04. Redis 核心原理
Posted IT BOY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了04. Redis 核心原理相关的知识,希望对你有一定的参考价值。
目录
06 Redis 核心原理
Pt1 线程模型
Pt1.1 Redis高性能
Redis到底有多快,我们可以使用Redis自带的benchmark脚本测试一下:
[root@VM-0-17-centos ~]# docker exec single-redis redis-benchmark -t set,lpush -n 100000 -q
SET: 29188.56 requests per second
LPUSH: 29351.33 requests per second
[root@VM-0-17-centos ~]# docker exec single-redis redis-benchmark -t set,lpush -n 100000 -q
SET: 28885.04 requests per second
LPUSH: 28481.91 requests per second好像没有官方说的那么高的性能,按照官方的说法,Redis现在的性能大概是在每秒13万左右。可能是我这个虚节点配置不够好,我这个云服务器节点只有1核2G1M带宽的配置。
高性能是Redis作为缓存的基础,高可用是Redis流行的原因。Redis性能非常高的原因主要有以下几点:
-
内存存储:Redis是使用内存(in-memeroy)存储,没有磁盘IO上的开销,在存储上有很大优势;
-
单线程实现:Redis使用单个线程处理请求,避免了多个线程之间线程切换和锁资源争用的开销;
-
优化的数据结构:Redis有诸多可以直接应用的优化数据结构的实现,应用层可以直接使用原生的数据结构提升性能,比如ziplist,quicklist,skiplist等。
-
非阻塞IO:Redis使用多路复用IO技术,在poll,epool,kqueue选择最优IO实现。
我们重点说明IO多路复用。
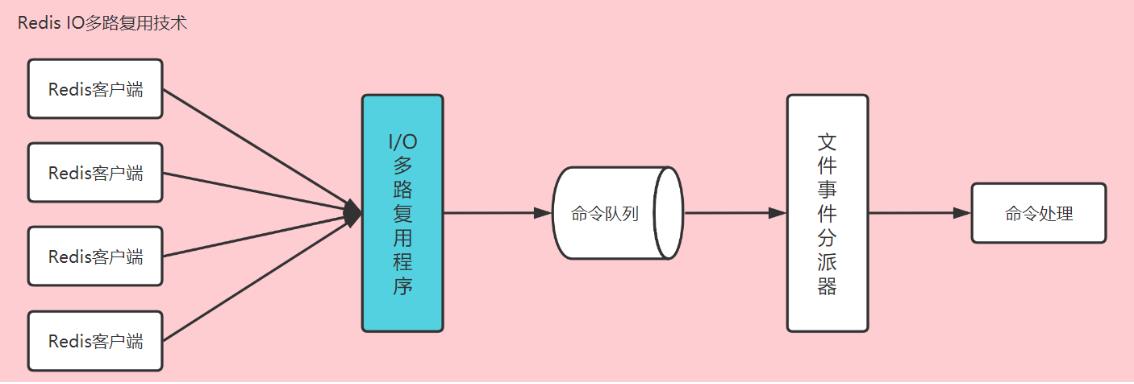
Pt1.2 IO多路复用
客户端发送命令时,会先通过Socket建立与服务端的TCP连接,然后服务端建立线程处理Socket IO。在高并发场景下,大量的客户端请求需要服务端产生大量的IO线程来处理,导致CPU性能下降。IO多路复用技术很好的解决了这个问题。
什么是I/O多路复用模型呢?I/O指网络I/O,多路指多个客户端的TCP连接,复用指共用一个线程或进程来处理,就是说在服务端复用同一个线程/进程来处理多个客户端网络I/O,降低线程开销。
Pt2 内存回收
Pt2.1 过期回收策略
对于设置了过期时间的key,redis有两种回收策略:
-
惰性过期(被动淘汰):当访问key时才会判断key是否已过期,过期则清除。该策略可以最大化节省CPU资源,但是对内存却不友好,可能会有很多过期的key不会再次被访问导致不会被动清除;
-
定期过期(主动扫描):Redis每隔10秒会执行一次主动扫描:[1.获取随机的20个keys进行相关过期检测。2. 删除所有已经过期的keys。3.如果有多于25%的keys过期,重复步奏1.]
