TADAM解读
Posted 周先森爱吃素
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TADAM解读相关的知识,希望对你有一定的参考价值。
这是最近公开的CVPR2021主会议论文中一篇MOT方向的论文,将位置预测和特征提取两个任务协同工作,从而有效改善了遮挡等问题。
简介
目前的多目标跟踪方法主要关注于两个方向来改进跟踪性能,一是基于跟踪信息从之前帧预测当前帧中的位置,二是生成更具判别性的身份嵌入(identity embedding)来增强数据关联。有一些工作将这两个方向组合到一个框架中,但是仍然是将它们视作两个独立的任务,因此获得了很少相互作用的效果。在这篇论文中,作者提出了一种新的具有协同作用的统一模型,它确保了位置预测和嵌入关联之间的协同工作。这两个任务是通过时间感知目标注意力和干扰物注意力以及身份感知记忆聚合模型链接到一起的。具体而言,注意力模块确保预测更加关注于目标而不是干扰物,因而更具可靠性的嵌入可以提取用于关联。另一方面,这种可靠的嵌入可以通过记忆聚合增强身份感知能力从而增强注意力模块并且抑制漂移。通过这种方式,位置预测和嵌入关联协同作用,增强了跟踪器对于遮挡的鲁棒性。实验表明,提出的TADAM在MOTChallenge上领先于现有的大多数跟踪方法,获得了SOTA的表现。
-
论文标题
Online Multiple Object Tracking with Cross-Task Synergy
-
论文地址
https://arxiv.org/abs/2104.00380
-
论文源码
https://github.com/songguocode/TADAM
介绍
多目标跟踪(MOT)任务目的在于在每一帧中定位目标并且保持其身份标识以形成跨帧轨迹。目前MOT领域的研究主要集中在TBD范式下,也就是将多目标跟踪问题分为两个步骤,首先是每帧上检测出所有目标,然后通过跨帧目标之间的数据关联来形成轨迹,数据关联时身份嵌入(identity embedding)常被用来衡量两个目标的相似性。这种二阶段的策略揭示了两种改进跟踪性能的方式,一种是增强检测,一种则是增强基于embedding的数据关联。
大多数现有的在线方法通常只解决这两个方面中的一个以获得更好的跟踪结果,然而目前跟踪中最常见的挑战之一,遮挡,会对这两个方面都造成影响。非预期的遮挡会由于目标的重叠而出现误检,这同时也增加了关联的难度。很多在线跟踪方法都通过预测被跟踪目标的新位置来填补遮挡期间检测的空白,而也有不少研究侧重于生成更可区分的嵌入来在整个遮挡期间关联。尽管最近的一些工作试图同时解决这两个问题,但位置预测和嵌入关联仍被视为两个单独的任务,如何使它们相互受益尚未得到很好的探索。
