人人皆可二次元!小姐姐生成不同风格动漫形象,肤色发型皆可变
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人人皆可二次元!小姐姐生成不同风格动漫形象,肤色发型皆可变相关的知识,希望对你有一定的参考价值。
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
编辑 | 杜伟、陈萍 来源 | 机器之心
一张输入人脸图像,竟能生成多样化风格的动漫形象。伊利诺伊大学香槟分校的研究者做到了,他们提出的全新 GAN 迁移方法实现了「一对多」的生成效果。
在 GAN 迁移领域,研究人员可以构建一个以人脸图像为输入并输出人脸动漫形象的映射。相关的研究方法已经出现了很多,如腾讯微视此前推出的迪士尼童话脸特效等等。
在迁移过程中,图像的内容(content)部分可能会被保留,但风格(style)部分必须改变,这是因为同一张脸在动画中能以多种不同的方式表示。这意味着:迁移过程是一个一对多的映射,该映射可以表示为一个函数,用于接受内容代码(即从人脸图像中恢复)和风格代码(这是一种潜变量)并生成动漫脸。但是,一些重要的限制条件必须遵守。
首先是控制(control):通过改变输入人脸来改变动漫人脸的内容(如动漫人脸应该随着输入人脸的转头而转头);
其次是一致性(consistency):使用相同潜变量渲染成动漫的真实人脸应在风格上高度匹配(如不改变潜变量的前提下,动漫人脸不会随输入人脸的转头而改变风格);
最后是覆盖范围(coverage):每个动漫人脸都可以使用内容和风格的组合来获取,这样就可以利用所有可能的动漫形象。
在近日的一项研究中,来自伊利诺伊大学香槟分校的研究者提出了一种新的 GAN 迁移方法 GANs N’ Roses(简写为 GNR),这一多模态框架使用风格和内容对映射进行直接的形式化(formalization)。简单来讲,研究者展示了一种以人脸图像的内容代码为输入并输出具有多种随机选择风格代码的动漫形象。

论文地址:https://arxiv.org/pdf/2106.06561.pdf
GitHub 项目地址:https://github.com/mchong6/GANsNRoses
从技术上来讲,研究者基于对内容与风格的简单和有效定义中得出了对抗性损失,它保证了映射的多样性,即可以从单一内容代码中生成多样化风格的动漫形象。在合理的假设下,这种映射不仅多样化,还能以输入人脸为条件正确地表示动漫形象的概率。相比之下,当前的多模态生成方法无法捕捉动漫中的风格。大量的定量实验表明,与 SOTA 方法相比,GNR 方法可以生成更多样风格的动漫形象。
GNR 的生成效果怎么样呢?我们可以先来看下 demo 图像戴珍珠耳环的少女的动漫形象:

目前,用户也可以试玩,只需上传自己的图像即可一键生成自己的动漫形象。机器之心用葡萄牙球星 C 罗的图片试了试生成效果,em……:

试玩地址:https://gradio.app/hub/AK391/GANsNRoses
与此同时,在没有对视频进行任何训练的情况下,GNR 方法还可以实现视频到视频的迁移。

技术实现
给定两个域 、
、
 ,目标是在
,目标是在 域中生成一组不同的
域中生成一组不同的 ,使其具有与 x 相似的语义内容。该研究详细阐述了从域
,使其具有与 x 相似的语义内容。该研究详细阐述了从域 到
到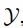 的转换细节。如图 2 所示,GANs N’ Roses 由一个编码器 E 和一个解码器 F 组成,这两个编码器可用于
的转换细节。如图 2 所示,GANs N’ Roses 由一个编码器 E 和一个解码器 F 组成,这两个编码器可用于 这两个方向。编码器 E 将图像 x 分解为内容编码 c(x) 和风格编码 s(x)。解码器 F 接收内容编码和风格编码,并从
这两个方向。编码器 E 将图像 x 分解为内容编码 c(x) 和风格编码 s(x)。解码器 F 接收内容编码和风格编码,并从 生成合适的图像。
生成合适的图像。
编码器和解码器共同形成了一个生成器。在运行时,通过向编码器传递图像来使用这个生成器,以保留生成的内容编码 c(x),获得一些其他相关的风格编码 s_z,然后将这对编码传递给解码器。该研究希望最终动漫内容由内容代编码控制,风格由风格编码控制。

