内存管理:虚拟地址空间布局
Posted 一口Linux
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内存管理:虚拟地址空间布局相关的知识,希望对你有一定的参考价值。
内存管理子系统的架构如图3.1所示,分为用户空间、内核空间和硬件3个层面。
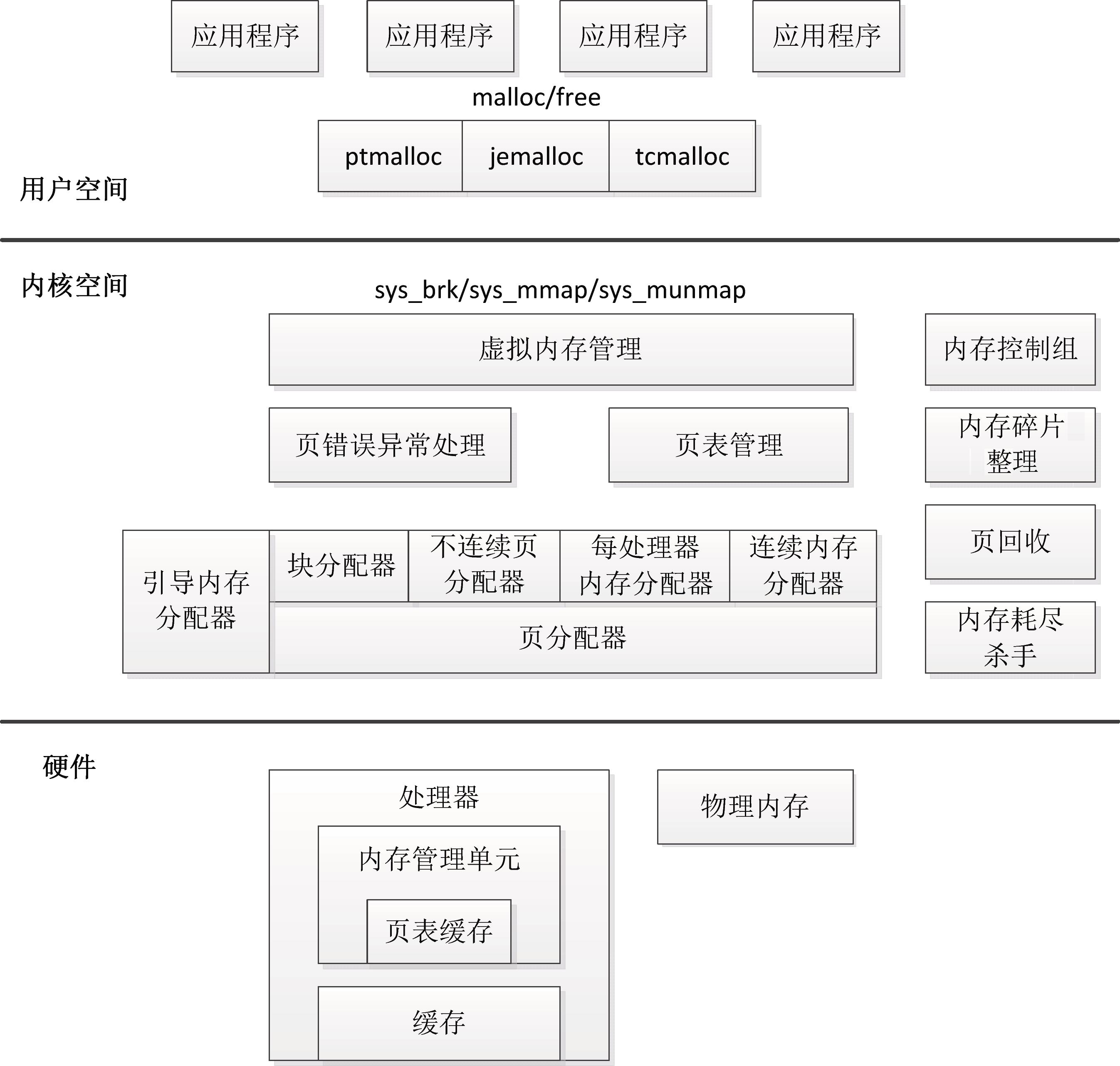
图3.1 内存管理架构
1.用户空间
应用程序使用malloc()申请内存,使用free()释放内存。
malloc()和free()是glibc库的内存分配器ptmalloc提供的接口,ptmalloc使用系统调用brk或mmap向内核以页为单位申请内存,然后划分成小内存块分配给应用程序。
用户空间的内存分配器,除了glibc库的ptmalloc,还有谷歌公司的tcmalloc和FreeBSD的jemalloc。
2.内核空间
(1)内核空间的基本功能。
虚拟内存管理负责从进程的虚拟地址空间分配虚拟页,sys_brk用来扩大或收缩堆,sys_mmap用来在内存映射区域分配虚拟页,sys_munmap用来释放虚拟页。
内核使用延迟分配物理内存的策略,进程第一次访问虚拟页的时候,触发页错误异常,页错误异常处理程序从页分配器申请物理页,在进程的页表中把虚拟页映射到物理页。
页分配器负责分配物理页,当前使用的页分配器是伙伴分配器。
内核空间提供了把页划分成小内存块分配的块分配器,提供分配内存的接口kmalloc()和释放内存的接口kfree(),支持3种块分配器:SLAB分配器、SLUB分配器和SLOB分配器。
在内核初始化的过程中,页分配器还没准备好,需要使用临时的引导内存分配器分配内存。
(2)内核空间的扩展功能。
不连续页分配器提供了分配内存的接口vmalloc和释放内存的接口vfree,在内存碎片化的时候,申请连续物理页的成功率很低,可以申请不连续的物理页,映射到连续的虚拟页,即虚拟地址连续而物理地址不连续。
每处理器内存分配器用来为每处理器变量分配内存。
连续内存分配器(Contiguous Memory Allocator,CMA)用来给驱动程序预留一段连续的内存,当驱动程序不用的时候,可以给进程使用;当驱动程序需要使用的时候,把进程占用的内存通过回收或迁移的方式让出来,给驱动程序使用。
内存控制组用来控制进程占用的内存资源。
当内存碎片化的时候,找不到连续的物理页,内存碎片整理(“memory compaction”的意译,直译为“内存紧缩”)通过迁移的方式得到连续的物理页。
在内存不足的时候,页回收负责回收物理页,对于没有后备存储设备支持的匿名页,把数据换出到交换区,然后释放物理页;对于有后备存储设备支持的文件页,把数据写回存储设备,然后释放物理页。如果页回收失败,使用最后一招:内存耗尽杀手(OOM killer,Out-of-Memory killer),选择进程杀掉。
