用户行为分析模型——路径分析
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用户行为分析模型——路径分析相关的知识,希望对你有一定的参考价值。
在网页或者营销渠道中,用户行为模型有比较多,基于渠道的,笔者觉得有:
| 渠道类型 | 渠道重要性 | 渠道跳转与流失 |
|---|---|---|
| 单渠道,多节点 | 路径分析,漏斗功能 | |
| 多渠道 | 归因分析 |
这里多渠道指的是,单渠道多节点的场景比较好理解,就是进入某个web \\ 小程序,在不同页面之间进行跳转,多渠道这里比较多的就是,同一用户在不同的较大的场景下的流转,比如在小红书种草 -> 微信好友推荐 -> 淘宝上买了。
归因分析是通过一定的逻辑方法,计算每个渠道、或者触点对最终结果贡献程度的方法。有一套合理的归因办法,才能科学地衡量不同渠道的广告价值,指导更好的投放。
其是衡量某一个渠道/触点价值的,没有考虑触点之间的跳转。
关于归因分析,之前笔者有整理:
多渠道归因分析(Attribution):传统归因(一)
本篇主要来看看路径/漏斗分析。
文章目录
1 路径与漏斗分析几个重要知识点
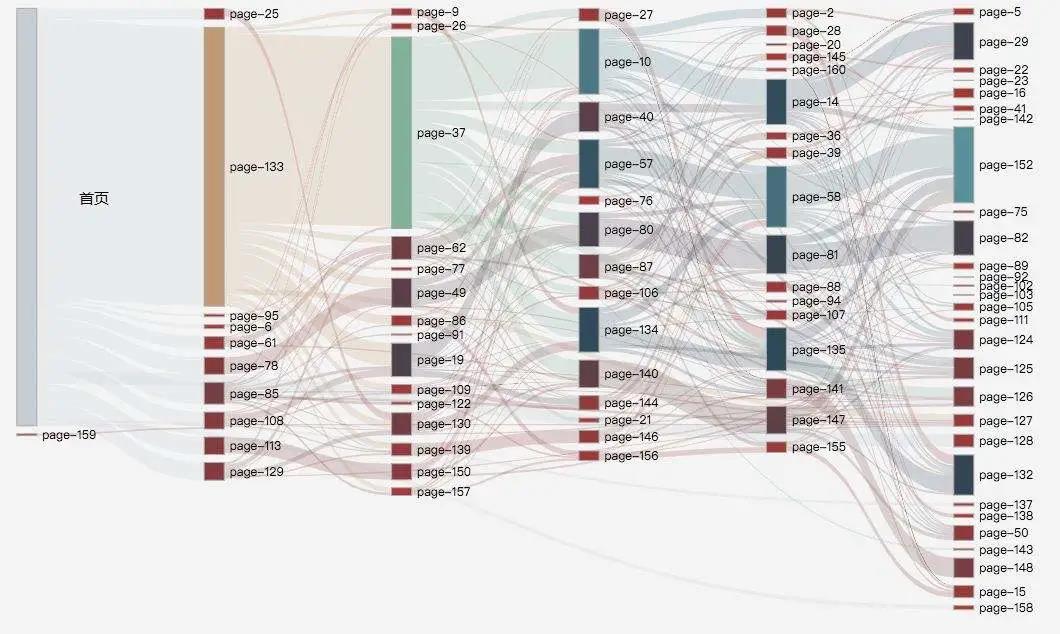
1.1 路径分析
通常用户在需要进行路径分析的场景时关注的主要问题:
- 按转换率从高至低排列在APP内用户的主要路径是什么;
- 用户在离开预想的路径后,实际走向是什么?
- 不同特征的用户行为路径有什么差异?
- 某个页面,引导用户去往哪个页面,对转化率最有利?
