从读取2.5G的《黄金时代》,我们聊一聊python的内存优化及垃圾回收机制
Posted Spuer_Tiger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从读取2.5G的《黄金时代》,我们聊一聊python的内存优化及垃圾回收机制相关的知识,希望对你有一定的参考价值。
故事篇
不知道是下载错了,还是什么错了?突然发现e盘里面的《黄金时代》.txt居然高达2.5G,打开之后发现又是原版的,归纳一句话:“错了,又没完全错(。◕ᴗ◕。)。”

《黄金时代》用着混乱猥琐,写美,写纯洁。
《黄金时代》给我的感觉,像那句:“当我沿着一条路走下去的时候,心里总想着另一条路上的事。这种时候,我心里很乱。 ”那么,话锋一转,问题来了( ̄ω ̄=),我是如何使用python读取这2.5G的《黄金时代》呢?以及python的内存检测及优化,垃圾回收机制又是怎样的呢?
正篇
读取大文件的错误原因分析
首先,我们读取"黄金时代.txt"文件:
# encoding==utf-8
with open("黄金时代.txt", "r") as file:
print(file.read())
或者:
with open(file_path, 'rb') as f:
for line in f.readlines():
print(line)
然后出现了out of memory的错误提示。 这对方法在读取小文件时确实不会产生什么异常,但是一旦读取大文件,很容易会产生MemoryError,也就是内存溢出的问题。 分析如下:
read():当默认参数size=-1时,read方法会读取直到EOF,当文件大小大于可用内存时,自然会发生内存溢出的错误。

readlines():会构造一个list。list而不是iter,所以所有的内容都会保存在内存之上,同样也会发生内存溢出的错误。

内存溢出的问题解决方法
①如果是二进制文件推荐用如下这种写法,可以自己指定缓冲区有多少byte。显然缓冲区越大,读取速度越快。
with open(file_path, 'rb') as f:
while True:
buf = f.read(1024)
if buf:
sha1Obj.update(buf)
else:
break
②如果是文本文件,则可以用readline方法或直接迭代文件。
with open(file_path, 'rb') as f:
while True:
line = f.readline()
if buf:
print(line)
else:
break
with open(file_path, 'rb') as f:
for line in f:
print(line)
③如果是CSV文件,采用分块读取后拼接的方法。
import pandas as pd
def read_data(file_name):
'''
file_name:文件地址
'''
inputfile = open(file_name, 'rb') #可打开含有中文的地址
data = pd.read_csv(inputfile, iterator=True)
loop = True
chunkSize = 1000 #一千行一块
chunks = []
while loop:
try:
chunk = data.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
loop = False
print("Iteration is stopped.")
data = pd.concat(chunks, ignore_index=True)
#print(train.head())
return data
④如果使用pycharm编译平台,可修改最大内存设置。
1、依次点击菜单栏中的Help、Find Action选项;
2、在弹出的输入框中输入VM,找到并打开Edit Custom VM Options选项;
3、修改“-Xms”与“-Xmx”配置即可。
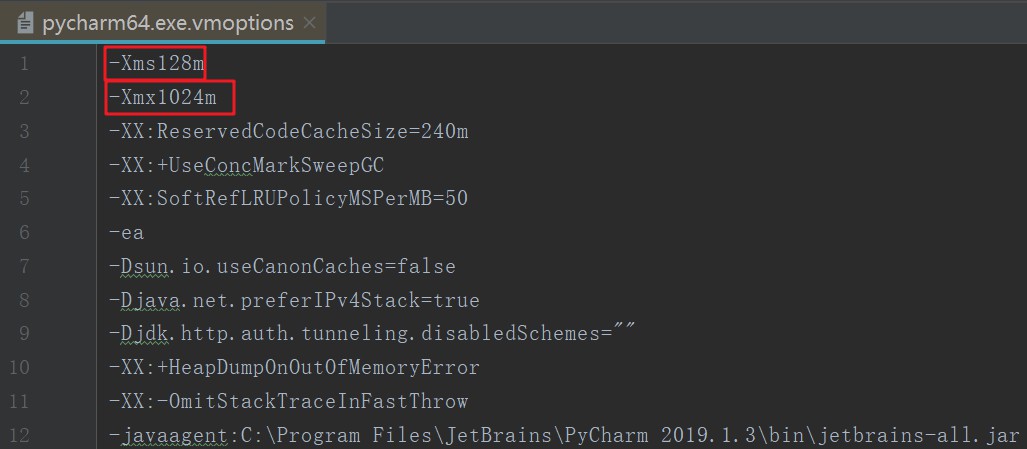
这里需要注意的是:
-Xms 用来设置“应用程序启动时的可用内存大小”;
-Xmx用来设置“ JVM最大分配的内存,即运行时可用的内存大小”。
点这里->参考链接:Java内存管理之类似-Xms、-Xmx 这些参数的含义
⑤当Pycharm的缓存过大,可删除content.dat.storageData文件。

找到该文件删除即可,一般该文件的路径如下:
C:\\Users\\xxx\\.PyCharm2017.2\\system\\caches\\content.dat.storageData
或者:
C:\\Users\\Administrator\\AppData\\Local\\JetBrains\\PyCharm2020.1\\caches\\content.dat.storageData
既然,我们的编译平台会出现内存溢出的情况,我们如何监测程序的内存占用,以及运行的时间呢?
