计算架构-量化方法 (粗译)连载5 Microsoft Catapult FPGA的探索
Posted 神铁哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算架构-量化方法 (粗译)连载5 Microsoft Catapult FPGA的探索相关的知识,希望对你有一定的参考价值。
T-opinion:软件走向云架构,硬件也在走向云架构,软件走向硬件,硬件也走向软件。目的只有一个,打造平台,提供特征化的,个性化的领域架构的算力能力。这是技术时代发展的特征,即DSA发展的一个趋势。
Google 跟随时代,微软也在其中。如果可以有一句话形容的话,就是I love FPGA。
Project Catapult应“云”而生,聚焦AI,押宝FPGA(Bing搜索结果排名吞吐量提升是一个用例),微软的目标通过现场可编程门阵列(FPGA)提高数据中心负载性能和能源效率;并且基于FPGA可编程能力绕开直接在芯片上蚀刻物理的逻辑门电路的需求,进一步通过软件解决硬件的需求,为云端的AI提供更加灵活和低成本的选择。
正文:
7.5 Microsoft Catapult, a Flexible Data Center Accelerator
7.5 Microsoft Catapult,灵活的数据中心加速器
在Google考虑在其数据中心部署自定义ASIC的同时,微软也在考虑为其加速器。 Microsoft的观点是,任何解决方案都必须遵循以下准则:
■它必须保持服务器的同质性,以便能够快速重新部署计算机,并避免使维护和调度变得更加复杂,即使该概念与DSA的概念有点矛盾。
■它必须扩展到可能需要比单个加速器所能容纳的资源更多的应用程序,而又不给所有应用程序增加多个加速器的负担。
■必须节能。
■成为单点故障不会成为可靠性问题。
■它必须适合现有服务器的可用备用空间和电源。
■它不会损害数据中心网络的性能或可靠性。
■加速器必须提高服务器的性价比。
第一条规则禁止部署仅帮助某些服务器上的某些应用程序的ASIC,这是Google做出的决定。
微软启动了一个名为Catapult的项目,该项目将PCIe总线板上的FPGA放置到数据中心服务器中。这些板卡具有专用网络,用于需要多个FPGA的应用。计划是利用FPGA的灵活性来针对不同服务器上的各种应用量身定制其用途,并对同一服务器进行重新编程以随着时间的推移加速不同的应用。该计划增加了加速器的投资回报。 FPGA的另一个优点是它们的NRE应该比ASIC低,这可以再次提高投资回报率。我们讨论了两代Catapult,展示了设计如何演变以满足WSC的需求。
FPGA的一个有趣方面是,每个应用程序-甚至应用程序的每个阶段-都可以被视为自己的DSA,因此在本节中,我们将看到在一个硬件平台上的许多新颖架构的示例。
Catapult Implementation and Architecture
Catapult的实现和架构
图7.19显示了Microsoft设计的适合其服务器的PCIe板,该板将功率和冷却限制为25W。这一限制导致选择了28nm的Altera Stratix V D5 FPGA来首次实现Catapult。
该板还具有32 MiB的闪存,并包括两组DDR3-1600 DRAM,总容量为8 GiB。 FPGA具有3926个18位ALU,5 MiB的片上存储器以及DDR3 DRAM的11 GB / s带宽。
图7.19Catapult板设计。
(A)显示了方框图,
(B)是电路板两面的照片,为10 cm_9 cm_16 mm。 PCIe和FPGA间FPGA网络连接到板底部的连接器,该连接器直接插入母板。
(C)是服务器的照片,高度为1U(4.45厘米),是标准机架宽度的一半。每个服务器都有两个12核Intel Sandy Bridge Xeon CPU,64 GiB DRAM,2个固态驱动器,4个硬盘驱动器和一个10 Gb以太网网卡。
