Java集合框架源码详解系列——迭代器设计模式详解
Posted AC-fun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java集合框架源码详解系列——迭代器设计模式详解相关的知识,希望对你有一定的参考价值。
上一篇博客:Java集合框架源码详解系列(一)
写在前面:大家好!我是
AC-fun,我的昵称来自两个单词Accepted和fun。我是一个热爱ACM的蒟蒻。如果博客中有不足或者的错误的地方欢迎在评论区或者私信我指正,感谢大家的不吝赐教。我的唯一博客更新地址是:https://ac-fun.blog.csdn.net/。非常感谢大家的支持。一起加油,冲鸭!
用知识改变命运,用知识成就未来!加油 (ง •̀o•́)ง (ง •̀o•́)ง
前言
在上一篇博客 Java集合框架源码详解系列(一) 对 Java 集合框架的整体结构进行了分析,这一篇来详细的介绍一下容器的设计模式以及设计模式的源码详解。
设计模式简介
Java一共具有 23 种设计模式,其实 设计模式 最早并不是计算机领域的术语而是建筑领域的。
1977 年,美国著名建筑大师、加利福尼亚大学伯克利分校环境结构中心主任 克里斯托夫·亚历山大 在他的著作 《建筑模式语言:城镇、建筑、构造》 中描述了一些常见的建筑设计问题,并提出了 253 种关于对城镇、邻里、住宅、花园和房间等进行设计的基本模式。1979 年他的另一部经典著作 《建筑的永恒之道》 进一步强化了设计模式的思想,为后来的建筑设计指明了方向。
直到 1990 年,软件工程界才开始研讨设计模式的话题,后来召开了多次关于设计模式的研讨会。
1995 年,艾瑞克·伽马、理査德·海尔姆、拉尔夫·约翰森、约翰·威利斯迪斯 等 4 位作者合作出版了 《设计模式:可复用面向对象软件的基础》 一书,在本教程中收录了 23 个设计模式,这是设计模式领域里程碑的事件,导致了软件设计模式的突破。这 4 位作者在软件开发领域里也以他们的“四人组”(Gang of Four,GoF)匿名著称。
为什么要使用设计模式呢?为什么不直接进行开发而去使用设计模式来进行开发呢?使用设计模式有什么好处呢?
这就要从我们程序员开发软件时经常碰到的挑战说起了,在设计编写软件的过程中,程序员经常面临着来自耦合性、内聚性、可维护性、可扩展性、重用性以及灵活性等多方面的挑战。而设计模式的目的就是要解决这些挑战,使程序员开发的软件具有更好的代码重用性、可读性、可扩展性、鲁棒性、低内聚、高耦合等特性。
当然,软件设计模式只是一个引导。在具体的软件开发中,必须根据设计的应用系统的特点和需求来进行恰当的选择。对于简单的程序开发,可能写一个简单的算法要比引入某种设计模式更加容易。但对大项目的开发或者框架设计,用设计模式来组织代码显然更好,选择恰当的设计模式将会大大提高我们软件的质量。
容器中的设计模式
Java 容器中的设计模式有两种:迭代器模式和适配器模式。
迭代器模式
Collection 继承了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。同样,在 List、Set、Map 等都包含了迭代器。
引入
迭代器模式可以帮助我们很方便的实现集合遍历,在使用迭代器遍历时不需要知道集合对象的底层表示。迭代器模式给我们提供了一种遍历集合元素的统一接口,可以用一致的方法遍历集合元素。
如果不使用迭代器,在我们设计实现集合遍历,访问集合中的数据的时候通常将集合的创建和遍历放在同一个类中。比如数据结构中的单链表的遍历就是将创建和遍历放到了一个类中,这样不利于程序的拓展,如果链表的形式变了,需要更换遍历方法就必须要更改源码,这样就违背了 开闭原则。
