Python:ID3算法的基本原理及代码复现
Posted Spuer_Tiger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python:ID3算法的基本原理及代码复现相关的知识,希望对你有一定的参考价值。
文章目录
引言
本文主要介绍了ID3算法进行决策树生成的算法原理,并对该算法流程进行了代码复现,其中算法的部分参考自李航-《统计学习方法》一书,代码的注释详细,供读者学习参考及学习交流。( 本文所有数据及代码均已上传,提取码:6w65!)
ID3算法的基本原理
信息增益的算法
根据信息增益准则的特征选择方法是:对训练数据集(或子集) D,计算其,每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征。
设训练数据集D,|D|表示其样本容量,即样本个数。设有K个Ck,k=1,2,…,K,|Ck|为属于类Ck的样本个数, ∑ k = 1 K ∣ C k ∣ = ∣ D ∣ \\sum_{\\mathbf{k}=1}^{\\begin{array}{c} \\mathbf{K}\\\\\\end{array}}{|\\mathbf{C}_{\\mathbf{k}}|=|\\mathbf{D}|} k=1∑K∣Ck∣=∣D∣。设特征A有n个不同的取值{a1,a2,…,an},根据特征A的取值将D划分为n个子集D1,D2,…,Dn,|Di|为Di的样本个数, ∑ i = 1 n ∣ D i ∣ = ∣ D ∣ \\sum_{\\mathbf{i}=1}^{\\begin{array}{c} \\mathbf{n}\\\\\\end{array}}{|\\mathbf{D}_{\\mathbf{i}}|=|\\mathbf{D}|} i=1∑n∣Di∣=∣D∣。记Di中属于类Ck的样本的集合为Dik,即Dik=Di∩Ck,|Dik|为Dik的样本个数,于是信息增益的算法如下:
输入:训练数据集D和特征A;
输出:特征A对训练数据集D的信息增益g(D,A)。
(1)计算数据集D的经验熵H(D)
H
(
D
)
=
−
∑
k
=
1
K
∣
C
k
∣
∣
D
∣
log
2
∣
C
k
∣
∣
D
∣
\\mathbf{H}\\left( \\mathbf{D} \\right) =-\\sum_{\\mathbf{k}=1}^{\\mathbf{K}}{\\frac{|\\mathbf{C}_{\\mathbf{k}}|}{|\\mathbf{D}|}\\log _2\\frac{|\\mathbf{C}_{\\mathbf{k}}|}{|\\mathbf{D}|}}
H(D)=−k=1∑K∣D∣∣Ck∣log2∣D∣∣Ck∣
(2)计算特征A对数据集D的经验条件熵H(DIA)
H
(
D
∣
A
)
=
∑
i
=
1
n
∣
D
i
∣
∣
D
∣
H
(
D
i
)
=
−
∑
i
=
1
n
∣
D
i
∣
∣
D
∣
∑
k
=
1
K
∣
D
i
k
∣
∣
D
i
∣
log
2
∣
D
i
k
∣
∣
D
i
∣
\\mathbf{H}\\left( \\mathbf{D}|\\mathbf{A} \\right) =\\sum_{\\mathbf{i}=1}^{\\mathbf{n}}{\\frac{|\\mathbf{D}_{\\mathbf{i}}|}{|\\mathbf{D}|}\\mathbf{H}\\left( \\mathbf{D}_{\\mathbf{i}} \\right) =-\\sum_{\\mathbf{i}=1}^{\\mathbf{n}}{\\frac{|\\mathbf{D}_{\\mathbf{i}}|}{|\\mathbf{D}|}}}\\sum_{\\mathbf{k}=1}^{\\mathbf{K}}{\\frac{|\\mathbf{D}_{\\mathbf{ik}}|}{|\\mathbf{D}_{\\mathbf{i}}|}\\log _2\\frac{|\\mathbf{D}_{\\mathbf{ik}}|}{|\\mathbf{D}_{\\mathbf{i}}|}}