(C)中右侧突出显示的矩形显示了Catapult FPGA板在服务器上的位置。冷空气从(C)处的左侧吸入,而热空气向右排出,并通过Catapult板。这个热点和连接器可以提供的功率意味着Catapult板限于25瓦。 48台服务器共享一个连接到数据中心网络的以太网交换机,它们占据数据中心机架的一半。
数据中心机架中一半的48台服务器中的每台都包含一个Catapult板。 Catapult遵循上述指导原则,即在不影响数据中心网络性能的情况下支持需要多个FPGA的应用程序。它增加了一个单独的低延迟20 Gbit / s网络,该网络连接48个FPGA。网络拓扑是二维6_8环形网络。
为了遵循关于不是单点故障的指导原则,即使其中一个FPGA出现故障,也可以将该网络重新配置为运行。该开发板还在FPGA外部的所有存储器上均具有SECDED保护,这对于在数据中心中进行大规模部署是必需的。
由于FPGA在芯片上使用大量内存来提供可编程性,因此它们比ASIC更容易遭受单事件翻转(SEU)的影响,因为随着工艺几何尺寸的缩小,它会产生辐射。 Catapult板上的Altera FPGA包括检测和纠正FPGA内部SEU的机制,并通过定期清除FPGA配置状态来减少SEU的机会。
与数据中心网络相比,单独的网络具有减少通信性能可变性的额外好处。网络的不可预测性增加了尾部等待时间,这对于面对最终用户的应用程序尤其有害,因此,单独的网络可以更轻松地将工作成功地从CPU卸载到加速器。该FPGA网络可以运行比数据中心更简单的协议,因为错误率大大降低,并且网络拓扑结构得到了很好的定义。
请注意,在重新配置FPGA时,必须特别注意弹性,以使其既不会出现故障的节点,也不会使主机服务器崩溃或破坏其邻居。 Microsoft开发了一种高级协议,以确保重新配置一个或多个FPGA时的安全性。
Catapult Software
Catapult软件
Catapult和TPU之间最大的区别可能是必须使用硬件描述语言(例如Verilog或VHDL)进行编程。正如Catapult作者所写(Putnam et al。,2016):
展望未来,FPGA在数据中心广泛采用的最大障碍可能是可编程性。 FPGA开发仍需要在寄存器传输级和手动调整方面进行大量的手工编码。
为了减轻对Catapult FPGA进行编程的负担,将寄存器传输级(RTL)代码分为shell和角色,如图7.20所示。shell程序代码类似于嵌入式CPU上的系统库。它包含RTL代码,这些代码将在同一FPGA板上的各个应用程序之间重复使用,例如数据封送,CPU到FPGA的通信,FPGA到FPGA的通信,数据移动,重新配置和健康监控。shellRTL代码占Altera FPGA的23%。角色代码是应用程序逻辑,由Catapult程序员使用剩余的77%的FPGA资源编写。拥有shell还具有在应用程序之间提供标准API和标准行为的额外好处。
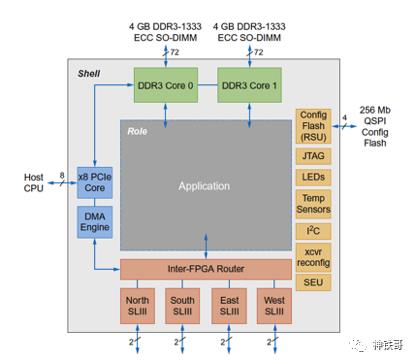
图7.20 Catapultshell的组件和RTL代码的角色拆分。
CNNs on Catapult
Catapult上的CNN
Microsoft开发了可配置的CNN加速器,作为Catapult的应用程序。配置参数包括神经网络层的数量,这些层的尺寸,甚至要使用的数值精度。 CNN加速器的框图如图7.21所示。其主要特点是:
■运行时可配置设计,无需使用FPGA工具重新编译。
■为了最大程度地减少内存访问,它提供了CNN数据结构的有效缓冲(请参见图7.21)。
■处理元素(PE)的二维数组,可以扩展到数千个单位。
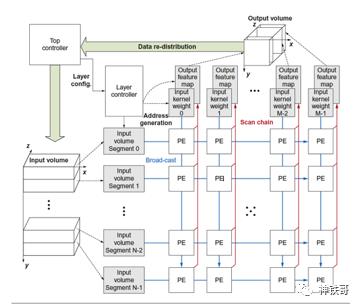