3.硬件层面
处理器包含一个称为内存管理单元(Memory Management Unit,MMU)的部件,负责把虚拟地址转换成物理地址。
内存管理单元包含一个称为页表缓存(Translation Lookaside Buffer,TLB)的部件,保存最近使用过的页表映射,避免每次把虚拟地址转换成物理地址都需要查询内存中的页表。
为了解决处理器的执行速度和内存的访问速度不匹配的问题,在处理器和内存之间增加了缓存。缓存通常分为一级缓存和二级缓存,为了支持并行地取指令和取数据,一级缓存分为数据缓存和指令缓存。
3.2 虚拟地址空间布局
3.2.1 虚拟地址空间划分
因为目前应用程序没有那么大的内存需求,所以ARM64处理器不支持完全的64位虚拟地址,实际支持情况如下。
(1)虚拟地址的最大宽度是48位,如图3.2所示。内核虚拟地址在64位地址空间的顶部,高16位是全1,范围是[0xFFFF 0000 0000 0000,0xFFFF FFFF FFFF FFFF];用户虚拟地址在64位地址空间的底部,高16位是全0,范围是[0x0000 0000 0000 0000,0x0000 FFFF FFFF FFFF];高16位是全1或全0的地址称为规范的地址,两者之间是不规范的地址,不允许使用。
(2)如果处理器实现了 ARMv8.2 标准的大虚拟地址(Large Virtual Address,LVA)支持,并且页长度是64KB,那么虚拟地址的最大宽度是52位。
(3)可以为虚拟地址配置比最大宽度小的宽度,并且可以为内核虚拟地址和用户虚拟地址配置不同的宽度。转换控制寄存器(Translation Control Register)TCR_EL1的字段T0SZ定义了必须是全0的最高位的数量,字段T1SZ定义了必须是全1的最高位的数量,用户虚拟地址的宽度是(64-TCR_EL1.T0SZ),内核虚拟地址的宽度是(64-TCR_EL1.T1SZ)。
在编译ARM64架构的Linux内核时,可以选择虚拟地址宽度。
(1)如果选择页长度4KB,默认的虚拟地址宽度是39位。
(2)如果选择页长度16KB,默认的虚拟地址宽度是47位。
(3)如果选择页长度64KB,默认的虚拟地址宽度是42位。
(4)可以选择48位虚拟地址。
在ARM64架构的Linux内核中,内核虚拟地址和用户虚拟地址的宽度相同。
所有进程共享内核虚拟地址空间,每个进程有独立的用户虚拟地址空间,同一个线程组的用户线程共享用户虚拟地址空间,内核线程没有用户虚拟地址空间。
3.2.2 用户虚拟地址空间布局
进程的用户虚拟地址空间的起始地址是0,长度是TASK_SIZE,由每种处理器架构定义自己的宏TASK_SIZE。ARM64架构定义的宏TASK_SIZE如下所示。
