Python--爬虫中国大学排行榜并将数据存储到表格
Posted Z && Y
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python--爬虫中国大学排行榜并将数据存储到表格相关的知识,希望对你有一定的参考价值。
1. 爬虫中国大学排行榜并将数据存储到表格
爬取网站:2021中国大学排名1200强【完整版】
完整代码:(这里给出完整的代码只是为了方便大家理解下面具体的步骤,请不要盲目的抄袭代码,重要的是掌握知识,谢谢了。)
craw.py
"""
爬虫中国大学排行榜并将数据存储到表格
"""
import requests # 爬虫请求
from lxml import etree # XPath
# 请求url 得到html静态页面的字符串
def getHtmlInfo():
# 1. 定义要访问的网站
url = 'http://www.gaosan.com/gaokao/265440.html'
# 2. 定义请求的头部信息
# 数据都在服务器里面 --> 游览器要得到数据 就需要通过游览器的验证机制(模拟是从游览器发出的请求)
headers = {
# 游览器信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400'
}
# 3. 发送请求 content.decode('utf-8'): 把返回的数据的编码设置为 utf-8
return requests.get(url, headers=headers).content.decode('utf-8')
# 进行 html静态页面字符串 的数据提取
def getDataInfo(html):
# 4. 创建一个html对象
myHtml = etree.HTML(html)
# text() 是把定位到的数据转换成文本格式
# 名次
ranking = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[1]/text()")
# 学校名称
schoolName = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[2]/text()")
# 综合得分
overallRatings = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[3]/text()")
# 星级排名
starRanking = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[4]/text()")
# 办学层次
schoolLevel = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[5]/text()")
# 遍历数据 让数据进行对应
# zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
# 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
with open('resource/中国大学排行榜.csv', 'w', encoding='utf-8') as file:
for r, sn, o, sr, sl in zip(ranking, schoolName, overallRatings, starRanking, schoolLevel):