比如之前我们使用的数组设计的静态链表,但是后来我们发现静态链表容易出现内存溢出,因为静态链表一旦空间使用完了,那么再加入新元素就会出现数据溢出的情况。为了解决这一问题我们使用链式存储数据,链式存储数据使用的是指针形式,所以遍历数据的方式就变了,我们不能使用之前遍历数组的那段代码来进行遍历了,所以就必须修改程序源码来重新实现链表的遍历。这种方式不但暴露了聚合类的内部表示,使数据不安全。也增加了开发人员的负担。迭代器模式 能较好地解决以上的问题,它在用户访问类与聚合类之间插入一个迭代器,这分离了聚合对象与其遍历行为,对用户也隐藏了其内部细节,且满足 单一职责原则 和 开闭原则。
迭代器模式具有如下优点:
- 聚合对象的内部类不会被暴露。
- 遍历任务交由迭代器完成,这简化了聚合类。
- 它支持以不同方式遍历一个聚合,甚至可以自定义迭代器的子类以支持新的遍历。
- 增加新的聚合类和迭代器类都很方便,无须修改原有代码。
- 封装性良好,为遍历不同的聚合结构提供一个统一的接口。
Iterator接口详解
通过观察源码发现 Iterator 接口包含 4 个抽象方法
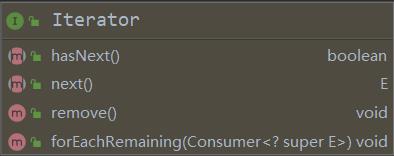
下面我们以 ArrayList 为例说明该接口的作用。
public class CollectionDemo01 {
public static void main(String[] args) {
// 创建Collection集合对象
List<String> c = new ArrayList<>();
// add
c.add("Hello");
c.add("World");
// foreach遍历
for (String item : c) System.out.print(item + ' ');
System.out.println();
// 获得迭代器
Iterator Itr = c.iterator();
while (Itr.hasNext()) System.out.println(Itr.next());
System.out.println(c);
}
}
这里创建了一个 ArrayList ,然后添加了两个单词。这里使用了两种方式遍历,一种是通过增强for循环的方式进行访问,另一种是通过迭代器方式访问。访问的方式还有很多种,这里就不再一一赘述了。这里主要说明迭代器部分,关于 ArrayList 源码的详解将在后续博客进行详细讲解。通过查看源码首先画出类图如下:
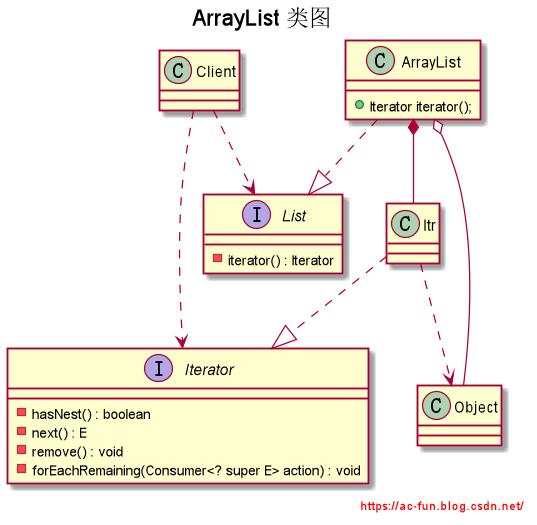
通过上面的类图我们可以知道首先 ArrayList 容器实现了 List 接口,它有一个叫做 Itr 的内部类实现了 Iterator 接口。下面通过 Itr 这一内部类来详细的解释一下迭代器中各个方法的作用:
hasNext() 方法源码详解
Itr 中 hasNext() 方法源码如下:
public boolean hasNext() {
return cursor != size;
}
ArrayList 是基于数组实现的,通过查看 ArrayList 的源码可以看到官方对于 cursor 的解释为 index of next element to return 意思就是 要返回的下一个元素的索引 ,默认值为 0。对 size 的解释为 The size of the ArrayList (the number of elements it contains). 意思为 ArrayList的长度(ArrayList中元素的个数)。所以该方法直接判断当前的数组元素的下一个元素应该返回的下标是否等于数组的总长度,因为数组下标是从零开始的,所以当下一个元素的下标等于数组的长度是正好能够说明没有下一个元素了。
为什么要有这个方法呢?因为在遍历 ArrayList 的时候需要先判断还有没有下一个元素。ArrayList 通过反复调用 next() 方法来逐个访问集合中的每个元素。但是,如果到达了集合的末尾,next() 方法将会抛出异常。所以在调用 next() 方法之前需要先调用一下 hasNext() 方法来判断下一个元素是否存在。如果迭代器对象还有元素可以访问,那么 hasNext() 方法将会返回 true,否则将会返回 false。