H(D∣A)=i=1∑n∣D∣∣Di∣H(Di)=−i=1∑n∣D∣∣Di∣k=1∑K∣Di∣∣Dik∣log2∣Di∣∣Dik∣
Dik:表示特征A的值为i的样本在k类别的样本数量,Di:表示特征A的值为i的样本数量。
(3)计算信息增益
g
(
D
,
A
)
=
H
(
D
)
−
H
(
D
∣
A
)
\\mathbf{g}\\left( \\mathbf{D},\\mathbf{A} \\right) =\\mathbf{H}\\left( \\mathbf{D} \\right) -\\mathbf{H}\\left( \\mathbf{D}|\\mathbf{A} \\right)
g(D,A)=H(D)−H(D∣A)
具体的计算过程,参考如下例题:
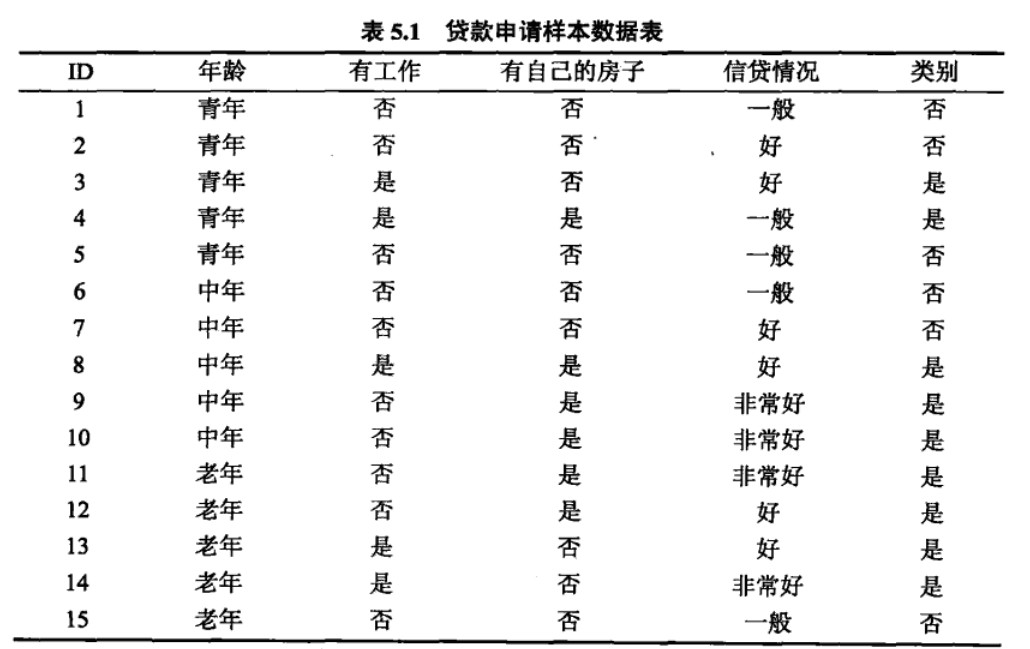

ID3算法的流程
输入:训练数据集D,特征集A,阈值ε;
输出:决策树T。
(1)若D中所有实例属于同一类Ck,则T为单节点树,并将类Ck作为该节点的类标记,返回T;
(2)若A=∅,则T为单节点树,并将D中实例数最大的类Ck作为该节点的类标记,返回T;
(3)否则,计算A中的各特征对D的信息增益,选择信息增益最大的特征Ag;
(4)如果Ag的信息增益小于阈值ε,则置T为节点树,并将D中实例数最大的类Ck作为该节点的类标记,返回T;
(5)否则,对Ag的每一个可能值ai,依Ag=ai将D分割为若干非空子集Di,将Di中实例数最大的类作为标记,构建子节点,由节点以及子节点构成T,返回T;
(6)对第i个子节点,以Di为训练集,以A-{Ag}为特征集,递归地调用步(1)–步(5),得到子树Ti,返回Ti。
具体的计算过程,参考如下例题:
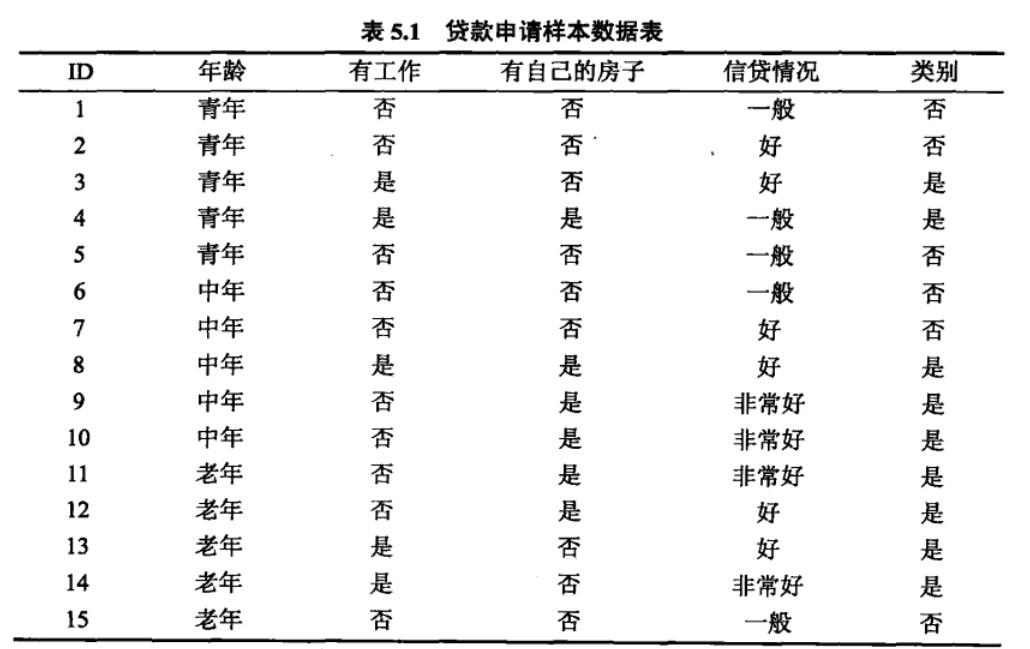
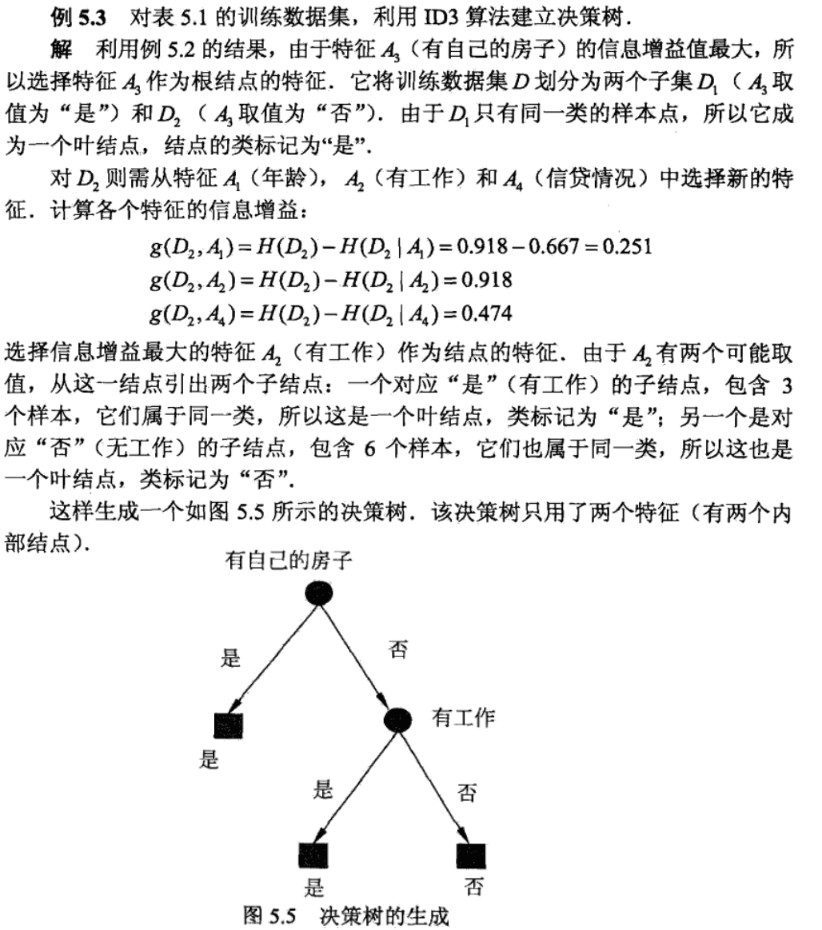
ID3算法的代码复现
数据集的准备:
1.Mnist数据集的格式转换
将mnist.idx-ubyte文件转换成.csv文件(mnist原始数据集为字符格式),代码如下:
def convert(imgf, labelf, outf, n):
f = open(imgf, "rb")
o = open(outf, "w")
l = open(labelf, "rb")
f.read(16)
l.read(8)
images = []
for i in range(n):
image = [ord(l.read(1))]
for j in range(28 * 28):
image.append(ord(f.read(1)))
images.append(image)
for image in images:
o.write(",".join(str(pix) for pix in image) + "\\n")
f.close()
o.close()
l.close()
if __name__ == '__main__':
convert(".\\Mnist\\\\t10k-images.idx3-ubyte", ".\\Mnist\\\\t10k-labels.idx1-ubyte",
".\\Mnist\\\\mnist_test.csv", 10000)