(1)32位用户空间程序:TASK_SIZE的值是TASK_SIZE_32,即0x100000000,等于4GB。
(2)64位用户空间程序:TASK_SIZE的值是TASK_SIZE_64,即2VA_BITS字节,VA_BITS是编译内核时选择的虚拟地址位数。
arch/arm64/include/asm/memory.h #define VA_BITS (CONFIG_ARM64_VA_BITS) #define TASK_SIZE_64 (UL(1) << VA_BITS) #ifdef CONFIG_COMPAT /* 支持执行32位用户空间程序 */ #define TASK_SIZE_32 UL(0x100000000) /* test_thread_flag(TIF_32BIT)判断用户空间程序是不是32位 */ #define TASK_SIZE (test_thread_flag(TIF_32BIT) ? \\ TASK_SIZE_32 : TASK_SIZE_64) #define TASK_SIZE_OF(tsk) (test_tsk_thread_flag(tsk, TIF_32BIT) ? \\ TASK_SIZE_32 : TASK_SIZE_64) #else #define TASK_SIZE TASK_SIZE_64 #endif /* CONFIG_COMPAT */
进程的用户虚拟地址空间包含以下区域。
(1)代码段、数据段和未初始化数据段。
(2)动态库的代码段、数据段和未初始化数据段。
(3)存放动态生成的数据的堆。
(4)存放局部变量和实现函数调用的栈。
(5)存放在栈底部的环境变量和参数字符串。
(6)把文件区间映射到虚拟地址空间的内存映射区域。
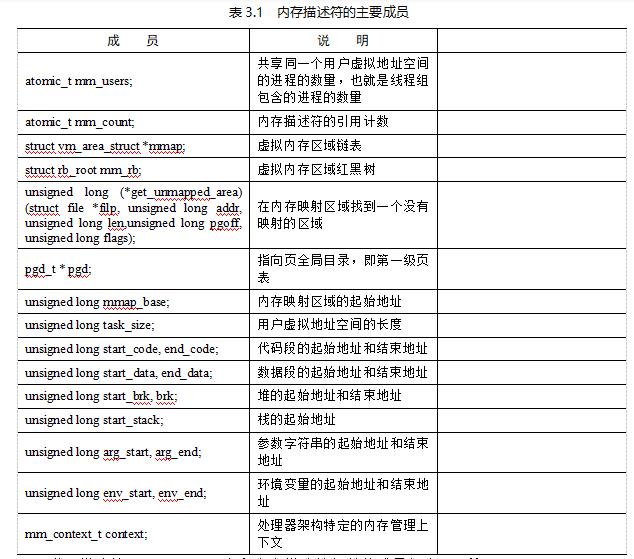
内核使用内存描述符mm_struct描述进程的用户虚拟地址空间,内存描述符的主要成员如表3.1所示。
表3.1 内存描述符的主要成员
|
进程描述符(task_struct)中和内存描述符相关的成员如表3.2所示。
表3.2 进程描述符中和内存描述符相关的成员
进程描述符的成员说 明struct mm_struct *mm;进程的mm指向一个内存描述符 内核线程没有用户虚拟地址空间,所以mm是空指针struct mm_struct *active_mm;进程的active_mm和mm总是指向同一个内存描述符 内核线程的active_mm在没有运行时是空指针,在运行时指向从上一个进程借用的内存描述符
如果进程不属于线程组,那么进程描述符和内存描述符的关系如图 3.3 所示,进程描述符的成员mm和active_mm都指向同一个内存描述符,内存描述符的成员mm_users是1、成员mm_count是1。
