elk搭建及应用服务日志采集
Posted wen-pan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elk搭建及应用服务日志采集相关的知识,希望对你有一定的参考价值。
一、日志采集流程简介
1、elasticsearch stack 介绍
elasticsearch stack 主要是是由 elasticsearch + beats + logstash + kibana 四个组件组成。
| 组件名称 | 作用 |
|---|---|
| elasticsearch | 负责核心存储和检索引擎(比如beats或logstash采集的日志就可以存储在es中)。 |
| beats | 有很多种类的beat,比如filebeat主要用于采集日志文件,metricbeat主要用于采集服务性能指标(比如操作系统性能指标,nginx性能指标,mysql性能指标,Redis性能指标等),packetbeat主要用于采集网络流量指标等。beat采集的日志一般有两种流向,一是可以直接存储到elasticsearch中,二是可以流向logstash中,经过logstash的一些过滤,切分等处理后再流向elasticsearch中进行存储。 |
| logstash | 也可以用于采集数据,但是logstash可以对采集的数据做一定的处理(比如切割,过滤,提取关键词等),然后传递给下游存储系统。 |
| kibana | 主要用于将数据进行可视化呈现,支持将数据按客户要求进行呈现(比如:柱形图,饼状图,折线图等)。方便用户查看日志。 |
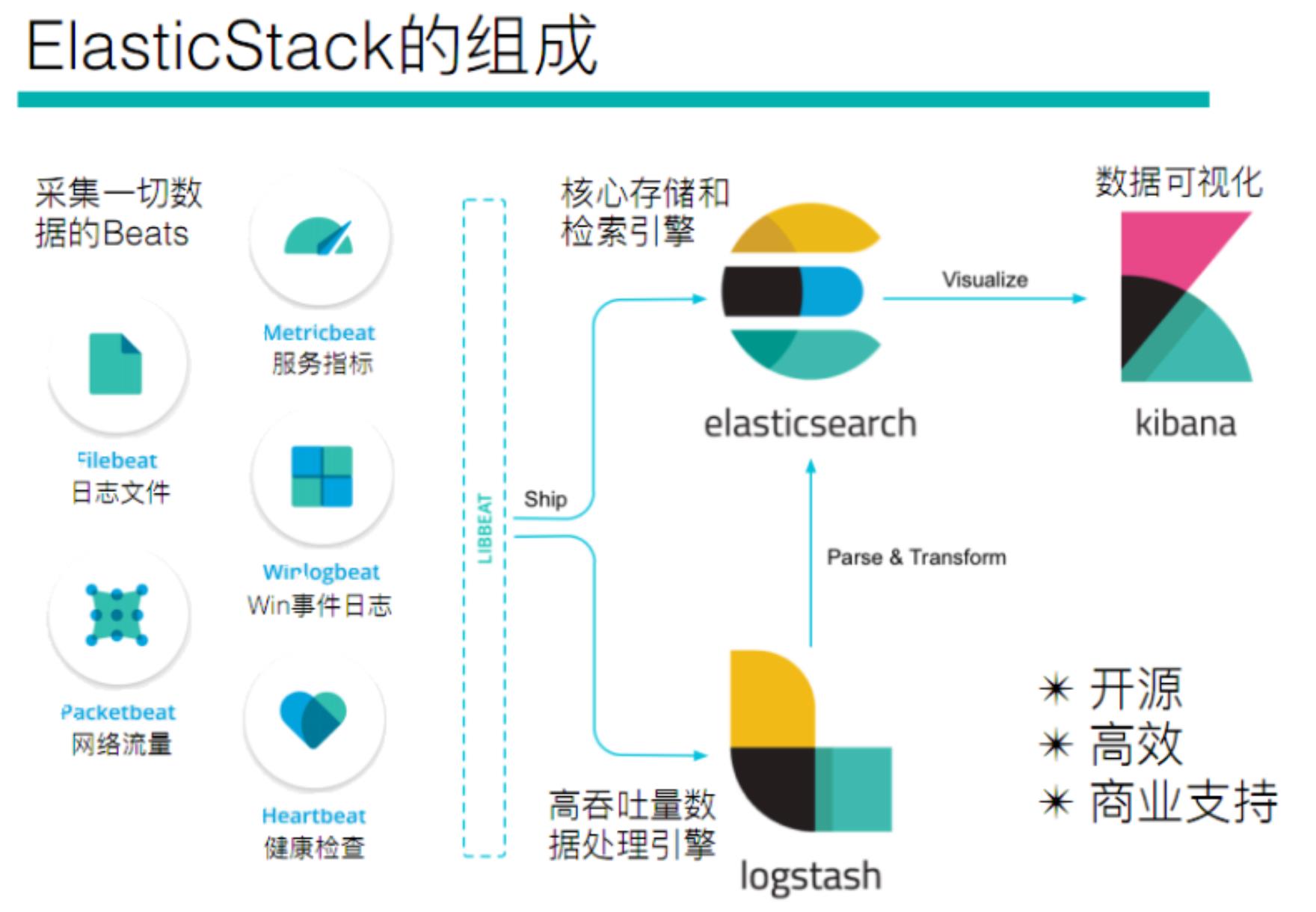
2、elasticsearch stack常见使用组合
一般来说,常见的组合流程有如下两种:
组合一、
- 使用beat采集日志,日志直接流向es中(日志不需要做额外处理)
- es存储采集到的日志
- kibana将es中的日志做可视化呈现
组合二、
- 使用beat采集日志,日志流向logstash中
- logstash接收来自beat的日志,然后做一些处理(比如:过滤,切分等),然后将处理后的日志流向es中。
- es存储logstash流过来的日志
- kibana将es中的日志做可视化呈现
二、本次搭建日志采集流程说明
本次采用上面的组合二的方式来进行搭建!
