自己动手从0开始实现一个分布式RPC框架
Posted 阿里技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自己动手从0开始实现一个分布式RPC框架相关的知识,希望对你有一定的参考价值。
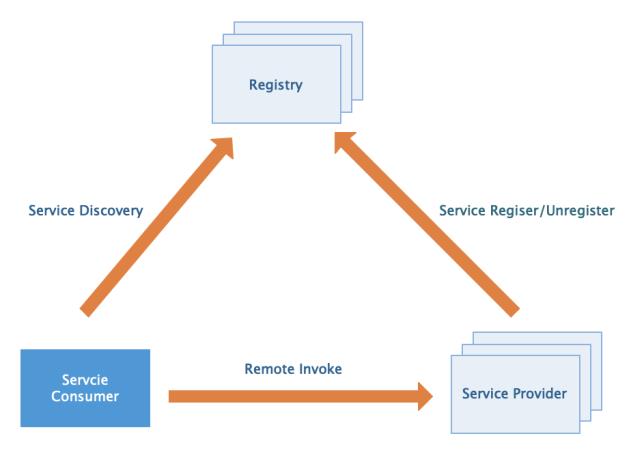
服务提供方 Serivce Provider
服务消费方 Servce Consumer
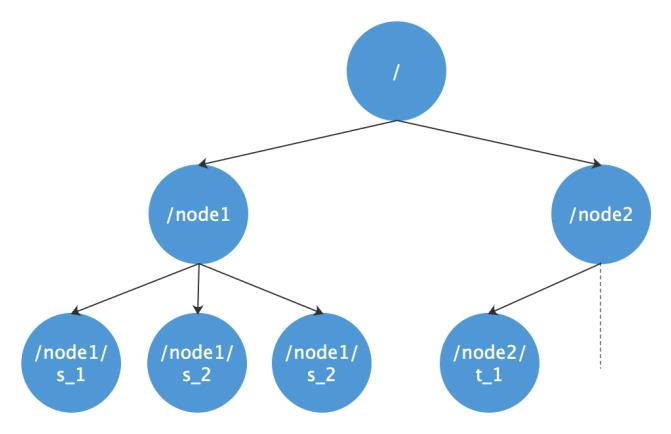
注册中心 Registery
消息定长,例如每个报文的大小为固定长度100字节,如果不够用空格补足。
在包尾特殊结束符进行分割。
将消息分为消息头和消息体,消息头中包含表示消息总长度(或者消息体长度)的字段。
+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+| BYTE | | | | | | | ........+--------------------------------------------+--------+-----------------+--------+--------+--------+--------+--------+--------+-----------------+| magic | version| type | content lenth | content byte[] | |+--------+-----------------------------------------------------------------------------------------+--------------------------------------------+
第一个字节是魔法数,比如我定义为0X35。
第二个字节代表协议版本号,以便对协议进行扩展,使用不同的协议解析器。
第三个字节是请求类型,如0代表请求1代表响应。
第四个字节表示消息长度,即此四个字节后面此长度的内容是消息content。


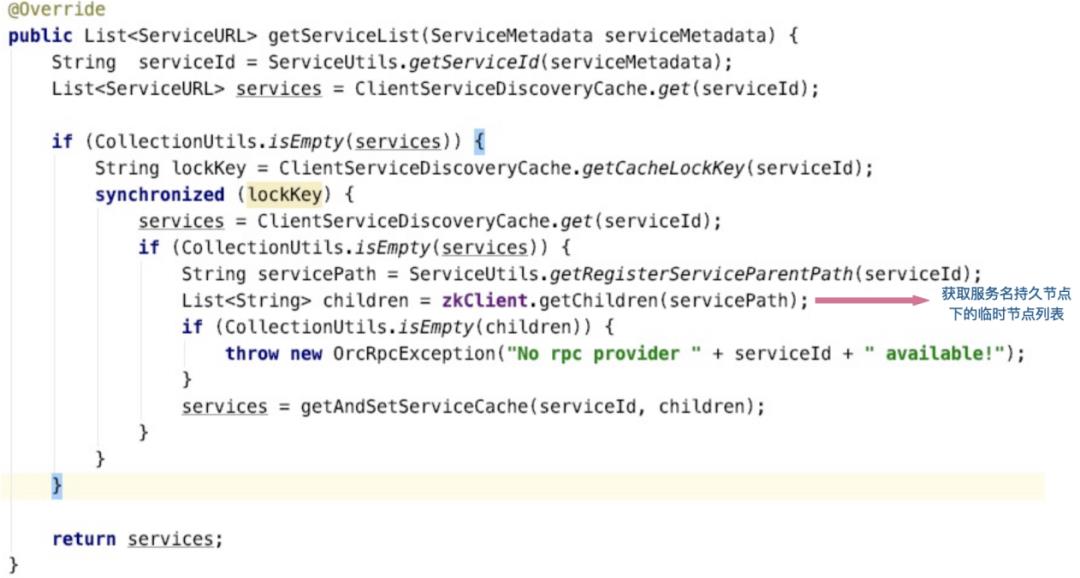
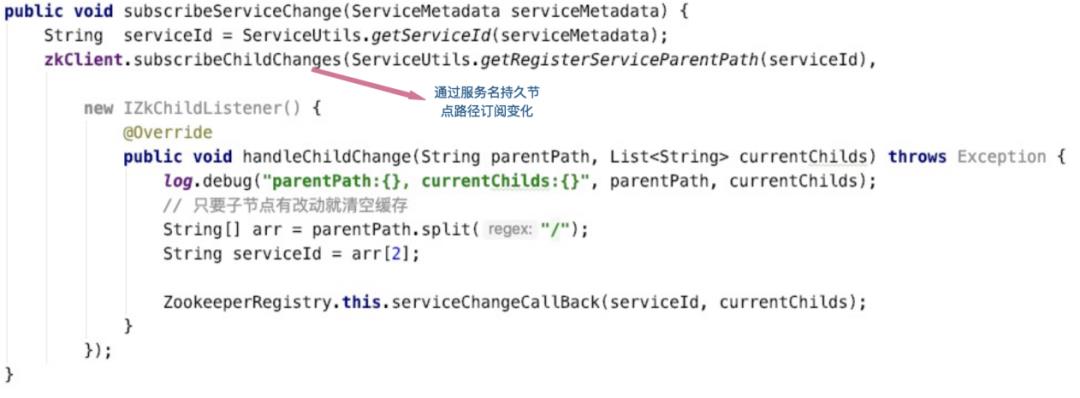
