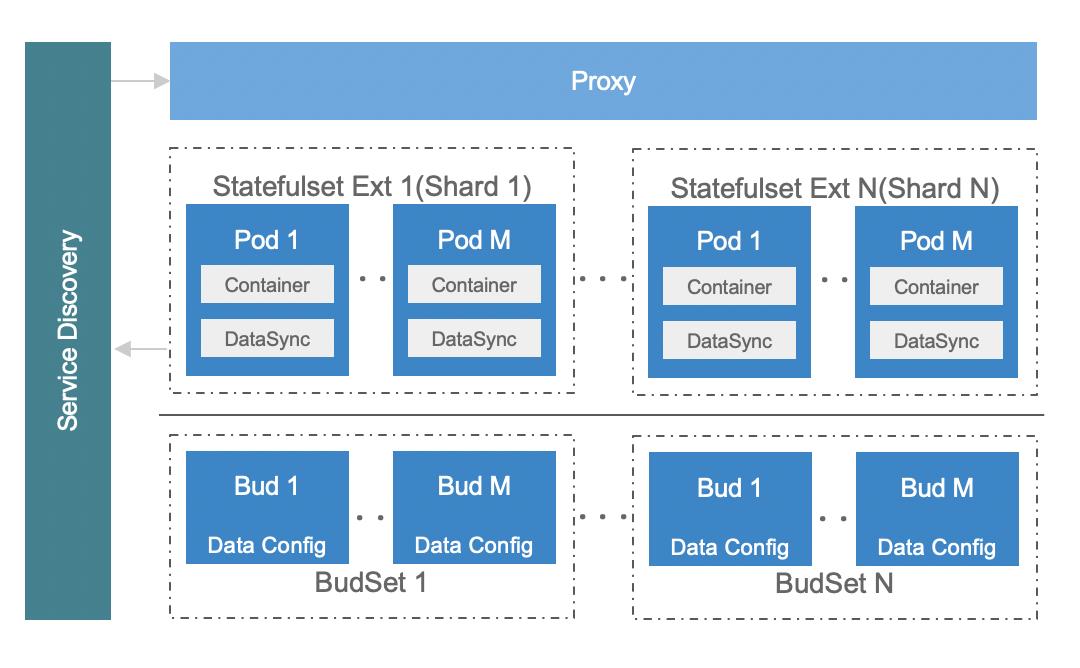
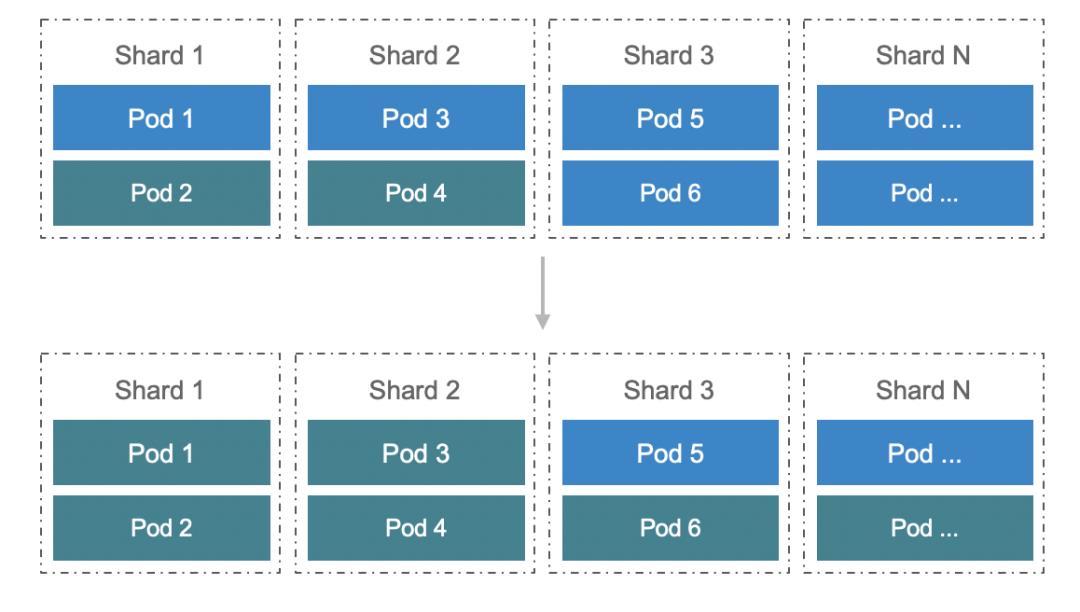
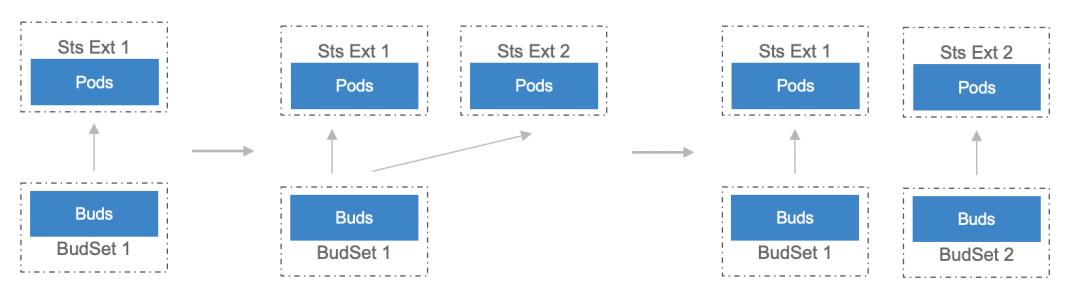
扩容 Data Shard:需要把数据分片的数量扩容。这种情况目前只支持成倍扩展,细分为几个步骤,可以看下图:
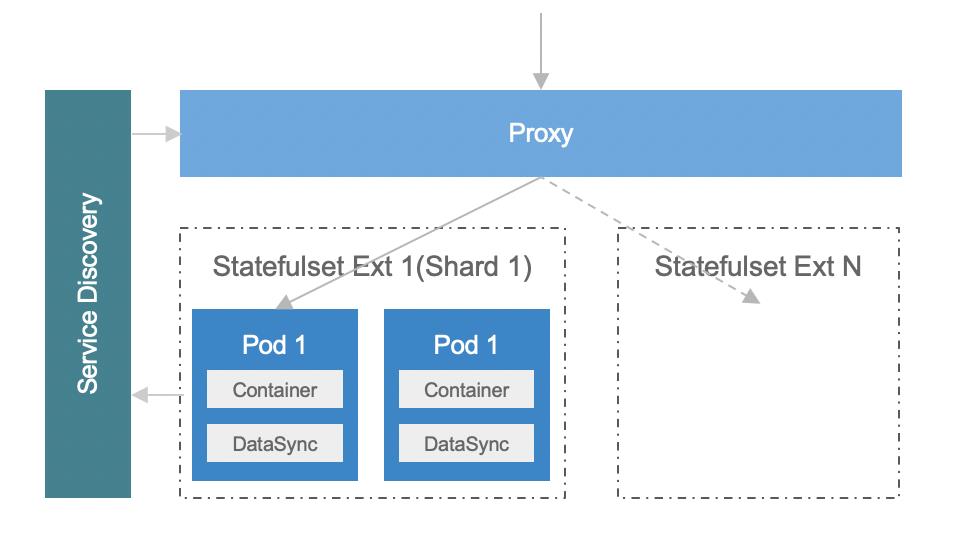
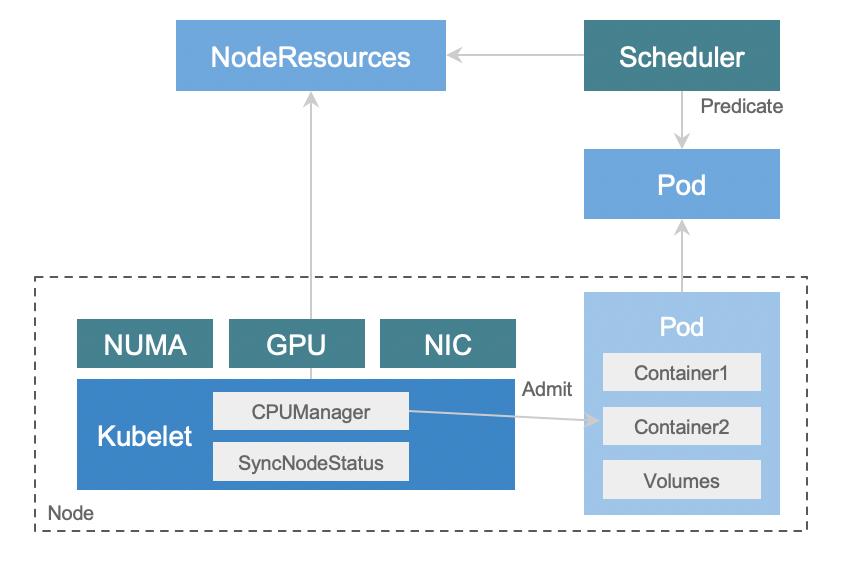
假设一开始只有全量数据,全都存在 Budset 1。Statefulset Extention 1 里的 Pod 全都加载了 Budset 1 的数据。做成倍扩展的时候,第一步是扩容 Statefulset。这时 Statefulset Extention 1、2 里面数据都是全量数据。之后再来更新 Budset,原来全量数据会被切成两个 Shard,这些过程都完成之后会再去更新服务发现,这个时候 Statefuleset Extention 2 的 Pod 才会正式承接流量。这时其实有一个问题:在 Budset 变更的时候,两个 Statefulset Extention 的 Pod 里的数据依然是全量的。这个时候我们跟业务框架有一些配合工作,有一些业务可能自己定义了数据退场 TTL 逻辑,这时只要等待数据冷却就可以了。此外,还有些业务自定义触发数据的 Compaction,把多余的数据驱逐掉。