《计算机网络自顶向下方法》读书笔记:传输层
Posted 思源湖的鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《计算机网络自顶向下方法》读书笔记:传输层相关的知识,希望对你有一定的参考价值。
前言
打算系统学习下计算机网络,就来翻阅经典的自顶向下
本篇是第三章传输层(书中翻译为运输层,故下面运输层和传输层可能会同时出现,anyway反正一个意思),主要关注TCP和UDP,还有注意拥塞控制
资源:
- 书是第7版中文电子书:https://pan.baidu.com/s/1PidIzLmFVWAb8T74GyVGlQ 密码: bhob
- 网站是2021年更新的第8版:https://www-net.cs.umass.edu/kurose_ross/interactive/
1、概述
传输层协议为运行在不同主机上的应用进程之间提供了逻辑通信(logic communication) 功能,是在端系统中而不是在路由器中实现的
为了简化术语,我们将运输层分组称为报文段(segment)。然而,因特网文献(如 RFC文档)也将TCP的运输层分组称为报文段,而常将UDP的分组称为数据报(datagram)
主机间交付扩展到进程间交付被称为运输层的多路复用 (transport-layer multiplexing)与多路分解(demultiplexing)
传输层协议支持的应用层协议如图所示:
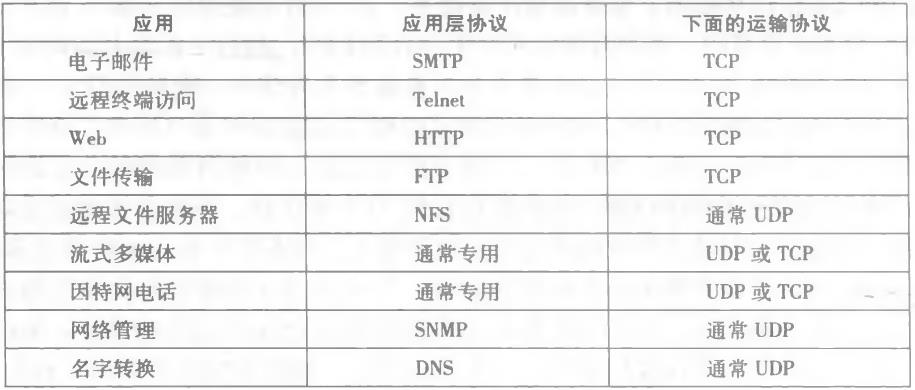
2、多路复用与多路分解
我们考虑接收主机怎样将一个到达的运输层报文段定向到适当的套接字。为此目的,每个运输层报文段中具有几个字段。在接收端,运输层检查这些字段,标识出接收套接字,进而将报文段定向到该套接字
- 多路分解(demultiplexing):将运输层报文段中的数据交付到正确的套接字