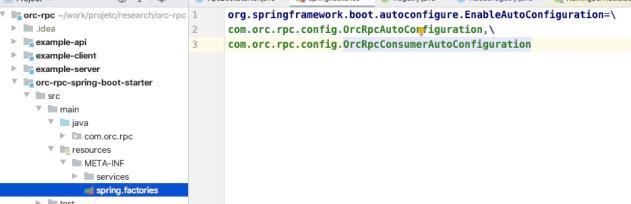
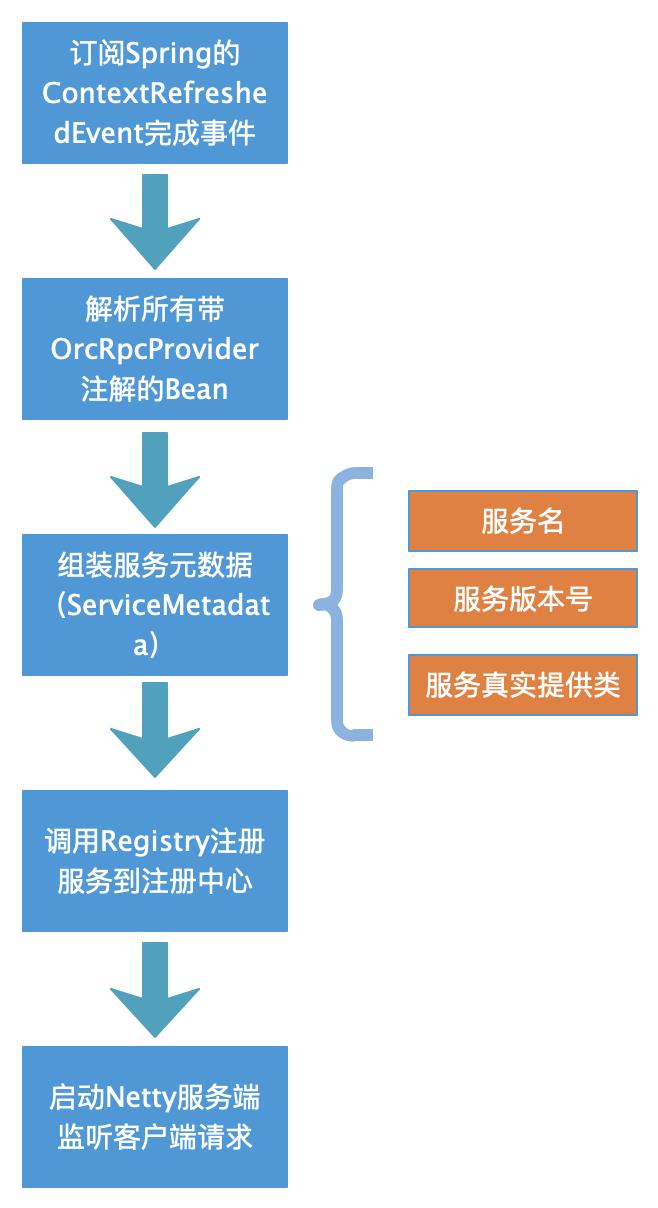

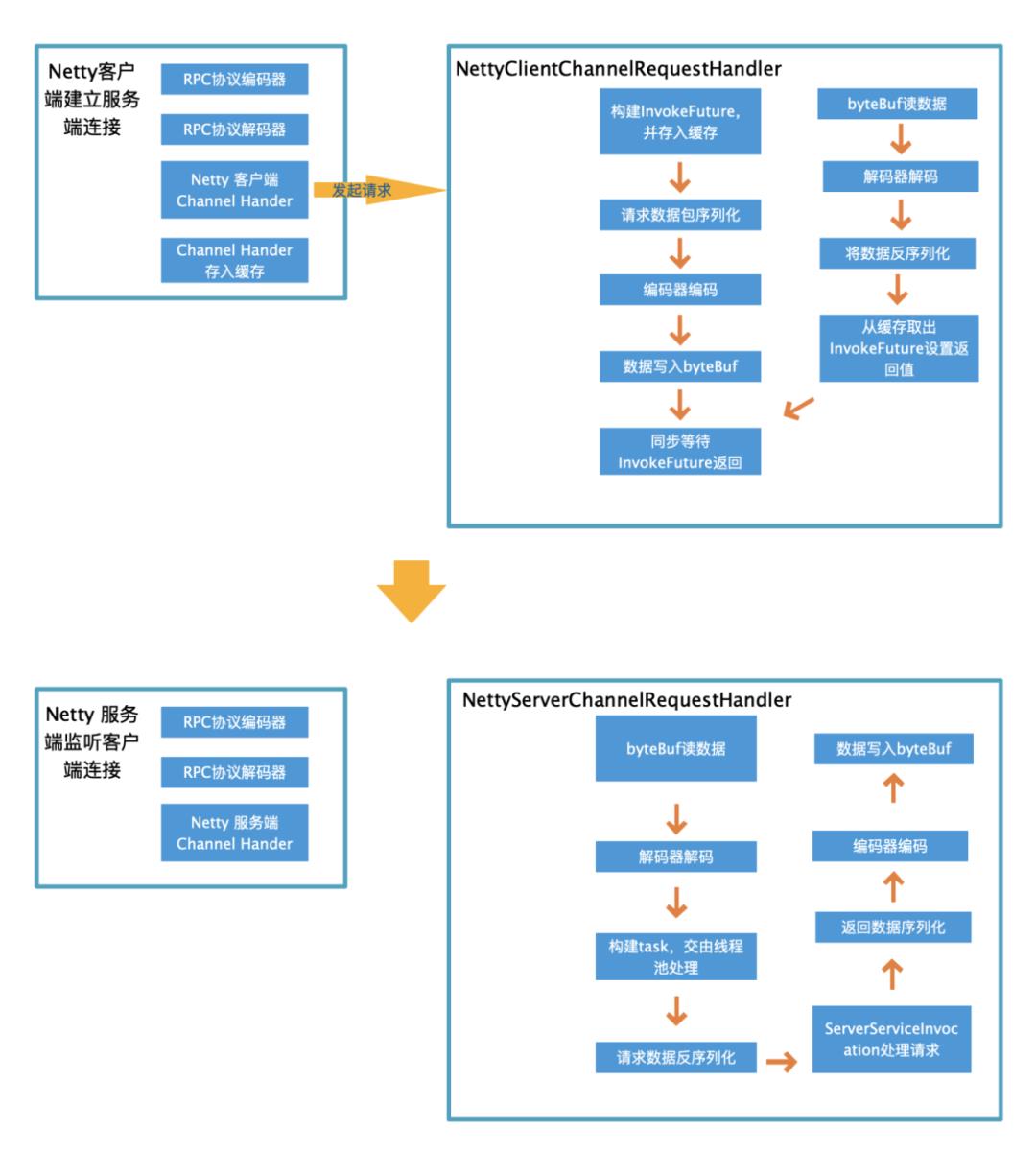
一是在应用的Spring Context初始化完成事件时触发,扫描所有的Bean,将Bean中带有OrcRpcConsumer注解的field获取到,然后创建field类型的代理对象,创建完成后,将代理对象set给此field。后续就通过该代理对象创建服务端连接,并发起调用。
二是通过Spring的BeanFactoryPostProcessor,其可以对bean的定义BeanDefinition(配置元数据)进行处理;Spring IOC会在容器实例化任何其他bean之前运行BeanFactoryPostProcessor读取BeanDefinition,可以修改这些BeanDefinition,也可以新增一些BeanDefinition。
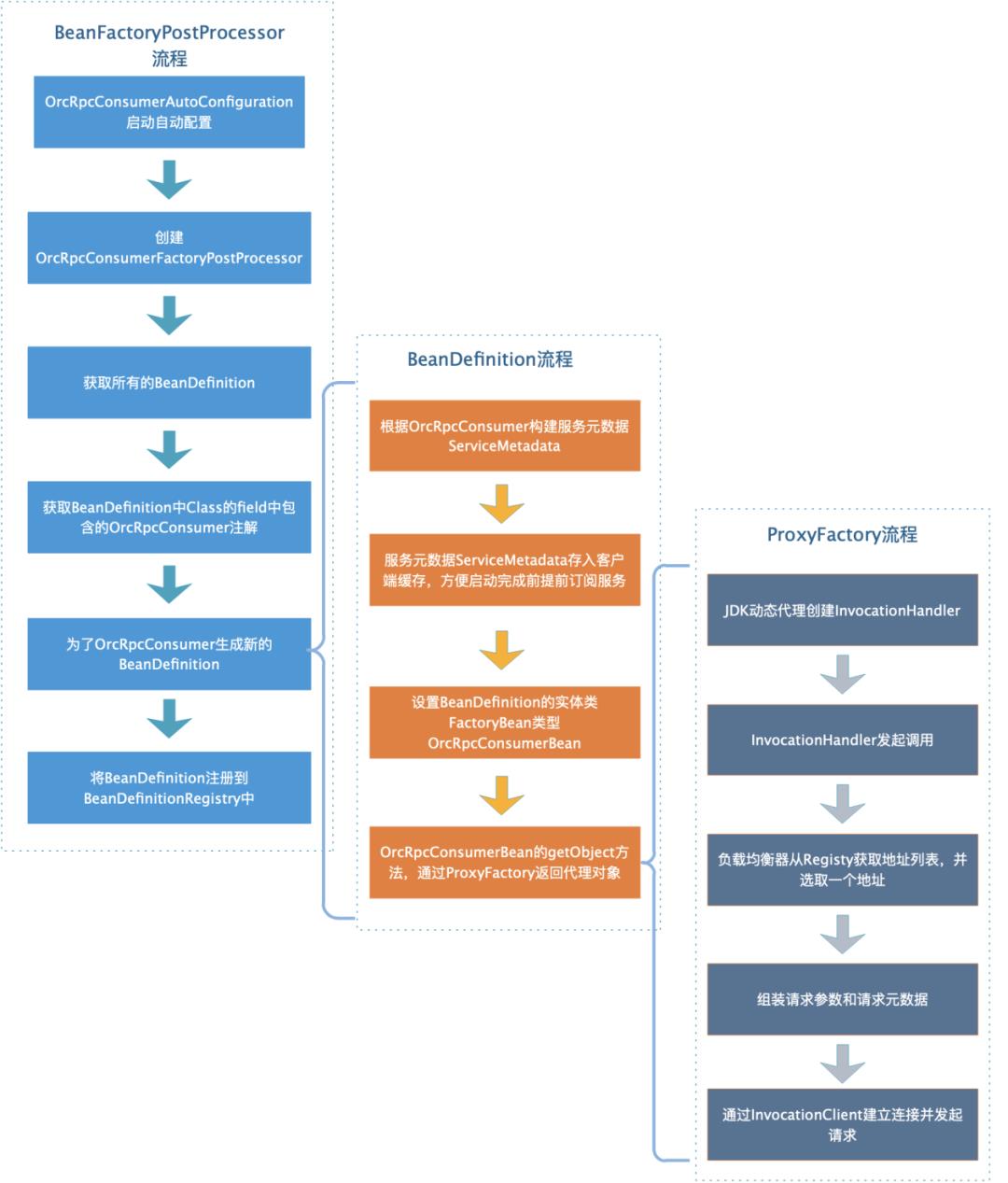
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory)throws BeansException {this.beanFactory = beanFactory;postProcessRpcConsumerBeanFactory(beanFactory, (BeanDefinitionRegistry)beanFactory);}private void postProcessRpcConsumerBeanFactory(ConfigurableListableBeanFactory beanFactory, BeanDefinitionRegistry beanDefinitionRegistry) {String[] beanDefinitionNames = beanFactory.getBeanDefinitionNames();int len = beanDefinitionNames.length;for (int i = 0; i < len; i++) {String beanDefinitionName = beanDefinitionNames[i];BeanDefinition