Hadoop之Flume
Posted _TIM_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop之Flume相关的知识,希望对你有一定的参考价值。
flume简介
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的软件。Flume的核心是把数据从数据源source收集过来,再将收集到的数据送到指定的目的地sink。为了保证输送的过程一定成功,在送到目的地sink之前,会先缓存数据channel,待数据真正到达目的地sink后,flume再删除自己缓存的数据
flume的采集频率是怎么设置的?
设置flume的采集频率,有两种控制策略,第一种: 文件127.9M的时候采集一次 第二种: 两个小时滚动一次
flume的监测
flume比较脆弱,一旦抛异常,就会停止工作,只能够手动重启,那么什么情况下flume死掉了?如果目的地数据没有增多,或者源数据没有变少,flume都有可能死掉了,可以写一个脚本定时执行检测,检测源数据有没有减少和目的地数据有没有增多,杀掉flume,重新启动,也可以用failover的机制
flume监控文件的内容变化,将文件里面新增的数据全部收集到hdfs上面去
flume的failover机制
可以实现将我们的文件采集之后发送到下游,下游可以通过flume的配置,实现高可用。failover用于解决一个点挂掉导致整体不可用。但是有备用的可以顶上,用于解决容错的方案最常见的就是HA(高可用):同一时间 只能有一个去干活
Failover Sink Processor维护一个优先级Sink组件列表,只要有一个Sink组件可用,Event就被传递到下一个组件。故障转移机制的作用是将失败的Sink降级到一个池,在这些池中它们被分配一个冷却时间,随着故障的连续,在重试之前冷却时间增加。一旦Sink成功发送一个事件,它将恢复到活动池。Sink具有与之相关的优先级,数量越大,优先级越高。例如,具有优先级为100的sink在优先级为80 的Sink之前被激活。如果在发送事件时汇聚失败,则接下来将尝试下一个具有最高优先级的Sink发送事件。如果没有指定优先级,则根据在配置中指定Sink的顺序来确定优先级。
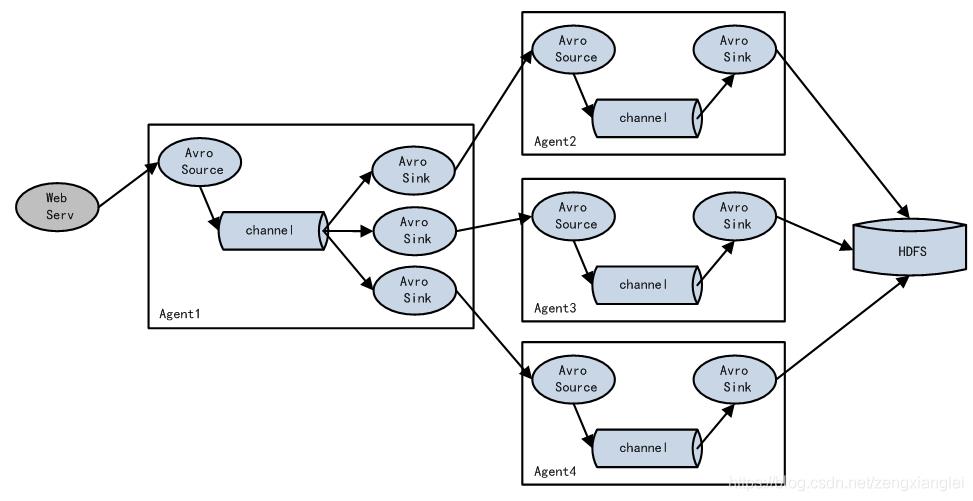
flume 负载均衡 load balance
简单来说就是一个agent从服务器上获取数据源下沉到多个sink,多个sink再由多个其他的agent1、agent2、agent3等来处理 然后sink都到hdfs
flume拦截器
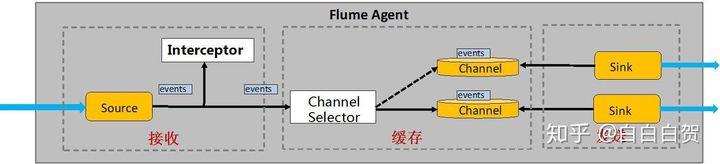
在source将event放入到channel之前,调用拦截器对event进行拦截和处理。Flume有各种自带的拦截器,比如:TimestampInterceptor、StaticInterceptor、HostInterceptor、RegexExtractorInterceptor等,通过使用不同的拦截器,实现不同的功能。但是以上的这些拦截器,不能改变原有日志数据的内容或者对日志信息添加一定的处理逻辑。
自定义拦截器
点赞、评论、浏览等不同类型的日志需要发送到不同的分析系统。此时会用到Flume拓扑结构中的Multiplexing结构,Multiplexing的原理是,根据event中Header的某个key的值,将不同的event发送到不同的Channel。定义一个Interceptor,根据event中body的类型,为不同类型的event的Header中的key赋予不同的值。
通过自定义Flume拦截器,过滤掉不需要的字段,并对指定字段加密处理,将源数据进行预处理。减少了数据的传输量,降低了存储的开销。
以上是关于Hadoop之Flume的主要内容,如果未能解决你的问题,请参考以下文章