PyTorch ResNet 实现图片分类
Posted 我是小白呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch ResNet 实现图片分类相关的知识,希望对你有一定的参考价值。
建党 100 年
百年风雨, 金戈铁马.
忆往昔, 岁月峥嵘;
看今朝, 灿烂辉煌.

Resnet
深度残差网络 ResNet (Deep residual network) 和 Alexnet 一样是深度学习的一个里程碑.
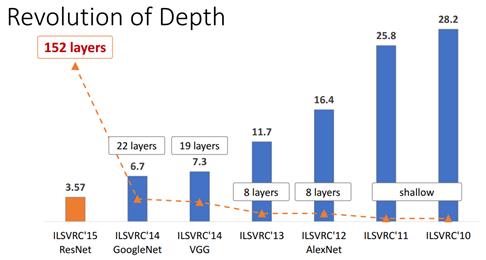
TensorFlow 版 Restnet 实现:
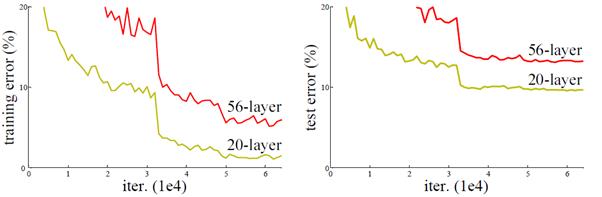
深度网络退化
当网络深度从 0 增加到 20 的时候, 结果会随着网络的深度而变好. 但当网络超过 20 层的时候, 结果会随着网络深度的增加而下降. 网络的层数越深, 梯度之间的相关性会越来越差, 模型也更难优化.
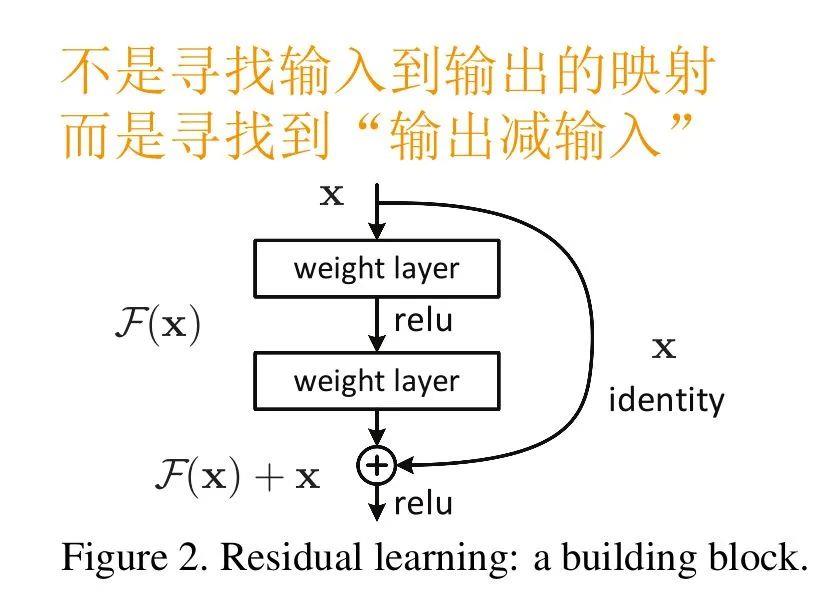
残差网络 (ResNet) 通过增加映射 (Identity) 来解决网络退化问题. H(x) = F(x) + x通过集合残差而不是恒等隐射, 保证了网络不会退化.