常见的预测方法很少考虑对象之间的交互,因此在处理遮挡时位置预测是不够强的。在严重遮挡下做的预测可能会导致边界框漂移,即目标的预测位置开始跟随一个邻近的目标,然后由于边界框预测出错提取的嵌入也开始恶化,最终导致帧间关联错误。这种情况下,进行预测反而会对嵌入造成损害,而且,仅仅改善嵌入也只能减少关联阶段的错误而不能阻止位置预测的错误。也就是说,这类方法都是将位置预测和嵌入关联视作两个独立的问题,它们之间没有真正的协同作用。如下图(a)所示,位置预测和嵌入关联并没有在遮挡时从彼此中受益,随着跟踪的进行,目标的位置预测发生了漂移,提取的嵌入也含有了噪声。
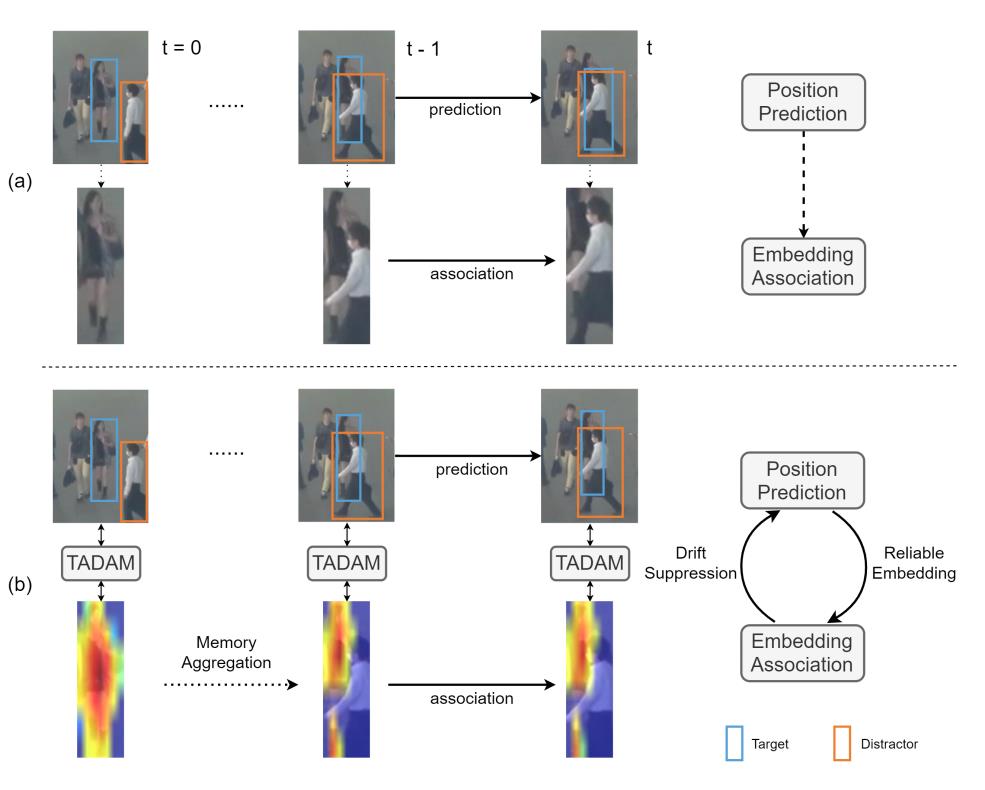
在这篇论文中,作者提出了一个统一的模型,将位置预测和嵌入关联联合优化彼此受益,增强了跟踪对于遮挡的鲁棒性并改善了跟踪的性能。为了实现真正的协同作用,作者让一个任务参与到另一个任务的过程中,这两个任务通过由目标注意力模块和干扰注意力模块以及判别性记忆聚合组成的链接桥接在一起。针对关联优化的身份嵌入不仅用于计算亲和度,还用于生成对目标的关注以及通过注意力模块抑制漂移。通过这种方式,位置预测配备了身份感知能力并对附近的物体变得敏感,在更严重的遮挡下可以执行更正确的预测而不会发生漂移。通过在遮挡期间更好的预测和对目标的关注,可以提取更高质量的嵌入。 这种更可靠的嵌入然后参与注意力生成以更好地关注目标。因此,位置预测和嵌入关联相互关联,从而形成互惠互利的正反馈循环。 身份感知记忆聚合进一步放大了协同作用,因为随着时间的推移积累的更丰富的整体嵌入能够产生更强大的注意力。因此,在有遮挡的复杂场景中的跟踪性能得到了提升。我们在统一的端到端模型下联合优化位置预测、嵌入关联和所有提出的模块。据作者所知,这篇论文是第一个在这两个任务上实现协同联合优化的。 大体的思路如上图的(b),上面的叙述还是比较多的,下面做一个简单的总结。
- 提出了一个统一的在线 MOT 模型,该模型在位置预测和嵌入关联之间带来了相互增益,从而实现了对遮挡的更强鲁棒性。
- 应用时间感知目标注意力和干扰注意力以及身份感知记忆聚合来链接这两个任务。
- 构建的TADAM跟踪器在MOTChallenge基准上获得了SOTA表现。
TADAM