es的搭建流程见我的上篇!!!https://blog.csdn.net/Hellowenpan/article/details/116497143?spm=1001.2014.3001.5501
1、流程图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D6UUy7tp-1620551964757)(picture/搭建流程图.png)]](https://image.cha138.com/20210709/91f628ad668b4496900daf999a622e55.jpg)
2、流程说明
- 模拟的应用服务产生日志(我们这里使用echo指令定时向某个文件写入日志模拟)。
- filebeat采集应用服务的日志,然后传递到logstash中。
- 在logstash中将采集到的服务日志按自己的要求做切分过滤,切分完毕后写入到es中。
- kibana读取es中的日志做可视化呈现,用户在浏览器上访问kibana的可视化界面就可查看到日志。
三、机器规划
- 一共使用三台服务器,分别是yuanping-host,hezhen-host,wenpan-host
- 三台服务器都部署es
- yuanping-host部署filebeat、logstash
- hezhen-host部署kibana
- 使用echo 命令向app-1.log和app-2.log文件写日志,模拟两个不同应用服务的日志
| yuanping-host | hezhen-host | wenpan-host | |
|---|---|---|---|
| Filebeat | √ | ||
| Logstash | √ | ||
| Es | √ | √ | √ |
| kibana | √ | ||
| 模拟的应用服务 | 使用echo命令向app-1.log、app-2.log写入数据 |
四、Filebeat搭建
1、下载安装包并解压
下载地址:https://www.elastic.co/cn/downloads/beats/filebeat
# 将filebeat解压到指定的目录
tar -zxvf filebeat-6.5.4-linux-x86_64.tar.gz -C /opt/module/beats/
2、编写配置文件
在filebeat安装目录新建一个config目录,用于存放我们自己编写的配置文件。在config目录下新建一个配置文件wenpan-filebeat-app-test.yml(名字随便取,启动filebeat的时候指定该配置文件即可),写入如下内容:
# 设置filebeat的输入为文件输入
filebeat.inputs:
# 这里可以配置多个path,采集不同应用服务的日志,然后在logstash中按照应用服务名为index保存到es中
- type: log
enabled: true
# 采集指定目录的日志(模拟采集第一个应用服务的日志)
paths:
- /opt/module/data/logs/app-1.log
# 指定应用程序日志type,方便后面logstash在es中对不同的应用服务日志创建不同的索引
fields:
appname: test-app01-log
# 将属性放到根下 比如 appname 属性,在其他地方访问直接 [appname] 即可访问,不开启的话需要 [fields][appname]才能访问
#fields_under_root: true
- type: log
enabled: true
# 采集指定目录的日志(模拟采集第二个应用服务的日志)
paths:
- /opt/module/data/logs/app-2.log
# 指定应用程序日志type,方便后面logstash在es中对不同的应用服务日志创建不同的索引
fields:
appname: test-app02-log
#fields_under_root: true
# 指定索引的分区数
setup.template.settings:
index.number_of_shards: 3
#指定logstash的配置,日志采集后输出到logstash中
output.logstash:
hosts: ["yuanping-host:5044"]
3、启动filebeat
# 执行如下命令启动filebeat
./filebeat -e -c wenpan-filebeat-app-test.yml -d "publish"
