Yolo 一小时学会基本操作
Posted 我是小白呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Yolo 一小时学会基本操作相关的知识,希望对你有一定的参考价值。
Yolo 一小时学会基本操作
Yolo
Yolo (You Only Look Once) 是目标检测 one-state 的一种神经网络. 今天我们用一小时讲述一下 Yolo 的基本操作.

指标
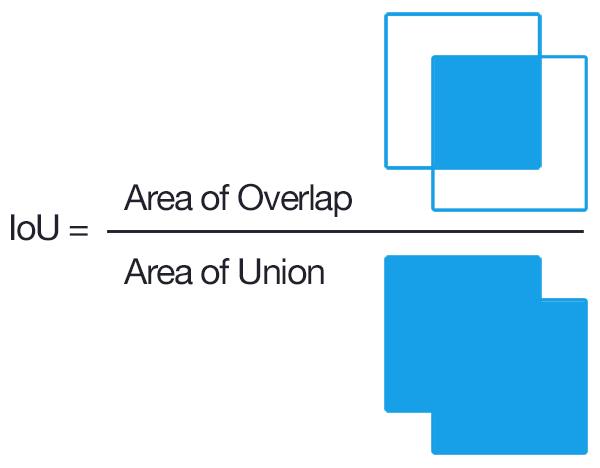
IOU
IOU (Intersection Over Union) 反应了预测位置和真实物位置的相似度.
IOU = 交集 / 并集:
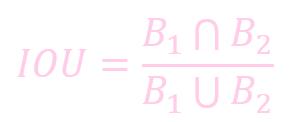
置信度
置信度 (box 内存在对象的概率 * box 与该对象实际 box 的 IOU)
公式:
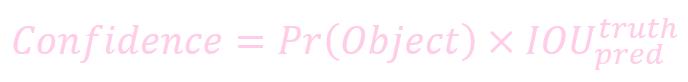
一个预测框的置信度 (Confidence) 代表了是否包含对象且位置正确的准确度.
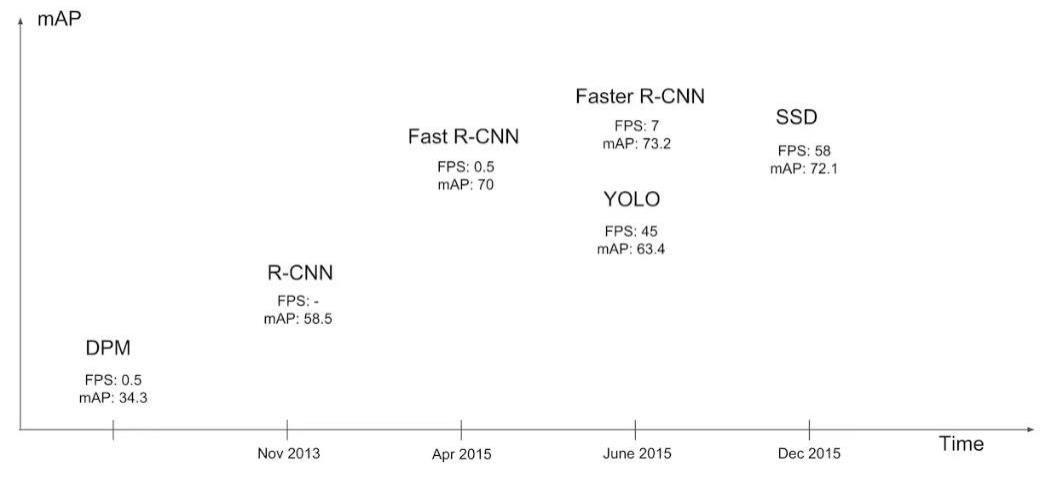
mAP
mAP (Mean Average Precision) 平均精度均值 是用来评价目标检测的常用指标.
mAP 是准确率和召回率的一个综合考量.
NMSE
NMSE (None-maximal Suppression) 非极大值抑制. 可以帮助我们消除多余的候选框.

B1,B2, B3, B4 四个框框都包含狗狗, 我们通过 NMSE 保留最大置信度 (B1), 去掉其他的候选框.
