Hadoop之MapReduce(TopN和Yarn)
Posted _TIM_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop之MapReduce(TopN和Yarn)相关的知识,希望对你有一定的参考价值。
TopN
GroupingComparator
GroupingComparator是MapReduce当中reduce端的一个功能组件,主要的作用是决定哪些数据作为一组,调用一次reduce的逻辑,默认是每个不同的key,作为多个不同的组,每个组调用一次reduce逻辑,我们可以自定义GroupingComparator实现不同的key作为同一个组,调用一次reduce逻辑。有如下订单数据:现在需要求出每一个订单中成交金额最大的一笔交易
| 订单id | 商品id | 成交金额 |
|---|---|---|
| Order_0000001 | Pdt_01 | 222.8 |
| Order_0000001 | Pdt_05 | 25.8 |
| Order_0000002 | Pdt_03 | 522.8 |
| Order_0000002 | Pdt_04 | 122.4 |
| Order_0000002 | Pdt_05 | 722.4 |
| Order_0000003 | Pdt_01 | 222.8 |
分析
- 分区: 相同的订单号发送到同一个
reduce里面去,所以这个时候就得将订单号作为k2。 - 排序: 在
reduce里面还要对金额进行排序,排序是对k2进行排序。要对谁进行排序就把谁当作k2,所以这个时候就把金额作为k2。
这个时候,就会发现有冲突,一个是把订单号作为k2,目的是分区。一个是把金额作为k2,目的是排序。要想同时将我们的订单号和金额作为k2,就得把这两个字段封装到javaBean里面去,重写分区规则,按照订单号进行分区,重写排序规则,按照金额进行排序。合并相同的key,并且将对应的value形成一个集合,去调用一次reduce。而此时的k2是如下形式,没有一个k2是相等的,不能合并,所以就得重写分组的策略。
Order_0000001 222.8
Order_0000001 25.8
Order_0000002 722.4
Order_0000002 522.8
Order_0000002 122.4
Order_0000003 222.8
重写分组策略,以我们的订单号作为判断依据,订单号相同的,就认为是同一组,key进行合并,value的数据放到同一个集合里面去,形成如下格式:
Order_0000001 [222.8 25.8]
Order_0000002 [722.4 522.8 122.4]
Order_0000003 [222.8]
实现
第一步: 定义一个OrderBean,里面定义两个字段,第一个字段是我们的orderId,第二个字段是我们的金额(注意金额一定要使用Double或者DoubleWritable类型,否则没法按照金额顺序排序)
public class OrderBean implements WritableComparable<OrderBean>{
private String orderId;
private Double price;
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
@Override
public String toString() {
return orderId + "\\t" + price;
}
//指定排序规则
@Override
public int compareTo(OrderBean orderBean) {
//先比较订单ID,如果订单ID一致,则排序订单金额(降序)
int i = this.orderId.compareTo(orderBean.orderId);
if(i == 0){
i = this.price.compareTo(orderBean.price) * -1;
}
return i;
}
//实现对象的序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeDouble(price);
}
//实现对象反序列化
@Override
public void readFields(DataInput in) throws IOException {
this.orderId = in.readUTF();
this.price = in.readDouble();
}
}
第二步: 定义Mapper类
public class GroupMapper extends Mapper<LongWritable,Text,OrderBean,Text>
{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1:拆分行文本数据,得到订单的ID,订单的金额
String[] split = value.toString().split("\\t");
//2:封装OrderBean,得到K2
OrderBean orderBean = new OrderBean();
orderBean.setOrderId(split[0]);
orderBean.setPrice(Double.valueOf(split[2]));