代码实现
残差块
class BasicBlock(torch.nn.Module):
"""残差块"""
def __init__(self, inplanes, planes, stride=1):
"""初始化"""
super(BasicBlock, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=inplanes, out_channels=planes, kernel_size=(3, 3),
stride=(stride, stride), padding=1) # 卷积层1
self.bn1 = torch.nn.BatchNorm2d(planes) # 标准化层1
self.conv2 = torch.nn.Conv2d(in_channels=planes, out_channels=planes, kernel_size=(3, 3), padding=1) # 卷积层2
self.bn2 = torch.nn.BatchNorm2d(planes) # 标准化层2
# 如果步长不为1, 用1*1的卷积实现下采样
if stride != 1:
self.downsample = torch.nn.Sequential(
# 下采样
torch.nn.Conv2d(in_channels=inplanes, out_channels=planes, kernel_size=(1, 1), stride=(stride, stride)))
else:
self.downsample = lambda x: x # 返回x
def forward(self, input):
"""前向传播"""
out = self.conv1(input)
out = self.bn1(out)
out = F.relu(out)
out = self.conv2(out)
out = self.bn2(out)
identity = self.downsample(input)
output = torch.add(out, identity)
output = F.relu(output)
return output
ResNet_18 = torch.nn.Sequential(
# 初始层
torch.nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1)), # 卷积
torch.nn.BatchNorm2d(64),
torch.nn.ReLU(),
torch.nn.MaxPool2d((2, 2)), # 池化
# 8个block(每个为两层)
BasicBlock(64, 64, stride=1),
BasicBlock(64, 64, stride=1),
BasicBlock(64, 128, stride=2),
BasicBlock(128, 128, stride=1),
BasicBlock(128, 256, stride=2),
BasicBlock(256, 256, stride=1),
BasicBlock(256, 512, stride=2),
BasicBlock(512, 512, stride=1),
torch.nn.AvgPool2d(2), # 池化
torch.nn.Flatten(), # 平铺层
# 全连接层
torch.nn.Linear(512, 100) # 100类
)
超参数
# 定义超参数
batch_size = 1024 # 一次训练的样本数目
learning_rate = 0.0001 # 学习率
iteration_num = 20 # 迭代次数
network = ResNet_18
optimizer = torch.optim.Adam(network.parameters(), lr=learning_rate) # 优化器
# GPU 加速
use_cuda = torch.cuda.is_available()
if use_cuda:
network.cuda()
print("是否使用 GPU 加速:", use_cuda)
print(summary(network, (3, 32, 32)))
ResNet 18 网络
ResNet_18 = torch.nn.Sequential(
# 初始层
torch.nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1)), # 卷积
torch.nn.BatchNorm2d(64),
torch.nn.ReLU(),
torch.nn.MaxPool2d((2, 2)), # 池化
# 8个block(每个为两层)
BasicBlock(64, 64, stride=1),
BasicBlock(64, 64, stride=1),
BasicBlock(64, 128, stride=2),
BasicBlock(128, 128, stride=1),
BasicBlock(128, 256, stride=2),
BasicBlock(256, 256, stride=1),
BasicBlock(256, 512, stride=2),
BasicBlock(512, 512, stride=1),
torch.nn.AvgPool2d(2), # 池化
torch.nn.Flatten(), # 平铺层
# 全连接层
torch.nn.Linear(512, 100) # 100类
)
获取数据
def get_data():
"""获取数据"""
# 获取测试集
train = torchvision.datasets.CIFAR100(root="./data", train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 转换成张量
torchvision.transforms.Normalize((0.1307,), (0.3081,)) # 标准化
]))
train_loader = DataLoader(train, batch_size=batch_size) # 分割测试集
# 获取测试集
test = torchvision.datasets.CIFAR100(root="./data", train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 转换成张量
torchvision.transforms.Normalize((0.1307,), (0.3081,)) # 标准化
]))
test_loader = DataLoader(test, batch_size=batch_size) # 分割训练
# 返回分割好的训练集和测试集
return train_loader, test_loader
训练
def train(model, epoch, train_loader):
"""训练"""
# 训练模式
model.train()
# 迭代
for step, (x, y) in enumerate(train_loader):
# 加速
if use_cuda:
model = model.cuda()
x, y = x.cuda(), y.cuda()
# 梯度清零
optimizer.zero_grad()
output = model(x)
# 计算损失
loss = F.cross_entropy(output, y)
# 反向传播
loss.backward()
# 更新梯度
optimizer.step()
# 打印损失
if step % 10 == 0:
print('Epoch: {}, Step {}, Loss: {}'.format(epoch, step, loss))
测试
def test(model, test_loader):
"""测试"""
# 测试模式
model.eval()
# 存放正确个数
correct = 0
with torch.no_grad():
for x, y in test_loader:
# 加速
if use_cuda:
model = model.cuda()
x, y = x.cuda(), y.cuda()
# 获取结果
output = model(x)
# 预测结果
pred = output.argmax(dim=1, keepdim=True)
# 计算准确个数
correct += pred.eq(y.view_as(pred)).sum().item()
# 计算准确率
accuracy = correct / len(test_loader.dataset) * 100
# 输出准确
print("Test Accuracy: {}%".format(accuracy))
完整代码

完整代码:
import torch
import torchvision
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchsummary import summary
class BasicBlock(torch.nn.Module):
"""残差块"""
def __init__(self, inplanes, planes, stride=1):
"""初始化"""
super(BasicBlock, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=inplanes, out_channels=planes, kernel_size=(3, 3),
stride=(stride, stride), padding=1) # 卷积层1
self.bn1 = torch.nn.BatchNorm2d(planes) # 标准化层1
self.conv2 = torch.nn.Conv2d(in_channels=planes, out_channels=planes, kernel_size=(3, 3), padding=1) # 卷积层2
self.bn2 = torch.nn.BatchNorm2d(planes) # 标准化层2
# 如果步长不为1, 用1*1的卷积实现下采样
if stride != 1:
self.downsample = torch.nn.Sequential(
# 下采样
torch.nn.Conv2d(in_channels=inplanes, out_channels=planes, kernel_size=(1, 1), stride=(stride, stride)))
else:
self.downsample = lambda x: x # 返回x
def forward(self, input):
"""前向传播"""
out = self.conv1(input)
out = self.bn1(out)
out = F.relu(out)
out = self.conv2(out)
out = self.bn2(out)
identity = self.downsample(input)
output = torch.add(out, identity)
output = F.relu(output)
return output
ResNet_18 = torch.nn.Sequential(
# 初始层
torch.nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1)), # 卷积
torch.nn.BatchNorm2d(64),
torch.nn.ReLU(),
torch.nn.MaxPool2d((2, 2)), # 池化
# 8个block(每个为两层)
BasicBlock(64, 64, stride=1),
BasicBlock(64, 64, stride=1),
BasicBlock(64, 128, stride=2),
BasicBlock(128, 128, stride=1),
BasicBlock(128, 256, stride=2),
BasicBlock(256, 256, stride=1),
BasicBlock(256, 512, stride=2),
BasicBlock(512, 512, stride=1),
torch.nn.AvgPool2d(2), # 池化
torch.nn.Flatten(), # 平铺层
# 全连接层
torch.nn.Linear(512, 100) # 100类
)
# 定义超参数
batch_size = 1024 # 一次训练的样本数目
learning_rate = 0.0001 # 学习率
iteration_num = 20 # 迭代次数
network = ResNet_18
optimizer = torch.optim.Adam(network.parameters(), lr=learning_rate) # 优化器
# GPU 加速
use_cuda = torch.cuda.is_available()
if use_cuda:
network.cuda()
print("是否使用 GPU 加速:", use_cuda)
print(summary(network, (3, 32, 32)))
def get_data():
"""获取数据"""
# 获取测试集
train = torchvision.datasets.CIFAR100(root="./data", train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 转换成张量
torchvision.transforms.Normalize((0.1307,), (0.3081,)) # 标准化
]))
train_loader = DataLoader(train, batch_size=batch_size) # 分割测试集
# 获取测试集
test = torchvision.datasets.CIFAR100(root="./data", train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 转换成张量
torchvision.transforms.Normalize((0.1307,), (0.3081,)) # 标准化
]))