file.write(f'{r},{sn},{o},{sr},{sl}\\n')
print('写入数据完成~~~')
if __name__ == '__main__':
getDataInfo(getHtmlInfo())
1.1 安装Xpath Helper
我这里使用的是QQ游览器
安装了xPath helper后就能轻松获取HTML元素的xPath,程序员就再也不需要通过
搜索html源代码,定位一些id去找到对应的位置去解析网页了。
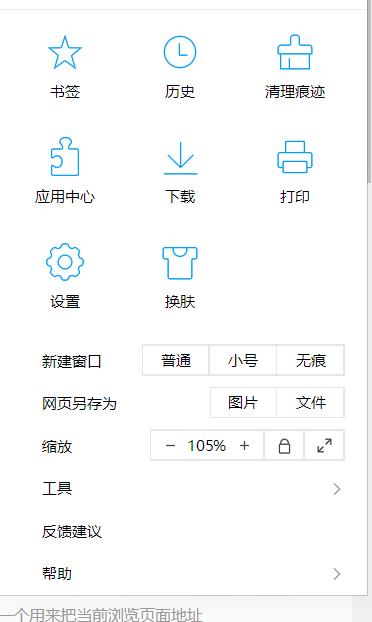
1.1.1 点击应用中心
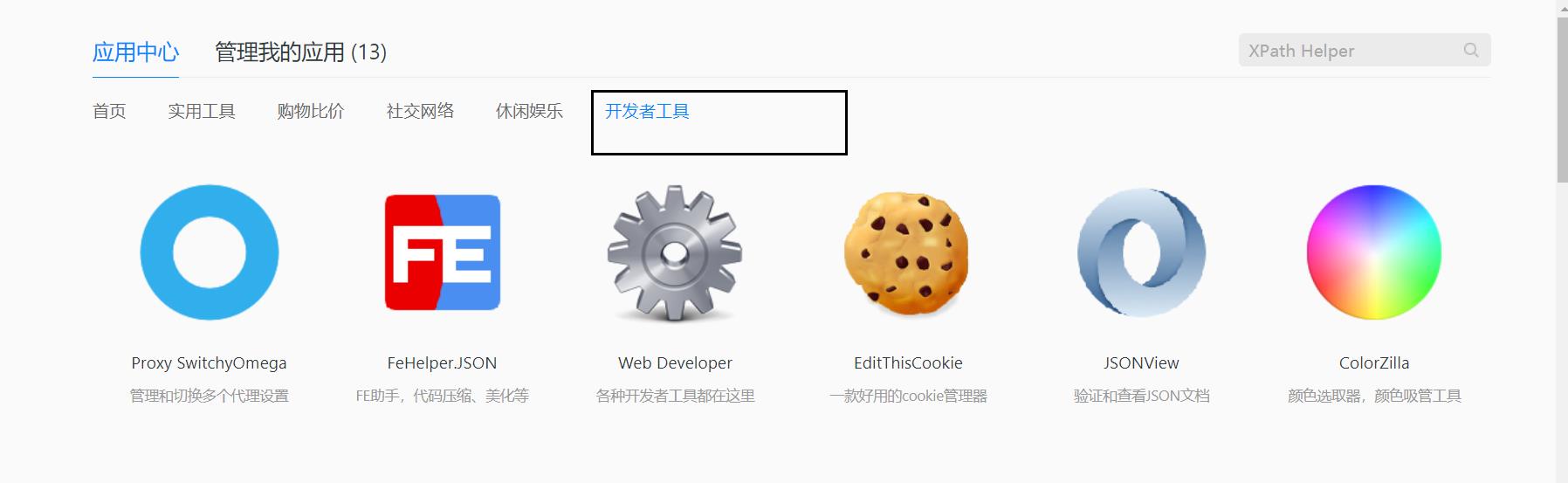
1.1.2 点击开发者工具
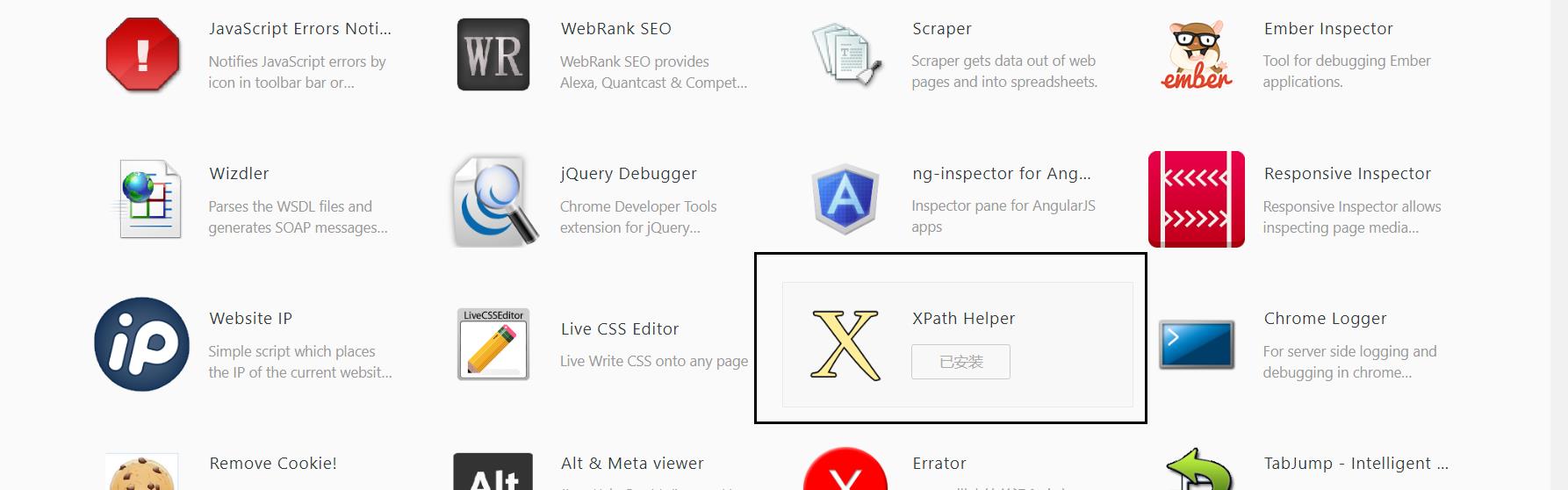
1.1.3 找到并且安装XPath Helper
1.2 爬取数据阶段
1.2.1 定义要访问的网站
# 1. 定义要访问的网站
url = 'http://www.gaosan.com/gaokao/265440.html'
1.2.2 定义请求的头部信息
数据都在服务器里面,游览器要得到数据 就需要通过游览器的验证机制(模拟是从游览器发出的请求)
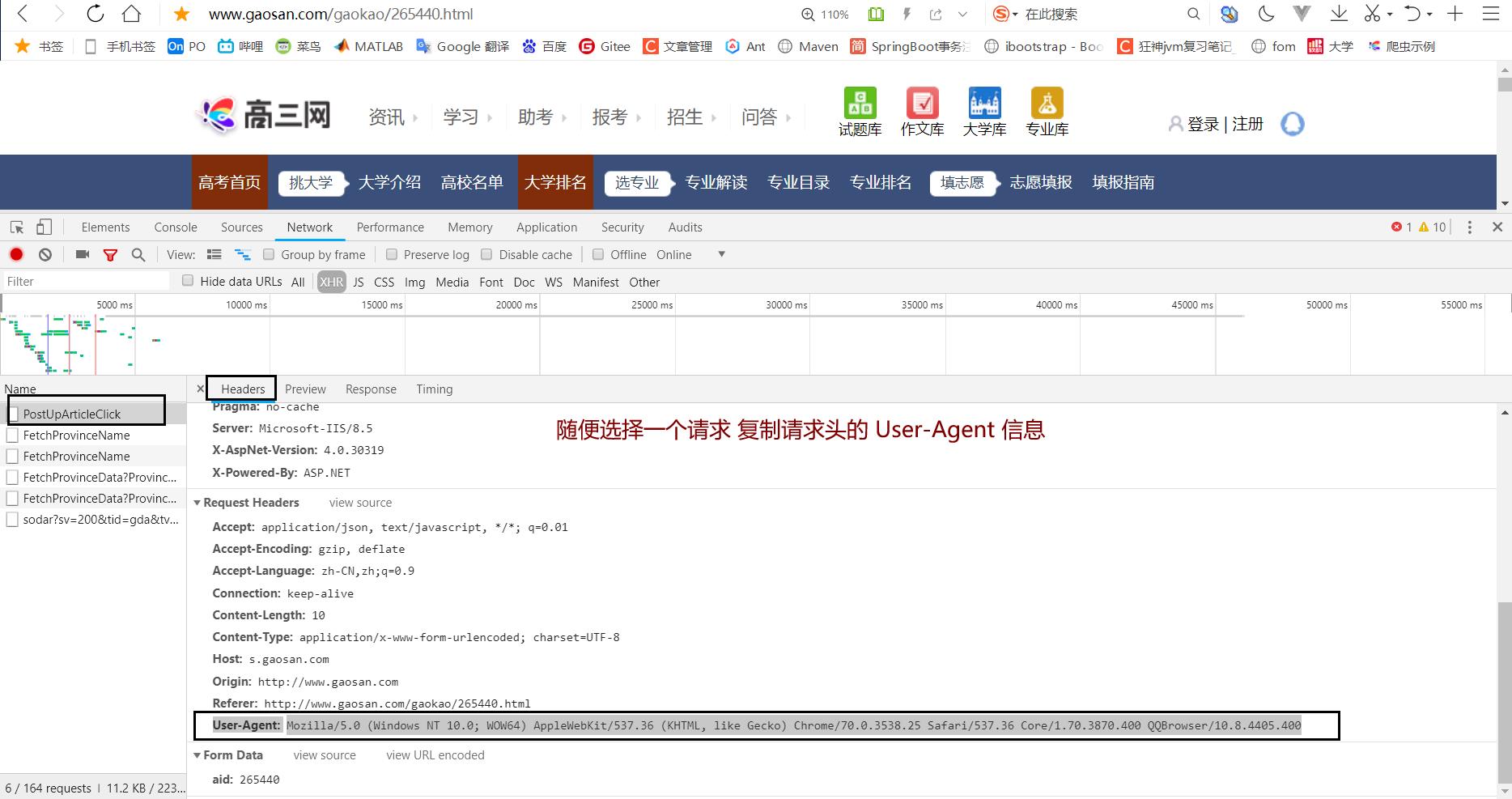
headers = {
# 游览器信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400'
}
1.2.3 发送请求
# 3. 发送请求 content.decode('utf-8'): 把返回的数据的编码设置为 utf-8
response = requests.get(url, headers=headers).content.decode('utf-8')