beanDefinition = beanFactory.getBeanDefinition(beanDefinitionName);String beanClassName = beanDefinition.getBeanClassName();if (beanClassName != null) {Class<?> clazz = ClassUtils.resolveClassName(beanClassName, classLoader);ReflectionUtils.doWithFields(clazz, new FieldCallback() {public void doWith(Field field) throws IllegalArgumentException, IllegalAccessException {parseField(field);}});}}Iterator<Entry<String, BeanDefinition>> it = beanDefinitions.entrySet().iterator();while (it.hasNext()) {Entry<String, BeanDefinition> entry = it.next();if (context.containsBean(entry.getKey())) {throw new IllegalArgumentException("Spring context already has a bean named " + entry.getKey());}beanDefinitionRegistry.registerBeanDefinition(entry.getKey(), entry.getValue());log.info("register OrcRpcConsumerBean definition: {}", entry.getKey());}}private void parseField(Field field) {// 获取所有OrcRpcConsumer注解OrcRpcConsumer orcRpcConsumer = field.getAnnotation(OrcRpcConsumer.class);if (orcRpcConsumer != null) {// 使用field的类型和OrcRpcConsumer注解一起生成BeanDefinitionOrcRpcConsumerBeanDefinitionBuilder beanDefinitionBuilder = new OrcRpcConsumerBeanDefinitionBuilder(field.getType(), orcRpcConsumer);BeanDefinition beanDefinition = beanDefinitionBuilder.build();beanDefinitions.put(field.getName(), beanDefinition);}}
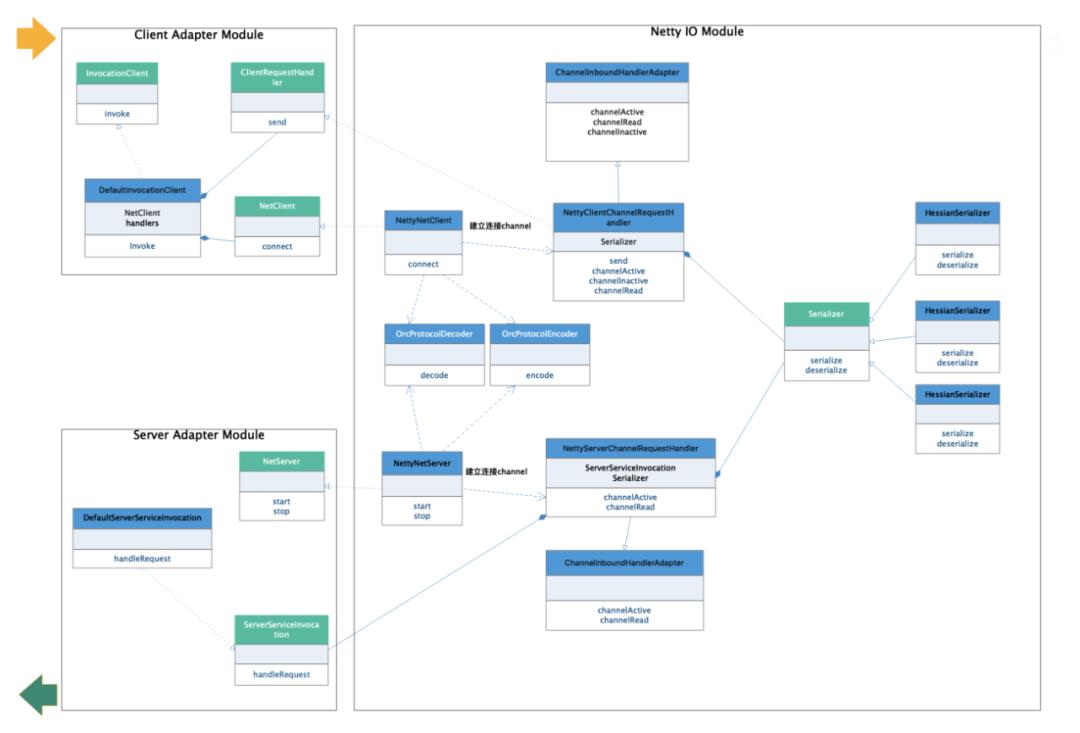
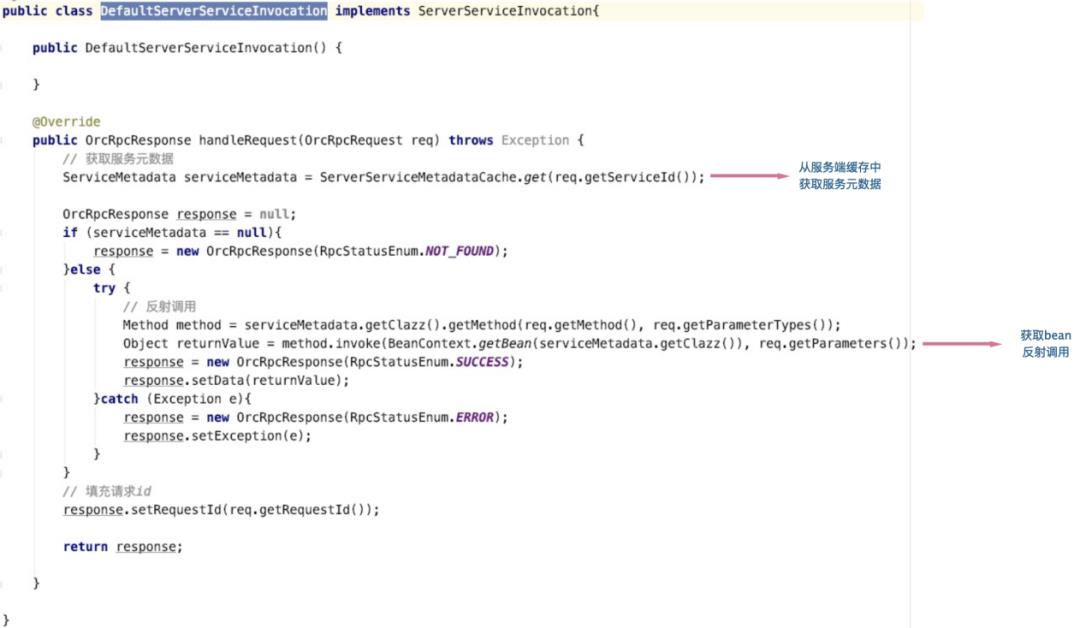
public class JdkProxyFactory implements ProxyFactory{public Object getProxy(ServiceMetadata serviceMetadata) {return Proxy.newProxyInstance(serviceMetadata.getClazz().getClassLoader(), new Class[] {serviceMetadata.getClazz()},new ClientInvocationHandler(serviceMetadata));}private class ClientInvocationHandler implements InvocationHandler {private ServiceMetadata serviceMetadata;public ClientInvocationHandler(ServiceMetadata serviceMetadata) {this.serviceMetadata = serviceMetadata;}public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {String serviceId = ServiceUtils.getServiceId(serviceMetadata);// 