- 多路复用(nmhiplexing):在源主机从不同套接字中收集数据块,并为每个数据块封装上首部信息(这将在以后用于分解)从而生成报文段,然后将报文段传递到网络层
(1)无连接的多路复用与多路分解
在主机A中的一个进程具有UDP端口 19157,它要发送一个应用程序数据块给位于主机 B中的另一进程,该进程具有UDP端口 46428
- 主机A中的运输层创建一个运输层报文段,其中包括应用程序数据、源端口号(19157)、目的端口号(46428)和两个其他值
- 运输层将得到的报文段传递到网络层。网络层将该报文段封装到一个IP数据报中,并尽力而为地将报文段交付给接收主机
- 如果该报文段到达接收主机B,接收主机运输层就检查该报文段中的目的端口号(46428) 并将该报文段交付给端口号46428所标识的套接字
- 值得注意的是,主机B能够运行多个进程,每个进程有自己的UDP套接字及相应的端口号
- 当UDP报文段从网络到达时,主机B通过检查该报文段中的目的端口号,将每个报文段定向(分解)到相 应的套接字
(2)面向连接的多路复用与多路分解
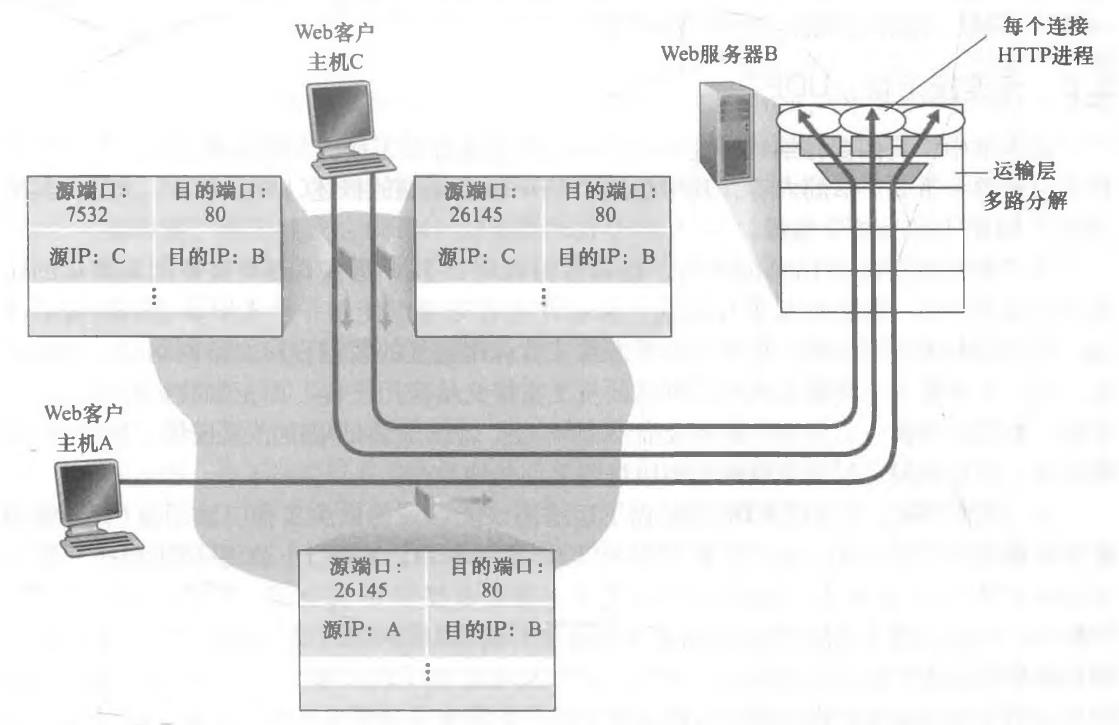
3、UDP
由[RFC 768]定义的UDP只是做了运输协议能够做的最少工作。除了复用/分解功 能及少量的差错检测外,它几乎没有对IP增加别的东西
特性:
- 关于发送什么数据以及何时发送的应用层控制更为精细
- 无须建立连接
- 也就无需维护连接状态
- 分组首部开销小,只要8字节
(1)报文
简单的一批,就是源端口和目的端口,然后总长度和校验
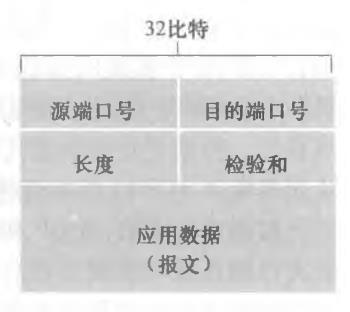
(2)校验和

4、可靠数据传输原理
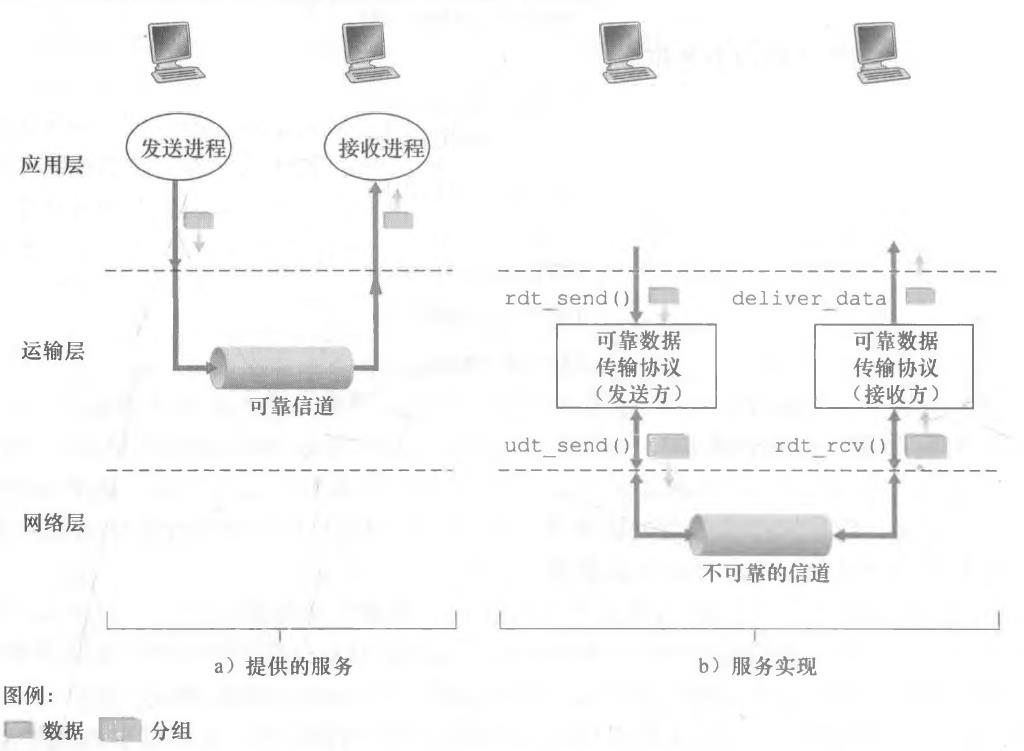