如果两个进程属于同一个线程组,那么进程描述符和内存描述符的关系如图3.4所示,每个进程的进程描述符的成员mm和active_mm都指向同一个内存描述符,内存描述符的成员mm_users是2、成员mm_count是1。
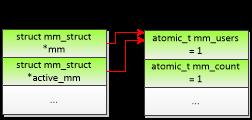
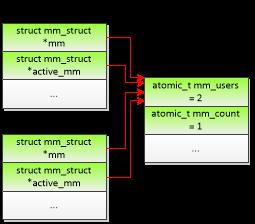
{:-:} 图3.3 进程的进程描述符和内存描述符的关系 图3.4 线程组的进程描述符和内存描述符的关系
内核线程的进程描述符和内存描述符的关系如图 3.5 所示,内核线程没有用户虚拟地址空间,当内核线程没有运行的时候,进程描述符的成员mm和active_mm都是空指针;当内核线程运行的时候,借用上一个进程的内存描述符,在被借用进程的用户虚拟地址空间的上方运行,进程描述符的成员active_mm指向借用的内存描述符,假设被借用的内存描述符所属的进程不属于线程组,那么内存描述符的成员mm_users不变,仍然是1,成员mm_count加1变成2。

图3.5 内核线程的进程描述符和内存描述符的关系
为了使缓冲区溢出攻击更加困难,内核支持为内存映射区域、栈和堆选择随机的起始地址。进程是否使用虚拟地址空间随机化的功能,由以下两个因素共同决定。
(1)进程描述符的成员personality(个性化)是否设置ADDR_NO_RANDOMIZE。
(2)全局变量randomize_va_space:0表示关闭虚拟地址空间随机化,1表示使内存映射区域和栈的起始地址随机化,2表示使内存映射区域、栈和堆的起始地址随机化。可以通过文件“
/proc/sys/kernel/randomize_va_space”修改。
mm/memory.c int randomize_va_space __read_mostly = #ifdef CONFIG_COMPAT_BRK 1; #else 2; #endif
为了使旧的应用程序(基于libc5)正常运行,默认打开配置宏CONFIG_COMPAT_BRK,禁止堆随机化。所以默认配置是使内存映射区域和栈的起始地址随机化。
栈通常自顶向下增长,当前只有惠普公司的PA-RISC处理器的栈是自底向上增长。栈的起始地址是STACK_TOP,默认启用栈随机化,需要把起始地址减去一个随机值。STACK_TOP是每种处理器架构自定义的宏,ARM64架构定义的STACK_TOP如下所示:如果是64位用户空间程序,STACK_TOP的值是TASK_SIZE_64;如果是32位用户空间程序,STACK_TOP的值是异常向量的基准地址0xFFFF0000。