通过负载均衡器选取一个服务提供方地址ServiceURL service = InvocationServiceSelector.select(serviceMetadata);OrcRpcRequest request = new OrcRpcRequest();request.setMethod(method.getName());request.setParameterTypes(method.getParameterTypes());request.setParameters(args);request.setRequestId(UUID.randomUUID().toString());request.setServiceId(serviceId);OrcRpcResponse response = InvocationClientContainer.getInvocationClient(service.getServerNet()).invoke(request, service);if (response.getStatus() == RpcStatusEnum.SUCCESS) {return response.getData();} else if (response.getException() != null) {throw new OrcRpcException(response.getException().getMessage());} else {throw new OrcRpcException(response.getStatus().name());}}}}

+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+| BYTE | | | | | | | ........+--------------------------------------------+--------+-----------------+--------+--------+--------+--------+--------+--------+-----------------+| magic | version| type | content lenth | content byte[] | |+--------+-----------------------------------------------------------------------------------------+--------------------------------------------+
第一个字节是魔法数定义为0X35。
第二个字节代表协议版本号。
第三个字节是请求类型,0代表请求1代表响应。
第四个字节表示消息长度,即此四个字节后面此长度的内容是消息content。
protected void encode(ChannelHandlerContext channelHandlerContext, ProtocolMsg protocolMsg, ByteBuf byteBuf)throws Exception {// 写入协议头byteBuf.writeByte(ProtocolConstant.MAGIC);// 写入版本byteBuf.writeByte(ProtocolConstant.DEFAULT_VERSION);// 写入请求类型byteBuf.writeByte(protocolMsg.getMsgType());// 写入消息长度byteBuf.writeInt(protocolMsg.getContent().length);// 写入消息内容byteBuf.writeBytes(protocolMsg.getContent());}
/*** 协议开始的标志 magic + version + type + length 占据7个字节*/public final int BASE_LENGTH = 7;@Overrideprotected void decode(ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf, List<Object> list)throws Exception {// 可读字节小于基本长度,无法解析出payload长度,返回if (byteBuf.readableBytes() < BASE_LENGTH) {return;}// 记录包头开始的indexint beginIndex;while (true) {// 