我们可以很好地发现用户的流转特点,发现用户是从哪些环节、哪些页面流失、或者发生了阻碍,从而有针对性地优化产品,提升业绩。
比如,我们发现很多用户在加购后没有进行支付,我们就可以通过路径分析,看看用户加购后,都去哪里了、发生了什么操作。如此,有可能找到支付率低的原因所在。
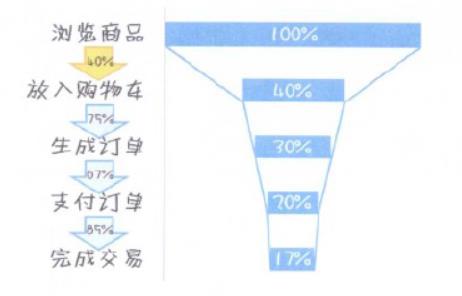
1.2 漏斗分析
漏斗分析是分析用户从起始到终点环节,过程当中每一步环节的转化(或者流失)情况。通过漏斗,可以找出全链路业务的问题环节所在,从而进行针对性优化。
几个特点:
- (1)是分多层、多环节的
- (2)各环节是有转化率(或者流失)效应的
- (3)环节之间有先后顺序
1.3 路径与漏斗分析的差异
漏斗分析是固化了具体的分析过程或者业务环节,然后分析这几个大的业务环节的转化;而路径分析,是固化了用户的路径顺序,在每个路径次序中,都包含了各个主要业务环节,因此在每一步中,出现的业务环节很有可能都是类似的。
总而言之,漏斗分析看重的是业务环节之间的留存关系,而路径分析看重的是用户在不同业务环节中的顺序及流失关系。
1.4 Session和Session Time
本模型中的Session Time的含义是,当两个行为间隔时间超过Session Time,我们便认为这两个行为不属于同一条路径。
使用更加灵活的Session划分,使得用户可以查询到在各种时间粒度(5,10,15,30,60分钟)的Session会话下,用户的页面转化信息。
