精HDFS踢盘策略优化
Posted Java不睡觉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精HDFS踢盘策略优化相关的知识,希望对你有一定的参考价值。
通过本文,你将有如下收获:
如何根据hdfs location定位到真实DataNode上的哪个目录,再进一步定位到磁盘扇区?
如何模拟扇区故障。诱发HDFS的IOException?
HDFS踢盘的优化方案。
一、实验过程
准备工作:为了防止坏块被HDFS修复,增大每次坏块的复现时间成本,因此在上传测试文件时指定为单副本,这样弄坏这个block之后,HDFS也没法正常补充它。
上传文件,并指定单副本命令
hdfs dfs -D dfs.replication=1 -put testfile /user/zhanghaobo/
补充知识:设置某个目录或文件为单副本(对已经上传的不影响)
hdfs dfs -setrep -R 1 /xxx/xxx
使用hdfs fsck命令查看上传文件所在DataNode
hdfs fsck /user/zhanghaobo/testfile -files -blocks -locations
BP-1950479666-x.x.x.x-1620631820311:blk_1141558067_67874822 len=1024 Live_repl=1 [DatanodeInfoWithStorage[x.x.x.x:50010,DS-54edfefb-2b2f-479b-bcbc-c6da5e73168f,DISK]]
接下来准备把这个blk_1141558067所在的扇区弄坏。
首先去test2节点的datanode数据目录下,找到这个blk文件所在的盘
使用如下命令输入每个盘的StorageID:
for i in $(ls /data*/hadoop/hdfs/data/current/VERSION); do echo $i; cat $i | grep storageID; done
所以上传的测试文件被存到了/data11目录下。find这个文件夹,找到具体的子目录:
zhanghaobo@sg-hadoop-test2:/data11$ sudo find ./ -name blk_1141558067
./hadoop/hdfs/data/current/BP-1950479666-x.x.x.x-1620631820311/current/finalized/subdir10/subdir11/blk_1141558067
zhanghaobo@sg-hadoop-test2:/data11$
使用filefrag命令查看这个文件在块设备上的位置:
zhanghaobo@sg-hadoop-test2:/data11$ sudo filefrag -v ./hadoop/hdfs/data/current/BP-1950479666-x.x.x.x-1620631820311/current/finalized/subdir10/subdir11/blk_1141558067
Filesystem type is: ef53
File size of ./hadoop/hdfs/data/current/BP-1950479666-x.x.x.x-1620631820311/current/finalized/subdir10/subdir11/blk_1141558067 is 1024 (1 block of 4096 bytes)
ext: logical_offset: physical_offset: length: expected: flags:
0: 0.. 0: 127970139.. 127970139: 1: last,eof