本节仅考虑可靠数据传输协议(reliable data transfer protocol)的单向数据传输(unidirectional data transfer)的情况
(1)构造可靠数据传输协议
这里有点意思,从第一版开始,一步步到最新的
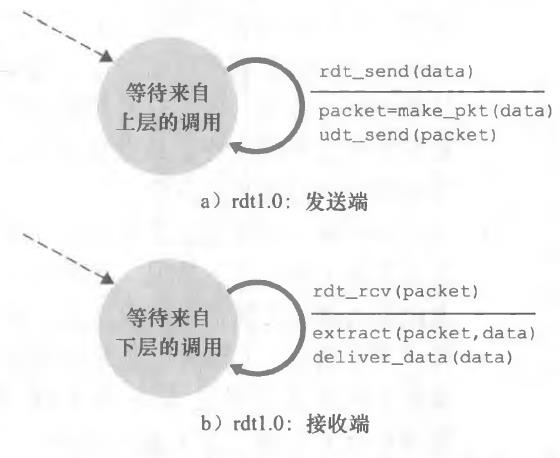
1、经完全可靠信道的可靠数据传输:rdt1.0
考虑底层信道是完全可靠,rdtl. 0发送方和接收方的有限状态机(Finite-State Machine, FSM)如图所示:
- 发送端只通过rdt_send(data)事件接受来自较高层的数据,产生一个包含该数据的分组(经由make-pkt (data)动作),并将分组发送到信道中。实际上,rdt_send(data)事件是由较高层应用的过程调用产生的
- 接收端,rdt通过rdt_rcv( packet)事件从底层信道接收一个分组,从分组中取岀数据 (经由extract(packet, data)动作),并将数据上传给较高层(通过deliver_data( dat3)动作)。 实际上,rdt_rcv( packet)事件是由较低层协议的过程调用产生的
2、经具有比特差错信道的可靠数据传输:rdt2.0
底层信道分组中的比特可能受损,这就引出了自动重传请求
(Automatic Repeat reQuest, ARQ)协议:
- 差错检测:使接收方检测到何时出现了比特差错
- 接收方反馈:发送方要了解接收方情况(此时为分组是否被正确接收)的唯一途径就是让接收方提供明确的反馈信息给发送方。在口述报文情况下回答的“肯定确认”(ACK) 和“否定确认” (NAK)就是这种反馈的例子。理论上,这些分组只需要一个比特长;如用0表示NAK,用1表示ACK
- 重传:接收方收到有差错的分组时,发送方将重传该分组文
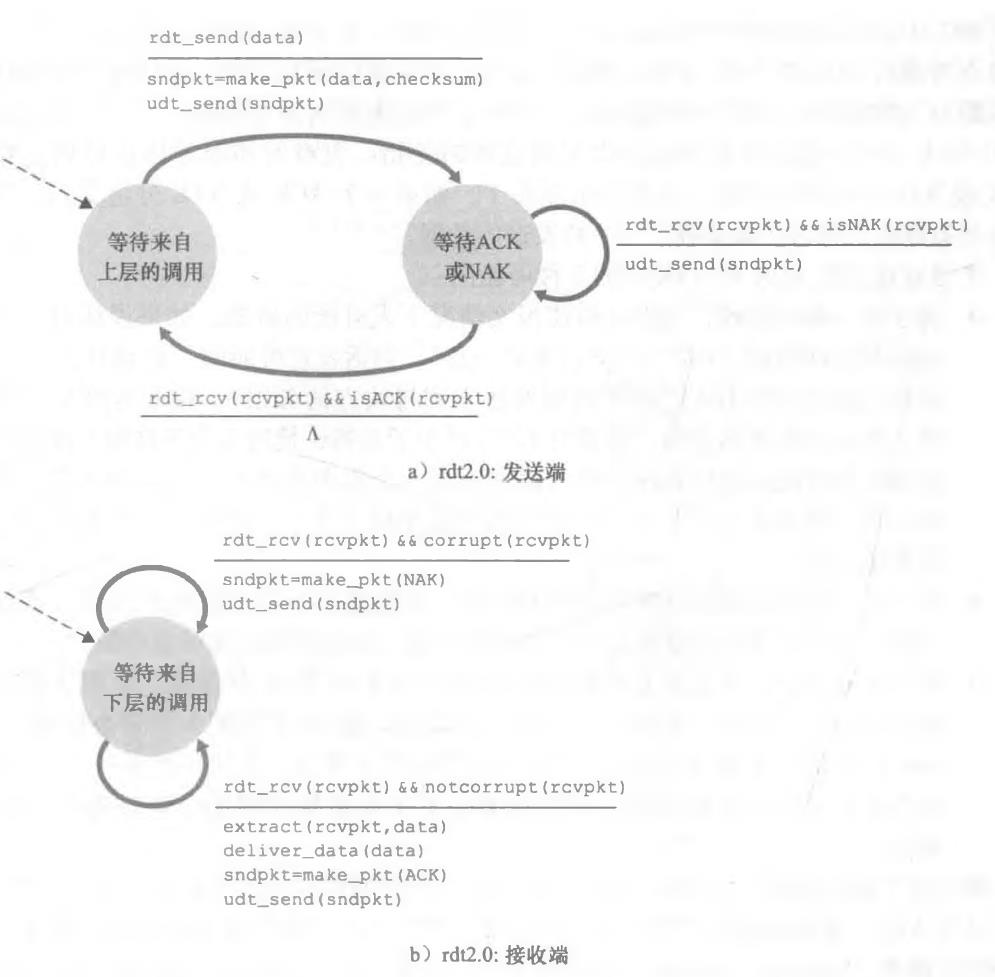