print(response)
运行结果:

1.2.4 把刚刚的步骤抽象称为一个方法
请求url 得到html静态页面的字符串
# 请求url 得到html静态页面的字符串
def getHtmlInfo():
# 1. 定义要访问的网站
url = 'http://www.gaosan.com/gaokao/265440.html'
# 2. 定义请求的头部信息
# 数据都在服务器里面 --> 游览器要得到数据 就需要通过游览器的验证机制(模拟是从游览器发出的请求)
headers = {
# 游览器信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400'
}
# 3. 发送请求 content.decode('utf-8'): 把返回的数据的编码设置为 utf-8
return requests.get(url, headers=headers).content.decode('utf-8')
1.2. 5 XPath学习
XPath:
// 根节点
/ 节点
@ 属性
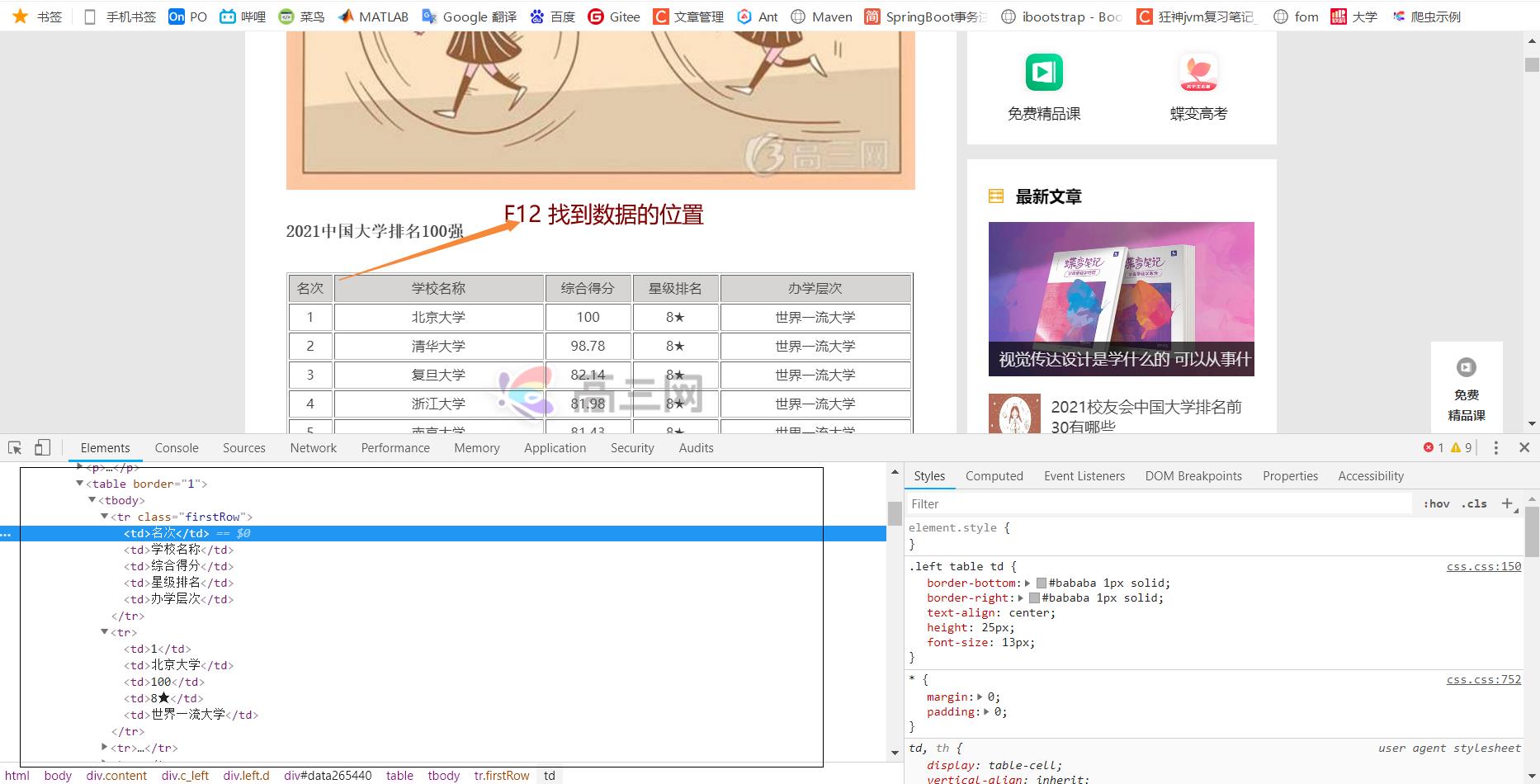
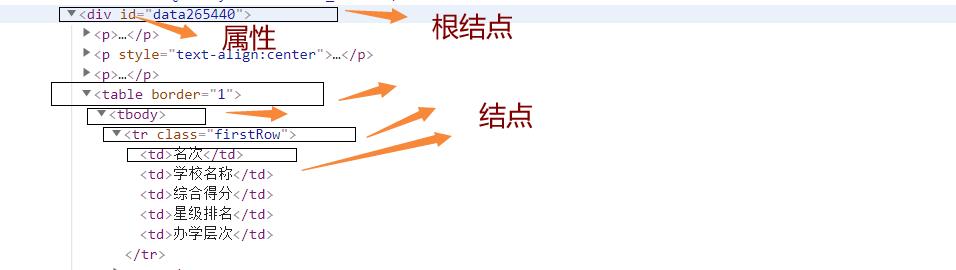
我们现在来定位 “名次 ”
tr里面有许多的td元素 可以用[index]的方式来定位具体的元素 注意 index是从1开始
//div[@id='data265440']/table[@border='1']/tbody/tr[@class='firstRow']/td[1]
开始测试:
# 进行 html静态页面字符串 的数据提取
def getDataInfo(html):
# 4. 创建一个html对象
myHtml = etree.HTML(html)
# text() 是把定位到的数据转换成文本格式
print(myHtml.xpath("//div[@id='data265440']/table[@border='1']/tbody/tr[@class='firstRow']/td[1]/text()"))
if __name__ == '__main__':
getDataInfo(getHtmlInfo())
主函数的运行结果:
可以看见得到的都是列表的格式

1.2.6 完善 getDataInfo(html) 函数
# 进行 html静态页面字符串 的数据提取
def getDataInfo(html):
# 4. 创建一个html对象
myHtml = etree.HTML(html)
# text() 是把定位到的数据转换成文本格式
# 名次
ranking = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[1]/text()")
# 学校名称
schoolName = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[2]/text()")
# 综合得分
overallRatings = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[3]/text()")
# 星级排名
starRanking = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[4]/text()")
# 办学层次
schoolLevel = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[5]/text()")
# 遍历数据 让数据进行对应
# zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
# 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
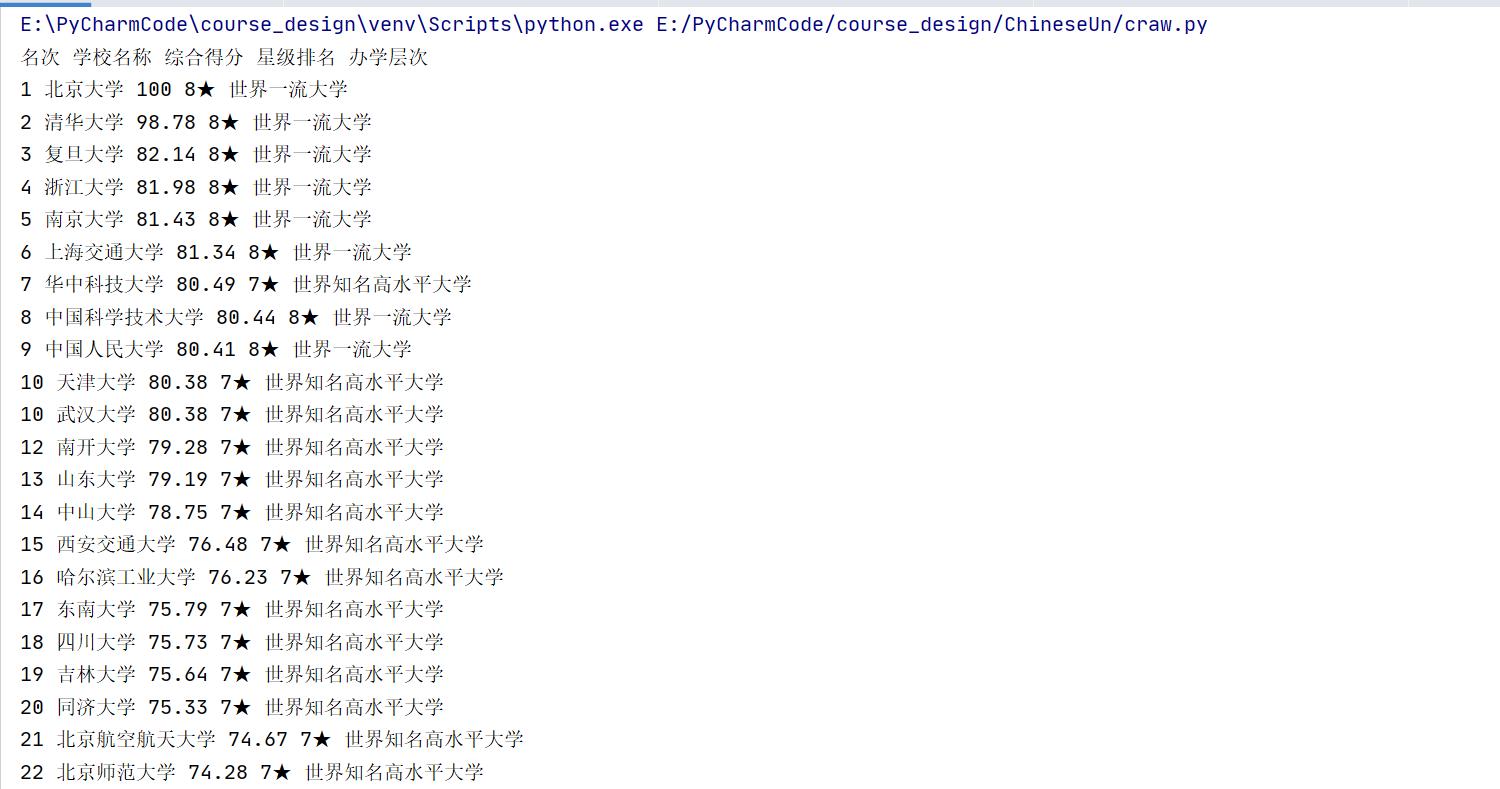
for r, sn, o, sr, sl in zip(ranking, schoolName, overallRatings, starRanking, schoolLevel):
print(r, sn, o, sr, sl)
主函数运行结果:
if __name__ == '__main__':
getDataInfo(getHtmlInfo())
1.2.7 保存数据到表格当中
# 进行 html静态页面字符串 的数据提取
def getDataInfo(html):
# 4. 创建一个html对象
myHtml = etree.HTML(html)
# text() 是把定位到的数据转换成文本格式
# 名次
ranking = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[1]/text()")
# 学校名称
schoolName = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[2]/text()")