arch/arm64/include/asm/processor.h #define STACK_TOP_MAX TASK_SIZE_64 #ifdef CONFIG_COMPAT /* 支持执行32位用户空间程序 */ #define AARCH32_VECTORS_BASE 0xffff0000 #define STACK_TOP (test_thread_flag(TIF_32BIT) ? \\ AARCH32_VECTORS_BASE : STACK_TOP_MAX) #else #define STACK_TOP STACK_TOP_MAX #endif /* CONFIG_COMPAT */
内存映射区域的起始地址是内存描述符的成员 mmap_base。如图 3.6 所示,用户虚拟地址空间有两种布局,区别是内存映射区域的起始位置和增长方向不同。
(1)传统布局:内存映射区域自底向上增长,起始地址是TASK_UNMAPPED_BASE,每种处理器架构都要定义这个宏,ARM64架构定义为 TASK_SIZE/4。默认启用内存映射区域随机化,需要把起始地址加上一个随机值。传统布局的缺点是堆的最大长度受到限制,在32位系统中影响比较大,但是在64位系统中这不是问题。
(2)新布局:内存映射区域自顶向下增长,起始地址是(STACK_TOP − 栈的最大长度 − 间隙)。默认启用内存映射区域随机化,需要把起始地址减去一个随机值。
当进程调用execve以装载ELF文件的时候,函数load_elf_binary将会创建进程的用户虚拟地址空间。函数load_elf_binary创建用户虚拟地址空间的过程如图3.7所示。
如果没有给进程描述符的成员personality设置标志位ADDR_NO_RANDOMIZE(该标志位表示禁止虚拟地址空间随机化),并且全局变量randomize_va_space是非零值,那么给进程设置标志PF_RANDOMIZE,允许虚拟地址空间随机化。
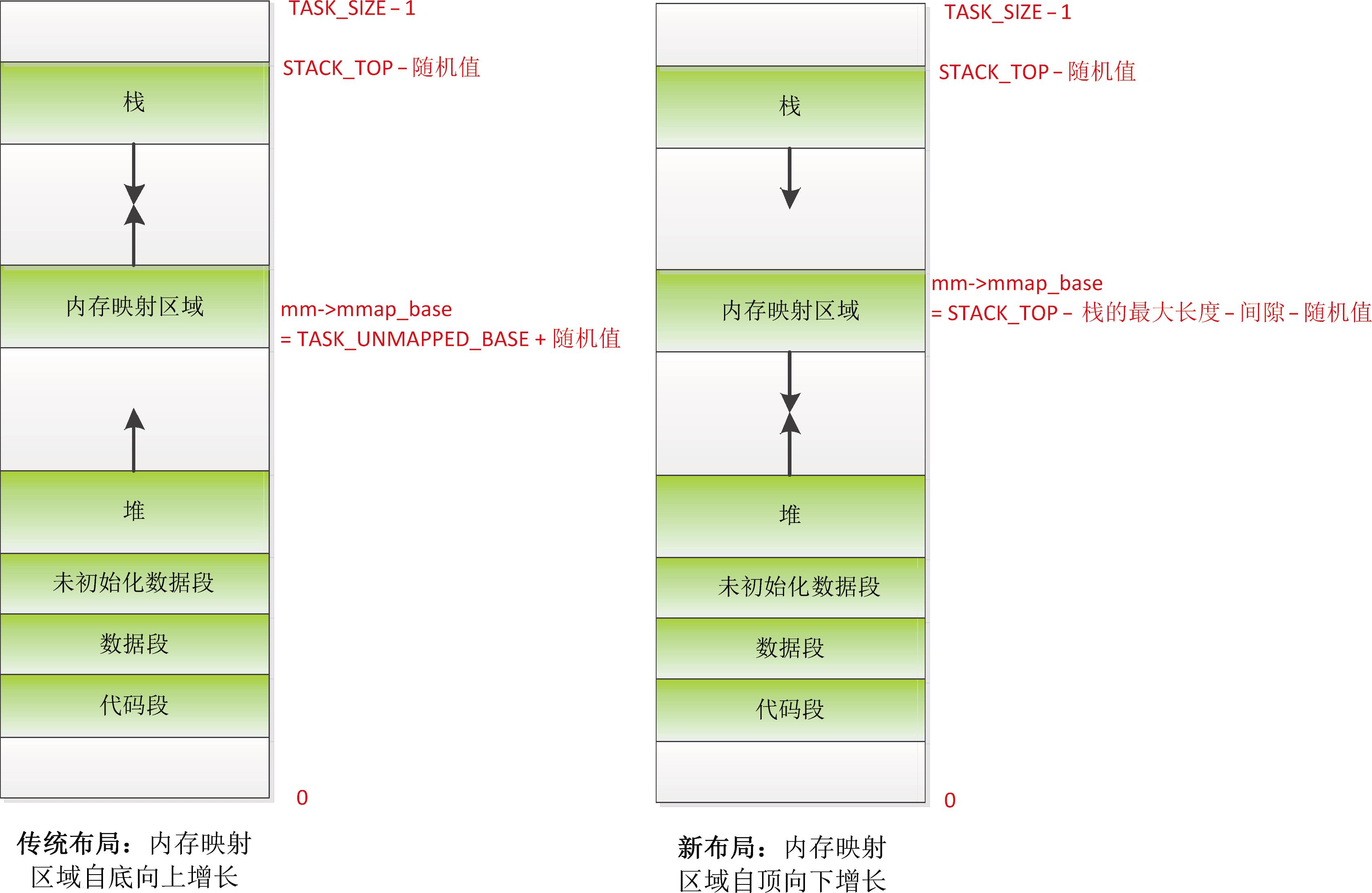
图3.6 用户虚拟地址空间的两种布局
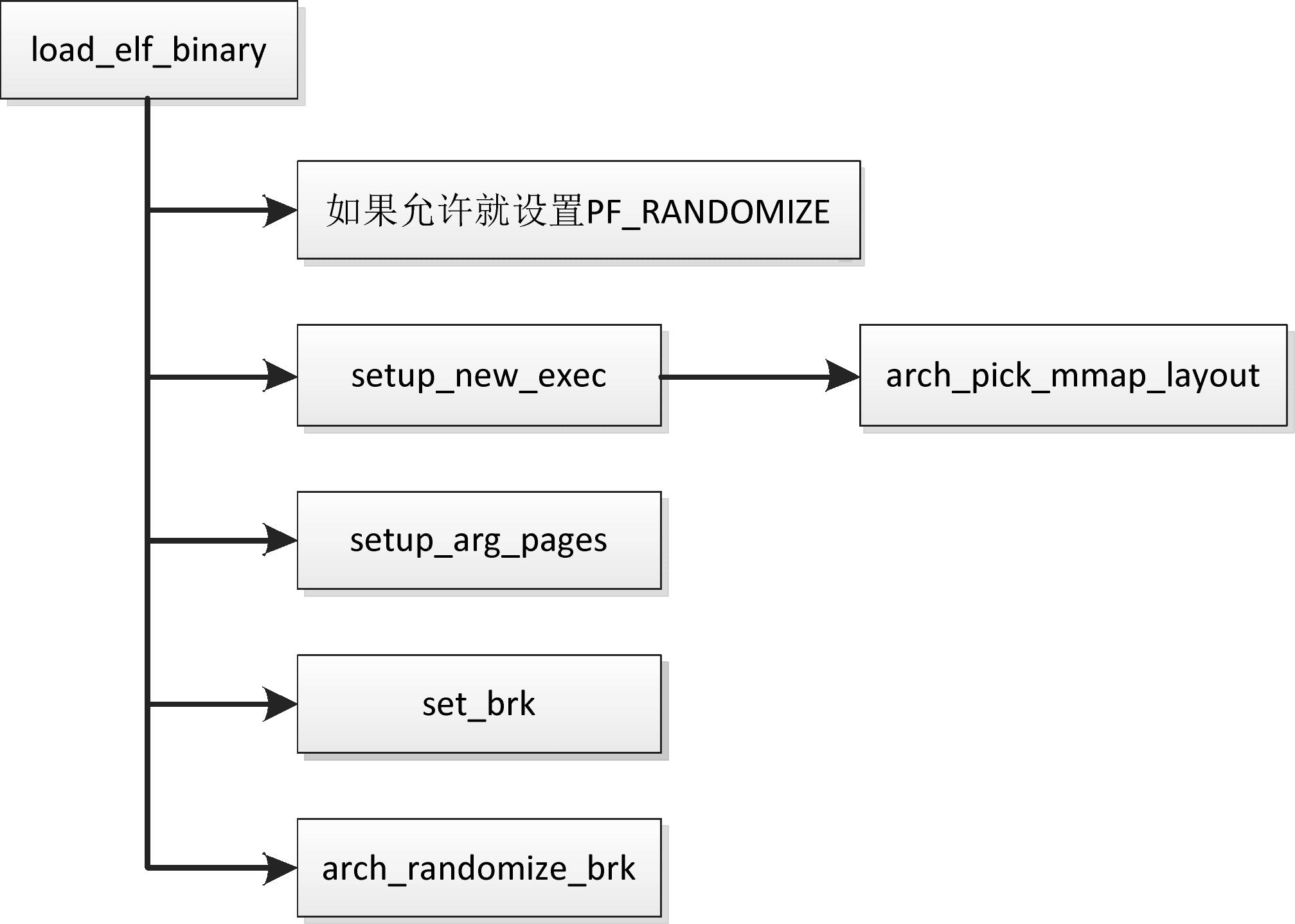
图3.7 装载ELF文件时创建虚拟地址空间
各种处理器架构自定义的函数arch_pick_mmap_layout负责选择内存映射区域的布局。ARM64架构定义的函数arch_pick_mmap_layout如下:
arch/arm64/mm/mmap.c
1 void arch_pick_mmap_layout(struct mm_struct *mm)
2 {
3 unsigned long random_factor = 0UL;
4
5 if (current->flags & PF_RANDOMIZE)
6 random_factor = arch_mmap_rnd();
7
8 if (mmap_is_legacy()) {
9 mm->mmap_base = TASK_UNMAPPED_BASE + random_factor;