//3:将K2和V2写入上下文中
context.write(orderBean, value);
}
}
第三步:自定义分区,按照订单id进行分区,把所有订单id相同的数据,都发送到同一个reduce中去
public class OrderPartition extends Partitioner<OrderBean,Text> {
//分区规则: 根据订单的ID实现分区
/**
*
* @param orderBean K2
* @param text V2
* @param i ReduceTask个数
* @return 返回分区的编号
*/
@Override
public int getPartition(OrderBean orderBean, Text text, int i) {
return (orderBean.getOrderId().hashCode() & 2147483647) % i;
}
}
第四步:自定义分组,按照我们自己的逻辑进行分组,通过比较相同的订单id,将相同的订单id放到一个组里面去,进过分组之后当中的数据,已经全部是排好序的数据,我们只需要取前topN即可
// 1: 继承WriteableComparator
public class OrderGroupComparator extends WritableComparator {
// 2: 调用父类的有参构造
public OrderGroupComparator() {
super(OrderBean.class,true);
}
//3: 指定分组的规则(重写方法)
@Override
public int compare(WritableComparable a, WritableComparable b) {
//3.1 对形参做强制类型转换
OrderBean first = (OrderBean)a;
OrderBean second = (OrderBean)b;
//3.2 指定分组规则
return first.getOrderId().compareTo(second.getOrderId());
}
}
第五步:定义Reducer类
public class GroupReducer extends
Reducer<OrderBean,Text,Text,NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int i = 0;
//获取集合中的前N条数据
for (Text value : values) {
context.write(value, NullWritable.get());
i++;
if(i >= 1){
break;
}
}
}
}
Yarn概述
yarn是hadoop集群当中的资源管理系统模块,从hadoop2.x开始引入yarn来进行管理集群当中的资源(主要是服务器的各种硬件资源,包括CPU,内存,磁盘,网络IO等)以及运行在yarn上面的各种任务。yarn主要就是为了调度资源,管理任务等。其调度分为两个层级来说:
一级调度管理:计算资源管理和App生命周期管理
二级调度管理: App内部的计算模型管理和多样化的计算模型
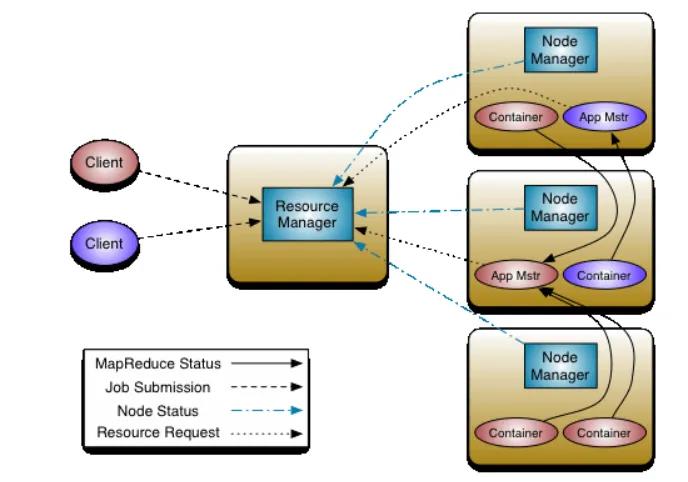
yarn的主要组件
ResourceManager: yarn集群的主节点,主要用于接收客户端提交的任务,并对任务进行分配。在每个集群中,仅有一个,负责集群资源的统一管理和调度。
NodeManager: yarn集群的从节点,主要用于任务的计算。每个节点都有一个,负责单节点资源管理和调度。
ApplicationMaster: 当有新的任务提交到ResourceManager的时候,ResourceManager会在某个从节点nodeManager上面启动一个ApplicationMaster进程,负责这个任务执行的资源的分配,任务的生命周期的监控等
Container: 资源的分配单位,ApplicationMaster启动之后,与ResourceManager进行通信,向ResourceManager提出资源申请的请求,然后ResourceManager将资源分配给ApplicationMaster,这些资源的表示,就是一个个的container.
ResourceManager主要作用: 处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、集群的资源分配与调度
NodeManager主要作用: 单个节点上的资源分配与任务调度、接收并处理来自ResourceManager的命令、接收并处理来自ApplicationMaster的命令、管理抽象容器container、定时向RM汇报本节点资源使用情况和各个container的运行状态
ApplicationMaster主要作用: 数据切分、为应用程序申请资源、任务监控与容错、负责协调来自ResourceManager的资源,开通NodeManager监视容的执行和资源使用(CPU,内存等的资源分配)
Container主要作用: 对任务运行环境的抽象、任务运行资源(节点,内存,cpu)、任务启动命令、任务运行环境
以上是关于Hadoop之MapReduce(TopN和Yarn)的主要内容,如果未能解决你的问题,请参考以下文章