图7.21用于Catapult的CNN加速器。左侧的输入量对应于图7.20左侧的Layer [i_1],其中NumFM [i_1]对应于y,DimFM [i_1]对应于z。顶部的输出量映射到Layer [i],z映射到NumFM [i],DimFM [i]映射到x。下图显示了处理元素(PE)的内部。
图像被发送到DRAM,然后输入到FPGA中的多存储区缓冲器中。输入被发送到多个PE进行模版计算,从而生成输出特征图。控制器(图7.21左上方)协调到每个PE的数据流。然后将最终结果循环到输入缓冲区以计算CNN的下一层。
与TPU一样,PE被设计为用作脉动阵列。
PE设计的细节如图7.22所示。
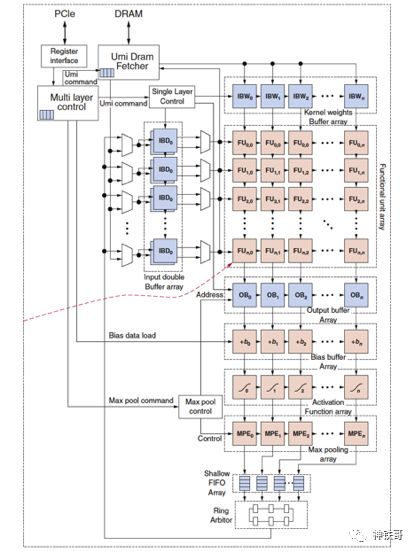
图7.22图7.21中用于Catapult的CNN加速器的处理元件(PE)。二维功能单元(FU)仅由一个ALU和几个寄存器组成。
Search Acceleration on Catapult
Catapult搜寻加速
测试Catapult的投资回报率的主要应用程序是Microsoft Bing搜索引擎的一项重要功能,即排名。它对搜索结果的顺序进行排序。输出是文档分数,它确定了呈现给用户的文档在网页上的位置。
该算法分为三个阶段:
1.特征提取基于搜索查询从文档中提取数千个有趣的特征,例如查询短语在文档中出现的频率。
2.自由格式表达式可以计算上一阶段的数千个特征组合。
3.机器学习评分系统使用机器学习算法来评估前两个阶段的功能,以计算返回给主机搜索软件的文档的浮点分数。
Catapult实现的排名与等效的Bing软件产生的结果相同,甚至重现已知的错误!利用上述准则之一,排名功能不必放在单个FPGA中。
以下是如何将排名阶段划分为八个FPGA:
■一个FPGA进行特征提取。
■两个FPGA执行自由格式表达式。
■一个FPGA进行压缩,以提高评分引擎的效率。
■三个FPGA做机器学习评分。
其余的FPGA备用来容忍故障。
由于专用的FPGA网络,对于一个应用程序使用多个FPGA效果很好。图7.23显示了功能提取阶段的组织。它使用43个特征提取状态机来对每个文档查询对并行计算4500个特征。接下来是下面的自由格式表达式阶段。
微软不是直接在Gate或状态机中实现这些功能,而是开发了一种60核处理器,该处理器通过多线程克服了长延迟操作。与GPU不同,Microsoft的处理器不需要执行SIMD。它具有三个使其可以满足延迟目标的功能:
1.每个内核支持四个同时线程,其中一个线程可以长时间运行而其他线程可以继续运行。
所有功能单元都是流水线,因此它们可以在每个时钟周期接受新的操作。
2.使用优先级编码器静态地对线程进行优先级排序。等待时间最长的表达式在所有内核上都使用线程插槽0,然后第二慢的是所有内核上的插槽1,依此类推。
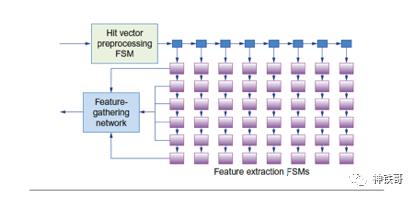
图7.23特征提取阶段的FPGA实现架构。将描述每个文档中查询词位置的命中向量流式传输到命中向量预处理状态机中,然后分为控制令牌和数据令牌。这些令牌与43个唯一功能状态机并行发布。特征收集网络收集生成的特征和值对,并将它们转发到以下“自由格式表达式”阶段。
3.太大的表达式无法容纳分配给单个FPGA的时间,可以在用于自由格式表达式的两个FPGA中进行拆分。 FPGA中可重编程性的一个成本是比定制芯片要慢的时钟速率。
机器学习计分使用两种形式的并行性来尝试克服该缺点。
第一个是拥有与应用程序中可用的管道并行性匹配的管道。对于排名,该限制为每级8μs。
并行的第二种形式是很少见的多个指令流,即单个数据流(MISD)并行,其中大量独立指令流在单个文档上并行操作。
