他说:“只是单纯的想用Python收集一些素颜照,做机器学习使用”,“我信你个鬼!”
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了他说:“只是单纯的想用Python收集一些素颜照,做机器学习使用”,“我信你个鬼!”相关的知识,希望对你有一定的参考价值。
今天,他爬取了 上千张 相亲素颜照。跟我说?刷相亲平台,收集素颜照,训练机器模型。这也能信?
她们明明化妆了。
阅读本文你将收获
- 近万张素颜头像;
lxml解析库初识;XPath语法初识;Cooike反爬;- 女朋友(没准是意外收获)
Python 采集 19 楼相亲女生头像
从本篇博客开始,你将进入爬虫 120 例的第二个小阶段,requests + lxml 实现爬虫。
requests 相信通过前面 10 个案例,你已经比较熟悉了,接下来我们在其基础上,新增一款爬虫解析库 lxml。该库主要用于 XML,html 的解析,而且解析效率非常高,使用它之后,你就可以摆脱编写正则表达式的烦恼了。
目标数据源分析
爬取目标网站
本次抓取目标是 19 楼女生相亲频道,该分类频道截止 7 月 1 日还在持续更新中。
https://www.19lou.com/r/1/19lnsxq.html
以下图片来自网页截图,如有侵权,及时联系橡皮擦哦~

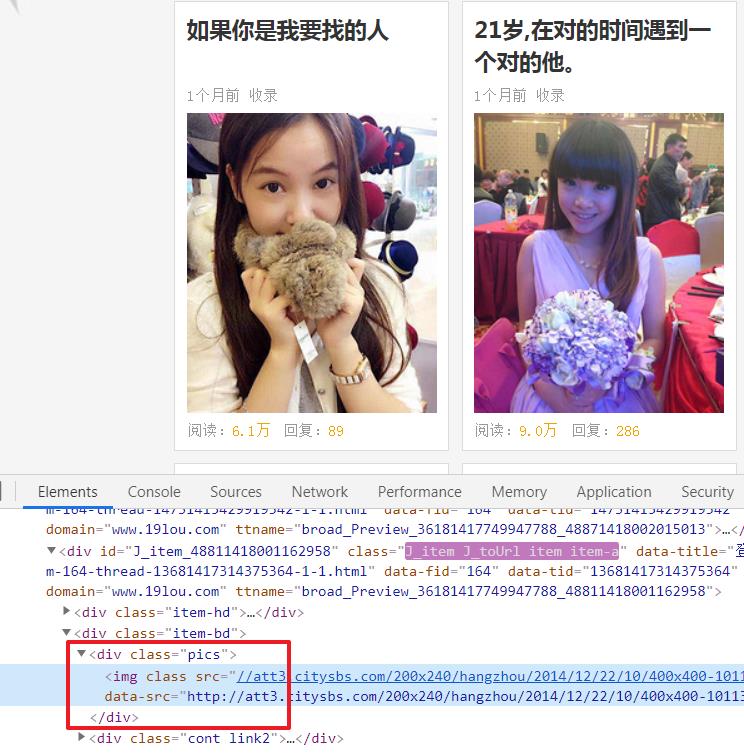
本次爬取的目标为上图头像图片,文件名保存为标题内容。
使用的 Python 模块
requests模块lxml模块fake_useragent模块
重点学习内容
lxml 模块初识。
列表页分析
本次抓取围绕列表页即可完成任务,列表页排序规则如下:
https://www.19lou.com/r/1/19lnsxq.html
https://www.19lou.com/r/1/19lnsxq_2.html
https://www.19lou.com/r/1/19lnsxq-233.html
图片所在标签如下所示,提取工作交给 lxml 模块完成,当然为了联系熟练程度,你依旧可以使用 re 模块完成一版。
lxml 基础知识
提前通过 pip install lxml 对该库完成安装。
导入该库与该库的基本使用。
from lxml import etree
html = "一点HTML代码"
#生成一个 XPath 对象
html=etree.HTML(text)
# 提取数据
html.xpath('//li/a')
上述代码注释中提及的 XPath 对象,关于 XPath,是一门在 XML/HTML 文档中查找信息的语言,大意为通过特定语法在 HTML 中提取数据的语言,基础知识的学习,可以参考 https://www.w3school.com.cn/xpath/xpath_intro.asp,最佳的学习技巧是边查边用。
整理需求如下
- 批量生成待抓取列表页;
requests请求目标数据;lxml提取目标数据;- 保存图片。
编码时间
在编码时,为了防止直接被反爬识别,所在爬取过程中,增加一个等待时间,限制爬取速度(当然在后续发现没有对 IP 的限制,直接移除即可)。
代码编写过程中,如果出现如下错误,更新 fake_useragent 即可。
raise FakeUserAgentError('Maximum amount of retries reached')
更新脚本如下:
pip install -U fake-useragent
如果依旧失败,建议自己写随机生成 UserAgent 的函数。
一点点反爬
爬取该目标数据时,直接通过 requests 请求目标地址,会返回如下代码,该代码不是目标数据所在页面,即网站存在反爬技术。
直接请求目标网址,得到的响应代码如下图所示,注意红框位置。