为了防范ACK和NAK损坏,做个小改进
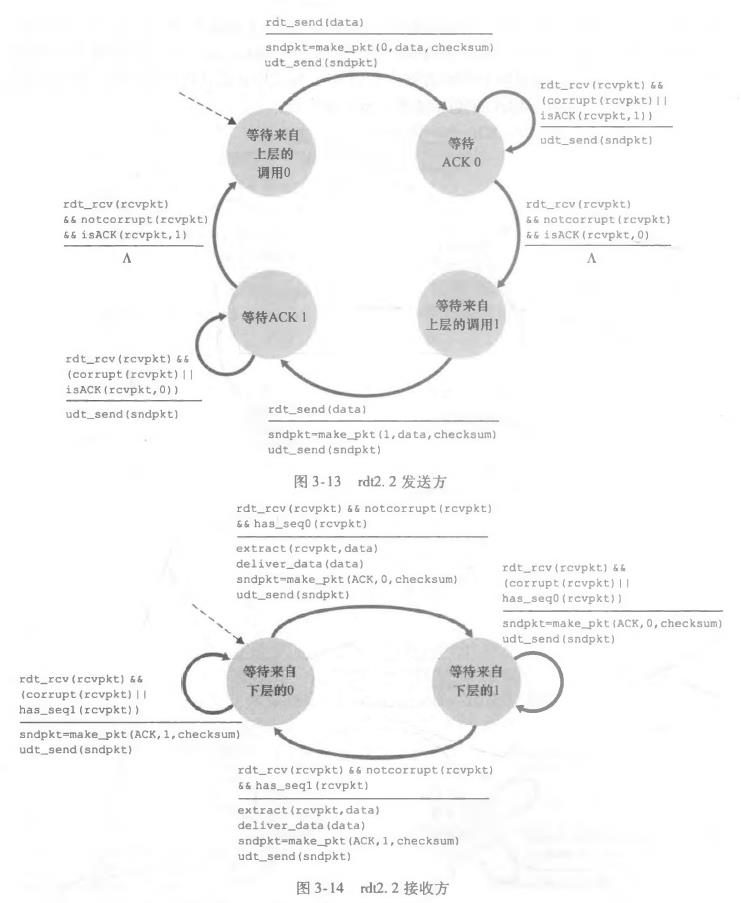
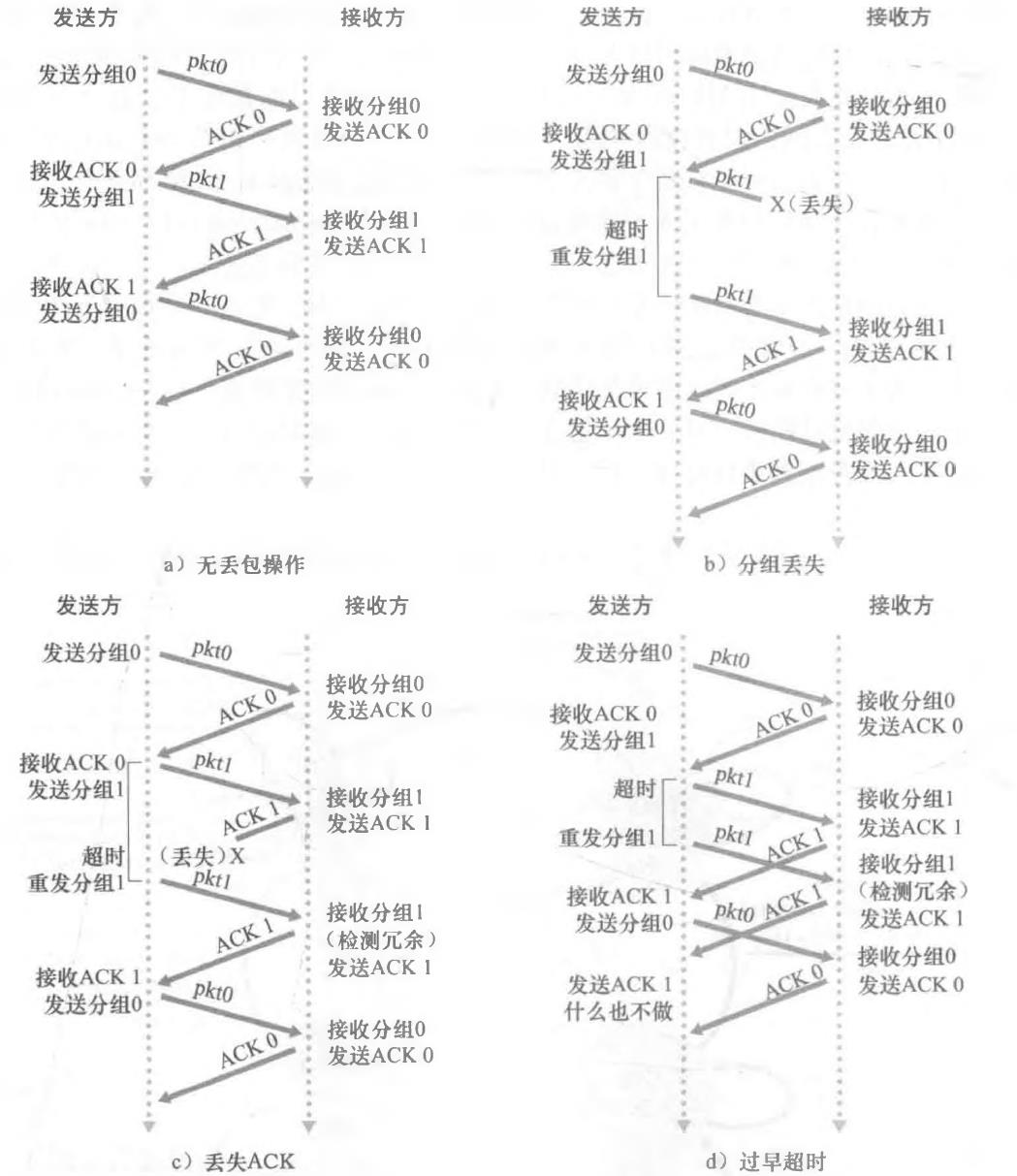
3、经具有比特差错的丢包信道的可靠数据传输:rdt3.0
于是有了基于时间的重传机制
(2)流水线可靠数据传输协议
上面这个rdt3.0似乎很棒了,但它是个停等协议,有效利用大概是万分之一。对比流水线,哪个更润显而易见,于是有
- 增加序号范围,因为每个输送中的分组(不计算重传的)必须有一个唯一的 序号,而且也许有多个在输送中的未确认报文
- 协议的发送方和接收方两端得缓存多个分组
- 所需序号范围和对缓冲的要求取决于数据传输协议如何处理丢失、损坏及延时过大的分组。解决流水线的差错恢复有两种基本方法是:回退/V步(Go-Back-N, GBN)和选择重传(Selective Repeat, SR)
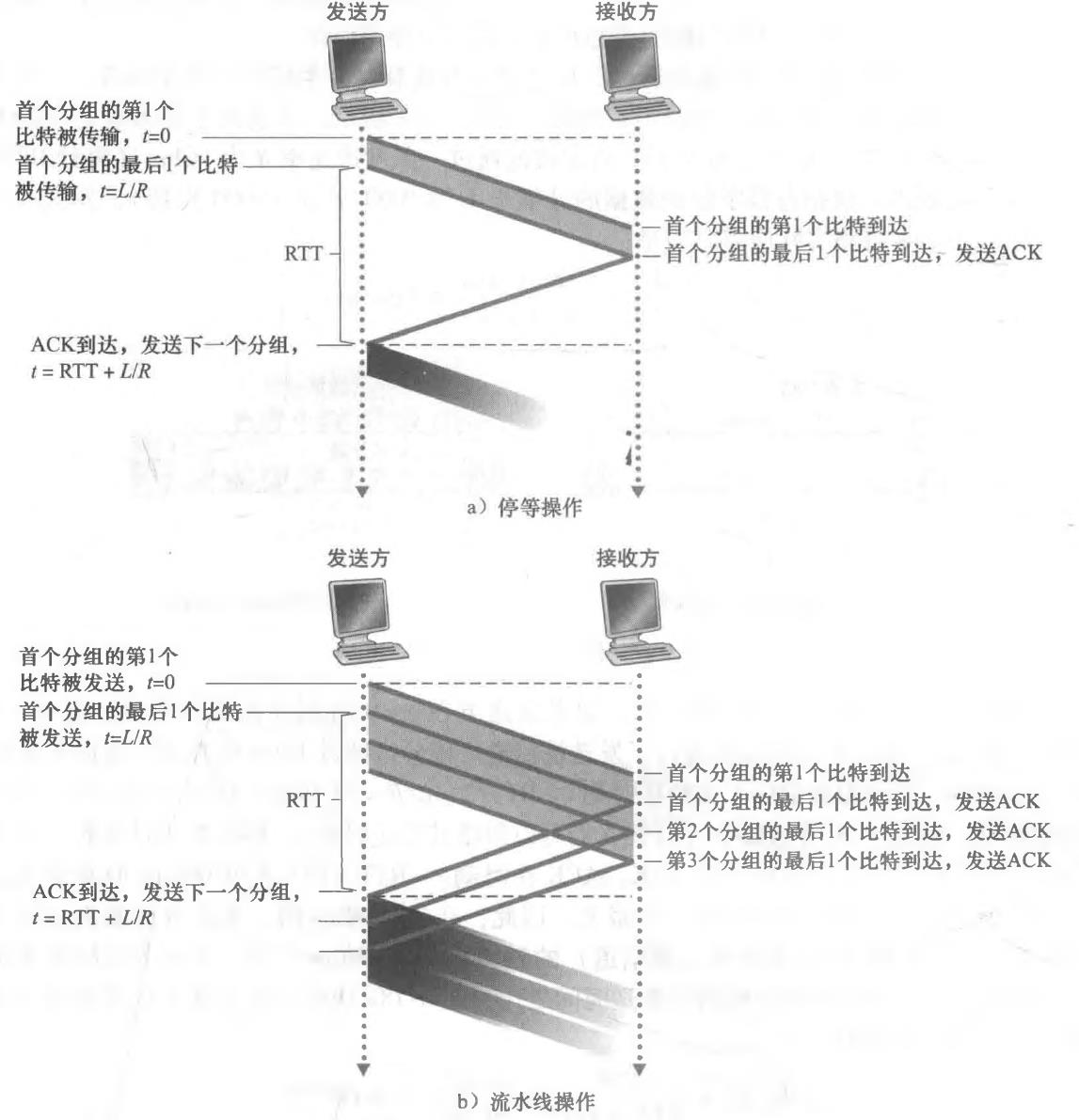
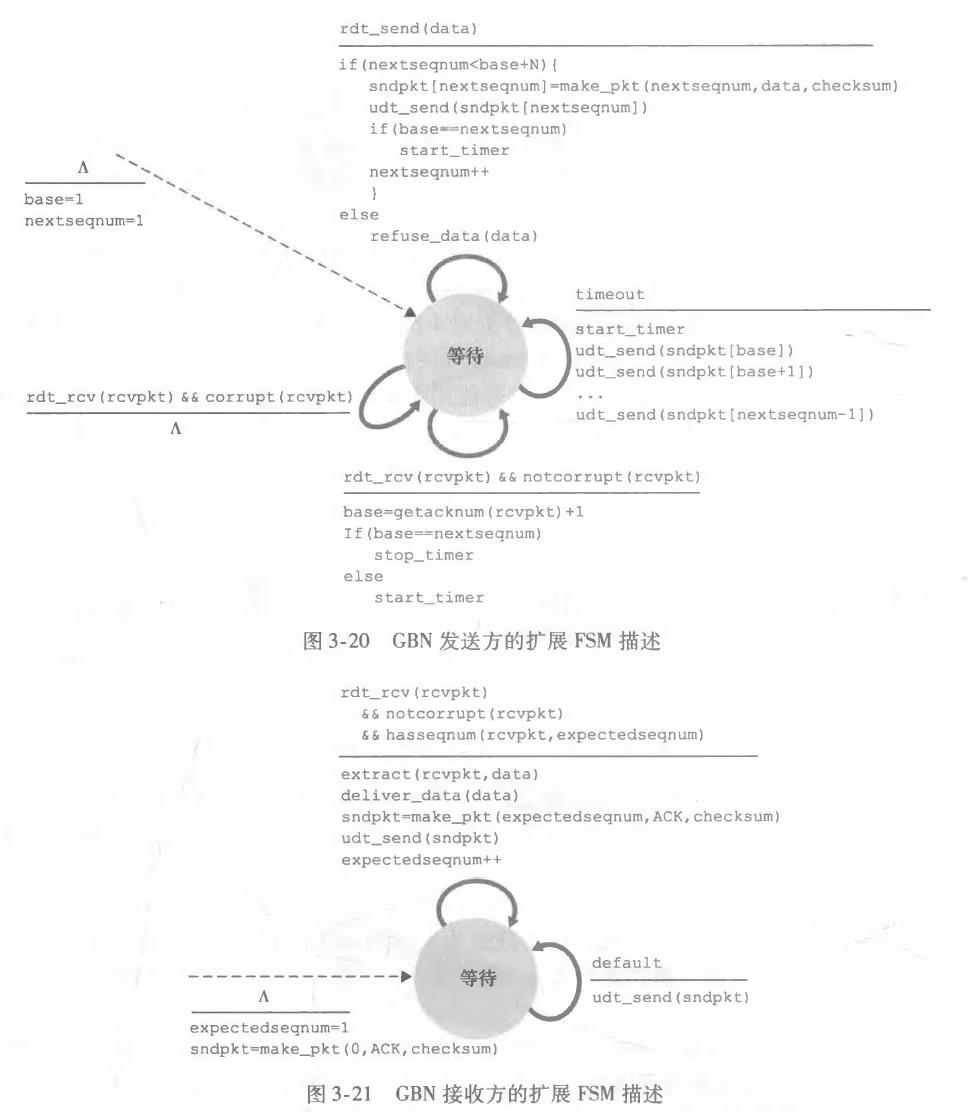
(3)回退N步(GBN)
看图理解,就是个滑动窗口
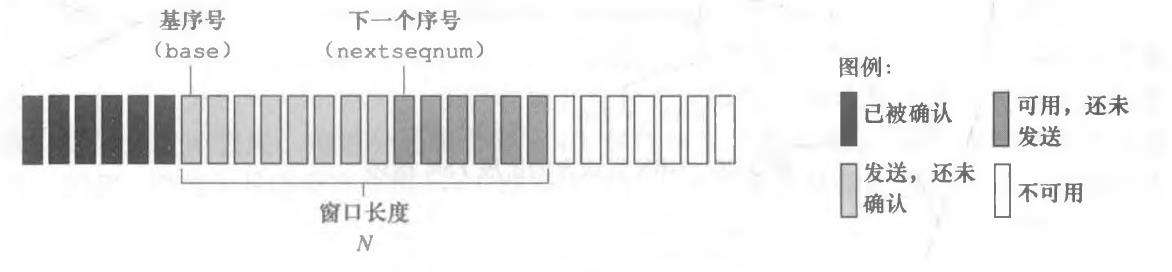
相应的FSM
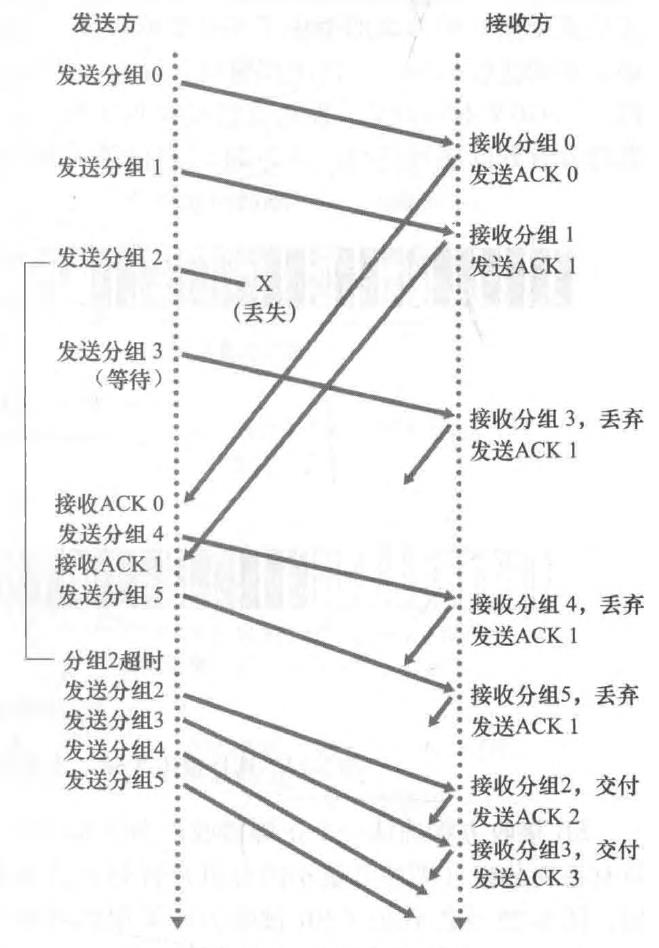
了窗口长度为4个分组的GBN协议运行流程
(4)选择重传(SR)


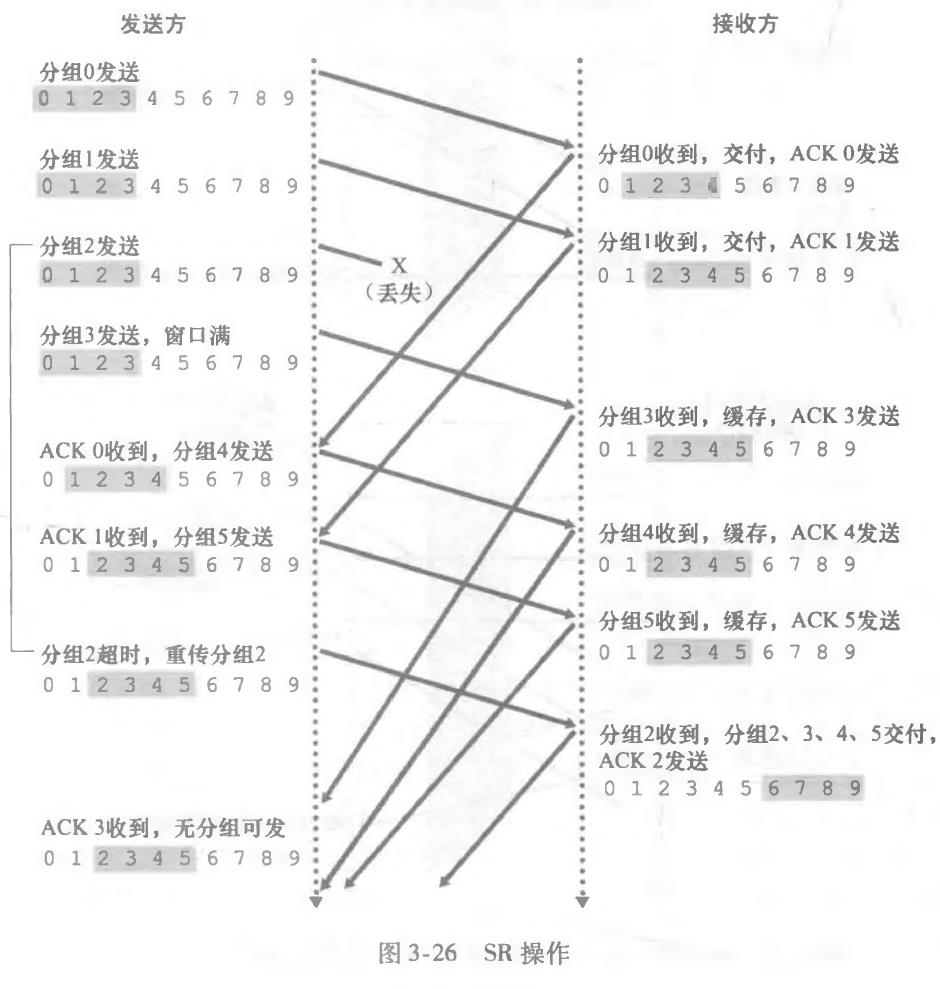
小结
5、TCP
TCP定义在RFC 793、RFC 1122、RFC 1323、 RFC 2018 以及 RFC 2581 中,用到了上一节提到的这些方法
(1)连接
连接是重头戏,完整图如下:
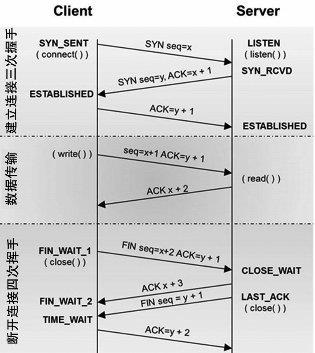
1、三次握手连接