test_loader = DataLoader(test, batch_size=batch_size) # 分割训练
# 返回分割好的训练集和测试集
return train_loader, test_loader
def train(model, epoch, train_loader):
"""训练"""
# 训练模式
model.train()
# 迭代
for step, (x, y) in enumerate(train_loader):
# 加速
if use_cuda:
model = model.cuda()
x, y = x.cuda(), y.cuda()
# 梯度清零
optimizer.zero_grad()
output = model(x)
# 计算损失
loss = F.cross_entropy(output, y)
# 反向传播
loss.backward()
# 更新梯度
optimizer.step()
# 打印损失
if step % 10 == 0:
print('Epoch: {}, Step {}, Loss: {}'.format(epoch, step, loss))
def test(model, test_loader):
"""测试"""
# 测试模式
model.eval()
# 存放正确个数
correct = 0
with torch.no_grad():
for x, y in test_loader:
# 加速
if use_cuda:
model = model.cuda()
x, y = x.cuda(), y.cuda()
# 获取结果
output = model(x)
# 预测结果
pred = output.argmax(dim=1, keepdim=True)
# 计算准确个数
correct += pred.eq(y.view_as(pred)).sum().item()
# 计算准确率
accuracy = correct / len(test_loader.dataset) * 100
# 输出准确
print("Test Accuracy: {}%".format(accuracy))
def main():
# 获取数据
train_loader, test_loader = get_data()
# 迭代
for epoch in range(iteration_num):
print("\\n================ epoch: {} ================".format(epoch))
train(network, epoch, train_loader)
test(network, test_loader)
if __name__ == "__main__":
main()
输出结果:
是否使用 GPU 加速: True
/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 30, 30] 1,792
BatchNorm2d-2 [-1, 64, 30, 30] 128
ReLU-3 [-1, 64, 30, 30] 0
MaxPool2d-4 [-1, 64, 15, 15] 0
Conv2d-5 [-1, 64, 15, 15] 36,928
BatchNorm2d-6 [-1, 64, 15, 15] 128
Conv2d-7 [-1, 64, 15, 15] 36,928
BatchNorm2d-8 [-1, 64, 15, 15] 128
BasicBlock-9 [-1, 64, 15, 15] 0
Conv2d-10 [-1, 64, 15, 15] 36,928
BatchNorm2d-11 [-1, 64, 15, 15] 128
Conv2d-12 [-1, 64, 15, 15] 36,928
BatchNorm2d-13 [-1, 64, 15, 15] 128
BasicBlock-14 [-1, 64, 15, 15] 0
Conv2d-15 [-1, 128, 8, 8] 73,856
BatchNorm2d-16 [-1, 128, 8, 8] 256
Conv2d-17 [-1, 128, 8, 8] 147,584
BatchNorm2d-18 [-1, 128, 8, 8] 256
Conv2d-19 [-1, 128, 8, 8] 8,320
BasicBlock-20 [-1, 128, 8, 8] 0
Conv2d-21 [-1, 128, 8, 8] 147,584
BatchNorm2d-22 [-1, 128, 8, 8] 256
Conv2d-23 [-1, 128, 8, 8] 147,584
BatchNorm2d-24 [-1, 128, 8, 8] 256
BasicBlock-25 [-1, 128, 8, 8] 0
Conv2d-26 [-1, 256, 4, 4] 295,168
BatchNorm2d-27 [-1, 256, 4, 4] 512
Conv2d-28 [-1, 256, 4, 4] 590,080
BatchNorm2d-29 [-1, 256, 4, 4] 512
Conv2d-30 [-1, 256, 4, 4] 33,024
BasicBlock-31 [-1, 256, 4, 4] 0
Conv2d-32 [-1, 256, 4, 4] 590,080
BatchNorm2d-33 [-1, 256, 4, 4] 512
Conv2d-34 [-1, 256, 4, 4] 590,080
BatchNorm2d-35 [-1, 256, 4, 4] 512
BasicBlock-36 [-1, 256, 4, 4] 0
Conv2d-37 [-1, 512, 2, 2] 1,180,160
BatchNorm2d-38 [-1, 512, 2, 2] 1,024
Conv2d-39 [-1, 512, 2, 2] 2,359,808
BatchNorm2d-40 [-1, 512, 2, 2] 1,024
Conv2d-41 [-1, 512, 2, 2] 131,584
BasicBlock-42 [-1, 512, 2, 2] 0
Conv2d-43 [-1, 512, 2, 2] 2,359,808
BatchNorm2d-44 [-1, 512, 2, 2] 1,024
Conv2d-45 [-1, 512, 2, 2] 2,359,808
BatchNorm2d-46 [-1, 512, 2, 2] 1,024
BasicBlock-47 [-1, 512, 2, 2] 0
AvgPool2d-48 [-1, 512, 1, 1] 0
Flatten-49 [-1, 512] 0
Linear-50 [-1, 100] 51,300
================================================================
Total params: 11,223,140
Trainable params: 11,223,140
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 3.74
Params size (MB): 42.81