图7.24显示了Catapult上排名功能的性能。正如我们将在7.9节中看到的那样,面向用户的应用程序通常具有严格的响应时间。如果应用程序错过了截止日期,那么吞吐量有多高无关紧要。 x轴显示响应时间限制,以1.0为截止值。在这种最大延迟下,Catapult的速度是主机英特尔服务器的1.95倍。Catapult第1版的部署在将整个仓库级计算机安装成千上万台服务器之前,Microsoft进行了17个完整机架的测试部署,其中包含17_48_2或1632个Intel服务器。 Catapult卡和网络链接在制造和系统集成时进行了测试,但是在部署时,有1632张卡中有7张发生故障(0.43%),而3264 FPGA网络链接之一(0.03%)有缺陷。经过几个月的部署,其他所有操作都没有失败。
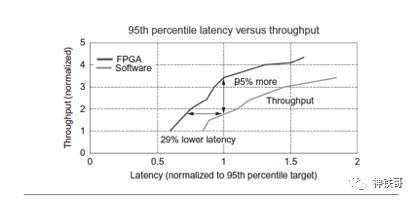
图7.24对于给定的延迟范围,Catapult上的排名功能的性能。 x轴显示Bing排名功能的响应时间。 x轴上Bing应用程序在第95个百分位数的最大响应时间是1.0,因此右侧的数据点可能具有更高的吞吐量,但到达时机太晚而无用。 y轴显示在给定响应时间内Catapult和纯软件上95%的吞吐量。在标准响应时间为1.0时,Catapult具有以纯软件模式运行的Intel服务器的吞吐量为1.95。换句话说,如果Catapult与Intel服务器在1.0标准化响应时间下的吞吐量相匹配,则Catapult的响应时间将减少29%。
Catapult Version 2
Catapult第2个版版
尽管测试部署成功完成,但Microsoft更改了实际部署的体系结构,以使Bing和Azure网络能够使用相同的板和体系结构(Caulfield et al,2016)。
V1体系结构的主要问题是独立的FPGA网络无法使FPGA查看和处理标准的Ethernet / IP数据包,从而阻止了FPGA用于加速数据中心网络基础设施。此外,电缆连接昂贵且复杂,仅限于48个FPGA,并且在某些故障模式期间重新路由流量会降低性能并可能隔离节点。
解决方案是将FPGA逻辑上放置在CPU和NIC之间,以便所有网络流量都通过FPGA。这种“在线连接”布局消除了Catapult V1中FPGA网络的许多弱点。此外,它使FPGA能够运行自己的低延迟网络协议,从而使它们可以被视为数据中心甚至整个数据中心中所有FPGA的全局池。
V1和V2之间发生了三处更改,以克服Catapult应用程序最初干扰数据中心网络流量的担忧。
首先,数据中心网络从10 Gbit / s升级到40 Gbit / s,增加了headroom。
其次,Catapult V2为FPGA逻辑添加了一个速率限制器,以确保FPGA应用程序不会淹没网络。
最终,也许是最重要的变化是,网络工程师现在可以在现场使用FPGA的情况下拥有自己的FPGA用例。这个特点将这些以前感兴趣的旁观者变成了热情的合作者。
通过在大多数新服务器中部署Catapult V2,Microsoft实质上拥有了第二台超级计算机,该超级计算机由分布式FPGA组成,该分布式FPGA与CPU服务器共享相同的网络线路,并且具有相同的规模,因为每个服务器只有一个FPGA。图7.25和7.26显示了Catapult V2的框图和电路板。
Catapult V2遵循RTL相同的shell和角色划分,以简化编程,但是在发布之时,该shell使用了将近一半的FPGA资源(44%),因为共享数据中心网络线的网络协议更加复杂。
Catapult V2用于等级加速和功能网络加速。在排名加速中,Microsoft并未执行FPGA中几乎所有的排名功能,而是仅实现了计算量最大的部分,其余部分留给了主机CPU:
■功能部件(FFU)是有限状态机的集合用来衡量搜索中的标准功能,例如计算特定搜索字词的频率。它在概念上与Catapult V1的特征提取阶段相似。