假设有用户a和用户b,a用户当天发生的行为事件分别为 E1, E2, E3… , 对应的页面分别为P1, P2, P3… ,事件发生的时间分别为T1, T2, T3… ,选定的session间隔为tg。如图所示T4-T3>tg,所以P1,P2,P3被划分到了第一个Session,P4,P5被划分到了第二个Session,同理P6及后面的页面也被划分到了新的Session。
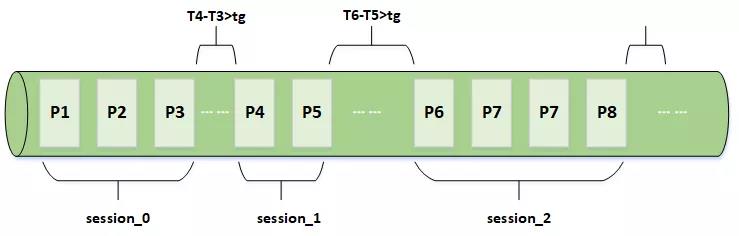
当然,如果支持选择不同粒度的session,数据计算要求较高
1.5 邻近页面去重
不同的事件可能对应同一页面,临近的相同页面需要被过滤掉,所以划分session之后需要做的就是相邻页面去重。
不过,这里是否去重还要根据实际业务场景来判定。

2 路径分析与桑基图
2.1 桑基图
桑基图主要是用来显示流向和数量。最大的特点,就是开始与结束是保持总量守恒的。
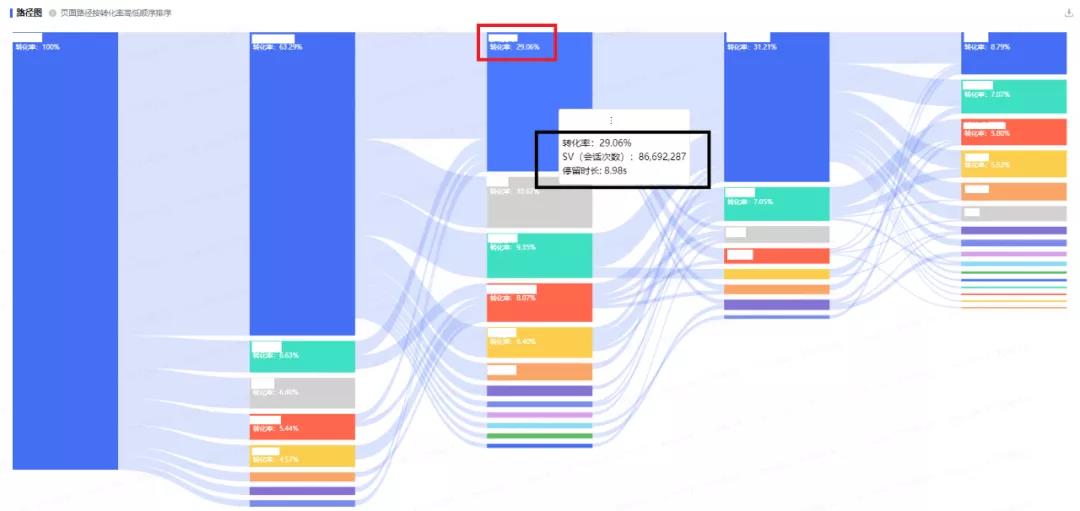
看出全体用户是从哪个地方来,经过一步一步的环节后,到了哪里去。另外一种和桑基图比较相似的图,是和弦图。如下示例:
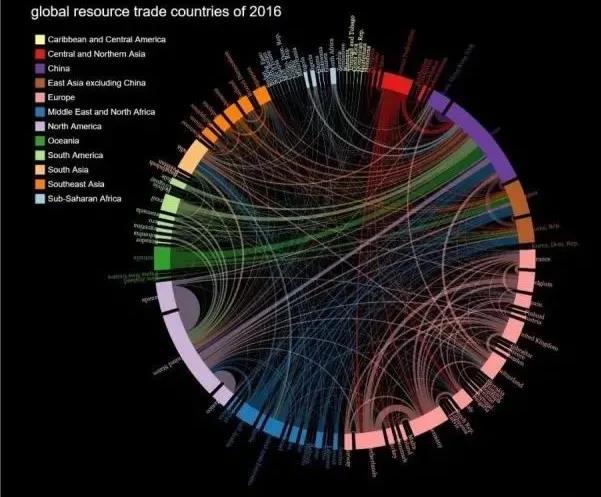
和弦图主要是呈现从一个内容转移到另外所有内容的情况,呈现不了桑基图多层环节的内容,仅仅是一个环节。
2.2 完整桑基图的数据结构与数据库选型
2.2.1 数据结构
来自vivo的这篇提到了他们超大规模工程化的数据结构,类似知识图谱图数据库的存储结构了。
构造桑基图可以简化为一个图的压缩存储问题。图通常由几个部分组成:
- 边(edge)
- 点(vertex)
- 权重(weight)
- 度(degree)