10 mm->get_unmapped_area = arch_get_unmapped_area;
11 } else {
12 mm->mmap_base = mmap_base(random_factor);
13 mm->get_unmapped_area = arch_get_unmapped_area_topdown;
14 }
15 }
16
17 static int mmap_is_legacy(void)
18 {
19 if (current->personality & ADDR_COMPAT_LAYOUT)
20 return 1;
21
22 if (rlimit(RLIMIT_STACK) == RLIM_INFINITY)
23 return 1;
24
25 return sysctl_legacy_va_layout;
26 }
第8~10行代码,如果给进程描述符的成员personality设置标志位ADDRCOMPAT LAYOUT表示使用传统的虚拟地址空间布局,或者用户栈可以无限增长,或者通过文件“
/proc/sys/vm/legacy_va_layout”指定,那么使用传统的自底向上增长的布局,内存映射区域的起始地址是 TASK_UNMAPPED_BASE 加上随机值,分配未映射区域的函数是arch_get_unmapped_area。
第11~13行代码,如果使用自顶向下增长的布局,那么分配未映射区域的函数是arch_ get_unmapped_area_topdown,内存映射区域的起始地址的计算方法如下:
arch/arm64/include/asm/elf.h
#ifdef CONFIG_COMPAT
#define STACK_RND_MASK (test_thread_flag(TIF_32BIT) ? \\
0x7ff >> (PAGE_SHIFT - 12) : \\
0x3ffff >> (PAGE_SHIFT - 12))
#else
#define STACK_RND_MASK (0x3ffff >> (PAGE_SHIFT - 12))
#endif
arch/arm64/mm/mmap.c**
#define MIN_GAP (SZ_128M + ((STACK_RND_MASK << PAGE_SHIFT) + 1))
#define MAX_GAP (STACK_TOP/6*5)
static unsigned long mmap_base(unsigned long rnd)
{
unsigned long gap = rlimit(RLIMIT_STACK);
if (gap < MIN_GAP)
gap = MIN_GAP;
else if (gap > MAX_GAP)
gap = MAX_GAP;