Estimated Total Size (MB): 46.56
----------------------------------------------------------------
None
Downloading https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz to ./data/cifar-100-python.tar.gz
169001984/? [00:07<00:00, 23425059.51it/s]
Extracting ./data/cifar-100-python.tar.gz to ./data
Files already downloaded and verified
================ epoch: 0 ================
Epoch: 0, Step 0, Loss: 4.73184871673584
Epoch: 0, Step 10, Loss: 4.262868881225586
Epoch: 0, Step 20, Loss: 3.946244239807129
Epoch: 0, Step 30, Loss: 3.7039854526519775
Epoch: 0, Step 40, Loss: 3.5138051509857178
Test Accuracy: 17.16%
================ epoch: 1 ================
Epoch: 1, Step 0, Loss: 3.3631155490875244
Epoch: 1, Step 10, Loss: 3.183103561401367
Epoch: 1, Step 20, Loss: 3.0515971183776855
Epoch: 1, Step 30, Loss: 2.913054943084717
Epoch: 1, Step 40, Loss: 2.8454060554504395
Test Accuracy: 26.76%
================ epoch: 2 ================
Epoch: 2, Step 0, Loss: 2.764857053756714
Epoch: 2, Step 10, Loss: 2.5304853916168213
Epoch: 2, Step 20, Loss: 2.3920257091522217
Epoch: 2, Step 30, Loss: 2.294809341430664
Epoch: 2, Step 40, Loss: 2.2125251293182373
Test Accuracy: 30.599999999999998%
================ epoch: 3 ================
Epoch: 3, Step 0, Loss: 2.15826678276062
Epoch: 3, Step 10, Loss: 1.9255717992782593
Epoch: 3, Step 20, Loss: 1.7490493059158325
Epoch: 3, Step 30, Loss: 1.6468313932418823
Epoch: 3, Step 40, Loss: 1.5404233932495117
Test Accuracy: 29.659999999999997%
================ epoch: 4 ================
Epoch: 4, Step 0, Loss: 1.4881120920181274
Epoch: 4, Step 10, Loss: 1.3130300045013428
Epoch: 4, Step 20, Loss: 1.119794249534607
Epoch: 4, Step 30, Loss: 1.07780921459198
Epoch: 4, Step 40, Loss: 0.9983140826225281
Test Accuracy: 27.04%
================ epoch: 5 ================
Epoch: 5, Step 0, Loss: 1.0429306030273438
Epoch: 5, Step 10, Loss: 0.9188315868377686
Epoch: 5, Step 20, Loss: 0.7664494514465332
Epoch: 5, Step 30, Loss: 0.8060574531555176
Epoch: 5, Step 40, Loss: 0.7700539231300354
Test Accuracy: 25.629999999999995%
================ epoch: 6 ================
Epoch: 6, Step 0, Loss: 0.8620188236236572
Epoch: 6, Step 10, Loss: 0.8017312288284302
Epoch: 6, Step 20, Loss: 0.6923062801361084
Epoch: 6, Step 30, Loss: 0.6696692109107971
Epoch: 6, Step 40, Loss: 0.6102812886238098
Test Accuracy: 25.45%
================ epoch: 7 ================
Epoch: 7, Step 0, Loss: 0.5835701823234558
Epoch: 7, Step 10, Loss: 0.5514459013938904
Epoch: 7, Step 20, Loss: 0.4809255301952362
Epoch: 7, Step 30, Loss: 0.3889707326889038
Epoch: 7, Step 40, Loss: 0.42040011286735535
Test Accuracy: 25.3%
================ epoch: 8 ================
Epoch: 8, Step 0, Loss: 0.4036518931388855
Epoch: 8, Step 10, Loss: 0.31424838304519653
Epoch: 8, Step 20, Loss: 0.2538606524467468
Epoch: 8, Step 30, Loss: 0.26636990904808044
Epoch: 8, Step 40, Loss: 0.23289920389652252
Test Accuracy: 28.22%
================ epoch: 9 ================
Epoch: 9, Step 0, Loss: 0.20370212197303772
Epoch: 9, Step 10, Loss: 0.21275906264781952
Epoch: 9, Step 20, Loss: 0.1724529266357422
Epoch: 9, Step 30, Loss: 0.16944238543510437