-
第一次握手:建立连接。客户端发送连接请求报文段,并将syn(标记位)设置为1,Squence Number(数据包序号)(seq)为x,接下来等待服务端确认,客户端进入SYN_SENT状态(请求连接)
-
第二次握手:服务端收到客户端的 SYN 报文段,对 SYN 报文段进行确认,设置 ack(确认号)为 x+1(即seq+1 ; 同时自己还要发送 SYN 请求信息,将 SYN 设置为1, seq为 y。服务端将上述所有信息放到 SYN+ACK 报文段中,一并发送给客户端,此时服务器进入 SYN_RECV状态。SYN_RECV是指,服务端被动打开后,接收到了客户端的SYN并且发送了ACK时的状态。再进一步接收到客户端的ACK就进入ESTABLISHED状态
-
第三次握手:客户端收到服务端的 SYN+ACK(确认符) 报文段;然后将 ACK 设置为 y+1,向服务端发送ACK报文段,这个报文段发送完毕后,客户端和服务端都进入ESTABLISHED(连接成功)状态,完成TCP 的三次握手
2、四次挥手断开
- 第一次挥手:客户端设置seq和 ACK ,向服务器发送一个 FIN(终结)报文段。此时,客户端进入 FIN_WAIT_1 状态,表示客户端没有数据要发送给服务端了
- 第二次挥手:服务端收到了客户端发送的 FIN 报文段,向客户端回了一个 ACK 报文段
- 第三次挥手:服务端向客户端发送FIN 报文段,请求关闭连接,同时服务端进入 LAST_ACK 状态
- 第四次挥手:客户端收到服务端发送的 FIN 报文段后,向服务端发送 ACK 报文段,然后客户端进入 TIME_WAIT 状态。服务端收到客户端的 ACK 报文段以后,就关闭连接。此时,客户端等待 2MSL(指一个片段在网络中最大的存活时间)后依然没有收到回复,则说明服务端已经正常关闭,这样客户端就可以关闭连接了
3、几个问题
-
为什么要三次握手?