对 requests 请求到的数据进行分析,发现在返回的代码中设置了 Cookie,该值进行反复测试之后,发现为固定值,后续直接通过 requests 参数 headers 设置即可。
获取到目标页面源码之后,就可以通过 lxml 进行页面提取操作了,在前文已经进行了简单的描述。重点学习的分为两个部分内容:
- 首先通过
lxml模块中的etree对象,将 HTML 源码进行序列化,即转化为 Element 对象; - 然后对
Element对象进行解析,这里用到的解析语法是 XPath,本文用到了路径解析,在完整代码部分有注释说明。
完整代码
import requests
from lxml import etree
from fake_useragent import UserAgent
import time
def save(src, title):
try:
res = requests.get(src)
with open(f"imgs/{title}.jpg", "wb+") as f:
f.write(res.content)
except Exception as e:
print(e)
def run(url):
# ua = UserAgent(cache=False)
ua = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36"
headers = {
"User-Agent": ua,
"Host": "www.19lou.com",
"Referer": "https://www.19lou.com/r/1/19lnsxq-233.html",
"Cookie": "_Z3nY0d4C_=37XgPK9h" # 从反爬代码中获取到的值
}
try:
res = requests.get(url=url, headers=headers)
text = res.text
# 将 html 转换成 Element 对象
html = etree.HTML(text)
# xpath 路径提取 @class 为选取 class 属性
divs = html.xpath("//div[@class='pics']")
# print(len(divs))
# 遍历 Elements 节点
for div in divs:
# 提取地址,注意提取的属性为 data-src 而不是 src
src = div.xpath("./img/@data-src")[0]
# 提取标题
title = div.xpath("./img/@alt")[0]
save(src, title)
except Exception as e:
print(e)
if __name__ == '__main__':
urls = ["https://www.19lou.com/r/1/19lnsxq.html"]
for i in range(114, 243):
urls.append(f"https://www.19lou.com/r/1/19lnsxq-{i}.html")
for url in urls:
print(f"正在抓取{url}")
run(url)
# time.sleep(5)
print("全部爬取完毕")
为了提高效率,你可以取消 5 秒等待,也可以采用多线程,不过尝试几秒钟就好了,不要过度抓取哦,毕竟咱们只为学习。
上述代码还存在一个重要知识点,在获取到的源码中图片的 src 属性为 dot.gif(加载图片),data-src 属性存在值。
具体对比如下图所示,上图为直接查看页面源码,下图为服务器直接返回源码。
这部分给我们的爬取提示为,任何数据的解析提取,都要依据服务器直接返回的源码。

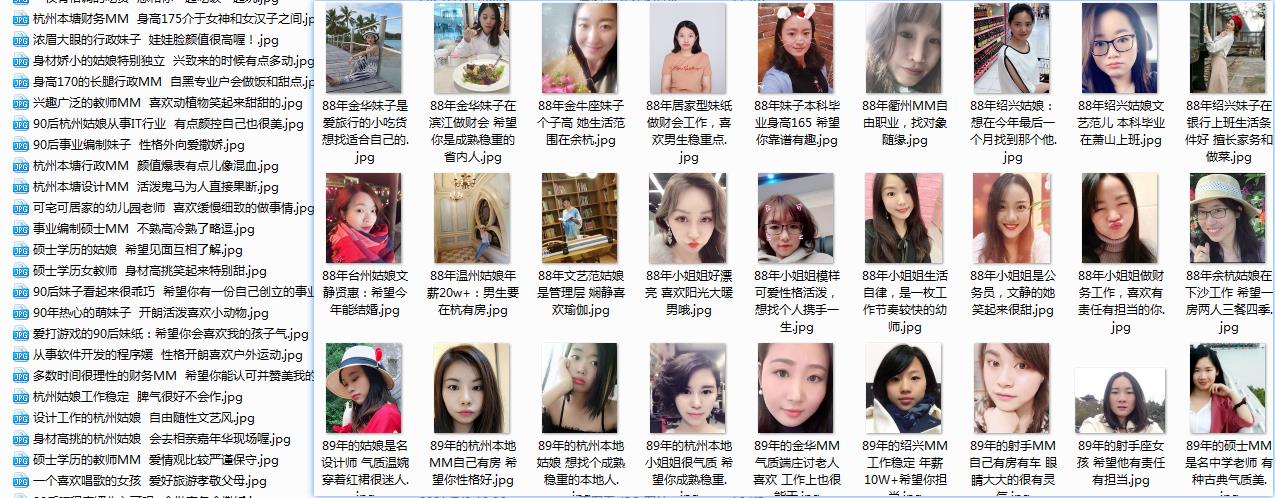
抓取结果展示时间
爬虫 120 例,第 11 例完成,希望本篇博客能带给你不一样的惊喜与知识。相关资料可以在下面直接获取。
完整代码下载地址:https://codechina.csdn.net/hihell/python120,NO11。
以下是爬取过程中产生的各种学习数据,如果只需要数据,可去下载频道下载~。
爬取资源仅供学习使用,侵权删。
抽奖时间
上篇博客获奖的朋友 ID 为 m0_59785054,抓紧联系橡皮哦。

评论数过 100,随机抽取一名幸运读者,
获取 29.9 元《Python 游戏世界》专栏 1 折购买券一份,只需 2.99 元。
今天是持续写作的第 174 / 200 天。可以关注我,点赞我、评论我、收藏我啦。
相关阅读
以上是关于他说:“只是单纯的想用Python收集一些素颜照,做机器学习使用”,“我信你个鬼!”的主要内容,如果未能解决你的问题,请参考以下文章