K8sMeetup服务发现与路由服务发现与路由包括两个要点。前面的例子提到过,有状态服务实例形成的矩阵中,每一列 Pod 对外提供不同 Data Shard 的数据服务。因此当一个请求来的时候,需要知道它是路由到哪个 Shard 的实例中。图中有一个 Proxy 业务层的组件,会统一分发请求,将请求分配给对应 Statefulset Extension 的 Pod。同时,同一个 Shard 里面存在多个 Pod 副本,由于宿主机微小的性能差异或其他原因,它们的错误率也不是完全相等的。这里就可以来做第二层路由逻辑,根据一个 Statefulset Extension 内 Pod 的错误率,进一步增强服务路由/熔断逻辑。基于这种复杂的定制的逻辑,我们并没有依赖 K8s Service 来对请求进行路由,而是通过自研的服务发现基础设施注册宿主机上的 IP 和端口,通过 KV 的方式写到 Service Discovery 这个组件里面。针对有状态服务,我们在 Service Discovery 组件里面额外注入了 ShardID、ReplicaID 和 Shard 总数等信息,方便上层框架从 KV 里读取,制定自己的熔断、路由的策略。上图展示的一个 Proxy 组件,是一种比较常见的服务形态:即把有状态服务上面做一层封装,完成路由转发。此外,请求转发其实也可以和 service mesh 进行进一步结合,通过胖客户端的方式,上游服务自己路由每一个请求到对应的 Pod 里面,以减少一层 Proxy 的开销。