作者设计了一个统一的模型,在位置预测和数据关联之间带来相互增益,从而增强了对遮挡的鲁棒性并提高了跟踪性能。为了实现这一点,作者引入了时间感知目标注意力和干扰物注意力以更好地关注目标并抑制干扰物的干扰,以及身份感知记忆聚合方案以生成更强大的注意力。作者将其根据设计的组件命名为TADAM,这里TA和DA而非你别表示目标注意力(target attention)和干扰物注意力(distractor attention),M则表示记忆聚合(memory aggregation)。上述提到的所有组件均使用同一个数据源统一训练,整个框架如下图所示,这一整节的叙述对照这个图理解起来会方便一些。
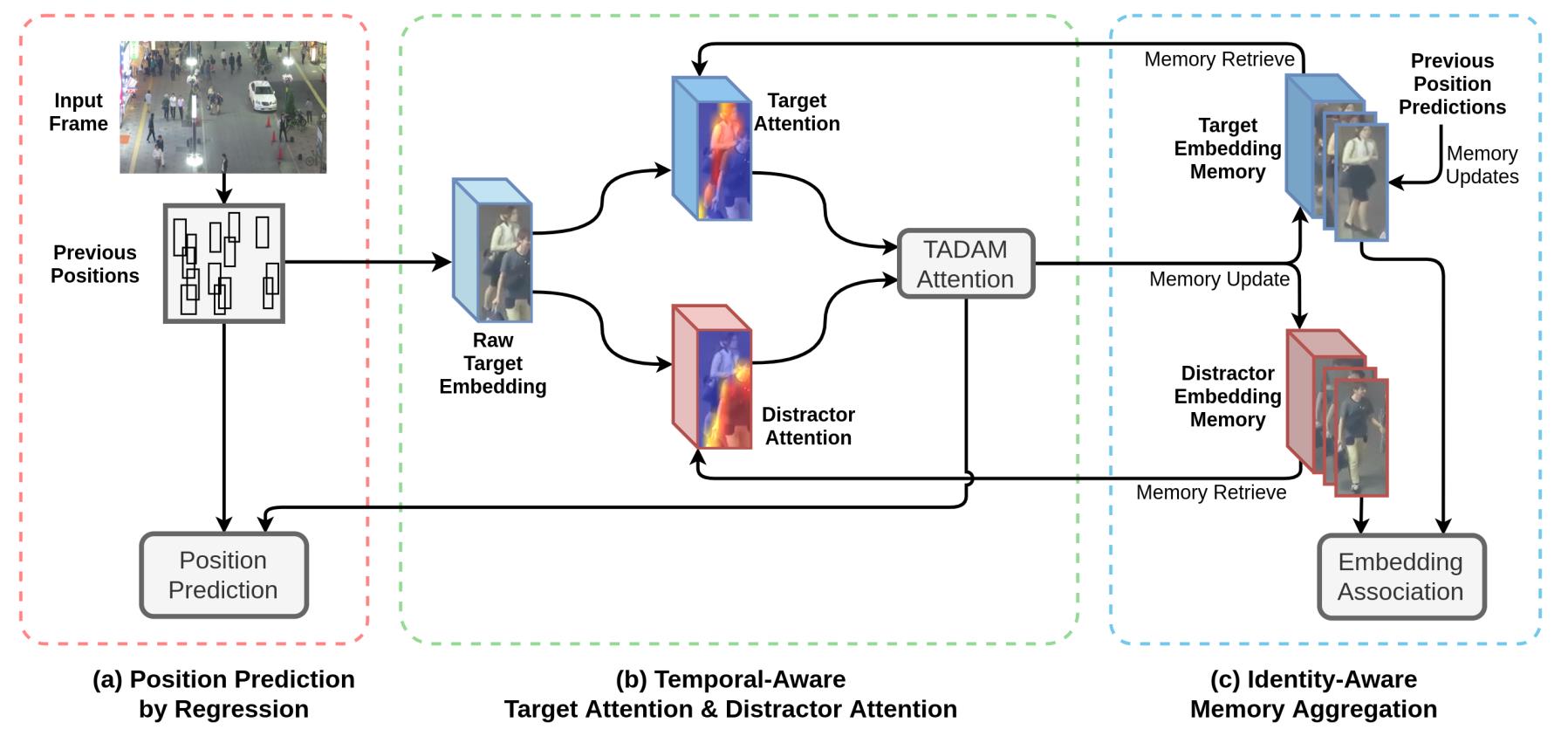
在进行后面的阐述之前,先对问题做一下简单的描述。一个被跟踪的目标在当前 t t t帧之前的轨迹可以记作 T t − 1 t a T_{t-1}^{ta} Tt−1ta,它在第 t − 1 t-1 t−1帧上的边框可以记为 B t − 1 t a B_{t-1}^{ta} Bt−1ta。其附近的一个干扰物可以描述为 T t − 1 d i T_{t-1}^{di} Tt−1di,其在 t − 1 t-1 t−1帧上的边界框相应的为 B t − 1 d i B_{t-1}^{di} Bt−1di。 F t t a F_t^{ta} Ftta表示的是这个目标在帧 t t t上预测位置处根据边框 B t − 1 t a B_{t-1}^{ta} Bt−1ta提取得到的特征。 E t t a E_t^{ta} Etta和 E t d i E_t^{di} Etdi表示目标及其干扰物当前帧上的身份嵌入,它们的历史嵌入参考则表示为 E r t a E_r^{ta} Erta和 E r d i E_r^{di} Erdi。
位置预测
作者采用Tracktor作为baseline,这是一个基于回归的位置预测跟踪器,它优于其他基于视觉线索的预测方法。该方法首先训练一个二阶段的Faster R-CNN检测器,其中RPN被训练用于粗糙的proposal框的生成,一个回归head和分类head被训练用于调整边框和推断框内目标的类别。在跟踪时,第一个阶段的RPN会被丢弃,利用训练好的回归head从其先前位置 B t − 1 t a B_{t-1}^{ta} Bt−1ta得到预测特征 F t t a F_t^{ta} Ftta来预测目标的新位置 B t t a B_t^{ta} Btta,分类head给出对应的置信度。上面框架图的(a)部分若不和其他部分相连,则描述了这种基于位置预测的跟踪过程。 E t t a E_t^{ta} Etta表示用于关联的嵌入,它随后在嵌入提取步骤获得。位置预测的能力主要来自于用给定的不太准确的框推断紧密拟合的边界框,并采用Faster R-CNN中的四个边的位移的smooth L1损失来训练,分类head则通过交叉熵来训练。这种位置预测方法摆脱了主动跟踪目标的数据关联,而通过匈牙利算法进行匹配仍然需要通过比较身份嵌入来搜索新检测中丢失目标的重新出现。这篇论文提出的方法目的在于在位置预测设计之上带来跨任务协同作用。