程序内存占用及模块运行时间的检测方法
①显示当前 python 程序占用的内存大小
import os
import psutil
# 显示当前 python 程序占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. / 1024
print('{} memory used: {} MB'.format(hint, memory))
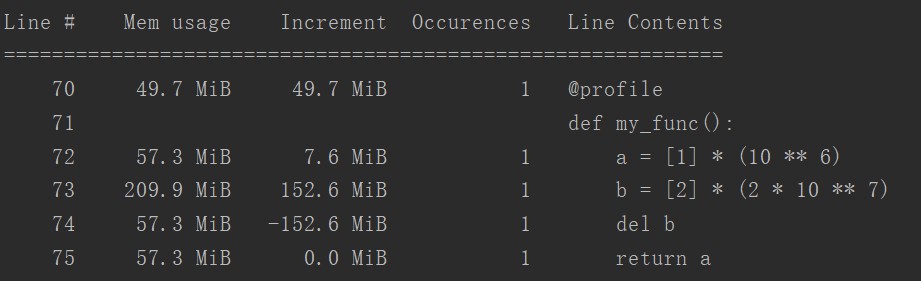
②使用memory_profiler监测每一步代码的内存占用
from memory_profiler import profile
@profile
# 放在需用计时的函数名称之前
def my_func():
a = [1] * (10 ** 6)
b = [2] * (2 * 10 ** 7)
del b
return a
if __name__ == '__main__':
my_func()
③检测指定路径下所有文件所占用内存
import os
def check_memory(path, style='M'):
i = 0
for dirpath, dirname, filename in os.walk(path):
for ii in filename:
i += os.path.getsize(os.path.join(dirpath, ii))
if style == 'M':
memory = i / 1024. / 1024.
print('%.2f MB' % memory)
else:
memory = i / 1024. / 1024. / 1024.
print('%.4f GB' % memory)
④检测指定路径剩余储存空间大小
import ctypes
import os
import platform
def get_free_space_mb(folder):
if platform.system() == 'Windows':
free_bytes = ctypes.c_ulonglong(0)
ctypes.windll.kernel32.GetDiskFreeSpaceExW(ctypes.c_wchar_p(folder), None, None, ctypes.pointer(free_bytes))
return free_bytes.value / 1024 / 1024 / 1024
else:
st = os.statvfs(folder)
return st.f_bavail * st.f_frsize / 1024 / 1024 / 1024.
print(str(get_free_space_mb(path)) + " GB")
⑤使用装饰器来衡量函数执行时间
首先,定义一个装饰器来测量函数的执行时间:
import time
from functools import wraps
def fn_timer(function):
@wraps(function)
def function_timer(*args, **kwargs):
t0 = time.time()
result = function(*args, **kwargs)
t1 = time.time()
print ("Total time running %s: %s seconds" %
(function.func_name, str(t1-t0))
)
return result
return function_timer
然后,将这个装饰器添加到需要测量的函数之前。
@fn_timer
# 放在需用计时的函数名称之前
def random_sort(n):
return sorted([random.random() for i in range(n)])
测试的示例如下:
点这里->参考链接:10种检测Python程序运行时间、CPU和内存占用的方法
⑥获取系统的物理内存和虚拟内存
import wmi
import platform
def get_memory_info(os):
"""
获取系统的物理内存和虚拟内存。
"""
print("memory_info:")
if os == "Windows":
c = wmi.WMI()
cs = c.Win32_ComputerSystem()
pfu = c.Win32_PageFileUsage()
MemTotal = int(cs[0].TotalPhysicalMemory) / 1024 / 1024
print('\\t' + "TotalPhysicalMemory :" + '\\t' + str(MemTotal) + "M")
# tmpdict["MemFree"] = int(os[0].FreePhysicalMemory)/1024
SwapTotal = int(pfu[0].AllocatedBaseSize)
print('\\t' + "SwapTotal :" + '\\t' + str(SwapTotal) + "M")
# tmpdict["SwapFree"] = int(pfu[0].AllocatedBaseSize - pfu[0].CurrentUsage)
if __name__ == "__main__":
os = platform.system()
get_memory_info(os)

⑦获取系统的CPU信息
import wmi
import platform
def get_cpu_info(os):
"""
获取CPU信息。
"""
print("cpu_info:")
if os == "Windows":