return PAGE_ALIGN(STACK_TOP - gap - rnd);
}
先计算内存映射区域的起始地址和栈顶的间隙:初始值取用户栈的最大长度,限定不能小于“128MB + 栈的最大随机偏移值 + 1”,确保用户栈最大可以达到128MB;限定不能超过STACK_TOP的5/6。内存映射区域的起始地址等于“STACK_TOP−间隙−随机值”,然后向下对齐到页长度。
回到函数load_elf_binary:函数setup_arg_pages把栈顶设置为STACK_TOP减去随机值,然后把环境变量和参数从临时栈移到最终的用户栈;函数set_brk设置堆的起始地址,如果启用堆随机化,把堆的起始地址加上随机值。
fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
retval = setup_arg_pages
(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
retval = set_brk(elf_bss, elf_brk, bss_prot);
if ((current->flags & PF_RANDOMIZE) && (randomize_va_space > 1)) {
current->mm->brk = current->mm->start_brk =
arch_randomize_brk(current->mm);
}
}
3.2.3 内核地址空间布局
ARM64处理器架构的内核地址空间布局如图3.8所示。
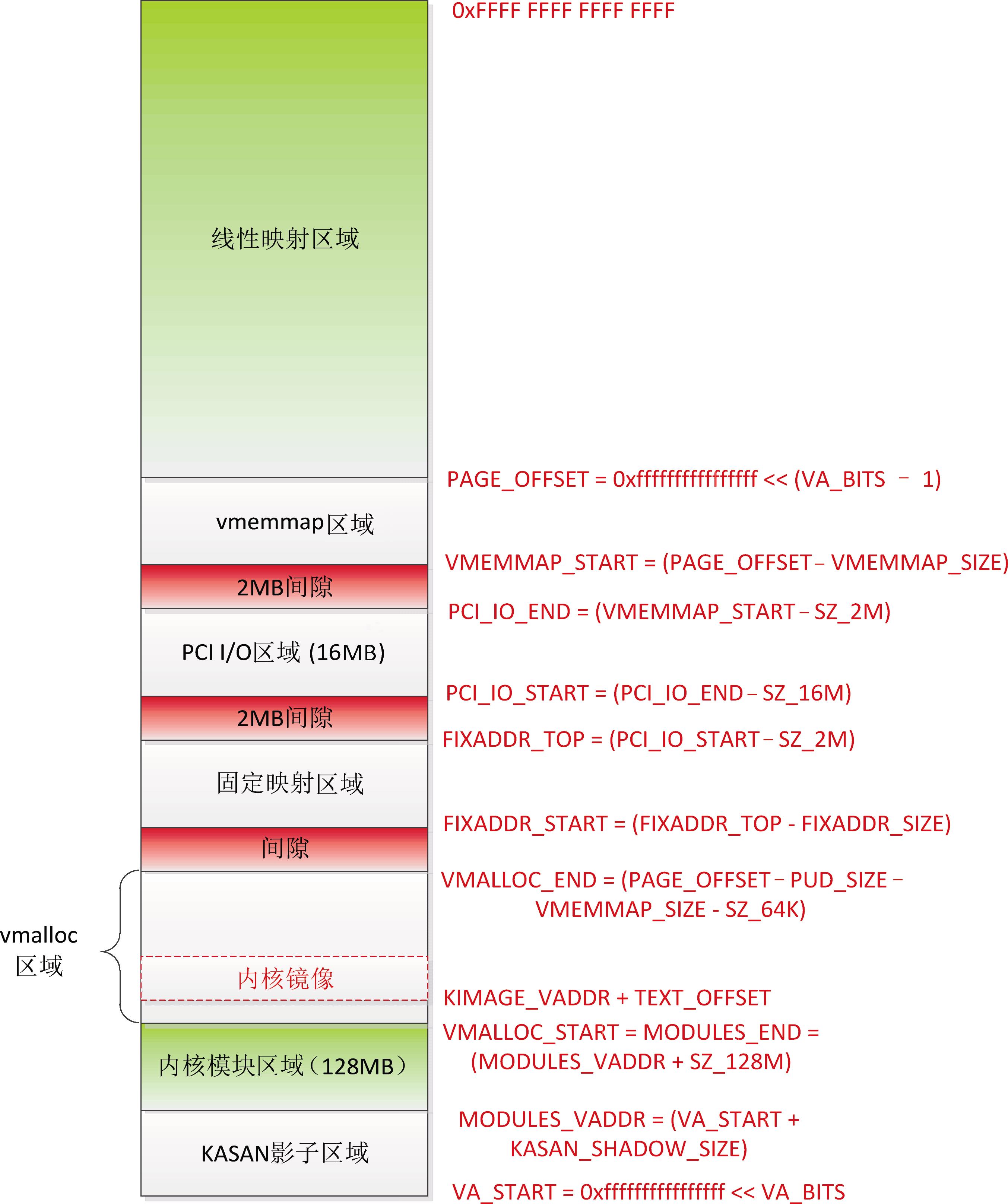
图3.8 ARM64架构的内核地址空间布局
(1)线性映射区域的范围是[PAGE_OFFSET, 264−1],起始位置是PAGE_OFFSET = (0xFFFF FFFF FFFF FFFF << (VA_BITS-1)),长度是内核虚拟地址空间的一半。称为线性映射区域的原因是虚拟地址和物理地址是线性关系:
虚拟地址 =((物理地址 − PHYS_OFFSET)+ PAGE_OFFSET),其中PHYS_OFFSET是内存的起始物理地址。
(2)vmemmap 区域的范围是[VMEMMAP_START, PAGE_OFFSET),长度是VMEMMAP_SIZE =(线性映射区域的长度 / 页长度 * page结构体的长度上限)。
内核使用page结构体描述一个物理页,内存的所有物理页对应一个page结构体数组。如果内存的物理地址空间不连续,存在很多空洞,称为稀疏内存。vmemmap区域是稀疏内存的page结构体数组的虚拟地址空间。
(3)PCI I/O区域的范围是[PCI_IO_START, PCI_IO_END),长度是16MB,结束地址是PCI_IO_END = (VMEMMAP_START − 2MB)。