■动态编程功能(DPF)使用动态编程创建了Microsoft专有的一组功能,并且与Catapult V1的“自由格式表达式”阶段有些相似。两者的设计都使其可以将非本地FPGA用于这些任务,从而简化了调度。图7.27显示了Catapult V2与软件相比的性能,格式类似于图7.24。现在可以在不影响延迟的情况下将吞吐量提高到2.25倍,而以前的速度是1.95倍。当在生产中部署和评估排名时,Catapult V2的尾部等待时间比软件更好。也就是说,尽管可以吸收两倍的工作量,但在任何给定的需求下,FPGA的延迟都不会超过软件的延迟。
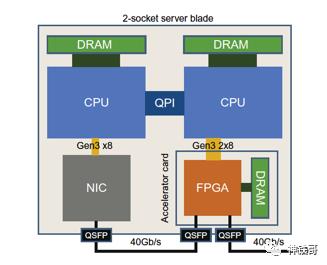
图7.25 Catapult V2框图。所有网络流量都通过FPGA路由到NIC。与Catapult V1中一样,CPU上还有一个PCIe连接器,该连接器允许将FPGA用作本地计算加速器。
图7.26 Catapult V2板使用PCIe插槽。它使用与Catapult V1相同的FPGA,TDP为32W。一块256 MB的闪存芯片保存着上电加载的FPGA的黄金映像以及一个应用程序映像。
Summary: How Catapult Follows the Guidelines
摘要:Catapult如何遵循指南
Microsoft报告说,在试验阶段将Catapult V1添加到服务器中,使总拥有成本(TCO)降低了不到30%。因此,对于此应用程序,排名的成本效益净收益至少为1.95 / 1.30,或约1.5的投资回报率。尽管未对Catapult V2的TCO做出任何评论,但该板具有相同数量的相同类型的芯片,因此我们可能会猜测TCO不会更高。如果是这样,Catapult V2的性价比大约为2.25 / 1.30,或排名为1.75。这是Catapult遵循7.2节指南的方式。
图7.27 Catapult V2上排名功能的性能与图7.24相同。请注意,此版本的尺寸为99%,而先前的数字为95%。
1. 使用专用存储器以最小化数据移动的距离。
Altera V FPGA的片上存储器具有5 MiB,应用可以对其进行定制以供其使用。例如,对于CNN,它用于图7.21的输入和输出特征图。
2. 将通过将高级微体系结构优化投入到更多的算术单元或更大的内存中而节省的资源进行投资。
Altera V FPGA还具有3926个针对该应用量身定制的18位ALU。对于CNN,它们用于创建驱动图7.22中的处理元素的脉动阵列,并且它们形成60核多处理器的数据路径,而该60核多处理器由“自由格式表达”排名阶段使用。
3. 使用最简单的与域匹配的并行形式。
Catapult选择与应用程序匹配的并行形式。例如,Catapult针对CNN应用程序使用二维SIMD并行性,并在“机器评分”阶段流排名中使用MISD并行性。
4. 将数据大小和类型减小到域所需的最简单类型。
Catapult可以使用应用程序所需的任何大小和数据类型,从8位整数到64位浮点。
5. 使用特定于域的编程语言将代码移植到DSA。
在这种情况下,编程是使用硬件寄存器传输语言(RTL)Verilog完成的,该语言比C or C ++的生产率更低。由于使用了FPGA,Microsoft没有(也可能没有)遵循该准则。尽管本指南涉及应用程序从软件到FPGA的一次性移植,但应用程序并未及时冻结。
按照定义,软件会不断发展以增加功能或修复错误,特别是对于与Web搜索一样重要的事情。维护成功的程序可能是软件开发的大部分费用。而且,在RTL中进行编程时,软件维护会更加繁重。像其他所有将FPGA用作加速器的开发人员一样,微软开发人员希望,针对特定领域的语言和软硬件协同设计系统的未来发展将减少对FPGA进行编程的难度。
以上是关于计算架构-量化方法 (粗译)连载5 Microsoft Catapult FPGA的探索的主要内容,如果未能解决你的问题,请参考以下文章