Epoch: 9, Step 40, Loss: 0.11199608445167542
Test Accuracy: 28.17%
================ epoch: 10 ================
Epoch: 10, Step 0, Loss: 0.14693205058574677
Epoch: 10, Step 10, Loss: 0.11063629388809204
Epoch: 10, Step 20, Loss: 0.08746964484453201
Epoch: 10, Step 30, Loss: 0.08660224825143814
Epoch: 10, Step 40, Loss: 0.09079966694116592
Test Accuracy: 29.12%
================ epoch: 11 ================
Epoch: 11, Step 0, Loss: 0.07582048326730728
Epoch: 11, Step 10, Loss: 0.07523166388273239
Epoch: 11, Step 20, Loss: 0.05015444755554199
Epoch: 11, Step 30, Loss: 0.06376209855079651
Epoch: 11, Step 40, Loss: 0.047050636261701584
Test Accuracy: 30.159999999999997%
================ epoch: 12 ================
Epoch: 12, Step 0, Loss: 0.03873936086893082
Epoch: 12, Step 10, Loss: 0.036511268466711044
Epoch: 12, Step 20, Loss: 0.03504694253206253
Epoch: 12, Step 30, Loss: 0.03236941248178482
Epoch: 12, Step 40, Loss: 0.04149263724684715
Test Accuracy: 30.69%
================ epoch: 13 ================
Epoch: 13, Step 0, Loss: 0.02524631842970848
Epoch: 13, Step 10, Loss: 0.02024298906326294
Epoch: 13, Step 20, Loss: 0.01565425843000412
Epoch: 13, Step 30, Loss: 0.03372647985816002
Epoch: 13, Step 40, Loss: 0.03173805773258209
Test Accuracy: 30.61%
================ epoch: 14 ================
Epoch: 14, Step 0, Loss: 0.013597095385193825
Epoch: 14, Step 10, Loss: 0.014107376337051392
Epoch: 14, Step 20, Loss: 0.010056688450276852
Epoch: 14, Step 30, Loss: 0.016869302839040756
Epoch: 14, Step 40, Loss: 0.016789773479104042
Test Accuracy: 30.79%
================ epoch: 15 ================
Epoch: 15, Step 0, Loss: 0.00870730821043253
Epoch: 15, Step 10, Loss: 0.0070304274559021
Epoch: 15, Step 20, Loss: 0.005506859626621008
Epoch: 15, Step 30, Loss: 0.02930188737809658
Epoch: 15, Step 40, Loss: 0.013658527284860611
Test Accuracy: 30.990000000000002%
================ epoch: 16 ================
Epoch: 16, Step 0, Loss: 0.006122640334069729
Epoch: 16, Step 10, Loss: 0.008687378838658333
Epoch: 16, Step 20, Loss: 0.008756318129599094
Epoch: 16, Step 30, Loss: 0.011087586171925068
Epoch: 16, Step 40, Loss: 0.011925156228244305
Test Accuracy: 31.25%
================ epoch: 17 ================
Epoch: 17, Step 0, Loss: 0.00833406113088131
Epoch: 17, Step 10, Loss: 0.004966908134520054
Epoch: 17, Step 20, Loss: 0.003708316246047616
Epoch: 17, Step 30, Loss: 0.020299237221479416
Epoch: 17, Step 40, Loss: 0.010047768242657185
Test Accuracy: 31.540000000000003%
================ epoch: 18 ================
Epoch: 18, Step 0, Loss: 0.0037587652914226055
Epoch: 18, Step 10, Loss: 0.0033208071254193783
Epoch: 18, Step 20, Loss: 0.004131313879042864
Epoch: 18, Step 30, Loss: 0.012251097708940506
Epoch: 18, Step 40, Loss: 0.00844736211001873
Test Accuracy: 31.8%
================ epoch: 19 ================
Epoch: 19, Step 0, Loss: 0.0030041378922760487
Epoch: 19, Step 10, Loss: 0.0028436880093067884
Epoch: 19, Step 20, Loss: 0.0026263371109962463
Epoch: 19, Step 30, Loss: 0.01706080697476864
Epoch: 19, Step 40, Loss: 0.007125745993107557
Test Accuracy: 31.72%

以上是关于PyTorch ResNet 实现图片分类的主要内容,如果未能解决你的问题,请参考以下文章