Linux文本处理神器awk实战案例
Posted herosunly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux文本处理神器awk实战案例相关的知识,希望对你有一定的参考价值。
文章目录
1. 什么是awk
AWK是为文本处理专门打造的领域指定语言,通常用作数据提取和数据报告。它和sed、grep的功能是类似的,能够进行过滤,并且它们三者是大多数Linux系统的标准工具。
20世纪70年代,AWK诞生于贝尔实验室。它的名字起源于三个作者姓的首字母。AWK语言是一种数据驱动的语言,它是由对文本流的一系列操作组成的,不仅能够对文件进行操作,也能够对管道进行操作,最终能够提取或者处理文本,例如产生格式化的报告。AWK广泛使用字符串类型,关联数组和正则表达式。
2. 打印不同列的内容
2.1 初探数据文件
首先,data.txt是awk工具的输入文件,其内容如下所示,其中第一列是材质,第二列是重量,第三列是发行年,第四列是发行国,最后一列是古币的名称:
gold 1 1908 Austria-Hungary Franz josef 100 Korona
gold 1 1985 Canada Maple leaf
silver 10 1981 USA ingot
gold 1 1983 RSA Krugerrand
gold 0.5 1981 RSA Krugerrand
gold 1 1986 USA American Eagle
silver 1 1986 USA Liberty dollar
silver 1 1986 USA Liberty 50-cent piece
gold 0.25 1986 USA Liberty 5-dollar piece
silver 1 1987 USA Constitution dollar
gold 0.1 1986 PRC Panda
gold 0.25 1987 USA Constitution 5-dollar piece
gold 1 1984 Switzerland ingot
其中最后一列的数据包括不定长个空格,这往往是文本处理的一个难点。
2.2 awk处理的三种模式
- BEGIN{ 这里面放的是执行前的语句 }
- END {这里面放的是处理完所有的行后要执行的语句 }
- {这里面放的是处理每一行时要执行的语句}
2.3 打印全部内容
如何使用awk打印文件全部内容呢?
awk '{print}' data.txt
但是上述命令和cat data.txt是等价的,如图所示:
2.4 打印第N列内容
打印第一列内容的代码如下所示:
awk '{print $1}' data.txt
打印第N列,只需把$1中1改成N即可,比如第三列:
awk '{print $3}' data.txt
2.5 打印多列内容
上一小节讲的是打印某一行的内容,如果学过Python,往往会联想是否存在切片操作,即能否取出多列内容。
同时取出前三列的命令如下所示:
awk '{print $1, $2, $3}' data.txt
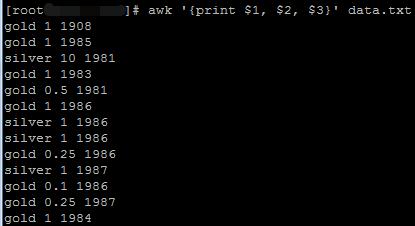
2.6 打印多列内容并对齐显示
可通过在每一列中添加制表符(TAB)来进行对齐,需要注意的是在awk命令内需要使用字符或者字符串用双引号进行表示:
awk '{print $1 "\\t" $2 "\\t" $3}' data.txt
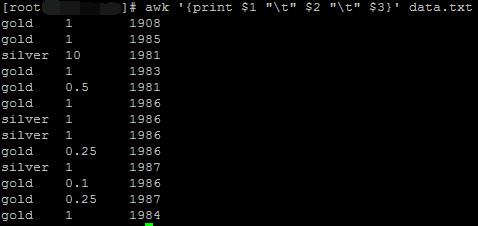
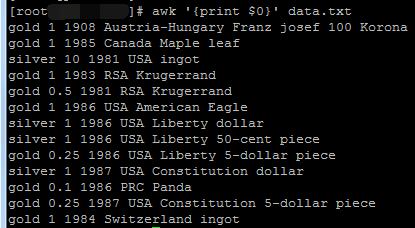
2.7 第0列的物理意义
其中第0列表示的是所有行,而不是所有列,如下所示:
awk '{print $0}' data.txt
3. 打印行号和列号
行号指的是位于第几行,而列号指的是这一行一共包含了几列。
3.1 列与列中间的分隔符
首先假设字符串1为s1,字符串2为s2,
- 空格:表示将字符串进行拼接,即s1+s2
- 逗号:表示通过空格进行拼接,即s1+空格+s2
- 制表符:表示通过TAB进行连接,即s1+TAB+s2
3.2 打印行号
将行号和原有列通过空格进行拼接:
awk '{print NR, $0}' data.txt
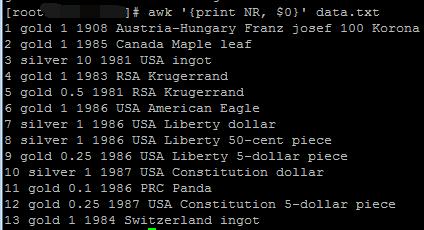
将行号和原有列通过TAB进行拼接:
awk '{print NR "\\t" $0}' data.txt
3.3 打印列号
由于在awk中,每个分隔符将两列数据分隔开。比如一行中包括了多个空格,则表示该行出现了多列数据,这就会导致不同行对应的列数是不一致的,打印每一行对应的列号代码如下所示:
awk '{print NF, $0}' data.txt
3.4 利用列号打印倒数第N列
打印最后一列直接用$NF,具体代码为:
awk 'print {$NF}' data.txt
所以打印倒数第N列,使用$(NF-N-1)即可。例如倒数第二列是$(NF-1)。
awk '{print $(NF-1)}' data.txt
3.5 打印最后一行
awk 'END {print NR, $0}' data.txt