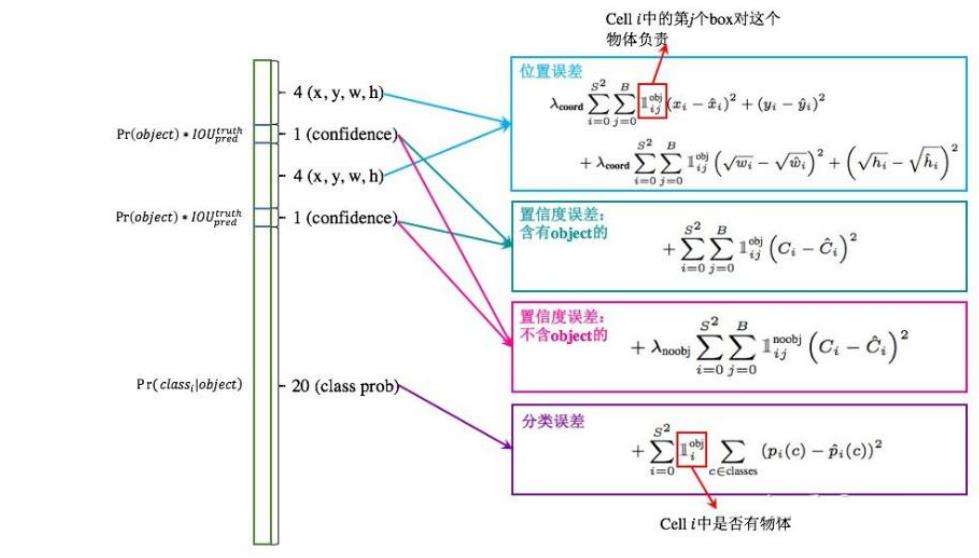
损失函数
Yolov1 vs Yolov2
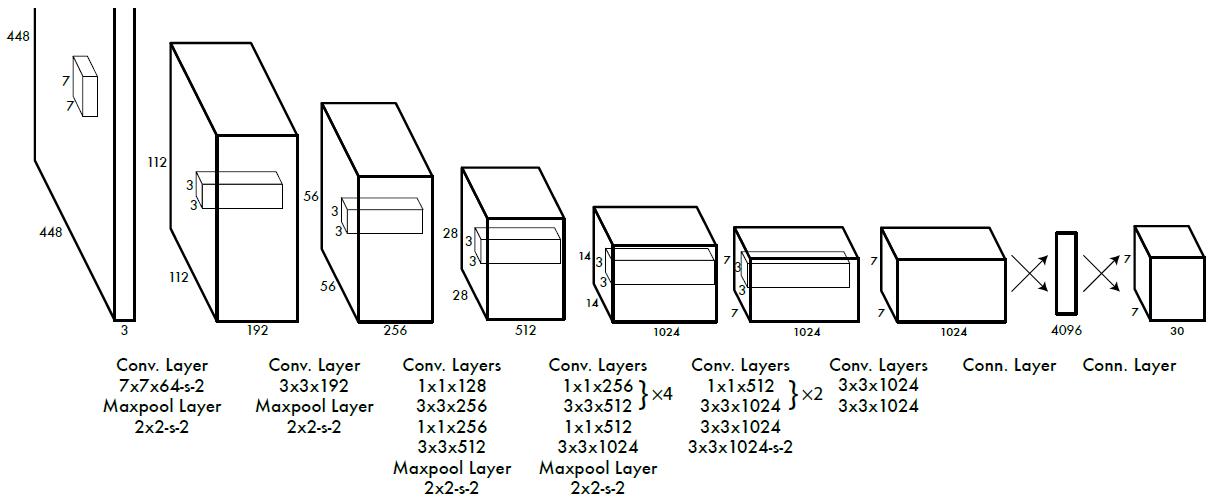
网络结构
v1:
v2:

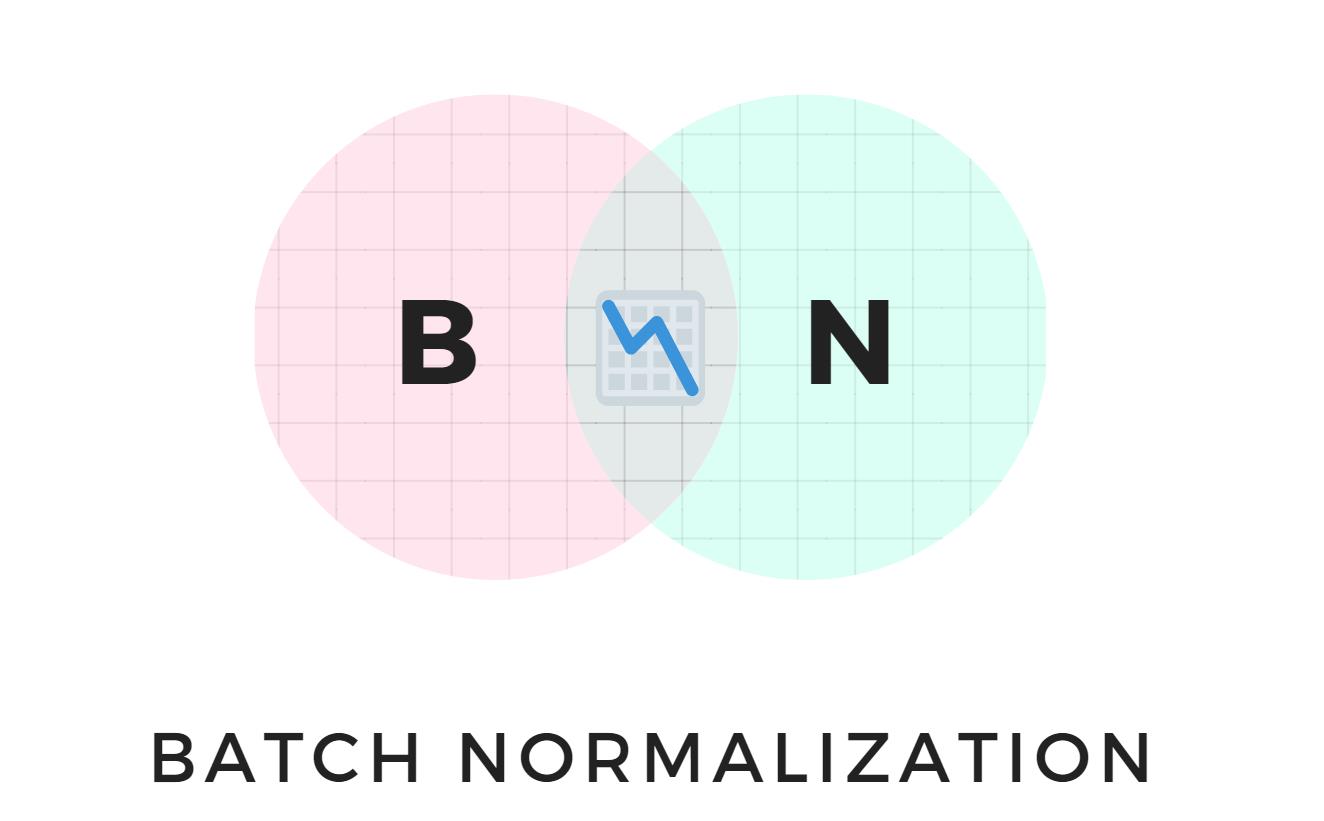
标准化
v2 版本舍弃 Dropout, 卷积后全部加入 Batch Normalization. 经过 Bach Normalization 处理后, 收敛相对更容易, 网络会提升 2.4% 的 mAP
高分辨率