时间感知目标注意力和干扰物注意力
当对目标 T t a T^{ta} Tta从 t − 1 t-1 t−1帧到 t t t帧进行位置预测时,预测特征 F t t a F_t^{ta} Ftta是根据目标之前的边框 B t − 1 t a B_{t-1}^{ta} Bt−1ta再第 t t t帧上提取得到的,目标的新位置则通过 F t t a F_t^{ta} Ftta预测得到。但是,当一个干扰物 T d i T^{di} Tdi离目标很近并且其边界框 B t − 1 d i B_{t-1}^{di} Bt−1di和目标边界框 B t − 1 t a B_{t-1}^{ta} Bt−1ta有较大的重叠的时候,做出一个正确的预测可能是很难的。假定 T t a T^{ta} Tta被 T d i T^{di} Tdi遮挡,即 T d i T^{di} Tdi在目标的前面,那么预测的边框 T t a T^{ta} Tta将更接近 T d i T^{di} Tdi,这是因为 F t t a F_t^{ta} Ftta的很大一部分来自 F t d i F_t^{di} Ftdi,而这些特征实际上属于 T d i T^{di} Tdi。在这种场景下的连续位置预测可能会导致 B t t a B_t^{ta} Btta逐步偏移向 B t d i B_t^{di} Btdi。
为了克服这个问题,作者引入了一个target-attention(TA)模块来增强
F
t
t
a
F_t^{ta}
Ftta中属于
T
t
a
T^{ta}
Tta的区域,以及一个distractor-attention(DA)模块来抑制
F
t
t
a
F_t^{ta}
Ftta中属于
T
d
i
T^{di}
Tdi的部分。target attention由目标最新的原始身份嵌入
E
t
t
a
E_t^{ta}
Etta和目标的历史聚合嵌入参考
E
r
t
a
E_r^{ta}
Erta计算得到,而distractor attention则依据
E
t
d
i
E_t^{di}
Etdi和干扰物遮挡参考
E
r
d
i
E_r^{di}
Erdi 以上是关于TADAM解读的主要内容,如果未能解决你的问题,请参考以下文章