采用邻接表进行存储。邻接表是一种常用的图压缩存储结构,借助链表来保存图中的节点和边而忽略各节点之间不存在的边,从而对矩阵进行压缩。
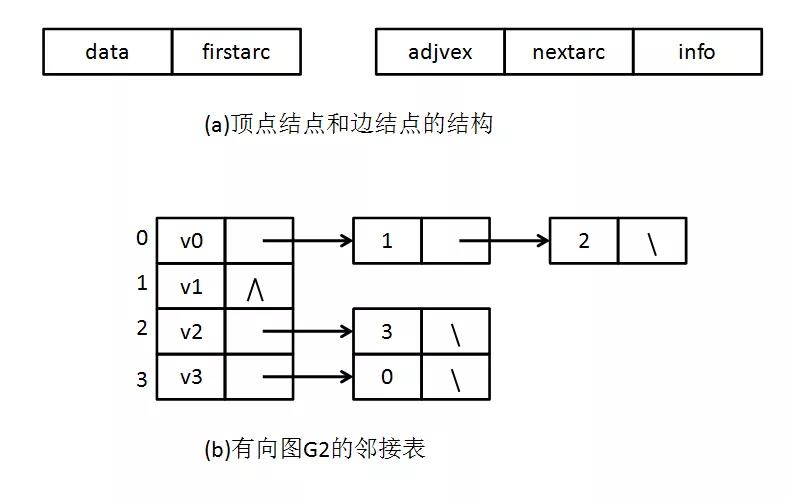
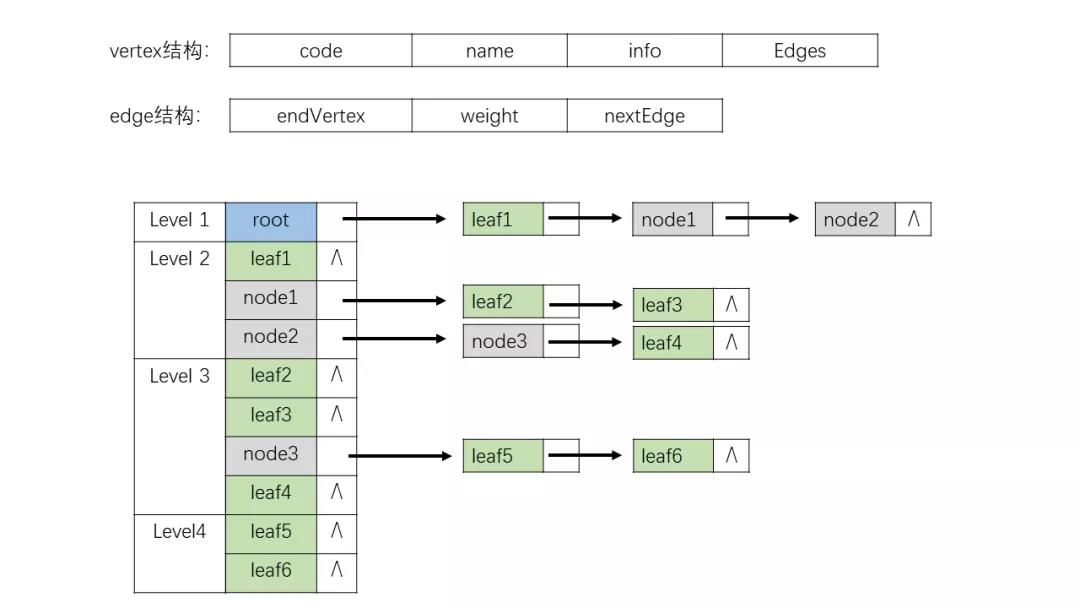
如下左图就是我们的邻接表设计。左侧顺序列表存储的是各个节点(Vertex),包含节点名称(name)、节点代码(code)等节点信息和一个指向边(Edge)列表的指针;每个节点(Vertex)指向一个边(Edge)链表,每条边保存的是当前边的权重、端点信息以及指向同节点下一条边的指针。
2.2.2 大规模数据库选型:ClickHouse
通过Spark分析计算的结果数据需要写入Clickhouse来线上服务,写入Hive来作为数据冷备份,可以进行Clickhouse的数据恢复。
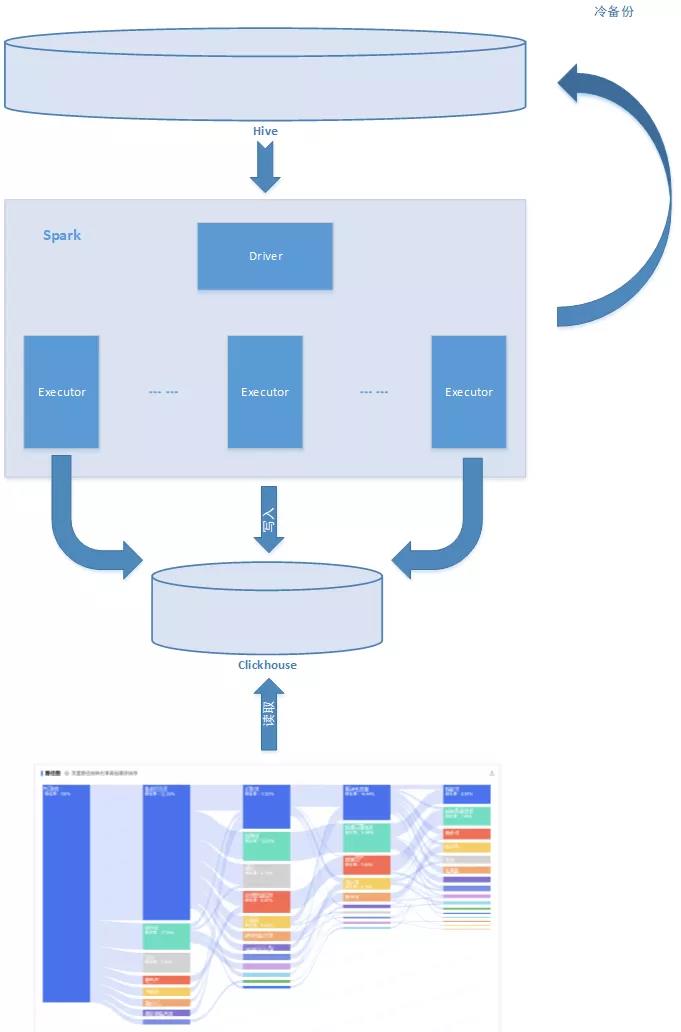
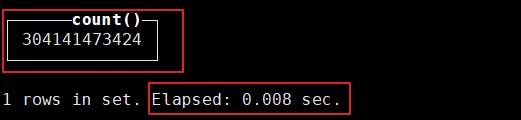
列存储的方式,对于这种超大规模数据的统计/计算查询数据非常便捷。
2.3 路径分级与树的剪枝
2.3.1 路径分级

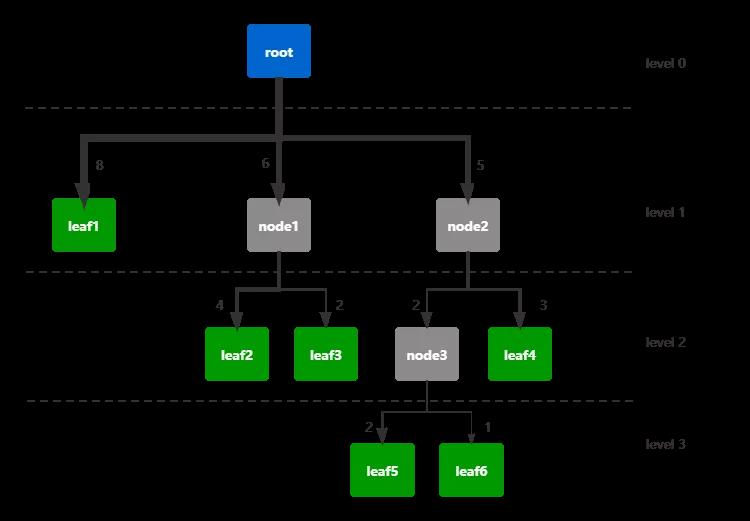
比如这个so的案例,p1 -> p2 -> p3 -> p4 - > p5 -> p6 -> p4就可以分成多级。
p1或p2或p3,单个节点构成了一级,
p1 -> p2 或 p2-> p3构成了二级,
p1 -> p2 -> p3 或 p5 -> p6 -> p4构成了三级
