论文阅读|《基于加权Q学习算法的自适应车间调度策略》
Posted 码丽莲梦露
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读|《基于加权Q学习算法的自适应车间调度策略》相关的知识,希望对你有一定的参考价值。
《Adaptive job shop scheduling strategy based on weighted Q-learning algorithm》
Journal of Intelligent Maunfacturing/2020
1 摘要
问题:作业车间动态、不确定性
方法:提出一种包括机器、缓冲区、状态和工件的多Agent动态调度系统,采用基于聚类和动态搜索的加权Q学习算法来确定最合适的操作对生产进行优化。为解决系统状态变化带来的大状态空间问题,提出了4种状态特征,状态空间的范围缩小通过聚类来实现。
2 问题描述
问题:带交货期和有限缓冲区的JSP问题
目标:最小化提前和延迟惩罚
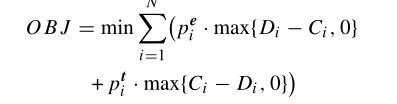
3 动态调度系统
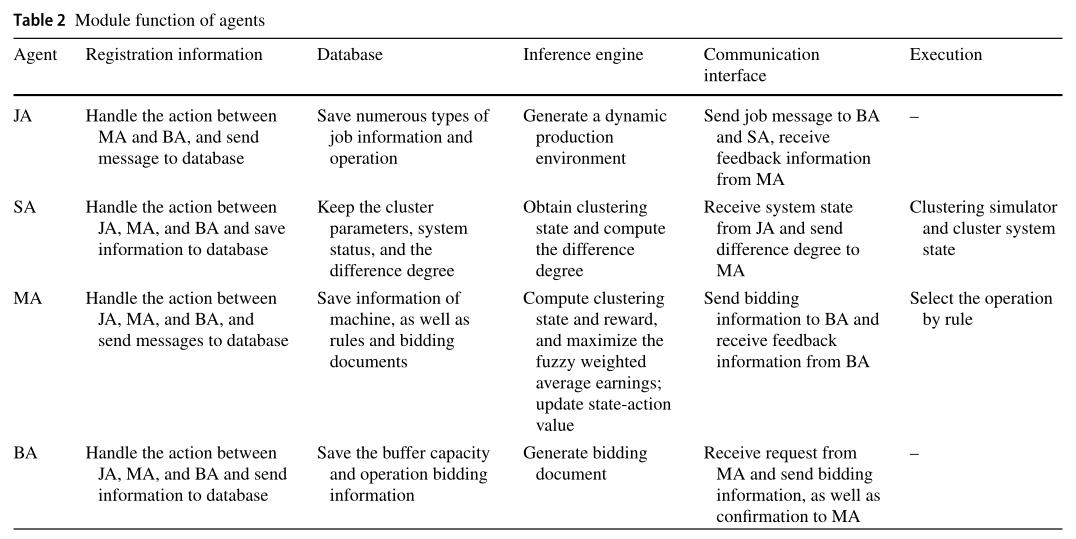
针对生产过程的复杂性和动态环境的不确定性,建立了基于多Agent的动态调度模型,如图1所示。该模型主要由以下几个部分组成:

JA:Job Agent
JA创建了人机交互界面。JA中包含某些信息,如作业编号、操作和处理时间。JA的内部结构包括数据库、注册信息模块、推理机和通信接口模块。
SA: State Agent
SA为系统状态。SA还包括数据库、注册信息模块、推理机、聚类模拟器和通信接口模块。
MA: Machine Agent
机器。动态调度在MA可用时间内通过招标方式进行。MA组件包括数据库、注册信息模块、推理机、执行模块和通信接口模块。
BA:Buffer Agent
缓冲区,存放待加工工件,并与MA交互。BA中封装了数据库、注册信息模块、推理机和通信接口模块。
详细如下:
4 基于WQ-CDS算法的自适应调度策略
状态差异度度量聚类与实际状态之间的距离。将系统状态-动作对替换为聚类状态-动作对,并将状态差异度作为Q学习函数迭代更新的权值,为提高算法的速度和精度,引入动态贪婪搜索策略。在建立的动态调度系统中,Agent通过通信接口与不断变化的生产环境进行交互,获得最优的Q函数值,然后选择最合适的中标文件。
4.1 Action Set
EDD(最早交货期)、SPT(最短加工时间)、FIFO(先进先出)、MST(最小松弛时间)
4.2 State Set
状态空间的维度为S={Pa,Fa,Lr,Um}:分别表示为:
Pa:Punishment of tardiness and earliness
Fa:the average delivery factor
![]()
Lr:the relative machine load
Um:the rate of machine utilization
4.2.1 State 聚类方法
根据系统状态的序列聚类方法得到K个簇,假设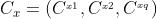 为x个聚类中心,x=1,2,...K,q为特征维度。
为x个聚类中心,x=1,2,...K,q为特征维度。
定义1 状态St和聚类状态Cx的Manhattan距离:

St和Cx的差异度可以定义为:

定义2 对任意St(C) 都有
![]()
于是St(C)为状态St.
4.3 更新Q函数
原来的Q函数:
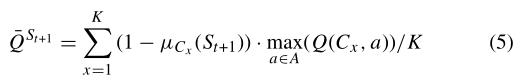
这篇文章改进为:
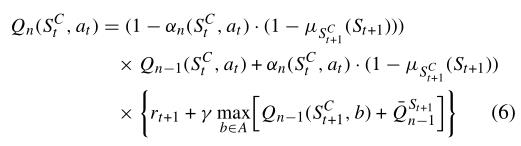

4.4 奖励函数的设计
本文的目标是使提前-拖期惩罚最小,而WQ_CDS算法为收敛到最大。为了保持最小化目标和最大Q函数的优化方向一致,采用了启发式即时奖励函数的原理。通过算法研究,系统给出了启发式即时奖励,并引导学习算法实现最优策略的更快收敛。因此,即时奖励函数设计如下:

其中:
![]()
![]()
Q-学习算法中的动作搜索通常采用ε贪婪搜索策略,其中ε表示知识搜索和利用的概率。在系统状态ST下,选择评价函数值最大的动作(“利用”)的概率为(1−ε),概率ε随机选择其他动作(“探索”)。ε的选择会影响搜索效果。根据效果,学习算法在第一阶段主要对知识进行“探索”。随着学习和经验的积累,知识的“利用率”逐渐提高,“探索性”逐渐降低。因此,ε应该随着学习过程而逐渐降低。针对上述分析,提出了基于学习时间n的动态贪婪策略:

其中,n是当前学习时间,na是学习周期总数,ξ是搜索幅度,0.95≤ξ<1,δ0是避免无意义边界值δ0∈(0,(1−ξ)na)的极限调整系数。在学习之初,ε(N)≈1只表示“探索”,没有表示“利用”。随着学习时间的增加,“利用”增加,“探索”减少。当n接近NA时,ε(N)≈0在学习过程中几乎只表示“利用”而不表示“探索”。在搜索过程中,ε(N)随时间的变化是一个从知识“探索”到“利用”的短暂过程。与传统的ε贪婪策略相比,动态贪婪策略更加智能,从而在学习过程中进行动态调整。动态贪婪策略可以同时避免盲目搜索,提高搜索效率。
以上是关于论文阅读|《基于加权Q学习算法的自适应车间调度策略》的主要内容,如果未能解决你的问题,请参考以下文章