tmpdict = {}
tmpdict["CpuCores"] = 0
c = wmi.WMI()
for cpu in c.Win32_Processor():
tmpdict["CpuType"] = cpu.Name
try:
tmpdict["CpuCores"] = cpu.NumberOfCores
except:
tmpdict["CpuCores"] += 1
tmpdict["CpuClock"] = cpu.MaxClockSpeed
print('\\t' + 'CpuType :\\t' + str(tmpdict["CpuType"]))
print('\\t' + 'CpuCores :\\t' + str(tmpdict["CpuCores"]))
if __name__ == "__main__":
os = platform.system()
get_cpu_info(os)
测试的示例如下:

点这里->参考链接:python使用WMI检测windows系统信息、硬盘信息、网卡信息的方法
提升python运行速度的方法
NumPy的创始人Travis Oliphant在离开Enthought之后,创建了CONTINUUM,致力于将Python大数据处理方面的应用。推出的Numba项目能够将处理NumPy数组的Python函数JIT编译为机器码执行,从而上百倍的提高程序的运算速度。
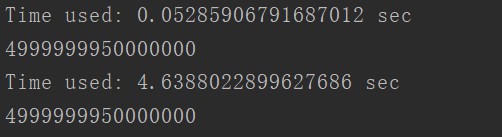
使用jit,超级加速程序的运行
import time
from numba import jit
@jit
def foo1(x, y):
tt = time.time()
s = 0
for i in range(x, y):
s += i
print('Time used: {} sec'.format(time.time() - tt))
return s
def foo2(x, y):
tt = time.time()
s = 0
for i in range(x, y):
s += i
print('Time used: {} sec'.format(time.time() - tt))
return s
print(foo1(1, 100000000))
print(foo2(1, 100000000))
测试的结果如下:
点这里->参考链接:一行代码让 Python 的运行速度提高100倍
Python的垃圾回收机制
垃圾回收机制(简称GC)是Python解释器自带一种机制,专门用来回收不可用的变量值所占用的内存空间。Python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用的问题,并且通过“分代回收”(generation collection)以空间换取时间的方式来进一步提高垃圾回收的效率。
解释器在执行到定义变量得语法时,会申请内存空间来存放变量得值,但是由于内存空间是有限的,这种时候就应该回收掉这个变量值得内存空间。
关于内存区域和 引用类型的概念如下:
1、堆区和栈区
在定义变量时,变量名与变量值都是需要存储的,分别对应内存中的两块区域:堆区与栈区。
1、变量名与值内存地址的关联关系存放于栈区;
2、变量值存放于堆区,内存管理回收的则是堆区的内容。
2、直接引用和间接引用
1.直接引用指的是从栈区出发直接引用到的内存地址;
x=10 # 10这个值被变量x直接引用2.间接引用指的是从栈区出发引用到堆区后,再通过进一步引用才能到达的内存地址。
list=[20,x] # 10这个值被列表list间接引用12
①"引用计数"机制
“引用计数”机制:变量值被变量名关联得次数(包括间接引用和直接引用 ),一旦变量得引用计数得值变成0,占用内存就会被回收。
只有当一个变量值每一次被直接或间接引用时,引用计数才会增加,在Python中让引用计数增加共有三种方法:
- 变量被创建,变量值引用计数加1
- 变量被引用,变量值引用计数加1
- 变量作为参数传入到一个函数,变量值引用计数加2
对象有新的引用时,它的 ob_refcnt 会增加;当对象的引用被删除时,ob_refcnt 会减少。当引用计数为 0 时,对象的生命周期就结束了。
具体例子分析:
import sys
a = []
# 两次引用,一次来自 a,一次来自 getrefcount
print(sys.getrefcount(a))
def func(a):
# 四次引用,a,python 的函数调用栈,函数参数,和 getrefcount
print(sys.getrefcount(a))
func(a)
# 两次引用,一次来自 a,一次来自 getrefcount,函数 func 调用已经不存在
print(sys.getrefcount(a))
输出结果为:
2
4
2
再看一个具体的例子:
import sys
a = []
print(sys.getrefcount(a)) # 两次
b = a
print(sys.getrefcount(a)) # 三次
c = b
d = b
e = c
f = e
g = d
print(sys.getrefcount(a)) # 八次
输出结果为:
2
3
8
●“引用计数”存在“循环引用”的内存泄漏问题
"循环引用"具体的例子如下:
import os
import psutil
# 显示当前 python 程序占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. / 1024
print('{} memory used: {} MB'.format(hint, memory))