Pt2.2 淘汰策略
除了过期清除外,还有一种场景就是redis的key并没有设置过期时间,随着时间推移,内存主键不够用了,Redis有如下策略来执行数据淘汰:
-
allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够内存位置。
-
volatile-lru:根据LRU算法删除设置了超时属性的键值。如果没有则退回到noeviction。
-
allkeys-lfu:在所有键中选择最不常用的,不管数据有没有设置超时属性。
-
volatile-lfu:在带有过期时间的键中选择最不常用的。
-
allkeys-random:随机删除所有键,直到腾出足够内存位置;
-
volatile-random:在带有过期时间的键中随机选择。
-
volatile-ttl:根据KV的ttl属性,删除最近将要过期数据。如果没有,回退到noeviction策略。
-
noeviction:默认策略,不会删除任何数据,拒绝所有写入操作并返回客户端OOM,此时Redis只响应读操作。
Pt3 数据持久化
对于缓存这类基于内存的存储来说,最怕的就是数据丢失。Redis基于内存处理速度很快,但是如果断电或者宕机时都会导致内存中的数据丢失。为了解决这个问题,Redis提供了两种数据持久化方案,一种是RDB快照(Redis DataBase),一种是AOF(Append Only File)。
Pt3.1 RDB
RDB是Redis默认持久化方案,当满足条件时,会把当前内存中的数据写入磁盘,生成一个快照文件dump.rdb,Redis重启会通过加载dump.rdb文件恢复数据。
(1) 自动触发RDB存储
在redis.conf中可以配置触发RDF存储的执行频率。如果不需要rdb方案,注释save行或者配置成空字符串""即可。
294 # In the example below the behavior will be to save:
295 # after 900 sec (15 min) if at least 1 key changed
296 # after 300 sec (5 min) if at least 10 keys changed
297 # after 60 sec if at least 10000 keys changed
298 #
299 # Note: you can disable saving completely by commenting out all "save" lines.
300 #
301 # It is also possible to remove all the previously configured save
302 # points by adding a save directive with a single empty string argument
303 # like in the following example:
304 #
305 # save ""
306
307 save 900 1 # 900秒内至少有一个key被修改(包括添加)
308 save 300 10 # 300秒内至少有10个key被修改(包括添加)
309 save 60 10000 # 60秒内至少有10000个key被修改(包括添加)上面3种配置并不冲突,通过阶梯式的频率设计,只要满足任意条件都会触发。使用lastsave命令可以查看最近一次成功生成快照的时间。
127.0.0.1:6379> lastsave
(integer) 1608589797在redis.conf文件中,配置了RDB文件的生成信息。
357 # 文件存放路径:rdb默认在启动目录下(相对路径),config get dir可以获取路径
365 dir ./
341 # 文件名称
342 dbfilename dump.rdb
326 # 是否以LZF压缩rdb文件:开启压缩可以节省存储空间,但是会消耗一些CPU的计算时间,默认开启
330 rdbcompression yes
332 # 开启rdb校验:使用CRC64算法来进行数据校验,但是会增加10%的性能消耗,关闭此功能可以提升性能
339 rdbchecksum yesRedis服务器正常关闭时也会触发RDB Save,如果是异常宕机则不会触发,所以会丢失最后一次rdb到宕机时这段时间的数据。flushall执行也会触发rdb save,其实是用空数据覆盖rdb文件,生成的dump.rdb也是空文件。
(2) 手动触发RDB存储
如果我们需要重启服务,备份数据或者迁移数据时,需要手动触发RDB快照,Redis提供两条命令来触发。
-
save:save在生成快照时会阻塞当前Redis服务器,Redis将不能处理其他正常命令。如果内存中数据比较多,rdb save时间比较长,会造成Redis长时间堵塞。
-
bgsave:执行bgsave时Redis会在后台异步进行快照操作,同时还可以响应客户端请求。当执行bgsave时,Redis进程会执行fork操作创建子进程(copy-on-write),rdb save过程由子进程负责处理,完成后自动结束,他不会记录fork之后产生的数据。阻塞只会发生在fork子线程的阶段,时间很短。
(3) RDB文件的优缺点
优势:
-
RDB文件内容紧凑,保存了Redis在某个时间点上的数据集,适合备份和灾难恢复;
-
通过fork子进程来处理所有快照工作,主进程不需要参与任何磁盘IO操作,只是在fork子进程的过程中有短暂的性能消耗,生成文件过程不影响主进程;