convert(".\\Mnist\\\\train-images.idx3-ubyte", ".\\Mnist\\\\train-labels.idx1-ubyte",
".\\Mnist\\mnist_train.csv", 60000)
转换的效果如下:
算法模块的实现
2.加载数据
对图片进行数据集和标签集的划分,同时对数据进行二值化的处理,减小生成决策树的计算量,代码如下:
def LoadData(filename):
'''
加载文件
:param filename:要加载的文件路径
:return: 数据集和标签集
'''
# 存放数据以及标记
dataArr = []
labelArr = []
# 读取文件
fr = open(filename)
# 遍历文件
for line in fr.readlines():
# strip:去除首尾部分的空格和回车
curline = line.strip().split(",")
# 数据二值化操作,减小运算量
dataArr.append([int(int(num) > 128) for num in curline[1:]])
# 添加标记
labelArr.append(int(curline[0]))
# 返回数据集和标记
return dataArr, labelArr
3.寻找对应样本数目最大的标签
找到当前标签集中占数目最大的标签, 遍历所有标签,对不同类别标签的统计情况进行降序排序,返回最大一项的标签,代码如下:
def MajorClass(labelArr):
'''
找到当前标签集中占数目最大的标签
:param labelArr: 标签集
:return: 最大的标签
'''
# 建立字典,统计不同类别标签的数量
classDict = {}
# 遍历所有标签
for i in range(len(labelArr)):
if labelArr[i] in classDict.keys():
classDict[labelArr[i]] += 1
else:
classDict[labelArr[i]] = 1
# 对不同类别标签的统计情况进行降序排序
classSort = sorted(classDict.items(), key=lambda x: x[1], reverse=True)
# 返回最大一项的标签,即占数目最多的标签
return classSort[0][0]
4.经验熵的计算
计算数据集D的经验熵,参考公式经验熵的计算。
def Cal_HD(trainLabelArr):
'''
计算数据集D的经验熵,参考公式经验熵的计算
:param trainLabelArr:当前数据集的标签集
:return: 经验熵
'''
HD = 0
# 统计该分支的标签情况
# set()删除重复数据
trainLabelSet = set([label for label in trainLabelArr])
# 遍历每一个出现过的标签
for i in trainLabelSet:
p = trainLabelArr[trainLabelArr == i].size / trainLabelArr.size
# 对经验熵的每一项进行累加求和
HD += -1 * p * np.log2(p)
# 返回经验熵
return HD
5.条件经验熵的计算
计算经验条件熵,这里需要注意的是trainDataArr_DevFeature(这个参数的含义是代表选定数据集的样本在指定的特征下那一列的特征向量),拿到当前指定feature中的可取值的范围,对于每一个特征取值遍历计算条件经验熵的每一项,代码如下:
def Cal_HDA(trainDataArr_DevFeature, trainLabelArr):
'''
计算经验条件熵