分级是为了更加细致地解析整个流程中,不同流程进度下的过程。
2.3.2 树的剪枝
剪枝是树的构造中一个重要的步骤,指删去一些不重要的节点来降低计算或搜索的复杂度。页面路径模型中,我们在剪枝环节对原始数据构造的树进行修整,去掉不符合条件的分支,来保证树中每条根节点到叶节点路径的完整性。
剪枝主要有几个方向:
- 清除孤立节点
- 过滤不完整路径
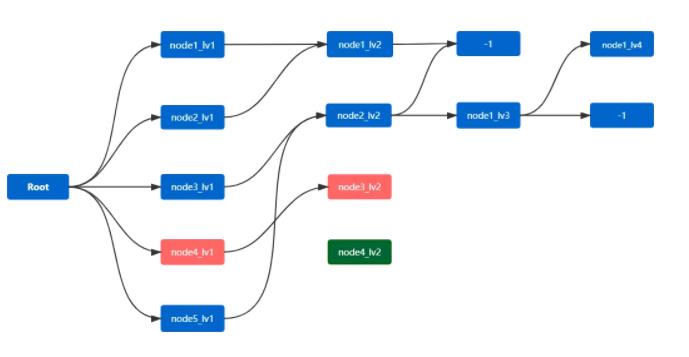
- 完整路径的定义:路径深度达到5且结束节点为退出或其它节点;路径深度未达到5且结束节点为退出。可见,图中标红的部分(node4_lv1 → node3_lv2)是一条不完整路径。
- 原始树中还会出现孤立节点(绿色节点node4_lv2)。这是由于在取数阶段,我们会对数据进行分层排序再取出,这样一来无法保证每层数据的关联性。
2.4 路径分析主要统计指标
- PV即Page View,访问次数,本模型中指的是一段时间内访问的次数;
- SV即Session View,会话次数,本模型中指出现过该访问路径的会话数。
如,
有路径一:A → B → C → D → A → B和路径二:A → B → D,
那么,
A → B的
PV为2+1=3,SV为1+1=2。
PV和SV是比较通常的指标,针对节点 / 路径会有不同的延申。
针对节点的PV / SV延申出:
- 节点pv/sv = 当前节点在当前层次中的pv/sv总和
- 节点转化率 = ( 节点pv/sv ) / ( 路径起始节点pv/sv )
- 节点间pv/sv = 上一级节点流向当前节点的pv/sv