记录包头开始的indexbeginIndex = byteBuf.readerIndex();// 标记包头开始的indexbyteBuf.markReaderIndex();// 读到了协议头魔数,结束循环if (byteBuf.readByte() == ProtocolConstant.MAGIC) {break;}// 未读到包头,略过一个字节// 每次略过一个字节,去读取包头信息的开始标记byteBuf.resetReaderIndex();byteBuf.readByte();/*** 当略过,一个字节之后,数据包的长度,又变得不满足* 此时结束。等待后面的数据到达*/if (byteBuf.readableBytes() < BASE_LENGTH) {return;}}// 读取版本号byte version = byteBuf.readByte();// 读取消息类型byte type = byteBuf.readByte();// 读取消息长度int length = byteBuf.readInt();// 判断本包是否完整if (byteBuf.readableBytes() < length) {// 还原读指针byteBuf.readerIndex(beginIndex);return;}byte[] data = new byte[length];byteBuf.readBytes(data);ProtocolMsg msg = new ProtocolMsg();msg.setMsgType(type);msg.setContent(data);list.add(msg);}
技术公开课
《Spring Cloud Alibaba Nacos 详解》
Nacos是阿里开源的配置管理与服务发现中心,其优势是将配置管理与服务发现合并,并且对Dubbo协议、RestApi统一管理。本课程使用Spring Cloud Alibaba体系架构进行案例演示,讲解Nacos配置管理、Nacos服务发现相关知识,从理论到实战帮助同学们快速将Spring Cloud Alibaba Nacos技术应用到项目中。
以上是关于自己动手从0开始实现一个分布式RPC框架的主要内容,如果未能解决你的问题,请参考以下文章
解密Dubbo:自己动手编写一个较为完善的RPC框架(两万字干货)