./hadoop/hdfs/data/current/BP-1950479666-x.x.x.x-1620631820311/current/finalized/subdir10/subdir11/blk_1141558067: 1 extent found
记住上述输出的physical_offset:127970139,这里的单位是4K(块大小),所以我们要根据真实的磁盘扇区大小再进行一次映射。因此要确定此机器磁盘的扇区大小,以便后续通过块offset定位扇区,使用如下命令:
cat /sys/block/sdb/queue/hw_sector_size
512
扇区大小是512B,块大小是4KB,所以要在刚才的physical_offset基础上乘8得到真实的磁盘上的偏移。
127970139 * 8 = 1023761112
接下来使用hdparm命令将这个扇区弄坏掉。(/dev/sdl是/data11的设备名,可通过df -h查看)
zhanghaobo@sg-hadoop-test2:/data11$ sudo hdparm --yes-i-know-what-i-am-doing --make-bad-sector 1023761112 /dev/sdl
/dev/sdl:
Corrupting sector 1023761112 (WRITE_UNC_EXT as pseudo): succeeded
好的,万事具备只欠东风。接下来我们去test3节点上读取这个文件。
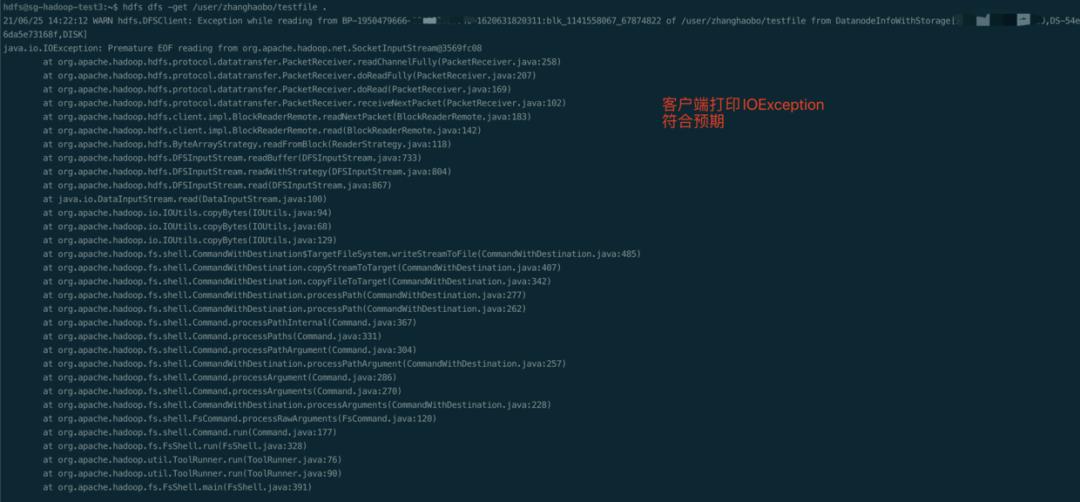
客户端的控制台会打印出IOException,这符合预期。
更重要的是看DataNode的日志,里面有我们的添加的打印某个Volume发生IOException的次数信息,如下图:
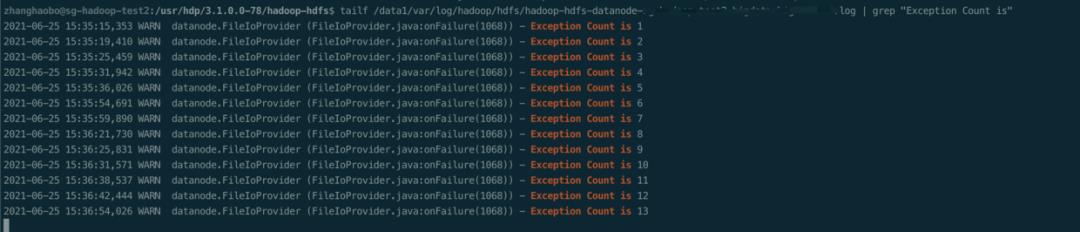
发现Volume的IOException是不断在增长的。其实这个IOException的信息还可以直接通过DataNode的jmx界面查看:
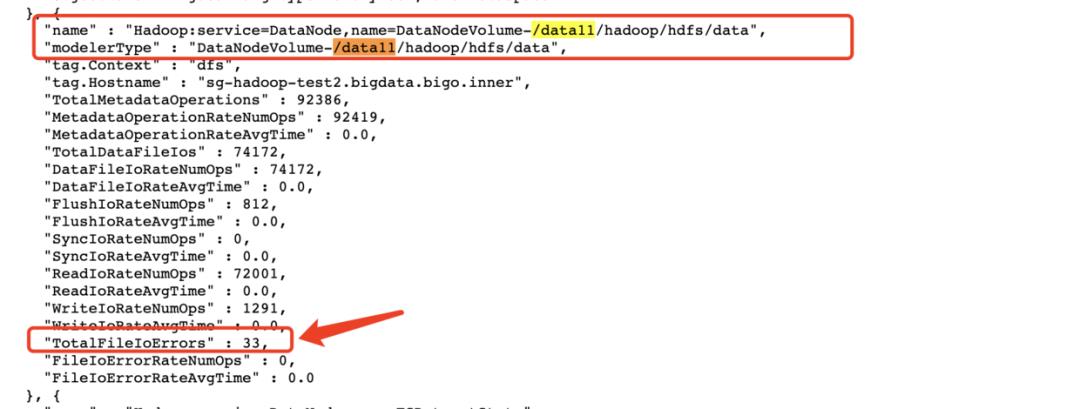
好的,到这里我们就从模拟IOException到观测DataNode侧指标变化一条龙走完了。
二、踢盘优化方案
在《HDFS--VolumeScanner深度分析》一文中指出了DataNode现有的踢盘机制触发条件和逻辑,指出了不足。并在文章最后给出了可以进行相关优化的大致方向。
本文我们就来重点聊聊如何实现。
先捋顺这样一个逻辑:DataNode现有踢盘机制触发条件是检查目录是否可读可写可执行,如果检测都通过则调用markHealthy标记为健康状态,如检测不过会抛出Exception。但是并没有考虑到部分坏块导致频繁发生IOException却依然检测通过的情形。因此我们要在markHealthy中加过判断,如果某个Volume当前一段时间内的IOException发生次数超过某个阈值(或这IOException增长速率超过某个阈值,看需求和具体实现而定),
tips:
如果要是用DataNode自带的FileIoException计数,需要设置
dfs.datanode.fileio.profiling.sampling.percentage 为1-100之间的值才行。此配置项默认值是0,不开启。如果不使用DataNode自带的FileIoException计数功能的话,需要我们自己开发。后面我会给出
接下来给出相关的code
首先定义一个VolumeExCountPair类,用于保存volume的IOException次数和时间戳。
package org.apache.hadoop.hdfs.server.datanode;
/**
* Record volume's IOException total counts and update timestamp
*/
public class VolumeExCountPair {
private long prevTs;
private long IoExceptionCnt;
private VolumeExCountPair() {
}
public VolumeExCountPair(long prevTimeStamp, long IoExceptionCnt) {
this.prevTs = prevTimeStamp;
this.IoExceptionCnt = IoExceptionCnt;
}
public void setNewPair(long now, long curExCnt) {
setPrevTs(now);
setIoExceptionCnt(curExCnt);
}
public VolumeExCountPair getPair() {
return new VolumeExCountPair(prevTs, IoExceptionCnt);
}
public void setPrevTs(long prevTs) {
this.prevTs = prevTs;
}
public void setIoExceptionCnt(long ioExceptionCnt) {
IoExceptionCnt = ioExceptionCnt;
}
public long getPrevTs() {
return prevTs;
}
public long getIoExceptionCnt() {
return IoExceptionCnt;
}
}
接着在FsVolumeSpi接口中,增加一个getExCountPair方法,用于获取上面的VolumeExCountPair类
然后在每个FsVolumeSpi的实现类中实现刚才添加的getExCountPair方法。这里以FsVolumeImpl类为例。
最后在DatasetVolumeChecker.ResultHandler#markHealthy方法中获取数据进行相应的处理。
private void markHealthy() {
long totalFileIoErrors = reference.getVolume().getMetrics().getTotalFileIoErrors();
VolumeExCountPair volumeExCountPair = reference.getVolume().getExCountPair();
LOG.warn("Volume {} Exception Count is {}", reference.getVolume().toString(), reference.getVolume().getExCountPair().getIoExceptionCnt());
if (volumeExCountPair.getIoExceptionCnt() == 0) {
volumeExCountPair.setNewPair(System.currentTimeMillis(),totalFileIoErrors);
} else {
// 拿到之前的时间戳、与currentTimeMillis比较
// 若过去多长时间内发生IOException的次数超过threshold次,则把volume标记为failureVolumes,然后直接return,不走原来的逻辑
}
// 下面是本来代码的逻辑
synchronized (DatasetVolumeChecker.this) {
healthyVolumes.add(reference.getVolume());
}
}
三、其他零碎的想说的
①可以对DataNode的Volume FileIoError进行监控,如果发生异常及时给出告警,便于及时排除慢节点隐患,保存异常现场,方便后续问题定位。
② 后续在生产集群上观测一下,如果表现良好,可贡献给社区。
③上面的优化代码只是一个初步的框架,还需要总和验证数据的并发安全性。
以上是关于精HDFS踢盘策略优化的主要内容,如果未能解决你的问题,请参考以下文章