- 节点间转化率 = ( 节点间pv/sv ) / ( 上一级节点pv/sv )
针对多级路径PV/SV延伸出:
- 页面转化率:假设有路径 A-B-C,A-D-C,A-B-D-C,其中ABCD分别是四个不同页面各自的转化
- 计算三级页面C的转化率:(所有节点深度为3的路径中三级页面是C的路径的pv/sv和)÷(一级页面的pv/sv)
- 路径转化率:假设有A-B-C,A-D-C,A-B-D-C,其中ABCD分别是四个不同页面,整个路径下的转化
- 计算A-B-C路径中B-C的转化率:(A-B-C这条路径的pv/sv)÷(所有节点深度为3的路径中二级页面是B的路径的pv/sv和)
3 获取路径的多级页面
vivo:用户行为分析模型实践(一)—— 路径分析模型这篇里面有比较详细的说明了他们获取多级页面的方式,不过不是特别让人看得懂。。
session = [['p1','p2','p3','p4','p5','p6','p4'],
['p1','p5','p1','p5','p1','p5','p1'],
['p6','p7','p8','p5','p9','p4'],
['p1','p4','p5','p1'],
['p4','p5','p2','p3','p5']]
sid = []
for nx,ps in enumerate(session):
for n,p in enumerate(ps):
prev_node = [-1 if r < 0 else ps[r] for r in range(n-4,n)]
now_node = ps[n]