#参数说明
-e: 输出到标准输出,默认输出到syslog和logs下
-c: 指定配置文件
-d: 输出debug信息
五、logstash搭建
1、下载并安装
下载地址:https://www.elastic.co/cn/downloads/logstash
或使用wget获取:wget https://artifacts.elastic.co/downloads/logstash/logstash-6.5.4.tar.gz
# 解压到指定目录
tar -zxvf logstash-6.5.4.tar.gz -C /opt/module/logstash/
2、创建配置文件wenpan-pipeline-app-test.conf
在config目录下创建一个配置文件wenpan-pipeline-app-test.conf(名字随便取,启动filebeat的时候指定该配置文件即可),写入如下内容:
# 从filebeat中输入
input {
beats {
port => "5044"
}
}
filter {
# 设置按照 | 拆分日志
mutate {
split => {"message"=>"|"}
}
# 获取拆分后的日志的第1、2、3个字段并为他们指定字段名(非必须)
mutate {
add_field => {
"userId" => "%{message[1]}"
"visit" => "%{message[2]}"
"date" => "%{message[3]}"
}
}
# 将上面拿到的字段进行类型转换(非必须)
mutate {
convert => {
"userId" => "integer"
"visit" => "string"
"date" => "string"
}
}
}
# 输出到es中
output {
# 匹配filebeat里面定义的type,以便于一个logstash可以收集多个日志
if [fields][appname] == "test-app-log" {
elasticsearch {
hosts => [ "wenpan-host:9200","hezhen-host:9200","yuanping-host:9200"]
# 刷新频率
#flush_size => 1000
# es中创建索引的名称(注意 index里面不能存在大写字符)
index => "%{[fields][appname]}-%{+YYYY.MM.dd}"
document_type => "log"
}
}
# 匹配filebeat里面定义的type,以便于一个logstash可以收集多个日志
if [fields][appname] == "product-app-log" {
elasticsearch {
hosts => [ "wenpan-host:9200","hezhen-host:9200","yuanping-host:9200"]
# 刷新频率
#flush_size => 1000
# es中创建索引的名称(注意 index里面不能存在大写字符)
index => "%{[fields][appname]}-%{+YYYY.MM.dd}"
document_type => "log"
}
}
# ======================上面的写法也可以直接写成如下格式,二选一即可======================
# 推荐下面这种写法,比较简洁
#elasticsearch {
#hosts => [ "wenpan-host:9200","hezhen-host:9200","yuanping-host:9200"]
# 刷新频率
#flush_size => 1000
# es中创建索引的名称(注意 index里面不能存在大写字符)
#index => "%{[fields][appname]}-%{+YYYY.MM.dd}"
#document_type => "log"
#}
}
3、启动logstash
# 用指定的配置文件启动logstash,后台启动
nohup ./bin/logstash -f ./wenpan-pipeline-app-test.conf &
六、kibana搭建
1、下载并解压
下载地址:https://www.elastic.co/cn/downloads/past-releases#kibana
# 解压到指定目录
tar -xvf kibana-6.5.4-linux-x86_64.tar.gz -C /opt/module/kibana