K8sMeetup基础能力增强我们在基础能力方面的增强主要包括调度和存储两个方面。调度调度能力方面,为了追求极致的性能优化,我们基于现代服务器的 NUMA 架构对 K8s 的 Scheduler 和 Kubelet 做了一些增强。NUMA 指非均匀内存访问架构,在一个多核处理器的标准架构中,CPU 访问不同内存的延迟是不一样的,一个处理器访问本地的内存和相对远的内存有延迟的差别。此外,不光是内存有这样的特性,GPU 设备或网卡也有这样的微拓扑亲和性,通过将服务的 Pod 绑定在与 CPU 邻近的内存 NUMA node 上,可以从系统层面极致优化服务器性能。具体做法如下:
Kubelet 通过一个 CRD 上报本节点可用微拓扑的资源量和总量。
Pod 进入调度流程时,调度器在预选阶段经过自研 predicate 选择符合微拓扑的节点。
调度器到了 priority 阶段,会通过自研 priority 尽可能堆叠 NUMA 资源分配,减少碎片。
在 Kubelet 也就是单机层面,我们会通过自研的 CPU Manager Policy 在 Pod admit 阶段把 Pod 对应的 CPU Set memory 和 NUMA node 计算好,通过原生 CRI 接口在 kubelet sync Pod 时设置这个 Pod 可以使用的 CPU 核心,以及对应的 NUMA node。
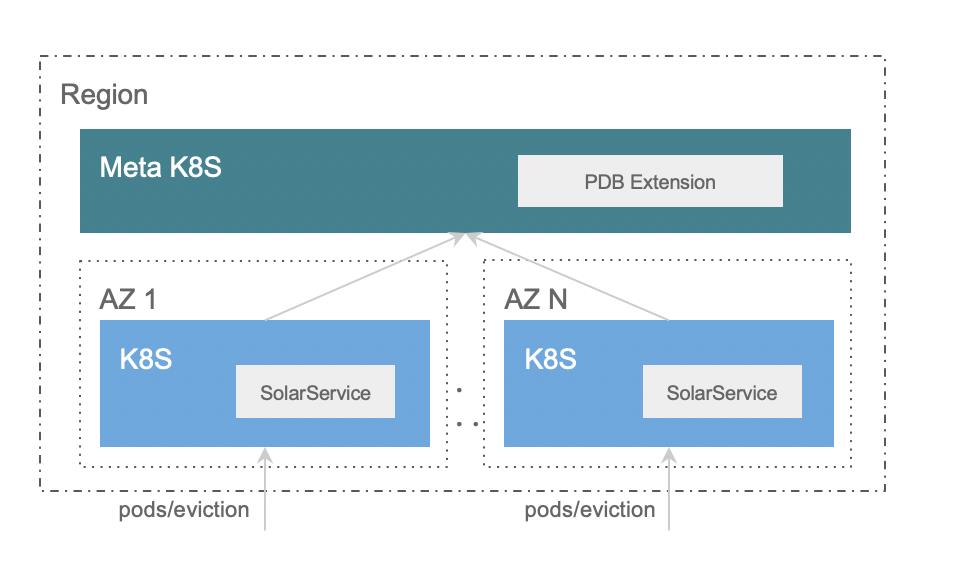