4. 修改输入和输出分隔符
默认的输入和输出分隔符都是空格。假如输入文件为csv文件,那么就需要更改输入分隔符为逗号。
如果使用默认分隔符的话,就无法进行分列,也就是说整个数据仅仅只有一列:

- 输入分隔符:FS
对输入分隔符进行修改的代码如下所示:
awk 'BEGIN{FS=","} {print $1, $2}' time_name_score.csv

- 输出分隔符:OFS
对输入和输出分隔符同时进行修改的代码如下所示:
awk 'BEGIN{FS=","; OFS="\\t"} {print $1, $2}' time_name_score.csv

5. 输入多个文件
直接把多个文件名依次排列在最后,需要注意的是把不同文件按照行进行拼接的:
awk '{print NR, $0}' data.txt data2.txt
6. 修改某一列的值
有时将某一列的值统一修改的需求,具体代码如下所示:
awk '$1 = 'silver'; {print $0}' data.txt
7. 条件筛选后打印
- 筛选并打印材质为银的所有古币的命令如下:
awk '$1=="silver" {print $0}' data.txt

- 筛选并打印出品年为1987年的所有古币的命令如下:
awk '$3==1987 {print $0}' data.txt

- 打印第7行
awk 'NR==7 {print $0}' data.txt
- 打印列数为7的所有行
awk 'NF==7 {print $0}' data.txt
8. 运算
8.1 数学运算
输入以下命令后,请再按一个回车,从而得到执行结果,得到结果后按Ctrl+C后退出即可:
- 加法:awk ‘{a=1; b=2; print a+b}’
- 减法:awk ‘{a=1; b=2; print a-b}’
- 乘法:awk ‘{a=1; b=2; print a*b}’
- 除法:awk ‘{a=1; b=2; print a/b}’
- 取余:awk ‘{a=1; b=2; print a%b}’
8.2 字符串拼接
字符串拼接:awk ‘{a=1; b=2; print a b}’

8.3 两者混合运算
字符串拼接时,可以通过括号进行表示,拼接后再进行数学运算,如下所示:
awk '{a=1; b=2; c=3; print (a b)+c}'

如果字符串中的开头是数字,则可以直接和数字进行运算,否则认为字符串代表的数字为0(即使是字符串的中部出现了数字也一样)。


9. 正则表达式
通过/正则表达式/来进行文本搜索。比如文本中包括字符串com,则搜索表达式为:
awk '/com/{print $0}' data.txt

以上是关于Linux文本处理神器awk实战案例的主要内容,如果未能解决你的问题,请参考以下文章