2、修改配置文件kibana.yml
vim config/kibana.yml
# 对外暴露服务的地址,如果是阿里云,公网想要访问到的话这里需要配置成0.0.0.0
server.host: "xx.xx.xx.xx"
# 配置Elasticsearch
elasticsearch.url: "http://es的IP:9200"
3、启动并访问
# 后台启动kibana
nohup ./bin/kibana &
启动报错 FATAL Error: listen EADDRNOTAVAIL xx.xx.xx.xx:5601
**解决方法:**修改server.host为 👉🏻 server.host: “0.0.0.0”
参考:http://www.west999.com/info/html/caozuoxitong/Linux/20200405/4668573.html
浏览器访问 IP:5601
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SQyrFeSW-1620551964758)(./picture/kibana搭建.png)]](https://image.cha138.com/20210709/070d1cfc4c7a49fcbdf3f79e6b752730.jpg)
七、测试
1、模拟产生日志
使用echo 命令向
/opt/module/data/logs/app.log文件写入日志,模拟应用程序产生日志。echo模拟产生日志:
echo "[INFO] 2019-03-15 22:55:02 [cn.wenpan.dashboard.Main] - DAU|7698|查看订单|2019-03-15 08:17:02" >> /opt/module/data/logs/app-1.log echo "[INFO] 2019-03-16 22:55:02 [cn.wenpan.dashboard.Main] - DAU|7698|查看订单|2019-03-15 08:17:02" >> /opt/module/data/logs/app-1.log echo "[INFO] 2019-03-17 22:55:02 [cn.wenpan.dashboard.Main] - DAU|7698|查看订单|2019-03-15 08:17:02" >> /opt/module/data/logs/app-2.log echo "[INFO] 2019-03-18 22:55:02 [cn.wenpan.dashboard.Main] - DAU|7698|查看订单|2019-03-15 08:17:02" >> /opt/module/data/logs/app-2.log
2、在es和kibana上查看
①、es上查看
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N8uiVRl7-1620551964760)(picture/在es上查看日志收集效果.png)]](https://image.cha138.com/20210709/cd280afff35247549b85aaf773025025.jpg)
②、kibana上查看
下面的页面需要在kibana的界面上的management中
create index pattern中创建一个index-pattern然后才能在discover中看到。
创建index-pattern
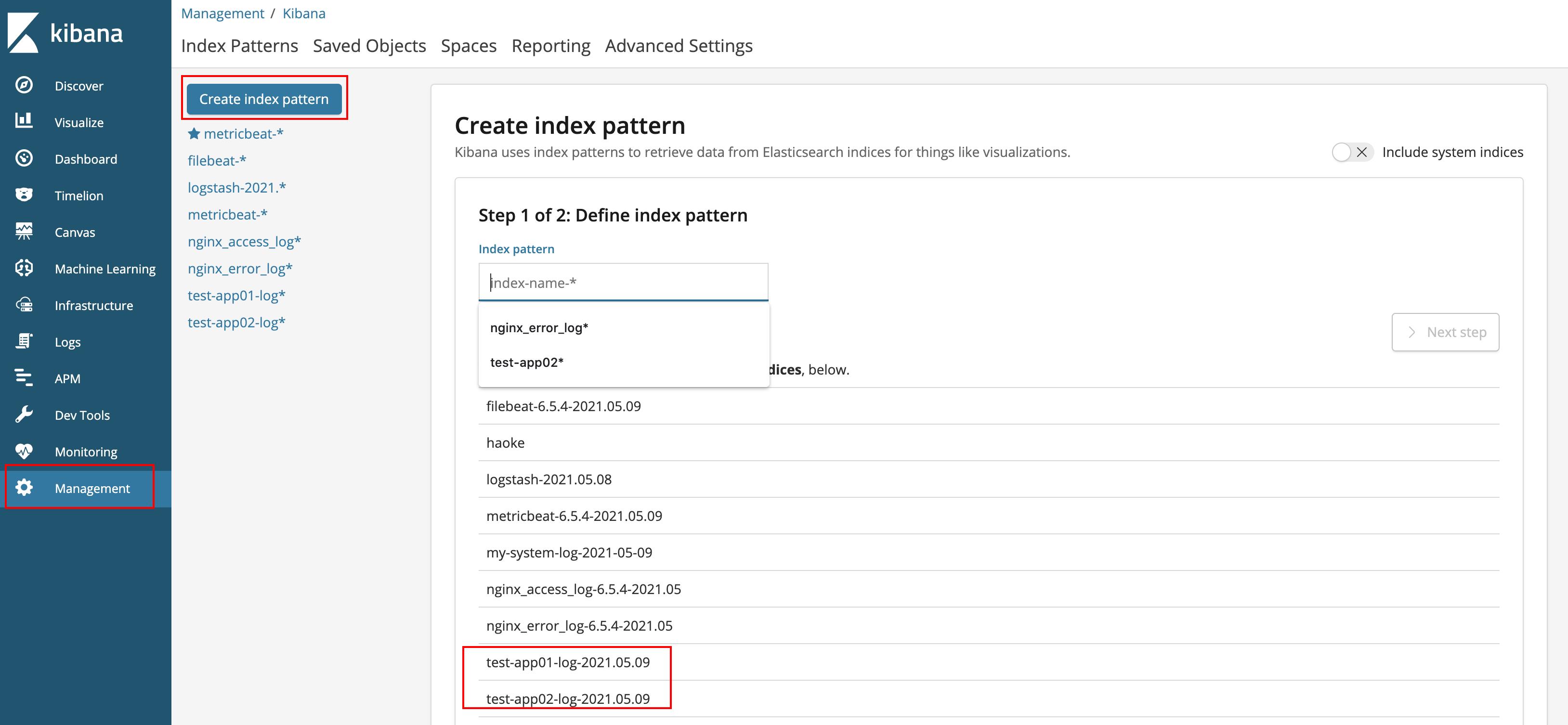
查看discover
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hQaSJAff-1620551964763)(picture/kibana上查看日志收集效果.png)]](https://image.cha138.com/20210709/e40249b0b50b4191a644ae546e5064f9.jpg)
八、其他
kibana还可以自己配置dashboard,按自己的需求按不同的维度以图表的方式呈现日志(比如柱状图、饼状图、折线图等)。配置方式也很简单。
配置filebeat采集多个应用服务日志,并且logstash中按自定义index写入es
以上是关于elk搭建及应用服务日志采集的主要内容,如果未能解决你的问题,请参考以下文章