为了解决这些问题,我们通过 Pod Eviction(驱逐) 完成主机的运维。在宿主机下线之前,通过 K8s API 驱逐掉宿主机上的 Pod。之所以没有使用 delete pod 接口的主要原因是,驱逐(Eviction)会检查 K8s 的 PDB 资源,而我们就可以通过扩展 PDB (通过 webhook 的方式拦截 Evictions 请求) 自定义驱逐策略。上图介绍的是多机房驱逐的例子。一个 Region 里的多个 AZ 可能有各自的 K8s 集群,里边部署了等价的 Solarservice,隶属于同一个服务。在进行驱逐的时候就要同时考虑图中两个 AZ 之间的实例比例关系,这样不会导致一个 AZ 里的 Pod 都被驱逐干净了,此 AZ 里错误率飙升,但总数却又符合要求的情况发生。具体做法是通过跨 AZ 的 Meta K8s 中以 CRD 形式保存我们的自定义策略 PDB Extension,来检查驱逐是否合法。K8sMeetupCSI Race Condition此外云原生实践过程中也遇到了很多 CSI 的问题。在删除 Pod 时,原生 CSI 接口中有两个相应的函数:
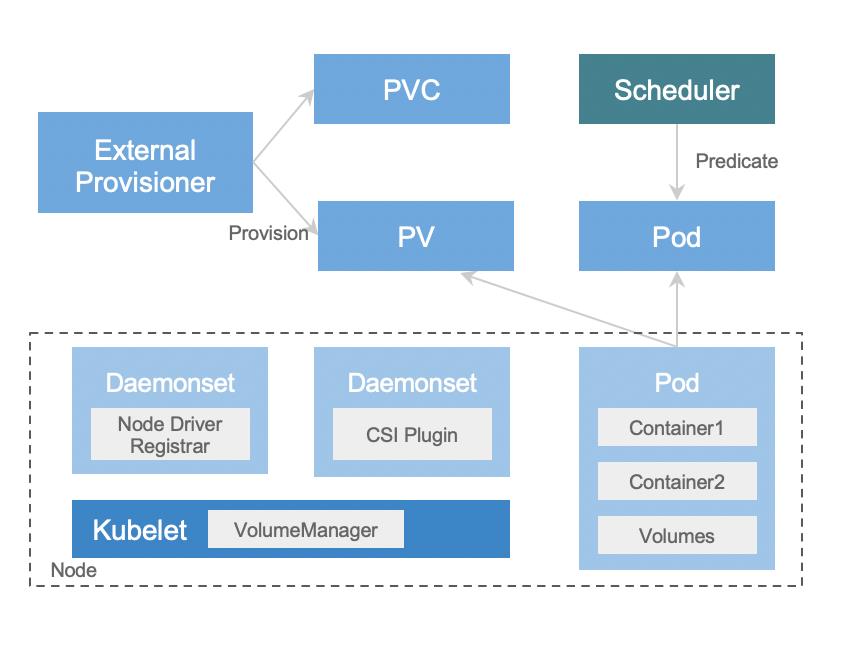
NodeUnpublishVolume:调用 CSI 对应的 driver,以清除 Pod 对应的挂载点。
NodeUnstageVolume:从节点上把卷卸载。
