第四篇:协调和协定之故障检测和互斥算法
Posted flying_1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第四篇:协调和协定之故障检测和互斥算法相关的知识,希望对你有一定的参考价值。
目标
对于分布式系统中的一组进程(即使存在故障)
- 协调他们的行动以实现共同目标
- 达成一致的值
话题(这几个话题是我们之后会细节讨论的)
- 故障检测
- 相互排斥
- 选举
- 组通信(组播)
- 共识
简单回忆重要概念
同步系统
- 一个进程的计算有已知的下界和上界
- 消息传递时间被限制在一个已知值
- 每个进程都有一个时钟,它的实时的漂移率受一个已知值的限制
异步系统
- 对进程执行时间、消息传递时间、时钟漂移率没有限制
(失败/故障)假设
进程通过可靠的信道连接
进程不依赖其他进程进行通信
取决于主题/算法:
- 进程不能失败
- 进程可能崩溃
- 故障检测器可用于检测崩溃故障
- 进程可能会意外运行
失败/故障检测器
可以判断进程是否崩溃的服务
可以与其他进程协作以检测故障
通常通过交互本地故障检测器实现
- 每个进程中的本地故障检测器
- 本地故障检测器与其他进程的本地故障检测器一起运行故障检测算法
两种类型:
- 不可靠的故障检测器
- 可靠的故障检测器
不可靠的故障检测器
当查询进程时,产生下面两个值之一:
unsuspected
- 检测器最近收到了表明该过程没有失败的证据
- 例如,最近收到一条消息
- 可能不准确,该过程可能从那时起就失败了
suspected
- 检测器有一些迹象表明该进程可能已失败/故障
- 例如,在很长一段时间内没有收到任何消息
- 可能不准确,例如,流程可能正常运行,但通信链路已关闭,或者运行速度可能比预期的要慢
两者都是提示,可能会也可能不会准确反映进程是否实际失败或故障。
可靠的故障检测器
当查询进程时,产生下面两个值之一:
unsuspected
- 就像在不可靠的检测器中一样可能不准确
failed
- 准确判断对等进程失败
不可靠的故障检测器:实现
实现:
- 周期性地,每个进程 p 每 T 秒发送一个“p 在这里”消息给每个其他进程
- 如果 q 处的本地故障检测器在 T+D(D = 估计最大传输延迟)内未从 p 接收到“p 在这里”,则怀疑 p
- 如果随后收到消息,则声明 p 为 OK
问题:传输延迟校准
- 对于小D,间歇性网络性能降级会导致疑似节点
- 对于大 D 崩溃将保持未观察到(崩溃的节点将在超时到期之前修复)
解决方案
- 反映观察到的网络延迟的变量 D
可靠的故障检测器:实现
只能在同步网络中使用
分布式互斥
分布式进程需要协调对临界区中共享资源、变量等的访问,以便一次只能有一个进程在临界区
在分布式系统中
- 没有共享变量(信号量)
- 没有协调对资源的访问的本地内核
- 消息传递是实现分布式互斥的唯一手段
- 算法必须处理不可预测的消息延迟和系统状态的不完整知识。
例子
- 对共享文件的一致访问(例如,网络文件系统)
- 以太网中的媒体访问控制
假设
只有一个临界区
系统是异步的
消息传递可靠,消息完整传递
对于这种情况:进程不会失败
应用层级的协议
enter()
- 进入临界区
- 必要时阻止
resourceAces()
- 访问临界区的共享资源
exit()
- 离开临界区
- 现在其他进程可以进入
互斥的条件
ME1:(safety 安全)
- 一次最多可以在临界区执行一个进程
ME2:(liveness活力)
- 进入和退出临界区的请求最终会成功(即没有死锁或饥饿)
ME3:(-> 顺序)
- 如果对资源的一个请求 r1 发生在另一个请求 r2 之前,则 r1 应该在 r2 之前进入临界区
互斥算法的评估指标
带宽消耗
- 每次 CS(临界区) 执行所需的消息数
- 进入 CS 所需的消息数 + 退出 CS 所需的消息数
客户端延迟
- 进程在每次进入和退出操作时产生的延迟(当没有其他进程在或等待时)
吞吐量
- 进程可以访问 CS 的速率 = 1/(SD+E)
- E = 在临界区花费的平均时间
- SD = 同步延迟 = 一个进程退出 CS 和下一个进程进入它之间的时间间隔(当只有一个进程在等待时)
- 同步延迟越短,吞吐量越大
中央服务器算法
中央服务器接收访问请求
- 如果临界区没有进程,请求将被批准
- 如果进程在临界区,请求将排队
进程离开临界区
- 授予对队列中下一个进程的访问权限,或者等待新的请求,如果队列为空
安全(ME1)和活性(ME2)有保障
不保证顺序 (ME3)
- 网络延迟可能会重新排序请求
服务器的性能和可用性是主要缺点
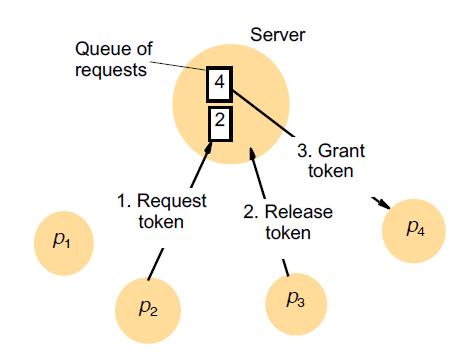
上图是例子,P2进程请求临界区,因为已经有其他进程在排队,所有加入队列,刚好P3使用完临界区释放资源并退出,P4因为在队列最前面获得批准进入临界区
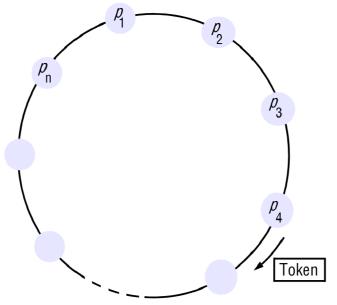
基于环的算法
围绕环传递令牌(在一个方向上)
环是逻辑的,不一定是物理链接
- 每个进程 pi 都连接到进程 p(i+1) mod N
令牌到达
- 只有拥有令牌的进程才能访问临界区
- 在以下情况下将令牌传递给邻居:令牌到达时没有请求,或退出临界区时
算法满足 ME1、ME2,但不满足 ME3
下图是环算法的样子
表现
带宽
- 恒定的带宽消耗!
- 如果没有进程请求令牌,则算法浪费带宽
- 输入:1 到 N 条消息
- 退出:1 条消息
客户端延迟
- 0 到 N 消息传输延迟
同步延迟
- 1 到 N-1 消息传输延迟
Ricart 和 Agrawala的算法
基于Lamport时钟
- 请求有逻辑时间戳
进程广播请求以进入 CS
- 当收到所有其他进程的回复时,进程可以访问 CS
- 如果他们在 CS 中或者如果他们更早地请求访问 CS,则处理延迟回复
进程 ID 用于打破关系
初始化:
state:= released;
去进入这个临界区:
state: = wanted;
多播请求给所有进程
T:= request timestamp
等待知道收到N-1个进程的回复
state:= Held
在收到请求 <Ti, pi> at pj (i ≠ j)
if (state = HELD or (state = WANTED and (T, pj) < (Ti, pi)))
then
将来自pi的请求加入队列不用回复
else
立刻回复pi
end if
在退出临界区:
state := RELEASED;
回复队列中的请求
再次举例讲解
p3 不想进入临界区
p1 和 p2 同时请求进入临界区
p1的请求时间戳为41,p2的时间戳为34
p3 立即回复 p1 和 p2 的请求
p2 接收 p1 的请求:它自己的请求具有较低的时间戳,因此不回复 p1
p1 发现 p2 的请求具有比它自己的请求低的时间戳并立即回复
一旦p2收到来自p1的回复,收到第二个回复(N-1=2),就可以进入临界区
当 p2 退出临界区时,它会回复 p1 的请求
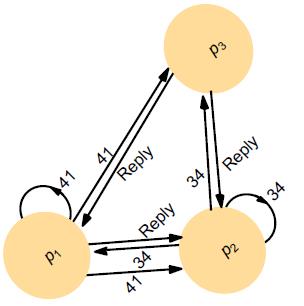
ME互斥条件
算法满足ME1
- 两个进程 pi 和 pj 只能同时访问临界区,如果它们都直接回复对方
- 但是对 <Ti, pi> 是完全有序的,一个进程必须将另一个放在队列中
算法满足ME2
- 所有其他 N-1 进程最终都会回复
算法满足ME3
- 具有较低 Lamport 时间戳的请求更早被授予
表现
消息复杂度
- 昂贵的访问,需要 2(N-1) 条消息
客户端延迟
- 请求和回复的往返时间
同步延迟
- 一条消息传输时间
存在用于降低带宽成本的改进版本,例如,在不执行协议的情况下重复允许同一进程进入
Maekawa的投票算法
主要思想:
- 一个进程不向所有其他进程请求许可,而只向进程的一个子集请求许可
进程被分组为整数个投票集
- 投票集至少有一个重叠过程
进程必须收集足够的选票才能进入 CS
- 足够:来自其投票集中的所有进程
2 个投票集的交集过程确保 ME1
- 因为他们只投票给一名候选人
投票集
对于 N 个进程 p1, ..., pN,选择投票集 V1, ..., VN 使得:
1. ∀i ∀j : i ≠ j,1 ≤ i, j ≤ N : Vi ∩ Vj ≠ {}(任意两个投票集重叠)
2. ∀i : 1 ≤ i ≤ N : pi ∈ Vi (pi 的投票集是 Vi,所以 pi 必须在 Vi 中)
3. ∀i : 1 ≤ i ≤ N : |Vi| = K(公平:所有投票集大小相等)
4. 每个进程 pj 包含在 K 个投票集 Vi 中
投票集的条件
优化目标
- 在实现互斥的同时最小化 K
- 当 K ~ √N 时达到
- 注意~而不是=,事实上,不能根据N来选择K,反之亦然。 Maekawa 指出,首先选择 K 的值,然后根据公式 N=K(K-1)+1 从 K 计算 N
最佳投票集
- 重要的计算,近似:导出 Vi 使得 |Vi| ~ 2√N - 1
- 将进程置于 √N × √N 矩阵中
- 让 Vi 包含 pi 的行和列的并集
算法
初始化
state := RELEASED;
voted := FALSE;
对于Pi进入临界区
state := WANTED;
多播请求 所有的进程在Vi投票集中;
等待直到回复数量等于K;
state := HELD;
在Pj收到来自Pi的请求
if (state = HELD or voted = TRUE)
then
将来自Pi的请求加入队列不回复;
else
回复Pi;
voted := TRUE;
end if
对于Pi退出临界区
state := RELEASED;
多播释放 所有的进程在Vi投票集中;
在Pj收到来自Pi的释放
if (请求队列非空)
then
移除队列头 – say pk;
回复 pk;
voted := TRUE;
else
voted := FALSE;
end if讨论
满足 ME1
- 如果两个进程可以同时进入临界区,那么它们投票集的非空交集中的进程将授予对两个进程的访问权限
- 不可能,因为所有进程在收到请求后最多投一票
死锁是可能的
- 给定三个进程,其中 V1 = {p1, p2}, V2 = {p2, p3}, V3 = {p3, p1}
- 所有请求访问 CS
- 构建循环等待图
- p1 对 p2 的请求,对来自 p3 的请求进行排队
- p2 请求 p3,从 p1 队列请求
- p3 对 p1 的请求,对来自 p2 的请求进行排队
满足 ME2 和 ME3 的扩展
- 修改以确保没有死锁
- 使用逻辑时钟:按发生前的顺序处理队列请求
表现
带宽利用率
- 每次进入 2√N,每次退出 √N,总共 3√N
- 比 Ricart 和 Agrawala 好(对于 N > 4)
客户端延迟
- 一次往返时间
- 与 Ricart 和 Agrawara 相同
同步延迟
- 往返时间
- 代替 Ricart 和 Agrawara 中的单消息传输时间
失败/故障
所涵盖的算法都不能容忍崩溃失败
环算法
- 不能容忍单一的崩溃失败
Maekawa算法
- 如果进程在不需要的投票集中,则容忍崩溃失败,系统的其余部分不受影响
中央服务器
- 容忍既没有请求访问也没有当前处于临界区的节点的崩溃故障
Ricart 和 Agrawala 的算法
- 如果我们假设一个失败的进程隐式地授予所有请求,则容忍崩溃失败
- 需要可靠的故障检测器
今天的内容就到这里拉!内容也是好多,辛苦大家观看,如果有问题,老样子,欢迎评论区随时交流探讨!
以上是关于第四篇:协调和协定之故障检测和互斥算法的主要内容,如果未能解决你的问题,请参考以下文章