John Snow 的Spark NLP 中Transformers
Posted dqz_nihao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了John Snow 的Spark NLP 中Transformers相关的知识,希望对你有一定的参考价值。
John Snow 的Spark NLP 中Transformers
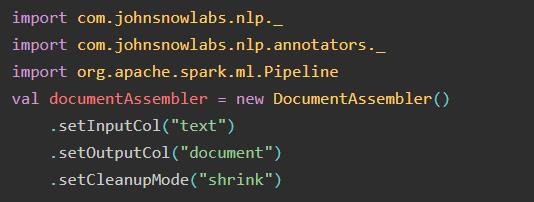
1.DocumentAssembler:获取数据
可设置的参数有:
setInputCol():设置输入列()
setOutputCol():设置输出列()
setIdCol() -> OPTIONAL: 带有 id 信息的 Sring 类型列
setMetadataCol() -> OPTIONAL: 可选:具有元数据信息的映射类型列
setCleanupMode(disabled) -> 清理选项,可能的值:
disabled: 来源保持原始。
inplace:删除新行和制表符。
inplace_full: 删除新行和制表符以及那些转换为字符串的行和制表符(即 \\n)
shrink: 删除新行和制表符,并将多个空格和空行合并为一个空格。
shrink_full: 删除新的行和制表符,包括字符串化的值,以及缩小的空格和空行。
2.TokenAssembler:重塑数据
该转换器从标记重建文档类型注释,通常在这些标记被规范化、词形还原、规范化、拼写检查等之后,以便在进一步的注释器中使用此文档注释。
可设置的参数有:
setInputCol(inputs:Array(String))
setOutputCol(输出:字符串)
setPreservePosition(preservePosition:bool): 是否保留标记的实际位置或将它们减少到一个空格

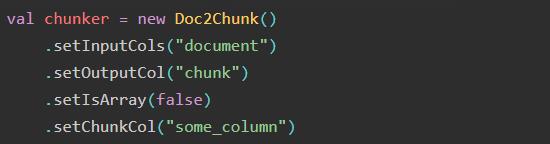
3.Doc2Chunk
使用 chunkCol 的内容将 DOCUMENT 类型注释转换为 CHUNK 类型。块文本必须包含在输入文档中。可以是 StringType 或 ArrayType[StringType](使用 isArray 参数)对于需要 CHUNK 类型输入的注释器很有用。
可设置的参数有:
setInputCol():设置输入列()
setOutputCol():设置输出列()
setIsArray(bool) -> 目标 chunkCol 是否为 ArrayType<StringType>
setChunkCol(string) -> String 或 StringArray 列,包含属于inputCol目标的块
setStartCol(string) -> 指向令牌索引的目标 INT 列(由空格分割)
setStartColByTokenIndex(bool) -> 是使用空格索引还是字符索引 startCol
setFailOnMissing(bool) -> 在 inputCol 中找不到块时是否失败
setLowerCase(bool) -> 是否通过在匹配前全部小写来增加匹配
4.Finisher
一旦准备好 NLP 管道,可能希望在其他易于使用的地方使用这注释结果。Finisher 将注释值输出到字符串中。
可设置的参数有:
setInputCols():输入列
setOutputCols():输出列
setCleanAnnotations(True) -> 是否删除中间注释
setValueSplitSymbol(“#”) -> 在注释字符中拆分值
setAnnotationSplitSymbol(“@”) -> 在注释字符之间拆分值
setIncludeMetadata(False) -> 是否包含元数据键。有时在某些注释中有用
setOutputAsArray(False) -> 是否输出为数组。可用作其他 Spark 变压器的输入。

5.EmbeddingsFinisher
该transformer设计来处理嵌入注释:WordEmbeddings,BertEmbeddings,SentenceEmbeddingd,和ChunkEmbeddings。通过使用,EmbeddingsFinisher可以轻松地将嵌入转换为浮点数或向量数组,这些数组与 Spark ML 函数(例如 LDA、K-mean、随机森林分类器或任何其他需要featureCol.
可设置的参数有:
setInputCols():输入列
setOutputCols():输出列
setCleanAnnotations(True) -> 是否删除和清理其余的注释器(列)
setOutputAsVector(False) -> 如果启用,它会将嵌入输出为向量而不是数组

以上是关于John Snow 的Spark NLP 中Transformers的主要内容,如果未能解决你的问题,请参考以下文章