-
RDB在大数据集恢复速度较快,比AOF速度快;
劣势:
-
通过刚才的配置可以看出,RDB是间隔时间备份数据,不能实时/秒级持久化,宕机可能丢失数据(至于丢多少要看执行频率);
-
每次主进程fork子进程会有性能损耗,执行太过频繁成本高;
(4) RDB数据恢复
场景一:查看此时数据,然后关闭服务器
127.0.0.1:6379> keys *
1) "age"
2) "name"然后再重启服务器,查看数据正常:
[root@VM-0-17-centos redis]# docker stop single-redis
single-redis
[root@VM-0-17-centos redis]# docker start single-redis
single-redis
[root@VM-0-17-centos redis]# ./redisCli.sh
127.0.0.1:6379> keys *
1) "name"
2) "age"场景二:异常宕机
备份rdb文件:
[root@VM-0-17-centos data]# cp dump.rdb dump.rdb.bak
[root@VM-0-17-centos data]# ll
total 228
-rw-r--r-- 1 polkitd root 113086 Dec 23 13:42 appendonly.aof
-rw-r--r-- 1 polkitd input 93627 Dec 23 11:14 appendonly.aof.aaa
-rw-r--r-- 1 polkitd input 439 Dec 23 11:24 backup.db
-rw-r--r-- 1 polkitd input 92 Dec 23 13:43 dump.rdb
-rw-r--r-- 1 root root 92 Dec 23 13:45 dump.rdb.bak
-rw-r--r-- 1 polkitd input 92 Dec 23 11:24 root
-rw-r--r-- 1 polkitd input 291 Dec 23 11:24 zzh模拟异常宕机,数据丢失:
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> keys *
(empty array)关机服务器,使用备份的rdb文件覆盖,然后重启服务器:
127.0.0.1:6379> keys *
1) "name"
2) "age"测试此功能时,需要关闭AOF,否则数据会从AOF加载。
Pt3.2 AOF
AOF默认不开启,如果开启了AOF,会优先使用AOF。
(1) AOF数据持久化
AOF采用日志形式记录每个写操作,并追加到文件中,开启后,执行更改Redis命令的数据时,会把命令写入到AOF文件中,和binlog很像。Redis重启时会根据日志文件的内容把执行从前到后执行一次以完成数据的恢复工作。
在redis.conf中可以配置AOF:
1088 # Redis默认只开启RDB持久化,开启AOF需要修改为yes
1089 appendonly no
1091 # 文件名称:路径也是通过dir参数配置, 可以使用config get dir查看
1093 appendfilename "appendonly.aof"
1118 AOF持久化策略(硬盘缓存到磁盘)
1119 appendfsync everysecAOF开启后,数据并不是直接写入磁盘,而是先写入硬盘缓存再根据策略持久化到磁盘中。主要有3中持久化策略:
-
no表示不执行fsync,由操作系统保证数据同步到磁盘
-
always表示每次写入都执行fsync,以保证数据同步到磁盘
-
everysec(默认)表示每秒执行一次fsync,可能会导致丢失这1s数据
(2) AOF文件重写
AOF持久化是Redis不断将命令写入AOF文件中,像记录日志文件一样,随着纪录不断增加,AOF文件会越来越大,占用服务器内存也会越来越大,而且会导致数据恢复时间很长。比如我们有个计数器,incr100万次后变成了100万,产生了100万个命令的记录,但是最终结果只有一个,count = 100w。在数据恢复的时候,重新执行100w次命令好像也不是个非常合理的方式。
为了解决这个问题,Redis增加了重写机制,当AOF文件的大小超过所设定的阈值时,Redis启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集。比如解决上面计数器的问题,AOF文件不会对源文件的100w条命令集进行重新整理,而是直接读取服务器现有的键值对,然后用一条命令去替代之前所有的键值对(保证结果集一致),生成新的AOF文件替换原有文件。AOF重写也是fork子进程来完成的。
Redis会用命令bgrewriteaof来重新AOF文件,有两种触发机制:
# 当前AOF文件大小是上次日志重写得到AOF文件大小的两倍(默认100)时,自动启动AOF重写。比例默认值100,可以修改。
# 当AOF文件增长到一定大小时,Redis调用bgrewriteaof对日志文件进行重写。
auto-aof-rewrite-percentage 100
# 设置允许重写的最小AOF文件大小,避免达到了约定百分比但是文件大小依然很小的情况还要频繁的重写。
auto-aof-rewrite-min-size 64mb但是文件再重写的过程中,键值可能会被修改,这时候如何处理并发的情况呢?