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
b = [i for i in range(10000000)]
show_memory_info('after a created')
a.append(b)
b.append(a)
del a #del操作导致引用数减1,但是b引用a的1次引用数并没有被减掉
del b
show_memory_info('after delete created')
func()
程序中,a 和 b 互相引用,并且作为局部变量在函数 func 调用结束后,a 和 b 这两个指针从程序意义上已经不存在,但从输出结果中看到,依然有内存占用,这是为什么呢?因为互相引用导致它们的引用数都不为 0(del操作导致引用数减1,但是b引用a的1次引用数并没有被减掉)。
试想一下,如果这段代码出现在生产环境中,哪怕 a 和 b 一开始占用的空间不是很大,但经过长时间运行后,Python 所占用的内存一定会变得越来越大,最终撑爆服务器,后果不堪设想。 有读者可能会说,互相引用还是很容易被发现的呀,问题不大。
可是,更隐蔽的情况是出现一个引用环,在工程代码比较复杂的情况下,引用环真不一定能被轻易发现。
事实上,Python 使用标记清除(mark-sweep)算法和分代收集(generational),来启用针对循环引用的自动垃圾回收。
②“标记-清除”机制
容器对象(比如:list,set,dict,class,instance)都可以包含对其他对象的引用,所以都可能产生循环引用。而“标记-清除”计数就是为了解决循环引用的问题。标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除。
“标记-清除”机制的原理概述:
我们先用图论来理解不可达的概念。对于一个有向图,如果从一个节点出发进行遍历,并标记其经过的所有节点;那么,在遍历结束后,所有没有被标记的节点,我们就称之为不可达节点。显而易见,这些节点的存在是没有任何意义的,自然的,我们就需要对它们进行垃圾回收。
“标记/清除”机制的效率问题
基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间的,于是引入了分代回收来提高回收效率,分代回收采用的是用“空间换时间”的策略。
当然,每次都遍历全图,对于 Python 而言是一种巨大的性能浪费。所以,在 Python 的垃圾回收实现中,标记清除算法使用双向链表维护了一个数据结构,并且只考虑容器类的对象(只有容器类对象才有可能产生循环引用)。
③"分代回收"机制
分代回收的核心思想是:在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低分代指的是根据存活时间来为变量划分不同等级(也就是不同的代)。
新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,接下来,青春代中的对象,也会以同样的方式被移动到老年代中。也就是等级(代)越高,被垃圾回收机制扫描的频率越低。也就是等级(代)越高,被垃圾回收机制扫描的频率越低,回收依然使用引用计数作为回收的依据。
●“分代回收”机制的缺点
例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,但青春代的扫描频率低于新生代,这就到导致了应该被回收的垃圾没有得到及时地清理。
python的常量池
在Python中严格的讲是没有常量这个概念的,即使你通过约定俗成的方法定义了一个常量,但这个常量也只是一个变量,也就是说只要你对这个常量做出修改,这个常量原有对应的常量值引用计数就会变成0,由于常量等同于变量,它一样会被Python垃圾回收机制回收。
但是在Python中,存在着一些例外,这些例外就是一个小整数池,顾名思义,小整数池表示的是从-5到256范围内的整数,这些整数定义出来后就是一个常量,也就是说他们的引用计数即使为0,也不会被Python的垃圾回收机制回收,可以通过下述实例验证:
import sys
first_l = [] # 定义列表l存储[-5,256]中的所有整数的引用计数
add_l = [] # 定义列表add_l存储[-5,256]中的所有整数的引用计数加1后的引用计数
del_l = [] # 定义列表del_l存储[-5,256]中的所有整数的引用计数减1后的引用计数
for i in range(-5, 256):
first_l.append(sys.getrefcount(i))
add = i
add_l.append(sys.getrefcount(i))
del add
del_l.append(sys.getrefcount(i))
first_l.sort()
add_l.sort()
del_l.sort()
print(f'min(first_l): {min(first_l)}') # 获取[-5,256]中所有整数的最小引用计数,输出为4
print(f'min(add_l): {min(add_l)}') # 获取[-5,256]中所有整数的最小引用计数,输出为5
print(f'min(del_l): {min(del_l)}') # 获取[-5,256]中所有整数的最小引用计数,输出为4
从上述实例可以看出,[-5,256]中的整数的getrefcount默认初始值为4,也就是说即使没有对这些整数进行初始化的创建,Python早已对他们进行了引用,即使他们的引用计数为0,他们也不会也不可能被删除,因为他们从Python解释器启动开始就已经被生成。
以上是关于从读取2.5G的《黄金时代》,我们聊一聊python的内存优化及垃圾回收机制的主要内容,如果未能解决你的问题,请参考以下文章