为了防止已失效的连接请求报文突然又传送到了服务端,因为产生错误。具体解释: “已失效的连接请求报文段”产生情况:client 发出的第一个连接请求报文段并没有丢失,而是在某个网络节点长时间滞留,因此导致延误到连接释放以后的某个时间才到达 service。如果没有三次握手,那么此时server收到此失效的连接请求报文段,就误认为是 client再次发出的一个新的连接请求,于是向 client 发出确认报文段,同意建立连接,而此时 client 并没有发出建立连接的情况,因此并不会理会服务端的响应,而service将会一直等待client发送数据,因此就会导致这条连接线路白白浪费。
如果此时变成两次挥手行不行?
这个时候需要明白全双工与半双工,再进行回答。比如:第一次握手: A给B打电话说,你可以听到我说话吗?
第二次握手: B收到了A的信息,然后对A说: 我可以听得到你说话啊,你能听得到我说话吗?
第三次握手: A收到了B的信息,然后说可以的,我要给你发信息啦!
在三次握手之后,A和B都能确定这么一件事: 我说的话,你能听到; 你说的话,我也能听到。 这样,就可以开始正常通信了,如果是两次,那将无法确定。 -
为什么要四次挥手?
TCP 协议是一种面向连接,可靠,基于字节流的传输层通信协议。TCP 是全双工模式(同一时刻可以同时发送和接收),这就意味着,当主机1发出 FIN 报文段时,只是表示主机1已结没有数据要发送了,主机1告诉主机2,它的数据已经全部发送完毕;但是,这个时候主机1还是可以接受来自主机2的数据;当主机2返回 ACK报文段时,这个时候就表示主机2也没有数据要发送了,就会告诉主机1,我也没有数据要发送了,之后彼此就会中断这次TCP连接。 -
为什么要等待 2MSL
MSL:报文段最大生存时间,它是任何报文段被丢弃前在网络内的最长时间。保证TCP协议的全双工连接能够可靠关闭;保证这次连接的重复数据从网络中消息第一点: 如果主机1直接 关闭,由于IP协议的不可靠性或者其他网络原因,导致主机2没有收到主机1最后回复的ACK。那么主机2就会在超时之后继续发送 FIN,此时由于主机1已经关闭,就找不到与重发的 FIN 对应的连接。所以,主机1 不是直接进入关闭,而是TIME_WAIT 状态。当再次收到 FIN 的时候,能够保证对方收到 ACK ,最后正确关闭连接。
第二点:如果主机1直接 关闭,然后又再向主机 2发起一个新连接,我们不能保证这个新连接与刚才关闭的连接端口是不同的。也就是说有可能新连接和老连接的端口号是相同的。一般来说不会发生什么问题,但还是有特殊情况出现;假设新连接和已经关闭的老连接端口号是一样的,如果前一次连接的某些数据仍然滞留在网络中( Lost Duplicate ),那些延迟数据在建立新连接之后才到达主机2,由于新连接和老连接的端口号是一样的,TCP协议就认为哪个延迟的数据时属于新连接的,这样就和真正的新连接的数据包发生混淆了。所以TCP连接要在 TIME_WAIT 状态等待两倍 MSL,保证本次连接的所有数据都从网络中消失。