next_node = [-1 if r > len(ps)-1 else ps[r] for r in range(n+1,n+5)]
sid.append([nx] + prev_node + [now_node] + next_node)
cols = ['path','page_id_previous4','page_id_previous3','page_id_previous2','page_id_previous1',
'page','page_id_next1', 'page_id_next2', 'page_id_next3', 'page_id_next4']
sid_data = pd.DataFrame(sid,columns = cols)
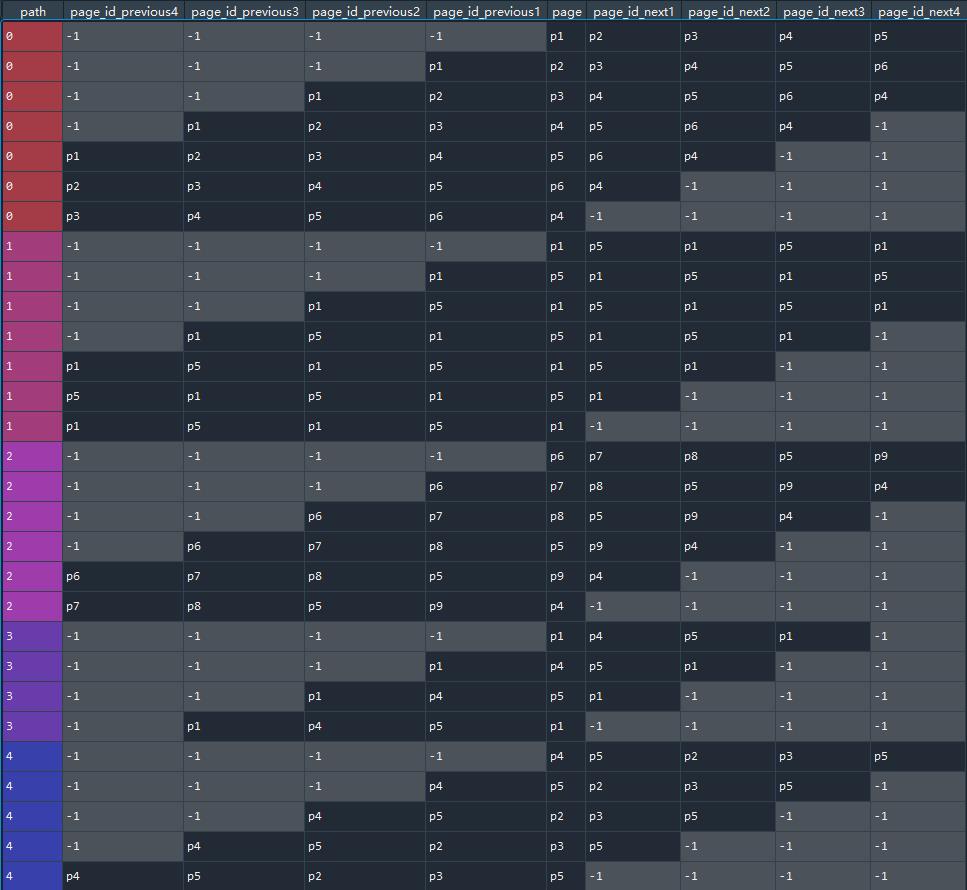
以上是按照下面的分发得出的:
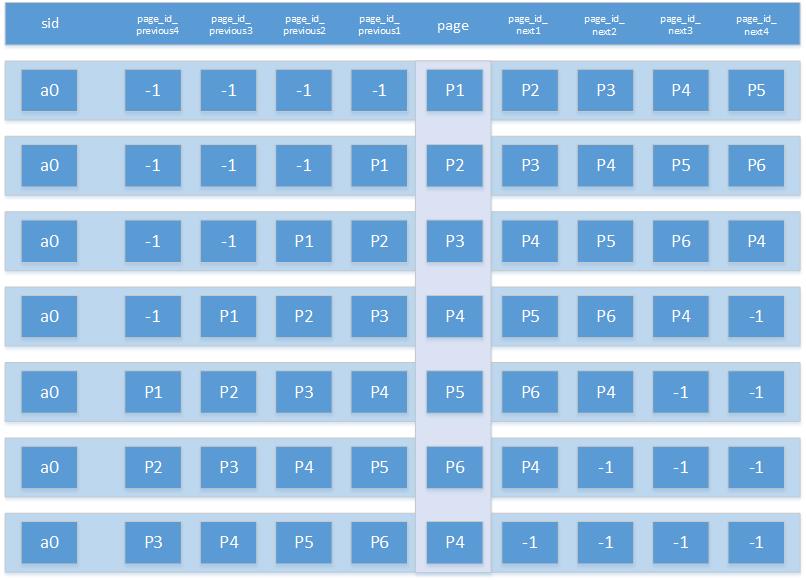
对于这个数据构造的方式,笔者也没细细琢磨,就先半路退堂,留下问题好了。。。
- 这里的负向路径是怎么记录的?貌似上图的,左侧负向最下面两排和右侧正向最上面两排是重复的?
- 这样列举多级,是不是还漏了很多?应该有20条左右
- 计算PV/SV什么方式统计的?按列,全部相等?这样计算不会很快吧?
参考文献
vivo:用户行为分析模型实践(一)—— 路径分析模型
路径分析:如何将用户的网站行为轨迹可视化呈现?
漏斗分析:你可能低估了它的复杂度(逻辑细节及产品化)
以上是关于用户行为分析模型——路径分析的主要内容,如果未能解决你的问题,请参考以下文章