Elasticsearch集群“脑裂”现象
Posted 熊猫IT学院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch集群“脑裂”现象相关的知识,希望对你有一定的参考价值。
1.什么是Elasticsearch集群脑裂
Elasticsearch集群由一个主节点(可以有多个备选主节点)和多个数据节点组成。其中主节点负责创建、删除索引、分配分片、追踪集群中的节点状态等工作,即调度节点,计算压力较轻;数据节点负责数据存储和具体操作,如执行搜索、聚合等任务,计算压力较大。
正常情况下,当主节点无法工作时,会从备选主节点中选举一个出来变成新主节点,原主节点回归后变成备选主节点。但有时因为网络抖动等原因,主节点没能及时响应,集群误以为主节点下线了,选举了一个新主节点,此时一个Elasticsearch集群中有了两个主节点,其他节点不知道该听谁的调度,这时就发生了"脑裂"现象,通俗点就是“精神分裂”。
es脑裂:一个大的es集群分裂成了多个小的集群。
比如有 a b c d 四个es
a b c d 之间选取一个master,比如master是a。
若某时刻 c d 访问不到a ,b能访问到a。
c d之间会重新选举一个master。
这样整个a b c d的es集群就会分裂为a b 和 b c 两个集群。
2.产生的原因
(1)网络抖动。
由于是内网通信、网络通信等问题造成部分节点认为master node挂掉, 然后另选master node的情况可能性较小;可以通过检查Ganglia集群监控,没有发现异常的内网流量, 故此原因可以排除。
而外网的网络出现问题的可能性更大,更有可能造成“脑裂”现象。
(2)节点负载。
如果主节点同时承担数据节点的工作,可能会因为工作负载大而导致对应的Elasticsearch实例停止响应。此外,由于数据节点上的Elasticsearch进程占用的内存较大, 较大规模的内存回收操作(GC)也能造成Elasticsearch进程失去响应。所以,该原因出现“脑裂”现象的可能性更大。
(3)内存回收。
由于数据节点上的Elasticsearch进程占用的内存较大,较大规模的内存回收操作也能造成Elasticsearch进程失去响应。
3.解决方法
(1)不要把主节点同时设为数据节点,即node.master和node.data不要同时为true。
主节点配置为:
node.master: true
node.data: false
从节点配置为:
node.master: false
node.data: true
(2)将节点响应超时discovery.zen.ping_timeout稍稍设置长一些(默认是3秒)。默认情况下, 一个节点会认为, 如果master节点在 3 秒之内没有应答, 那么这个节点就是挂掉了, 而增加这个值, 会增加节点等待响应的时间, 从一定程度上会减少误判。
(3)discovery.zen.minimum_master_nodes的默认值是1,该参数表示, 一个节点需要看到的具有master节点资格的最小数量, 然后才能在集群中做操作,即重新选举主节点。官方的推荐值是(N/2)+1,其中 N 是具有 master资格的节点的数量,即只有超过(N/2)+1个主节点同意,才能重新选举主节点。
4.方案分析
实际解决办法
最终考虑到资源有限,解决方案如下:
增加一台物理机,这样,一共有了三台物理机。在这三台物理机上,搭建了6个ES的节点,三个data节点,三个master节点(每台物理机分别起了一个data和一个master),3个master节点,目的是达到(n/2)+1等于2的要求,这样挂掉一台master后(不考虑data),n等于2,满足参数,其他两个master节点都认为master挂掉之后开始重新选举,
master节点上
node.master = true
node.data = false
discovery.zen.minimum_master_nodes = 2
data节点上
node.master = false
node.data = true
方案分析
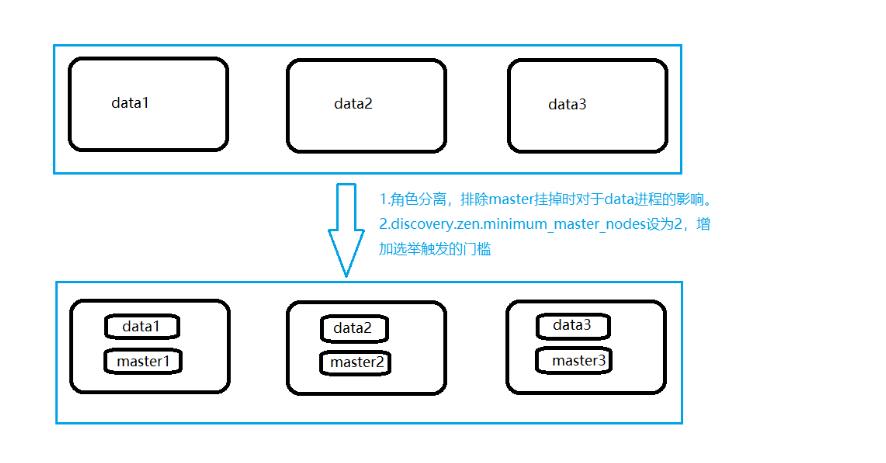
1.角色分离后,当集群中某一台节点的master进程意外挂掉了,或者因负载过高停止响应,终止掉的master进程很大程度上不会影响到同一台机器上的data进程,即减小了数据丢失的可能性。
2.discovery.zen.minimum_master_nodes设置成了2(3/2+1)当集群中两台机器都挂了或者并没有挂掉而是处于高负载的假死状态时,仅剩一台备选master节点,小于2无法触发选举行为,集群无法使用,不会造成分片混乱的情况。
而图一,两台节点假死,仅剩一台节点,选举自己为master,当真正的master苏醒后,出现了多个master,并且造成查询不同机器,查到了结果不同的情况。
5.总结
以上的解决方法只能是减缓这种现象的发生, 并没有从根本上杜绝。
如果发生了脑裂, 如何解决?
所以怎么从脑裂中恢复?
第一个建议是给所有数据重新索引。
第二, 如果脑裂发生了, 要十分小心的重启你的集群。 停掉所有节点并决定哪一个节点第一个启动。 如果需要, 单独启动每个节点并分析它保存的数据。 如果不是有效的, 关掉它, 并删除它数据目录的内容( 删前先做个备份) 。 如果你找到了你想要保存数据的节点, 启动它并且检查日志确保它被选为主节点。 这之后你可以安全的启动你集群里的其他节点了。
以上是关于Elasticsearch集群“脑裂”现象的主要内容,如果未能解决你的问题,请参考以下文章