next() 方法源码详解
Itr 中 next() 方法源码如下:
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
首先 next() 方法调用了 checkForComodification() 方法,该方法的源码如下:
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
在该方法中 modCount 代表该 ArrayList 对象被修改的次数,每对 ArrayList 对象修改一次,modCount 都会加 1 。
expectedModCount 的值为创建 Itr 对象的时候 ArrayList 的 modCount 值。用此变量来检验在迭代过程中 ArrayList 对象是否被修改了,如果被修改了则抛出 java.util.ConcurrentModificationException 异常。在每次调用 Itr 对象的 next() 方法的时候都会调用checkForComodification() 方法进行一次检验,checkForComodification() 方法中做的工作就是比较expectedModCount 和 modCount 的值是否相等,如果不相等,就认为还有其他对象正在对当前的 ArrayList 进行操作或者在之前集合就被修改过导致集合实际修改的次数与预期修改的次数不一致,那个就会抛出ConcurrentModificationException 异常。该异常主要是检测集合是否出现 并发修改异常。
然后判断下一个进行遍历的元素是否存在,如果不存在则会抛出异常。如果下一个遍历的元素存在,那么将集合存储数据的地址复制给该方法的局部变量(Object[] elementData = ArrayList.this.elementData;)。
然后再判断一下是否产生了 并发修改异常,如果没有出现则将 cursor 变量加 1,再将当前的元素返回。
remove() 方法源码详解
remove() 方法从底层集合中删除此迭代器返回的最后一个元素,简单来说就是删除集合中的元素(可选操作)。 此方法只能调用一次 next() 。如果底层集合在迭代过程中以任何方式进行修改而不是通过调用此方法,则迭代器的行为是未指定的。 该方法的源码如下:
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
该方法首先判断了一下 lastRet 是否小于零,如果小于零则抛出异常。这里的 lastRet 变量的默认值为 -1 源码的注释为 index of last element returned; -1 if no such,意思是迭代器返回的最后一个元素的下标,通过查看 next() 方法的源码,我们可以发现该下标正是调用该方法最后返回的元素的下标。然后又调用 checkForComodification() 方法判断是否出现了 并发修改异常。都没有之后进行删除操作,通过 ArrayList.this.remove(lastRet); 方法我们可以发现其实迭代器中的 remove() 删除操作实际调用的还是集合的删除方法。关于集合中的删除方法将会在后面 ArrayList 中进行详解,这里就不再讲解了。
删除成功之后再更新 cursor 变量,因为当前的元素已经被删除了,所以该变量的值不能再加一了,而 next() 方法和 remove() 调用之间存在依赖性。如果调用remove() 方法之前没有调用 next() 是不合法的。所以需要重新更新一下 cursor 变量的值。然后将 lastRet 变量更改为默认值 -1。然后再把实际修改集合的次数赋值给预期修改次数(expectedModCount = modCount;)。
未完待续,持续更新中……

以上是关于Java集合框架源码详解系列——迭代器设计模式详解的主要内容,如果未能解决你的问题,请参考以下文章