(2)报文

(3)往返时间的估计与超时
公式:
EstimatedRTT = (1 - a) • EstimatedRTT + a • SampleRTT
均值EstimatedRTT的新值是由以前的EstimatedRTT值与测一次的SampleRTT新值加权组合而成的。在[RFC 6298 ]中给岀的a推荐值是 a =0.125 ,这时上面的公式变为:
EstimatedRTT =0. 875 • EstimatedRTT +0. 125 • SampleR IT
[RFC 6298]定义了 RTT偏差 DevRTT,用于估算SampleRTT 一般会偏离EstimatedRTT的程度:
DevRTT = (1 -β) • DevRTT +β • | SampleRTT - EstimatedRTT |
注意到DevRTT是一个SampleRTT与EstimatedRTT之间差值的EWMA。如果SampleRTT值波动较小,那么DevRTT的值就会很小;另一方面,如果波动很大,那么DevRTT的值就会很大,β的推荐值为0. 25。
确定重传超时间隔的方法中,所有这些因素都考虑到了:
Timeoutinterval = EstinMrtedRTT +4 • DevRTT
推荐的初始Timeoutinterval值为1秒[RFC 6298]
(4)可靠数据传输
TCP在IP不可靠的尽力而为服务之上创建了一种可靠数据传输服务(reliable data transfer service)。TCP的可靠数据传输服务确保一个进程从其接收缓存中读出的数据流是 无损坏、无间隙、非冗余和按序的数据流;即该字节流与连接的另一方端系统发送出的字节流是完全相同
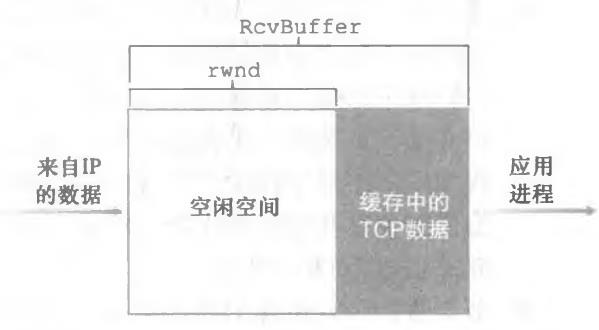
(5)流量控制
假设主机A通过一条TCP连接向主机B发送一个大文件。主机B为 该连接分配了一个接收缓存,并用RcvBuffer来表示其大小:
- LastByteRead:主机B上的应用进程从缓存读出的数据流的最后一个字节的编号
- LastByteRcvd:从网络中到达的并且已放入主机B接收缓存中的数据流的最后一个字节的编号
由于TCP不允许已分配的缓存溢岀,下式必须成立:
LastByteRcvd - LastByteRead ≤ RcvBuffer
接收窗口用rwnd表示,根据缓存可用空间的数量来设置:
rwnd = RcvBuffer - [ LastByteRcvd - LastByteRead ]
6、拥塞控制原理
(1)原因
情况1:两个发送方和一台具有无穷大缓存的路由器
两台主机(A和B)都有一条连接,且这两条连接共享源与目的地之间的单跳路由
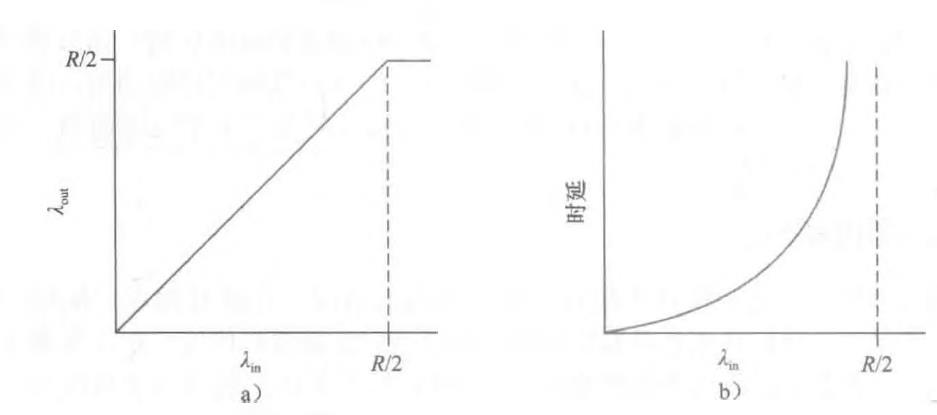