:param trainDataArr_DevFeature:切割后只有feature那列数据的数组
:param trainLabelArr: 标签集数组
:return: 条件经验熵
'''
# 初始为0
HDA = 0
# 拿到当前指定feature中的可取值的范围
trainDataSet = set([label for label in trainDataArr_DevFeature])
# 对于每一个特征取值遍历计算条件经验熵的每一项
# trainLabelArr[trainDataArr_DevFeature == i]表示特征值为i的样本集对应的标签集
for i in trainDataSet:
HDA += trainDataArr_DevFeature[trainDataArr_DevFeature == i].size / trainDataArr_DevFeature.size * Cal_HD(
trainLabelArr[trainDataArr_DevFeature == i])
# 返回得出的条件经验熵
return HDA
6. 计算信息增益最大的特征
计算数据集的经验熵,对每一个特征进行遍历计算信息增益,不断更新最大的信息增益以及对应的特征,最终返回最大的信息增益以及对应的特征,代码如下:
def Cal_BestFeature(trainDataList, trainLabelList):
'''
计算信息增益最大的特征
:param trainDataList: 当前数据集
:param trainLabelList: 当前标签集
:return: 信息增益最大的特征及最大信息增益值
'''
# 列表转为数组格式
trainDataArr = np.array(trainDataList)
trainLabelArr = np.array(trainLabelList)
# 获取当前的特征个数
# 获取trainDataArr的列数
featureNum = trainDataArr.shape[1]
# 初始化最大信息熵G(D|A)
max_GDA = -1
# 初始化最大信息增益的特征索引
max_Feature = -1
# 计算数据集的经验熵
HD = Cal_HD(trainLabelArr)
# 对每一个特征进行遍历计算
for feature in range(featureNum):
# .flat:flat返回的是一个迭代器,可以用for访问数组每一个元素
trainDataArr_DevideByFeature = np.array(trainDataArr[:, feature].flat)
# 计算信息增益G(D|A) = H(D) - H(D|A)
GDA = HD - Cal_HDA(trainDataArr_DevideByFeature, trainLabelArr)
# 不断更新最大的信息增益以及对应的特征
if GDA > max_GDA:
max_GDA = GDA
max_Feature = feature
return max_Feature, max_GDA
7.子数据集和对应标签集的创建
对当前数据集的每一个样本进行遍历,如果当前样本的特征为指定特征值a,那么将该样本的第A个特征切割掉,放入返回的数据集中,代码如下:
def GetSubDataArr(trainDataArr, trainLabelArr, A, a):
'''
待更新的子数据集和标签集
:param trainDataArr: 待更新的数据集
:param trainLabelArr: 待更新的标签集
:param A: 待去除的以上是关于Python:ID3算法的基本原理及代码复现的主要内容,如果未能解决你的问题,请参考以下文章