图 2 GANs N’ Roses
但什么是内容,什么是风格?GANs N'Rose 的核心思想是将内容定义为事物所在的位置,将风格定义为事物的外观。这可以通过使用数据增强的思想来实现。选择一组相关的数据增强,在所有条件下:风格是不变的,内容是可变的。注意,这个定义是以数据增强为条件的——不同的数据增强集将导致不同的风格定义。
确保风格的多样性
为了确保用户可以得到不同风格的动漫,当前有三种策略:首先,可以简单地从随机选择的风格代码 s_z 中生成;其次,解码器具有可以从解码器中恢复 s_z 的属性;第三,可以编写一个确定的惩罚函数,强制不同风格代码的解码不同;但这些策略都不是令人满意的。
该研究对风格和内容的定义提供了一种新的方法。即必须学习一个映射 F(c, s; θ),该映射采用内容编码 c 和风格编码 s 来生成动漫面孔。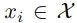 表示从数据中随机选择的单个图像,T(·) 表示对该图像应用随机选择的增强的函数,P(C) 表示内容编码的分布,P(Y) 表示真实动漫(等)的真实分布,
表示从数据中随机选择的单个图像,T(·) 表示对该图像应用随机选择的增强的函数,P(C) 表示内容编码的分布,P(Y) 表示真实动漫(等)的真实分布, 为生成的动漫图像。这里必须有 c(xi) ∼ P(C)。因为风格定义为在增强下不会改变的内容,合理选择的增强应该意味着 c(T(x_i)) ∼ P(C) , 即对图像应用随机增强会导致内容编码是先前内容编码的示例。这个假设是合理的,如果它被严重违反,那么图像增强训练分类器将不起作用。
为生成的动漫图像。这里必须有 c(xi) ∼ P(C)。因为风格定义为在增强下不会改变的内容,合理选择的增强应该意味着 c(T(x_i)) ∼ P(C) , 即对图像应用随机增强会导致内容编码是先前内容编码的示例。这个假设是合理的,如果它被严重违反,那么图像增强训练分类器将不起作用。
损失函数为:
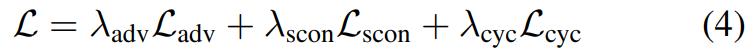
实验结果
在实验部分,该研究使用 batch 为 7,λ_scon = 10, λ_cyc = 20, λ_adv = 1 进行实验。网络架构基于 StyleGAN2[9],该架构风格编码的维度为 8。使用 Adam 优化器 [12] 对所有网络进行 300k 批次迭代,学习率为 0.002。在输入图像上使用的随机增强包括随机水平翻转、(−20,20)之间的旋转、缩放(0.9,1.1)、平移(0.1,0.1)、剪切(0.15)。图像被放大到 286 × 286,并随机裁剪为 256 × 256。数据集主要采用 selfie2anime 数据集 [10] 以及 AFHQ [1] 的附加实验。
定性比较
一般来说,当给定相同的源图像和不同的随机风格编码时,GNR 会产生不同的图像。风格编码驱动头发、眼睛、鼻子、嘴巴、颜色等的外观,而内容驱动姿势、面部大小、面部部位的位置等。图 4 显示,GNR 在质量和多样性方面优于其他 SOTA 多模态框架。
GNR 生成的图像具有不同的颜色、发型、眼睛形状、面部结构等,而其他框架则只能生成不同的颜色。

将多模态结果与 SOTA 迁移框架进行了比较。
该研究还在图 5 中与 AniGAN [14] 进行了比较。请注意,即使 AniGAN 是在更大、更多样化的数据集上进行训练的,但是,该研究也能够生成具有更好的、更多样性的、更高质量的图像。此外,AniGAN 以 128 × 128 的分辨率生成,而该研究以 256 × 256 的分辨率生成。

下图展示的消融实验显示了多样性鉴别器(Diversity Discriminator)在确保多样性输出方面起着重要作用(图 6),实验可得多样性鉴别器明显促进了 GNR 输出更具多样性、更真实的图像。

定量比较
表 1 中使用多样性 FID、FID 和 LPIPS 对 GNR 进行了定量评估。在表 1 的所有实验中,研究发现 GNR 在所有指标上都明显优于其他 SOTA 框架。DFID 和 LPIPS 都关注图像的多样性,这些指标的得分从数量上证实了该研究生成图像的多样性优于其他框架。

视频到视频迁移
该研究对风格和内容的定义是,当一张脸在一个框架中移动时,风格不应该改变,但内容会改变。特别是,内容对特征所在的位置进行编码,而风格对特征的外观进行编码。反过来,内容编码应该捕获所有帧到帧的运动,合成动漫视频,而不必训练时间序列。
该研究将 GNR 逐帧应用于人脸视频,然后将生成的帧组装成视频。图 3 第 2 行中的结果显示,GNR 产生根据源移动的图像,同时在时间上保持一致的外观。


推荐阅读
(点击标题可跳转阅读)
更多细节可参考论文原文。欢迎加入迈微学习交流群,成为迈微社友,一起学习进步!

# CV技术社群邀请函 #

△长按添加迈微官方微信号
备注:姓名-学校/公司-研究方向-城市(如:小C-北大-目标检测-北京)
△点击卡片关注迈微AI研习社,获取最新CV干货
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:yidazhang1@gmail.com
最近在GitHub开源的电子书《计算机视觉实战演练:算法与应用》,是一种结合代码、数据集及html的在线学习媒介!在线电子文档、免费GPU代码运行、常用网络代码开源。

- GitHub项目地址
https://github.com/Charmve/computer-vision-in-action
- 在线电子书
https://charmve.github.io/computer-vision-in-action
由于微信公众号试行乱序推送,您可能不再能准时收到迈微AI研习社的推送。为了第一时间收到报道, 请将“迈微AI研习社”设为星标账号,以及常点文末右下角的“在看”。
觉得有用麻烦给个在看啦~ 
以上是关于人人皆可二次元!小姐姐生成不同风格动漫形象,肤色发型皆可变的主要内容,如果未能解决你的问题,请参考以下文章