但是 Kubelet 删除 Pod 时,只会判断第一件事情是否完成。因此在短暂的时间窗口里,如果有运维或其他情况发生,就可能会造成 race condition。Global Mount 挂载点残留在这种情况下,执行完第一个函数清除了挂载点,但是卷还残留在宿主机上。这时如果对 Kubelet 执行重启,重启之后的 Kubelet 发现 Pod 已经被删除了,就只会看当前节点上还存活的 Pod 所使用的卷。那些未完成 unstage 的卷就不会被删除。我们的解决方案是针对 fs 类型的卷,在 Kubelet Volume Manager 增加残留挂载点扫描操作,清理残留挂载点。重复打开正在卸载的卷这种情况也是发生在 Kubelet 删除 Pod 后,NodeUnstageVolume 之前。如果一个 Pod 被删除,没有进行 unstageVolume,新的 Pod 已经创建出来,并且调度上其他节点上了,而且新的 Pod 需要挂载同一个卷,那么从存储侧发现 Kubelet 正在尝试重复挂载。例如,在前面提到的基于 NBD 的块设备,一个单读单写的模式中,新的节点开始尝试建立 NBD 连接了,旧的卷连接还保留着,那么在存储侧服务端就会发现异常并报警。Case Study最后介绍几个在对接过程中遇到的问题。前面介绍了 NBD 多块盘共享宿主机的内核,一旦宿主机由于 NBD 不稳定出现故障,会影响整台宿主机上所有的 Pod。因此我们也在积极尝试基于 Kata 的轻量级虚拟化方案,降低爆炸半径,把故障范围从宿主机粒度降低为 Pod 粒度。K8sMeetup总结在字节跳动云原生化过程中,从无状态应用逐渐进入到有状态化应用的云原生对接,有状态应用一般有如下特点: