第十篇:上下文表示
Posted flying_1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第十篇:上下文表示相关的知识,希望对你有一定的参考价值。
目录
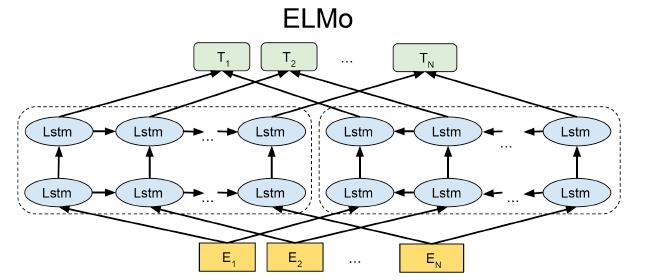
ELMO:Embeddings from Language Models
BERT: Bidirectional Encoder Representations from Transformers
Self-Attention 通过 Query, Key, Value
词向量/嵌入
• 每种词类型都有一种表示
‣ Word2Vec
• 无论单词的上下文如何,始终使用相同的表示
• 无法捕捉词的多种含义
• 上下文表示 = 基于上下文的单词表示
• 预训练的上下文表示非常适合下游应用程序!
RNN 语言模型
解决上面无法使用上下文的问题了嘛?
• 几乎,但RNN上下文表示仅捕获左侧的上下文
• 解决方案:改用双向RNN!
大纲
• ELMo
• BERT
• Transformers
ELMo
ELMO:Embeddings from Language Models
• 在 1B 单词语料库上训练双向、多层 LSTM 语言模型
• 将来自多层 LSTM 的隐藏状态组合起来用于下游任务
‣ 先前的研究仅使用顶层信息
• 显着提高任务性能!
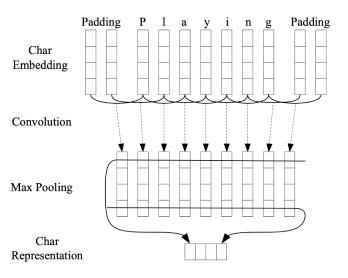
• LSTM 层数 = 2
• LSTM 隐藏维度 = 4096
• 用于创建词嵌入的字符卷积网络 (CNN)
‣ 没有生词
提取上下文表示
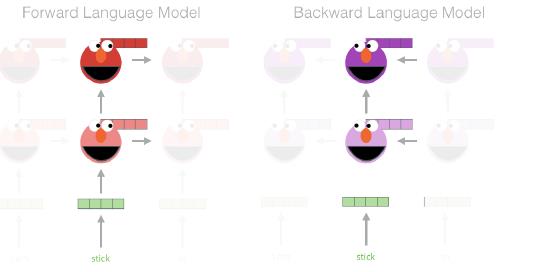
抽取stick单词的上下文表示
ELMO 有多好?
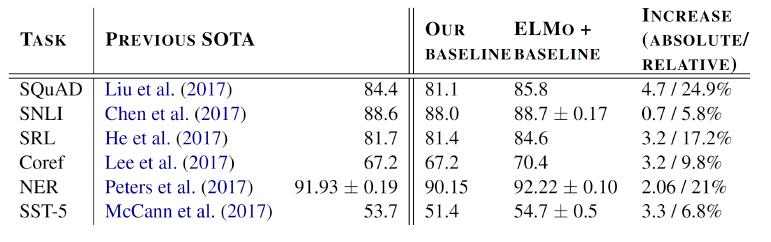
| SQuAD | QA |
| SNLI | textual entailment 文本蕴涵 |
| SRL | 语义角色标签 |
| Coref | coreference resolution共指解析 |
| NER | 命名实体识别 |
| SST-5 | 情感分析 |
其他发现
• 较低层表示 = 捕获语法
‣ 适合词性标注、NER
• 更高层表示 = 捕获语义
‣ 有利于 QA、文本蕴涵、情感分析
BERT
RNN 的缺点
• 顺序处理:难以扩展到非常大的语料库或模型
• RNN 语言模型从左到右运行(仅捕获上下文的一侧)
• 双向 RNN 有帮助,但它们只能捕获表面双向表示
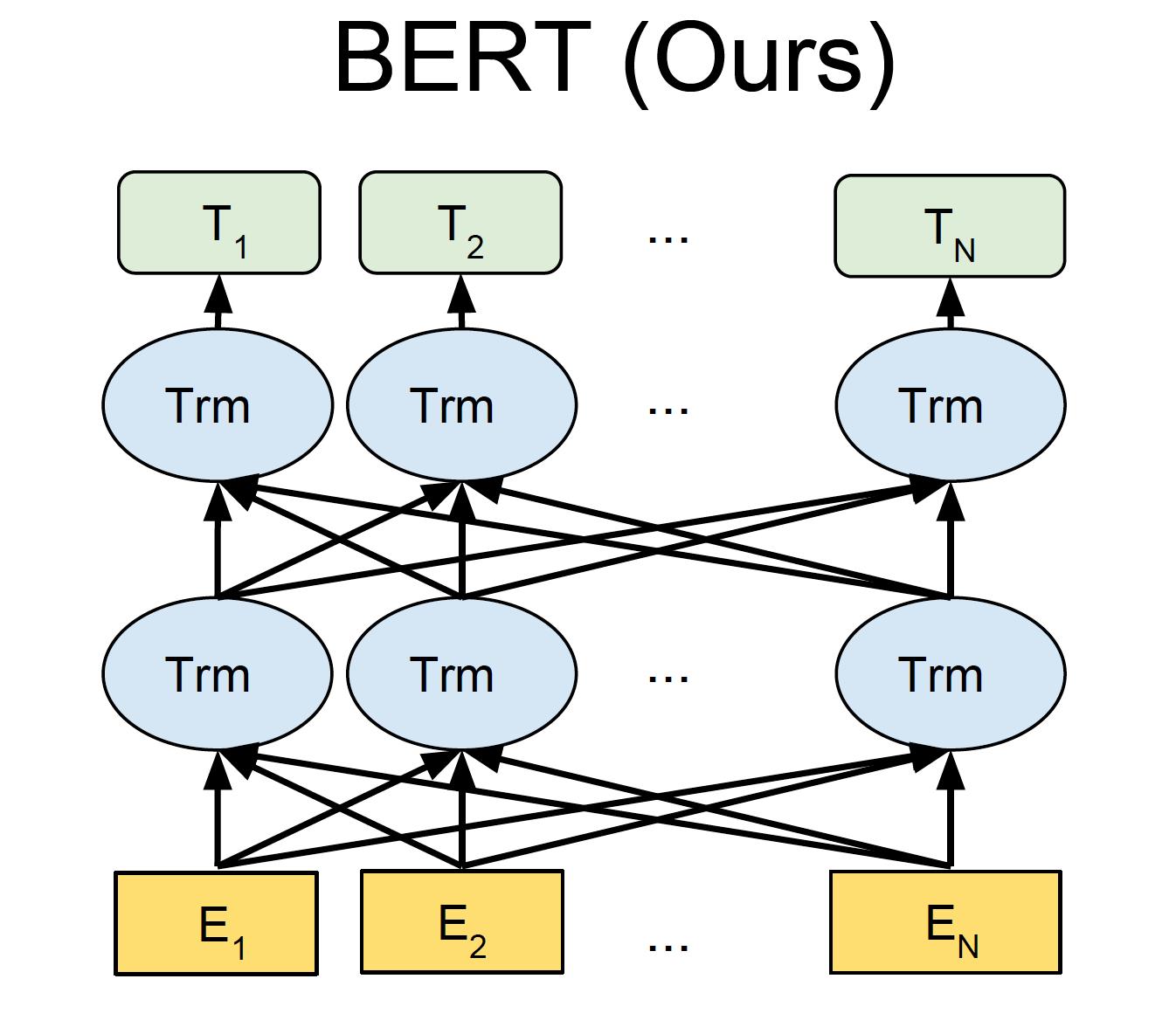
BERT: Bidirectional Encoder Representations from Transformers
• 使用自注意力网络(又名 Transformers)来捕获单词之间的依赖关系
‣ 无顺序处理
• 用于捕获深度双向表示的掩码语言模型目标
• 失去生成语言的能力
• 如果目标是学习上下文表示,则不是问题
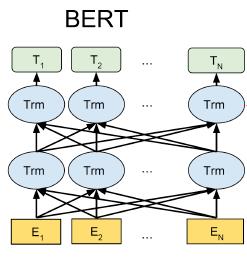
目标 1:掩码语言模型
• 随机“屏蔽”k% 的令牌
• 目标:预测被屏蔽的词

如上图这样子
目标 2:下一句预测
• 了解句子之间的关系
• 预测句子 B 是否跟随句子 A
• 对分析句子对的下游应用有用的预训练目标(例如文本蕴涵)
训练/模型详细信息
• WordPiece(子词)标记化
• 多层转换器以学习上下文表示
• BERT 在 Wikipedia+BookCorpus 上进行了预训练
• 训练需要在几天内使用多个 GPU
如何使用BERT?
• 给定一个预训练的 BERT,在下游任务上继续训练它(即微调)
• 但如何使其适应下游任务?
• 在上下文表示之上添加分类层
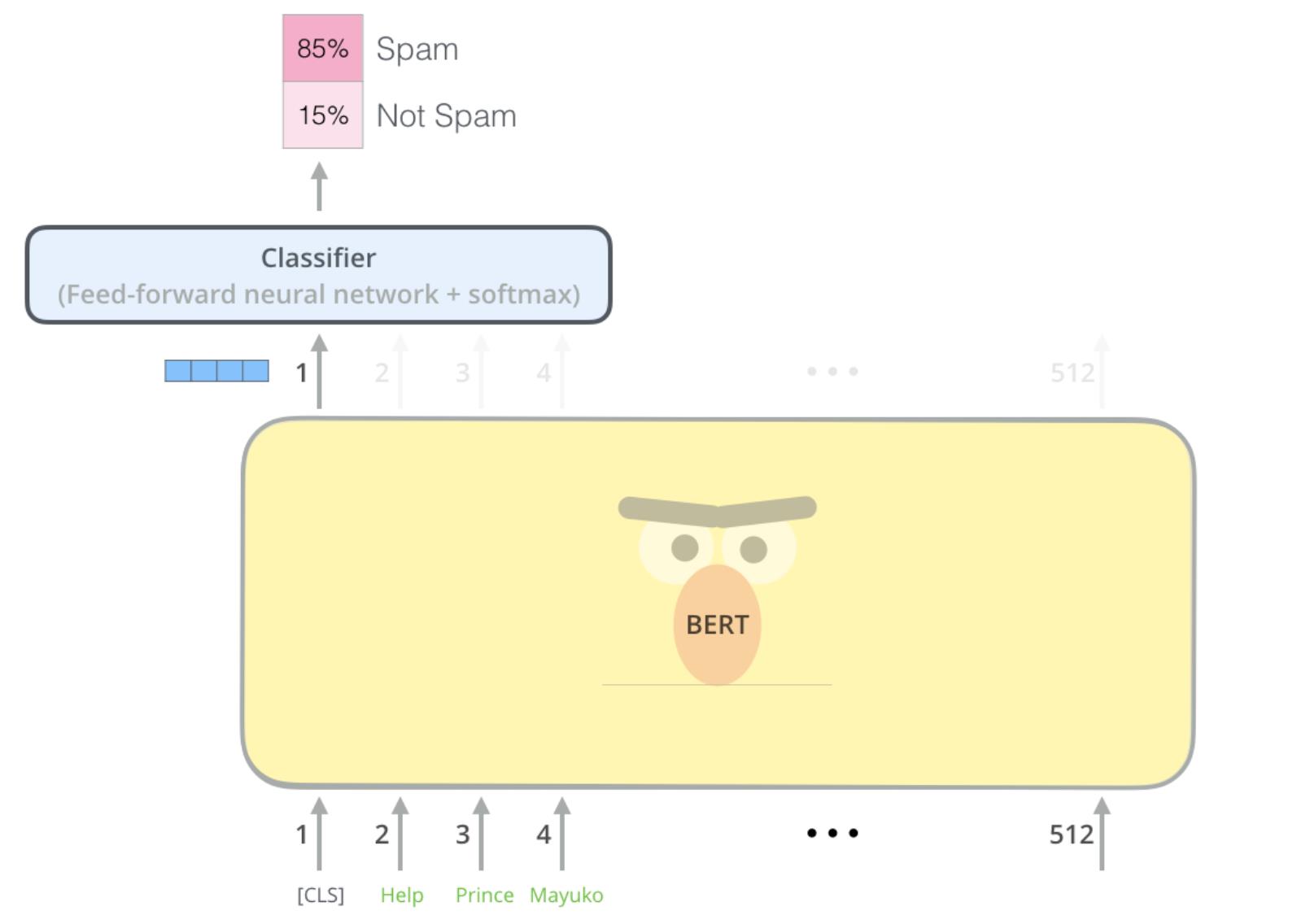
示例:垃圾邮件检测
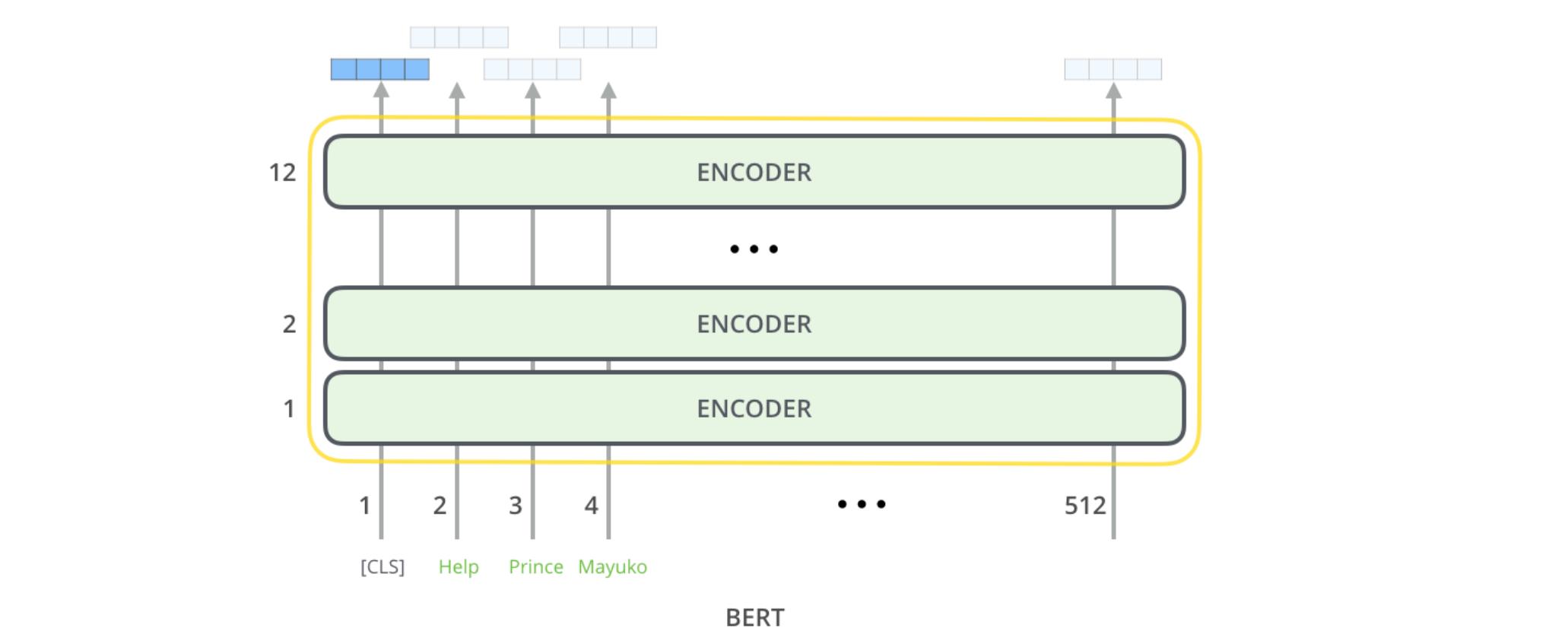
CLS:每个句子开头的特殊标记
上图中最后会输出每个单词对应的文本表示,CLS则是句子对应的文本表示
1旁边的四个蓝色方格就是cls 符号,也就是输入的这句话的文本表示;
Classifier:下游任务的分类层; 随机初始化
微调时,全网参数更新!全网参数指的是bert中的参数+分类层的参数
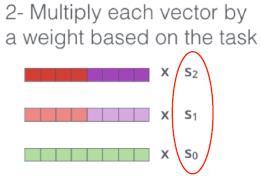
BERT vs. ELMo
• ELMo 仅提供上下文表示
• 下游应用有自己的网络架构
• ELMo 参数在应用于下游应用时是固定的
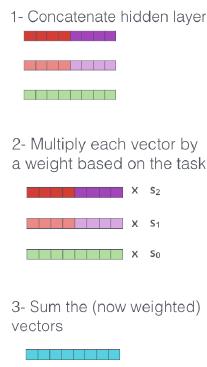
‣ 仅学习组合来自不同 LSTM 层的状态的权重(上面提到的权重s0,s1,s2)
• BERT 为下游任务添加了一个分类层
‣ 无需特定任务模型
• BERT 在微调期间更新所有参数
BERT有多好?
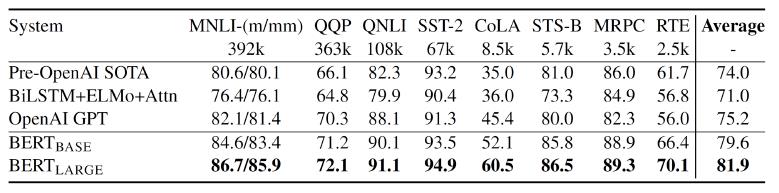
| MNLI, RTE | textual entailment 文本蕴涵 |
| QQP, STS-B, MRPC | 句子相似度 |
| QNLI | 可回答性预测 |
| SST-2 | 情感分析 |
| COLA | 句子可接受性预测 |
Transformers
Attention is All You Need
• 使用注意力而不是使用 RNN(或 CNN)来捕获单词之间的依赖关系
Self-Attention 通过 Query, Key, Value
• 输入:
‣ query q (e.g. made )
‣ key k and value v (e.g. her)
• Query, key and value都是向量
‣ 词嵌入的线性投影
• 比较目标词(made)的查询向量(query vec)和上下文词的键向量(key vec)以计算权重
目标词的上下文表示=上下文词和目标词的值向量(value vec)的加权和
![]()
简单来说,也就是query和key计算权重,然后和value加权求和即可获得目标词的向量。
我们刚刚说的过程也如下图所展示的
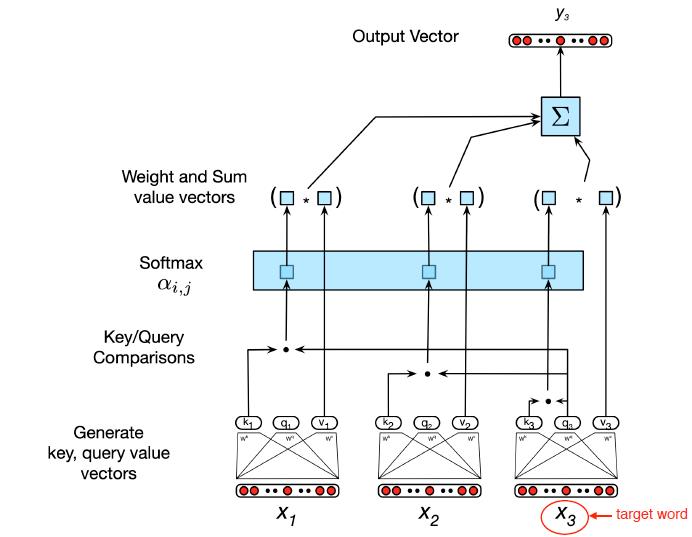
自注意力
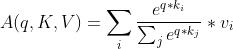
• 多个查询,将它们堆叠在一个矩阵中
A(Q,K, V) = softmax(Q*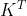 )V
)V
• 使用缩放点积来防止值增长过大
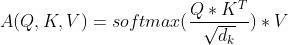
• 每个词对只有一个注意力
• 使用多头注意力来允许多次交互
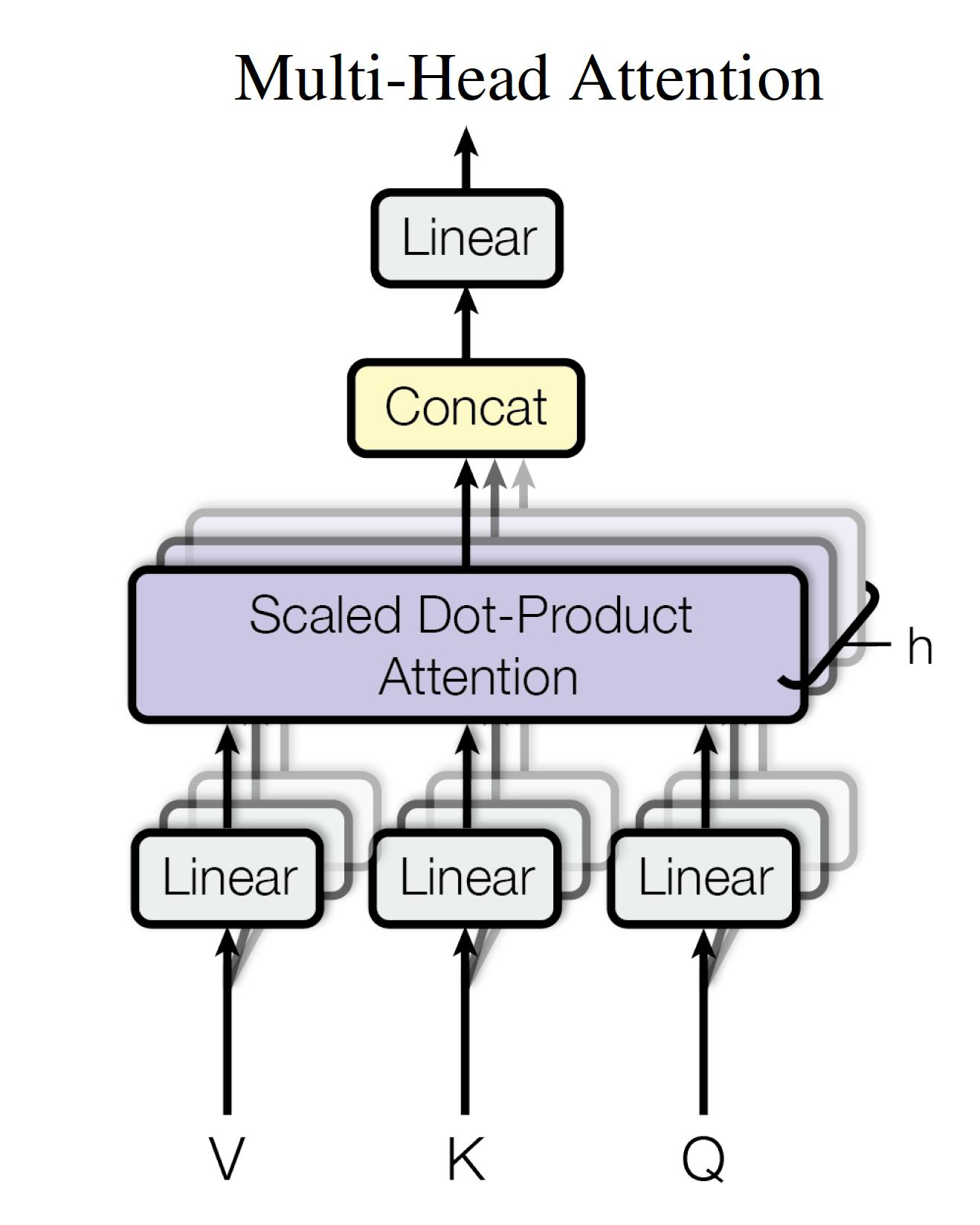
Transformer 块
中的Trm的结构是下图
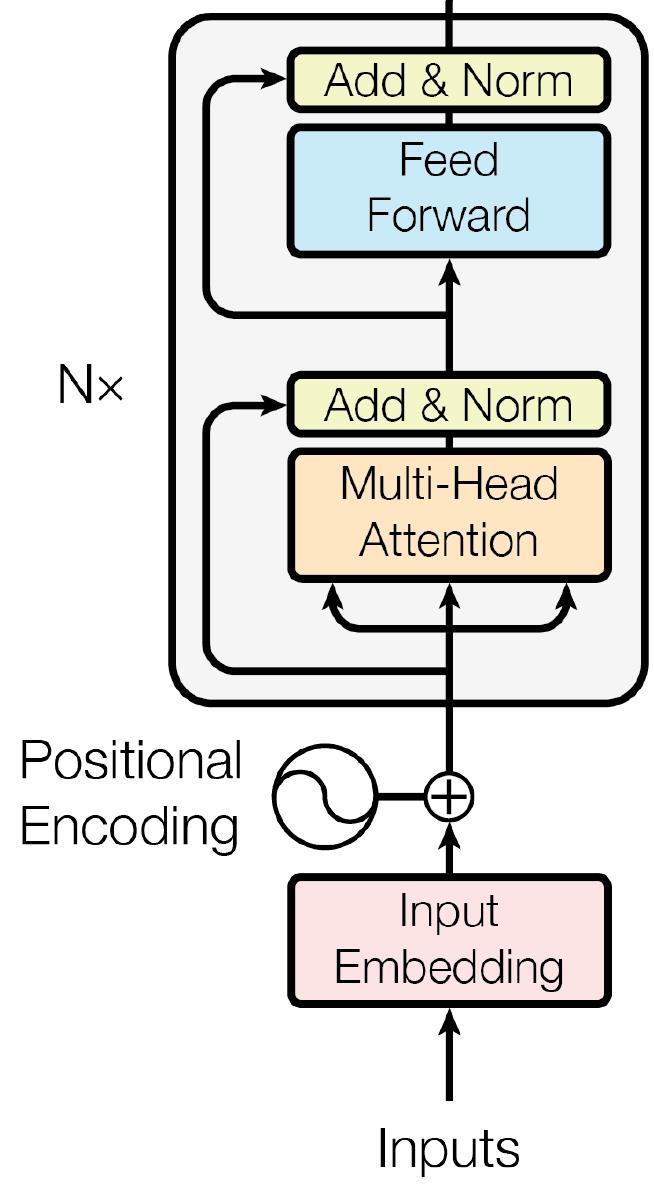
总结
• 上下文表示非常有用
• 在非常大的语料库上预先训练
‣ 学习了一些语言知识
‣ 使用无监督目标
• 当我们将它们用于下游任务时,我们不再是“从头开始”
OK,今天的内容就到这里,辛苦大家观看,有问题随时交流!
以上是关于第十篇:上下文表示的主要内容,如果未能解决你的问题,请参考以下文章