使用 Scala 进行并行计算
Posted 数据之其然
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 Scala 进行并行计算相关的知识,希望对你有一定的参考价值。
一个话题忽然而出:我们可以做些什么来解决不适合单核 CPU 的问题?
这个论理话题出自--莫哈末纳迪姆阿赫塔尔 .软件工程师
在当今世界,数据正在逐步增长,需要解决更大或更复杂的计算问题。对于不适合单核 CPU 或无法在合理时间内解决的问题,我们应该怎么做?
并行编程不仅解决了这些问题,而且还减少了计算时间。现在所有的电脑都是多核处理器,即使你的 iPhone 4s 也有两个内核。在本文中,我将研究可以应用并行计算的可能场景以及影响计算时间的因素。我们还将研究并行程序的基准测试。
并行计算是一种可以同时执行不同计算的计算类型。
基本原理:可以将问题分解为子问题,每个子问题可以同时解决。
我们中的许多人无法发现并行编程与并发编程有何不同。让我们退后一步,了解并行计算背后的概念和推理。
并行计算:
优化使用并行硬件来快速执行计算
划分子问题
主要关注:速度
主要用于:算法问题、数值计算、大数据处理
发编程:
可能会也可能不会同时提供多个执行开始
主要关注:便利性、更好的响应性、可维护性
存在不同级别的并行性,例如位级别、指令级别和任务级别。出于本文的目的,我们将重点关注任务级并行性。
在进入并行编程问题之前,让我们首先了解硬件的行为方式。
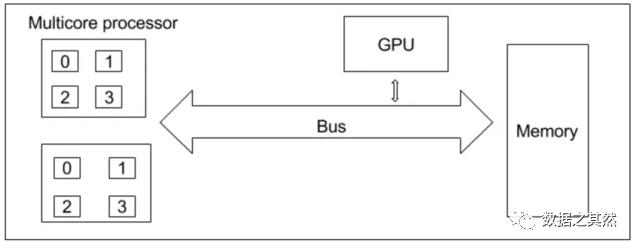
IBM 和 Oracle 等处理器供应商在同一处理器芯片上提供多核 CPU,每个 CPU 都能够执行单独的指令流:
多核处理器
对称多处理器
图形处理单元
并行编程比顺序编程困难得多。它甚至使开发人员的生活更加艰难。然而,在并行编程方面,可以交付结果的速度是一个很大的优势。
任务级并行性
一个任务可以被表述为并行执行单独的指令流。
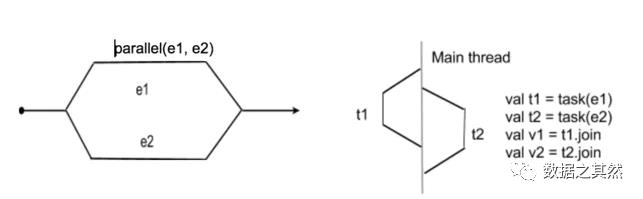
并行执行的签名,其中 taskA 和 taskB 按名称调用,意味着它不会顺序执行。

在这里你可以看到方法“task”,它被安排在一个单独的线程上

让我们看一个例子:
找出可以为指定金额的指定硬币列表进行更改的总方式数。

此方法“countChange”按顺序运行并在'82.568 ms ' 内产生结果:

而并行版本的运行时间为“ 48.686 毫秒”,加速为“1.695 毫秒”。
我们在这个例子中使用了什么硬件?MacBook Pro“酷睿i5”:
处理器 2.4 GHz(单个硅芯片上的双独立处理器“核心”)
内存 8GB
当然,您不能并行化所有内容。让我们尝试了解拆分和组合数据结构(例如数组)的成本。
假设我们有一个四核处理器和一个大小为 100 的数组,我们必须对其执行过滤操作。
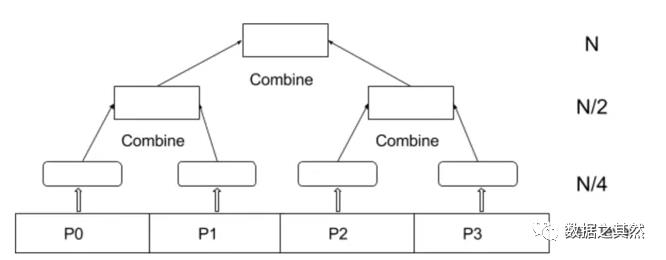
在并行归约树的叶级,它将在 N/4 个计算步骤中遍历 N 个元素并执行过滤。进程 P0 和 P1 产生两个数组,类似地,P2 和 P3 也产生。
在下一步中,两个数组将在 N/2 个计算步骤中组合在一起。最后,在根级别,我们必须组合两个需要 N 个计算步骤的数组。
在总结所有计算步骤时,我们发现 7N/4 > N > N/4。
整体复杂度为 O(n + m),效率不高。此外,我们可以看到合并与过滤花费的时间一样多。为了理解它,让我们定义组合操作。
正如我们所见,需要 2n + 2m = 2(n+m)。在复杂性分析中,常数被忽略,因此 O(n+m)。
数据结构如下所示:
HashTables 计算元素的哈希码,其中查找、插入和删除操作需要常数时间 O(1)
平衡树期望 O(logn) 到达任何节点
可变链表可以有 O(1) 级联
有了这个,我们可以看到可以在微不足道的时间内组合数据结构。为了进行并行计算,我们必须在 O(logn + logm) 时间内执行。
为什么要对并行程序进行基准测试?
性能优势是我们首先编写并行程序的主要原因。它计算程序部分的性能指标,这就是为什么它比对顺序程序进行基准测试更重要的原因。
影响性能的因素:
处理器数量
访问内存和吞吐量时的延迟
处理器速度
缓存行为
垃圾收集
即时编译
线程调度
ScalaMeter是一个用于 JVM 的基准测试和性能回归测试框架,这是一个很好的工具。它计算程序部分的性能指标。指标可以是运行时间、内存占用、网络流量、磁盘使用情况和延迟。
概括
在本文中,我介绍了并行编程的基本原理、硬件资源的作用、复杂性和基准测试。我想强调一些在设计并行计算算法时通常会出现的要点。
并行化的限制受内核数量的限制
使用阈值,即使您有足够的内核以避免并行开销。
那么问题来了,什么时候不应该使用并行计算?
如果您没有足够的并行资源:无论是硬件核心及其通过线程池的抽象,还是诸如内存带宽之类的不太明显的东西。
如果并行化的开销超过收益:即使您有足够的内核,并行计算也会产生开销。这包括,除其他外,产生任务和调度
单独使用上述两个条件会使并行执行的效率低于顺序执行,因此稳健的算法应确保不会出现这些问题。
考虑数组只有 100 个元素并且我们必须在多个内核上并行执行元素添加的情况。在这里,无论您拥有多少个内核,并行化计算的开销都是不值得的。只是数据不够。
另一方面,如果我们有一个包含 1000 个元素的数组,并且必须对其执行过滤或任何其他操作,那么并行计算就变得值得了。
以上是关于使用 Scala 进行并行计算的主要内容,如果未能解决你的问题,请参考以下文章