通过双写来保证,如下图所示:
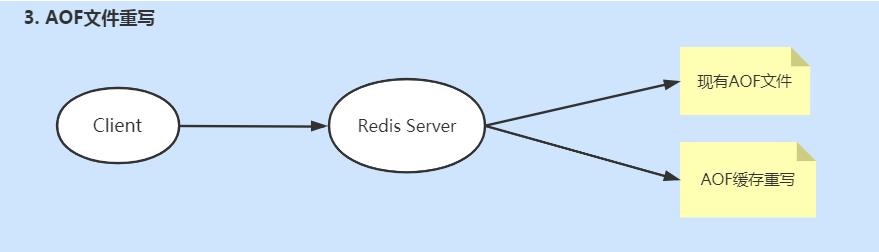
当子进程在执行AOF重写时,主进程会执行一下三个操作:
-
处理命令请求;
-
将命令追加到现有AOF文件中;
-
将命令追加到AOF重写缓存中,实现命令重新后还会执行新的命令完成数据更新;
还有两个与AOF密切相关的参数:
-
no-appendfsync-on-rewrite:AOF重写和RDB写入的时候,会执行大量的IO,会导致AOF的everysec和always模式执行fsync阻塞,当设置为yes表示rewrite期间对新写操作不fsync,暂存在内存中,等rewrite结束在写入,但是如果此时发生宕机,这段时间的数据都会丢失。默认是no,建议修改为yes。Linux默认的fsync策略是30秒,可能丢失30秒数据。
-
aof-load-truncated:当Redis所在主机发生系统宕机可能导致AOF文件不完整,比如ext4文件系统没有加上data=ordered选项等。当Redis重新启动的时候,如果选择是,当截断文件被导入的时候会自动发布一个log给客户端然后load;如果是no,用户必须手动redis-check-aof修复AOF文件才可以。默认yes。
(3) AOF恢复案例
简单模拟一个Redis故障恢复的场景。
查看当前存储的数据:
127.0.0.1:6379> keys *
1) "hobby"
2) "age"
3) "name"
127.0.0.1:6379>到服务器上人工备份aof文件
[root@VM-0-17-centos data]# cp appendonly.aof appendonly.aof.bak
[root@VM-0-17-centos data]# ll
total 204
-rw-r--r-- 1 polkitd input 93610 Dec 23 11:11 appendonly.aof
-rw-r--r-- 1 root root 93610 Dec 23 11:13 appendonly.aof.bak # 备份文件
-rw-r--r-- 1 polkitd input 454 Dec 22 06:29 backup.db
-rw-r--r-- 1 polkitd input 169 Dec 21 22:09 dump.rdb
-rw-r--r-- 1 polkitd input 454 Dec 22 06:29 root
-rw-r--r-- 1 polkitd input 454 Dec 22 06:29 zzh执行flushdb清除所有数据模拟故障发生:
[root@VM-0-17-centos redis]# ./redisCli.sh
127.0.0.1:6379> flushdb
OK关闭redis服务器,发现appendonly.aof变大了,但是执行命令时已经没有数据了:
[root@VM-0-17-centos data]# ll
total 204
-rw-r--r-- 1 polkitd input 93627 Dec 23 11:14 appendonly.aof
-rw-r--r-- 1 root root 93610 Dec 23 11:13 appendonly.aof.bak
-rw-r--r-- 1 polkitd input 454 Dec 22 06:29 backup.db
-rw-r--r-- 1 polkitd input 169 Dec 21 22:09 dump.rdb
-rw-r--r-- 1 polkitd input 454 Dec 22 06:29 root
-rw-r--r-- 1 polkitd input 454 Dec 22 06:29 zzh
127.0.0.1:6379> get name
(nil)我们使用备份的.bak文件替换原来aof文件,重启redis:
127.0.0.1:6379> keys *
1) "age"
2) "hobby"
3) "name"数据又恢复了。
(4) AOF优缺点
优势:
-
AOF持久化提供了多种同步频率,即使使用默认的同步频率每秒同步一次,Redis异常时最多也就丢失1秒的数据。
劣势:
-
AOF文件通常会比RDB文件体积更大,因为RDB存的是数据快照,而AOF存的是数据的操作命令。
-
在高并发情况下,RDB比AOF有更好的性能,因为RDB是通过子进程处理,AOF则需要主线程来处理,并且是持续的处理命令。
Pt3.3 RDB Vs AOF
如果可以忍受一小段时间内的数据丢失,使用RDB是最好的,定时生成快照非常便于进行数据库备份,并且RDB恢复速度要比AOF快很多。
如果无法忍受数据丢失,则需要使用AOF重写。一般情况下建议不要单独使用某一种持久化机制,如果两种同时开启,Redis重启时会优先加载AOF文件来恢复原始数据,因为通常情况下AOF的数据集要比RDB文件更完整。
以上是关于04. Redis 核心原理的主要内容,如果未能解决你的问题,请参考以下文章