Spark NLP的一些基础方法
Posted dqz_nihao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark NLP的一些基础方法相关的知识,希望对你有一定的参考价值。
Spark NLP的一些基础方法
1.DocumentAssembler:获取数据
为了通过 NLP 过程,我们需要对原始数据进行注释。有一个特殊的转换器可以为我们执行此操作:DocumentAssembler,它创建了第一个Document类型的注释。
val documentAssembler = new DocumentAssembler().
setInputCol("text").
setOutputCol("document")
2.Sentence detection and tokenization:识别输入文档中的句子
SentenceDetector 需要一个 Document 注释,它由 DocumentAssembler 输出提供,它本身就是一个 Document 类型标记。Tokenizer 需要一个 Document 注释类型。这意味着它适用于 DocumentAssembler 或 SentenceDetector 输出。在以下示例中,我们使用句子输出。
val sentenceDetector = new SentenceDetector().
setInputCols(Array("document")).
setOutputCol("sentence")
val regexTokenizer = new Tokenizer().
setInputCols(Array("sentence")).
setOutputCol("token")
3.Finisher:获取数据
在每个管道或 Spark NLP 完成的任何阶段的末尾,可能希望获得结果是到另一个管道或者简单地将它们写入磁盘。该Finisher注释可以帮助清理元数据(如果它设置为true),并将结果输出到一个数组:
val finisher = new Finisher()
.setInputCols("token")
.setIncludeMetadata(true)
如果需要从结构类型列以外的任何注释中获得扁平化的 DataFrame(新列中的每个子数组),可以使用explode Spark SQL 中的函数。还可以使用 Apache Spark 函数 (SQL) 以需要的任何方式操作输出 DataFrame。在这里,我们将Token和 NER 结果结合在一起:
finisher.withColumn("newCol", explode(arrays_zip($"finished_token", $"finished_ner")))
import org.apache.spark.sql.functions._
df.withColumn("tmp", explode(col("chunk"))).select("tmp.*")
4.使用 Spark ML 管道
现在想把所有这些放在一起并检索结果,可以使用管道。在 fit() 中使用将在转换中使用的相同数据,因为没有一个管道阶段有训练阶段。
val pipeline = new Pipeline().
setStages(Array(
documentAssembler,
sentenceDetector,
regexTokenizer,
finisher
))
val data = Seq("hello, this is an example sentence").toDF("text")
val annotations = pipeline.
fit(data).
transform(data).toDF("text"))
annotations.select("finished_token").show(truncate=false)
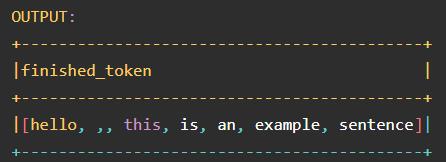
SparkML 管道是一种统一的结构,有助于创建和调整实用的机器学习管道。Spark NLP 与它们无缝集成,因此掌握这个概念很重要。一旦使用fit()训练了 流水线,它就变成了流水线模型
5.使用 Spark NLP 的 LightPipeline
LightPipeline 是 Spark NLP 特定的 Pipeline 类,相当于 Spark ML Pipeline。不同之处在于它的执行不遵循 Spark 原则,而是在本地(但并行)计算所有内容,以便在处理少量数据时获得快速结果。这意味着,我们不输入 Spark Dataframe,而是输入一个字符串或一个字符串数组,以进行注释。要创建 Light Pipelines,需要输入一个已经训练(fit)的 Spark ML Pipeline。它的 transform() 阶段被转换为 annotate() 。
import com.johnsnowlabs.nlp.base._
val explainDocumentPipeline = PretrainedPipeline("explain_document_ml")
val lightPipeline = new LightPipeline(explainDocumentPipeline.model)
lightPipeline.annotate("Hello world, please annotate my text")
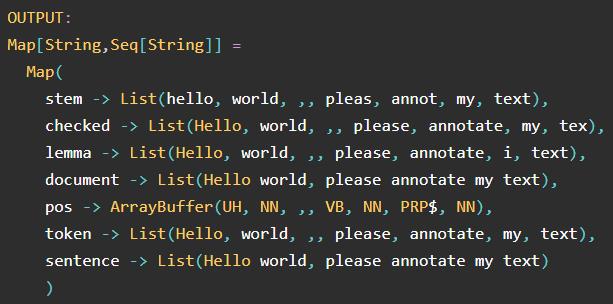
LightPipelines 是 Spark ML 管道转换为单机多线程任务,对于较小的数据量,速度提高了 10 倍以上(较小是相对的,但 50k 句子大致是一个很好的最大值)。要使用它们,只需插入经过训练的(装配好的)管道即可。
以上是关于Spark NLP的一些基础方法的主要内容,如果未能解决你的问题,请参考以下文章