外围组件互联(Peripheral Component Interconnect,PCI)是一种总线标准,PCI I/O区域是PCI设备的I/O地址空间。
(4)固定映射区域的范围是[FIXADDR_START, FIXADDR_TOP),长度是FIXADDR_SIZE,结束地址是FIXADDR_TOP = (PCI_IO_START − 2MB)。
固定地址是编译时的特殊虚拟地址,编译的时候是一个常量,在内核初始化的时候映射到物理地址。
(5) vmalloc区域的范围是[VMALLOCSTART, VMALLOC_END),起始地址是VMALLOC START,等于内核模块区域的结束地址,结束地址是VMALLOC_END = (PAGE_OFFSET − PUD_SIZE − VMEMMAP_SIZE − 64KB),其中PUD_SIZE是页上级目录表项映射的地址空间的长度。
vmalloc区域是函数vmalloc使用的虚拟地址空间,内核使用vmalloc分配虚拟地址连续但物理地址不连续的内存。
内核镜像在vmalloc区域,起始虚拟地址是(KIMAGE_VADDR + TEXT_OFFSET) ,其中KIMAGE_VADDR是内核镜像的虚拟地址的基准值,等于内核模块区域的结束地址MODULES_END;TEXT_OFFSET是内存中的内核镜像相对内存起始位置的偏移。
(6)内核模块区域的范围是[MODULES_VADDR, MODULES_END),长度是128MB,起始地址是MODULES_VADDR =(内核虚拟地址空间的起始地址 + KASAN影子区域的长度)。
内核模块区域是内核模块使用的虚拟地址空间。
(7)KASAN影子区域的起始地址是内核虚拟地址空间的起始地址,长度是内核虚拟地址空间长度的1/8。
内核地址消毒剂(Kernel Address SANitizer,KASAN)是一个动态的内存错误检查工具。它为发现释放后使用和越界访问这两类缺陷提供了快速和综合的解决方案。
本文摘自《Linux内核深度解析 》,作者: 余华兵

编辑推荐
- 基于ARM64架构的Linux 4.x内核
- 全面介绍内核引导、进程管理、内存管理、异常处理、互斥技术和文件系统等关键子系统的实现。
- 内核引导部分详解从处理器上电到用户空间的进程产生的整个过程,并介绍多处理器系统的启动过程。
- 结合源代码分析,详细解读每种技术的使用方法及其原理。
- 通过图例帮助读者理解各种数据结构之间的关系。
- 通过执行流程图帮助读者理解函数的执行过程。
- 对同类技术进行归纳总结和对比分析,例如3种块分配器、巨型页的两种实现、解决内存碎片问题的各种技术、3种中断下半部和3种RCU技术,等等。
以上是关于内存管理:虚拟地址空间布局的主要内容,如果未能解决你的问题,请参考以下文章