即当分组的到达速率接近链路容量时,分组经历巨大的排队时延
情况2:两个发送方和一台具有有限缓存的路由器
假定路由器缓存的容量是有限的,这种现实世界的假设的结果是,当分组到达一个已满的缓存时会 被丢弃。其次,我们假定每条连接都是可靠的
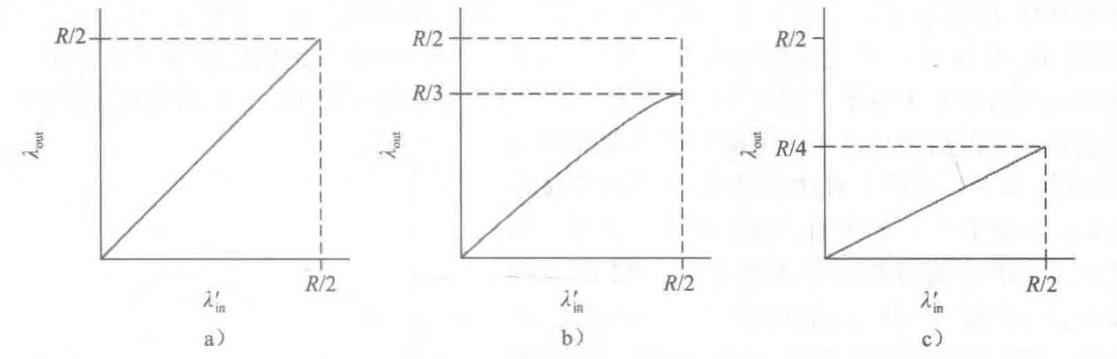
发送方在遇到大时延时所进行的不必要重传会引起路由器利用其链路带宽来转发不必要的分组副本
情况3: 4个发送方和具有有限缓存的多台路由器及多跳路径
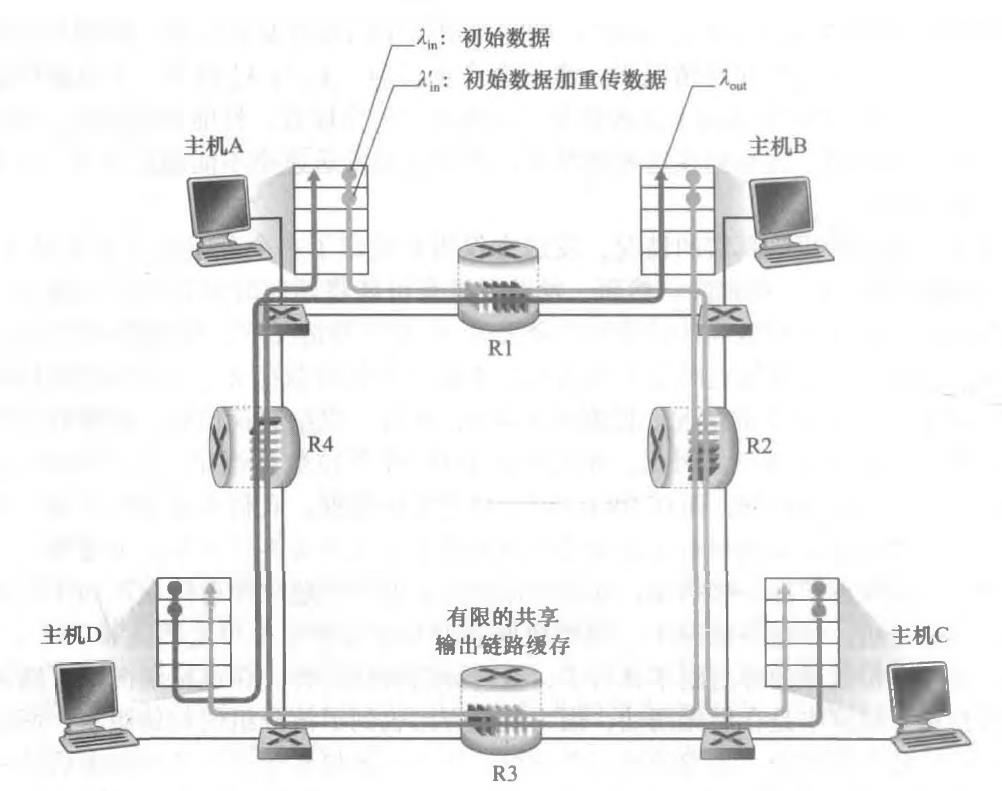
因为A-C流量与B-D流量在路由器R2上必须为有限缓存空间而竞争,所以当来自B-D连接的供给载荷越来越大时,A-C连接上成功通过R2 (即由于缓存溢出而未被丢失)的流量会越来越小
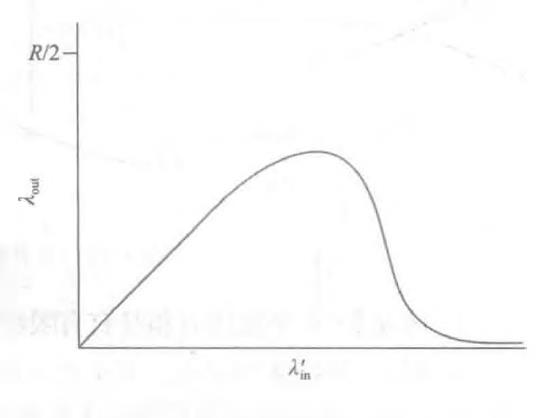
当一个分组沿一条路径被丢弃时,每个上游路由器用于转发该分组到丢弃该分组而使用的传输容量最终被浪费掉了
(2)拥塞控制方法
1、端到端拥寒控制
在端到端拥塞控制方法中,网络层没有为运输层拥塞控制提供显式支持。即使网络中存在拥塞,端系统也必须通过对网络行为的观察(如分组丢失与时延)来推断之
2、网络辅助的拥塞控制
在网络辅助的拥塞控制中,路由器向发送方提供关于网络中拥塞状态的显式反馈信息。这种反馈可以简单地用一个比特来指示链路中的拥塞情况。该方法在早期的 IBM SNA [ Schwartz 1982]、DEC DECnet [Jain 1989;Ramakrishnan 1990]和ATM [ Black 1995]等体系结构中被采用。更复杂的网络反馈也是可能的。例如,在ATM可用比特率(Available Bite Rate, ABR)拥塞控制中,路由器显式地通知发送方它(路由器)能在输出链路上支持的最大主机发送速率
7、TCP拥塞控制
FSM如下
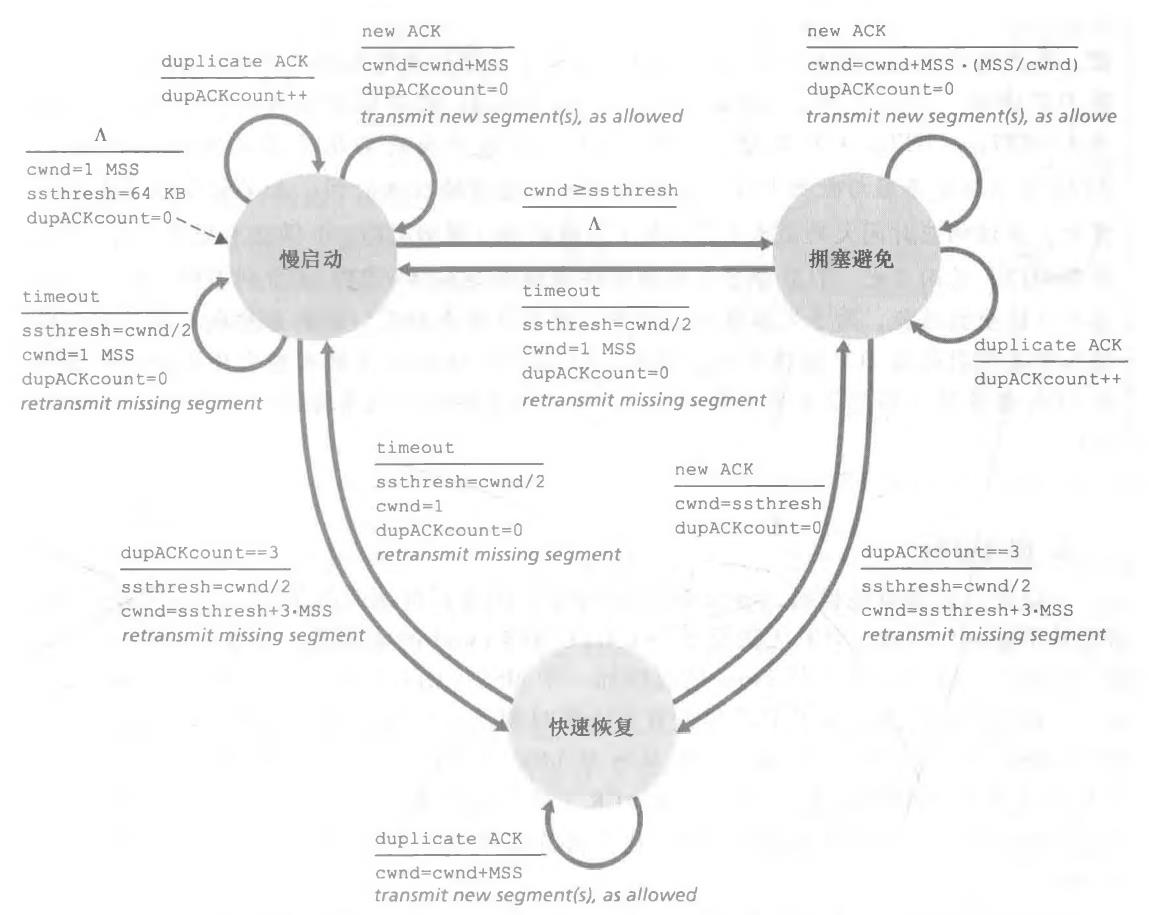
(1)慢启动
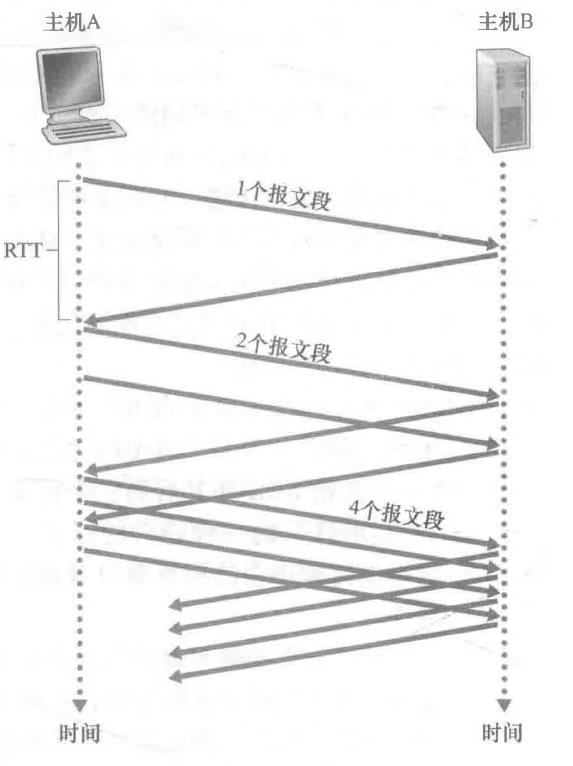
在慢启动(slow-start) 状态,cwnd的值以1个MSS开始并且每当传输的报文段首次被确认就增加1个MSS。于是,每过一个RTT,发送速率就翻番
(2)拥塞避免
一旦进入拥塞避免状态,cwnd的值大约是上次遇到拥塞时的值的一半,即距离拥塞 可能并不遥远!因此,TCP无法每过一个RTT再将cwnd的值翻番,而是采用了一种较为 保守的方法,每个RTT只将cwnd的值增加一个MSS [RFC 5681]
(3)快速恢复
快速恢复是TCP推荐的而非必需的构件[RFC5681]
结语
传输层的学习,重点是TCP以及拥塞控制
以上是关于《计算机网络自顶向下方法》读书笔记:传输层的主要内容,如果未能解决你的问题,请参考以下文章