- v1 训练时用的是 224 * 224, 测试使用 448 * 448. v2 训练时额外又进行了 10 次 448 * 448 的微调. 使用高分辨率分类器后, v2 的 mAP 提升了约 4%
无全连接层
v2 版本舍弃了 FC (Fully Connect) 层, 使用平均池化代替了全连接层.

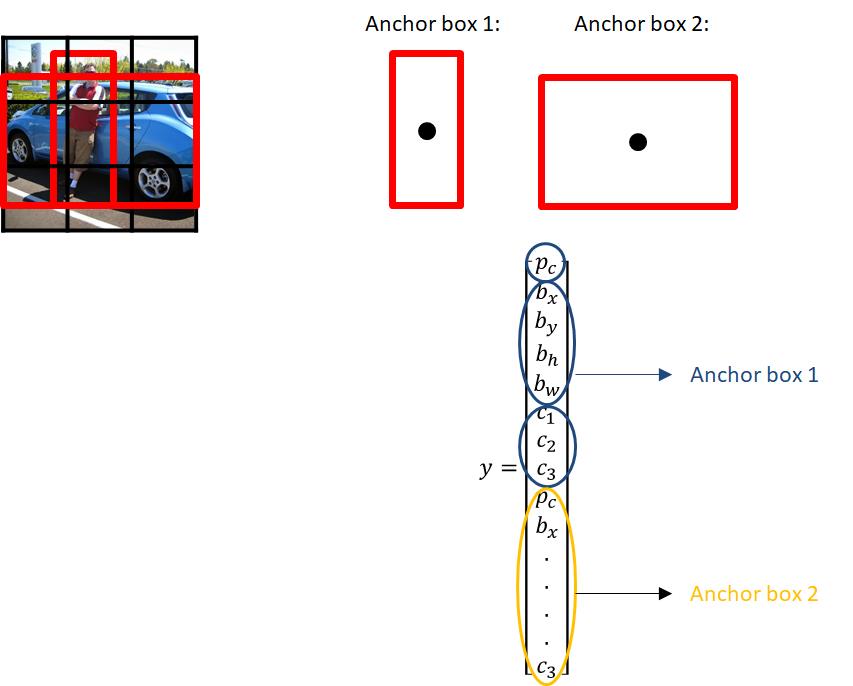
锚框
以往的模型一个窗口只能预测一个目标. 通过引入锚框 (anchor box), 在训练中我们将每一个锚框视为一个训练样本, 通过使用不同形状的锚框, 可以使得预测框更有针对性.