# 综合得分
overallRatings = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[3]/text()")
# 星级排名
starRanking = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[4]/text()")
# 办学层次
schoolLevel = myHtml.xpath("//div[@id='data265440']/table/tbody/tr/td[5]/text()")
# 遍历数据 让数据进行对应
# zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
# 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
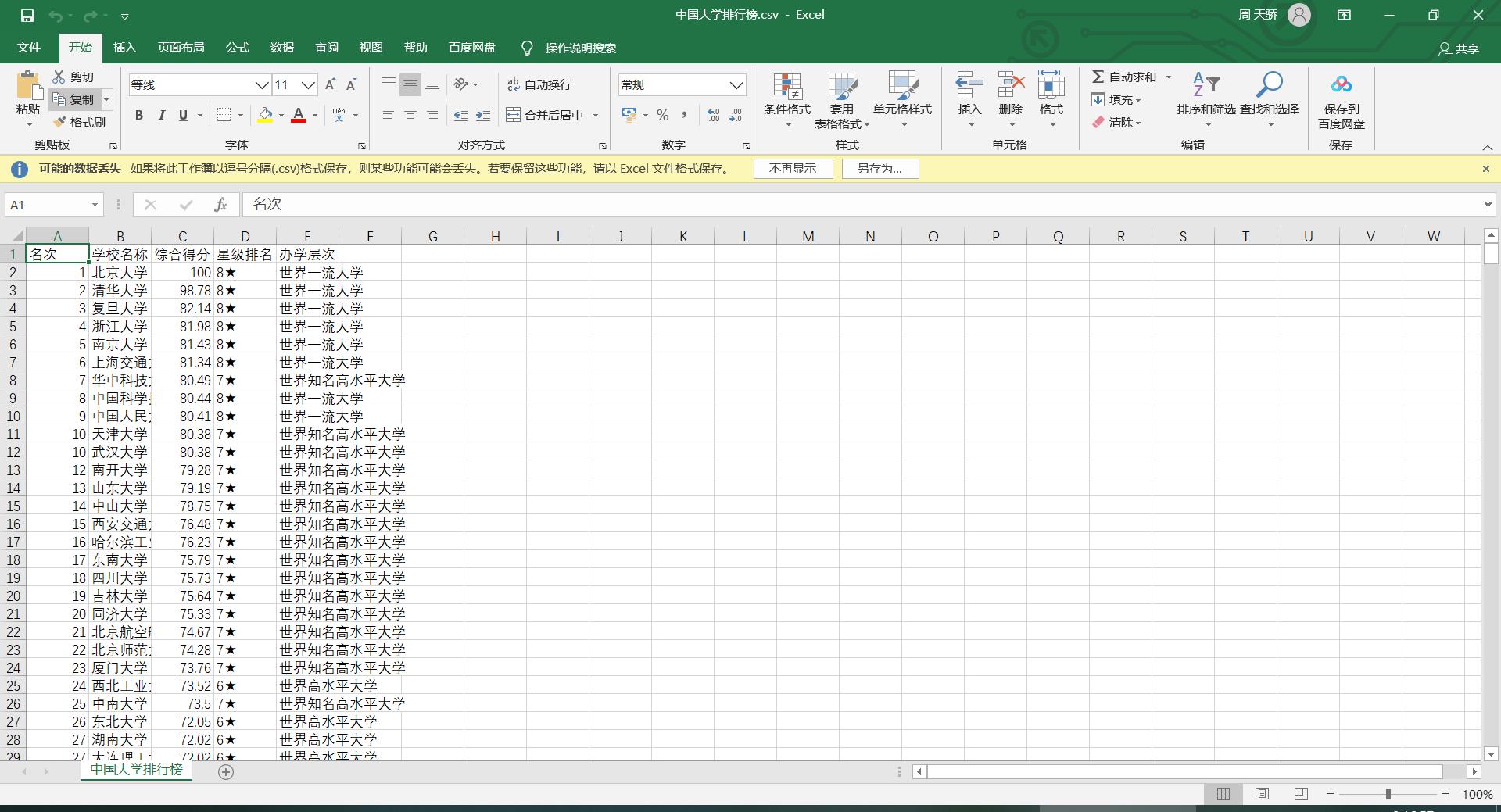
with open('resource/中国大学排行榜.csv', 'w', encoding='utf-8') as file:
for r, sn, o, sr, sl in zip(ranking, schoolName, overallRatings, starRanking, schoolLevel):
file.write(f'{r},{sn},{o},{sr},{sl}\\n')
print('写入数据完成~~~')
1.2.7 测试
主函数运行结果:
if __name__ == '__main__':
getDataInfo(getHtmlInfo())

以上是关于Python--爬虫中国大学排行榜并将数据存储到表格的主要内容,如果未能解决你的问题,请参考以下文章