玩转PaddleHub:无须训练即可合成毕加索画风的蒙娜丽莎和动漫
Posted 飞桨PaddlePaddle
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了玩转PaddleHub:无须训练即可合成毕加索画风的蒙娜丽莎和动漫相关的知识,希望对你有一定的参考价值。


实践效果

毕加索画风的BadApple MV
实践方法
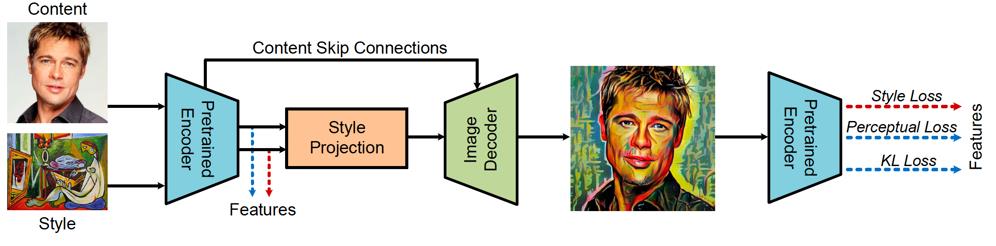
def style_transfer(self,
images=None,
alpha=1,
use_gpu=False,
visualization=True,
output_dir='transfer_result'):
-
images (list[dict]): ndarray 格式的图片数据。每一个元素都为一个 dict,有关键字 content, styles, weights(可选),相应取值为: -
content (numpy.ndarray): 待转换的图片,shape 为 [H, W, C],BGR格式; -
styles (list[numpy.ndarray]) : 作为底色的风格图片组成的列表,各个图片数组的shape 都是 [H, W, C],BGR格式; -
weights (list[float], optioal) : 各个 style 对应的权重。当不设置 weights 时,默认各个 style 有着相同的权重。 -
alpha (float) : 转换的强度,[0, 1] 之间,默认值为1; -
use_gpu (bool): 是否使用 GPU,使用GPU可以用来加快处理速度; -
visualization (bool): 是否将结果保存为图片,默认为 False; -
output_dir (str): 图片的保存路径,默认设为 transfer_result 。
1. 毕加索画风的蒙娜丽莎实现
# 导入必要的包
import cv2
import paddlehub
as hub
# 导入并加载模型
stylepro_artistic = hub.Module(name=
"stylepro_artistic")
# 风格转换
result = stylepro_artistic.style_transfer(
images=[{
'content': cv2.imread(
'target.jpg'),
# 载入《蒙娜丽莎》图像
'styles': [cv2.imread(
'style.jpg')],
# 风格采用了《双臂抱胸的女人》
'weights':[
1]
# 由于上面只选取了一个图片,所以这里只能有一个数字组成的数组
}],
alpha =
1.0,
use_gpu =
False,
visualization=
True,
output_dir=
'transvideo_result')
[
{'data': array([[[108, 166, 133],
[
62, 107, 84],
[
133, 169, 134],
...,
[
83, 141, 159],
[
85, 145, 169],
[
85, 142, 169]],
[
[106, 164, 132],
[
64, 109, 84],
[
134, 170, 136],
...,
[
91, 142, 161],
[
90, 144, 169],
[
90, 142, 170]],
[
[109, 164, 133],
[
65, 110, 86],
[
136, 171, 139],
...,
[
95, 141, 160],
[
100, 147, 173],
[
95, 144, 172]],
...,
[
[ 71, 71, 82],
[
72, 72, 83],
[
71, 66, 74],
...,
[
31, 30, 40],
[
84, 93, 113],
[
64, 77, 111]],
[
[ 71, 71, 83],
[
71, 71, 85],
[
70, 65, 75],
...,
[
30, 29, 39],
[
87, 96, 117],
[
69, 84, 119]],
[
[ 71, 71, 83],
[
72, 71, 85],
[
70, 64, 76],
...,
[
31, 30, 39],
[
87, 97, 118],
[
71, 83, 118]]], dtype=uint8),
'save_path':
'transfer_result/ndarray_1588391023.5056114.jpg'}]
import matplotlib.pyplot as plt
plt.imshow(result[
0][
'data'])
2. 毕加索画风的BadApple MV实现
每帧融合代码:
%env CUDA_VISIBLE_DEVICES=
0
# 指定GPU,很重要
# 导入必要的包
import cv2
import paddlehub
as hub
from tqdm
import tqdm
stylepro_artistic = hub.Module(name=
"stylepro_artistic")
video = cv2.VideoCapture(
"work/badapple.mp4")
# 获取帧数/s
fps = video.get(cv2.CAP_PROP_FPS)
# 获取总帧数
frameCount = video.get(cv2.CAP_PROP_FRAME_COUNT)
# 获取视频的尺寸信息
size = (int(video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(video.get(cv2.CAP_PROP_FRAME_HEIGHT)))
print(
"总共的帧数为:",frameCount)
success, frame = video.read()
file_paths = []
index =
0
for i
in tqdm(range(int(frameCount))):
# 判断是否读取帧成功,且前33帧为黑屏帧,这里不做处理,加快进度
if success
and index >
33:
result = stylepro_artistic.style_transfer(
images=[{
'content': frame,
'styles': [cv2.imread(
'work/pics/8.jpg')]
}],
use_gpu=
True,
# 有GPU时,简易使用GPU可以加速
visualization=
True,
output_dir=
'transvideo_result')
file_paths.append(result[
0][
'save_path'])
elif success:
filep =
'transvideo_result/'+str(index)+
'.jpg'
cv2.imwrite(filep, frame)
file_paths.append(filep)
success, frame = video.read()
index +=
1
整合代码:
import os
import cv2
import datetime
file_dict = {}
video = cv2.VideoCapture(
"work/badapple.mp4")
fps = video.
get(cv2.CAP_PROP_FPS)
frameCount = video.
get(cv2.CAP_PROP_FRAME_COUNT)
size = (
int(video.
get(cv2.CAP_PROP_FRAME_WIDTH)),
int(video.
get(cv2.CAP_PROP_FRAME_HEIGHT)))
# 读取图像并根据unix时间戳进行排序
for i
in os.listdir(
'transvideo_result/'):
file_dict[
'transvideo_result/'+i] =
float(i.replace(
'ndarray_',
'').replace(
'.jpg',
''))
file_dict = sorted(file_dict.items(),key = lambda x:x[
1])
videoWriter = cv2.VideoWriter(
'trans.avi', cv2.VideoWriter_fourcc(*
"MJPG"), fps, size)
flag = True
for i
in file_dict:
if flag:
# 前34帧我们直接填充黑屏帧
for j in range(34):
videoWriter.write(cv2.imread('work/target/0.jpg'))
flag = False
videoWriter.write(cv2.imread(i[
0]))
videoWriter.release()
实践总结
END
以上是关于玩转PaddleHub:无须训练即可合成毕加索画风的蒙娜丽莎和动漫的主要内容,如果未能解决你的问题,请参考以下文章