Yolov3 vs Yolov2
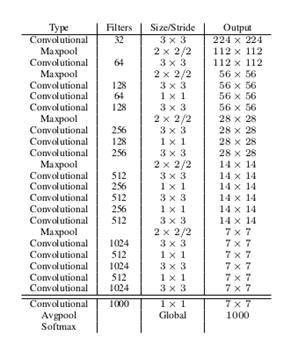
网络结构
v2 (Darknet-19):
v3 (Darknet-53):
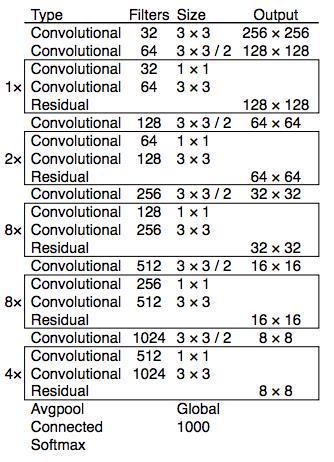
v3 去除了 maxpool, 通过步长为 2 的卷积来实现下采样.
Scale
为了能检测不同大小的物体, 设计了 3 种大小, 三种规格, 一共 9 种不同的先验框:
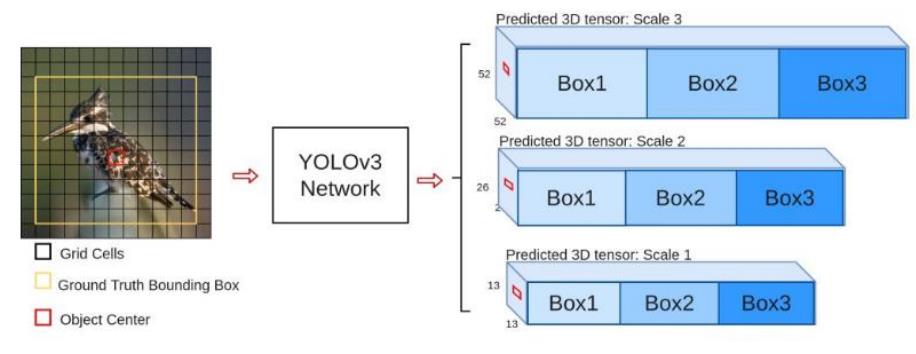
一个物体和哪个锚框匹配度最高就会被指定给这个锚框.

特征融合
对不同的特征图分别利用:
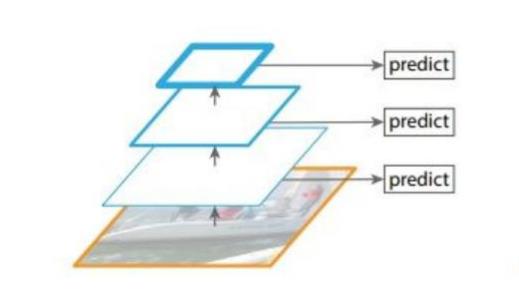
对不同的特征图进行融合:
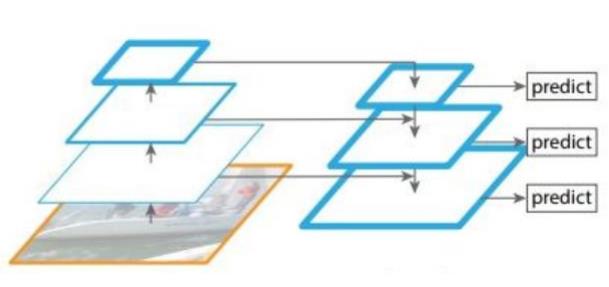
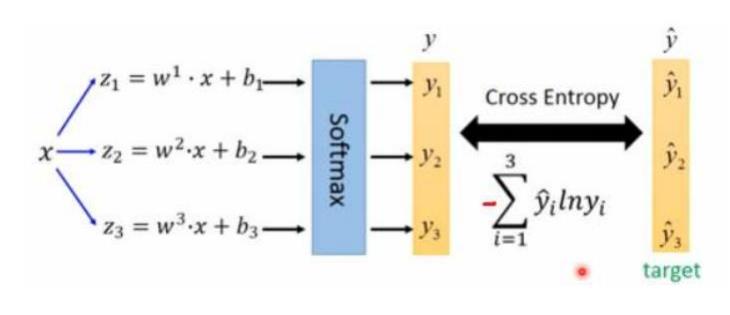
预测
使用 logistic 激活函数代替 softmax, 解决了物体检测任务中可能一个物体有多个标签的问题.
以上是关于Yolo 一小时学会基本操作的主要内容,如果未能解决你的问题,请参考以下文章