解密贪心算法——最高效的近似算法
Posted 算法匠人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解密贪心算法——最高效的近似算法相关的知识,希望对你有一定的参考价值。
在解决一些问题的时候,有的问题要得到最优解是非常困难的。这个时候我们就不要再执着于最优解了,因为即便得到了最优解也可能是得不偿失的。采用贪心算法求解这个问题是一种折中的好方法。
所谓贪心算法就是在对问题求解时,总是做出当前看来是最好的选择。也就是说贪心算法并不从整体最优上考虑问题,算法得到的是某种意义上的局部最优解。而局部的最优解叠加在一起便构成了问题的整体最优解,或者近似最优解。正是因为贪心算法思想简单,且算法效率较高,所以在一些问题的解决上有着明显的优势。
下面我们来看一个经典的问题——集合覆盖问题,从中体会一下贪心算法的妙用。
假设你办了个广播节目,要让全美 50个州的听众都收听得到。为此,你需要决定在哪些广播台播出。在每个广播台播出都需要支付费用,因此你力图在尽可能少的广播台播出。现有广播台名单(部分)如下。
表(1)每个广播台和对应覆盖的州
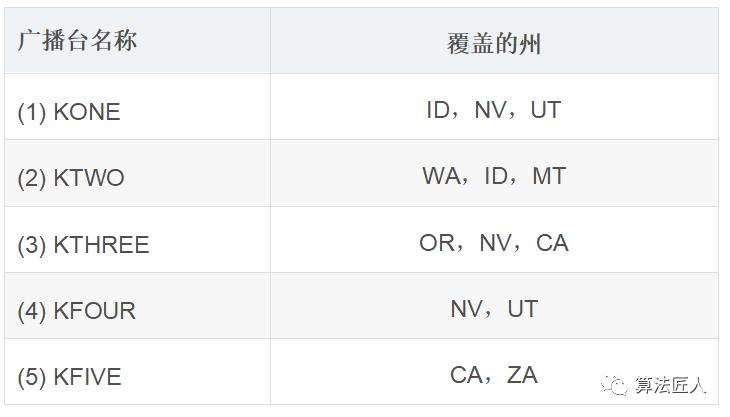
如何找出覆盖全美 50个州的最小广播台集合呢?
一般情况下,我们会想到使用穷举法来解决这个问题。假设全美共有n个广播台可供选择,那么每个广播台就有“选择”(1)和“不选择”(0)两种状态,将这n个广播台中每个广播台的两种选择方式任意组合,则共有2n种组合方式,也就是共有2n个可能的广播台集合。现在我们要做的就是从这2n个集合中找出一个集合,要求该集合中的广播台可以覆盖全美50个州,同时广播台的数量是最小的。
这个方法看似简单直观,但是却非常耗时,因为该方法的时间复杂度达到了O(2n)。如果广播台的数量不够多(例如表1中所示仅有5个),则穷举法依然是可行的,毕竟可以在有限时间内找到问题的最优解;但是如果广播台的数量很多(例如题目中要求的50个),则消耗的时间会非常长,因为随着广播台的增多,消耗的时间将呈指数(2n)级增长!假设每秒钟可得到10个广播台的集合,随着广播台数量的增加,所需时间变化如表2所示。
表(2)广播台的数量和计算这些数量下广播台组合所需时间

可见如果广播台数量较大,穷举法不是一个可行的解决方案。
于是我们就要祭出终极大招了——贪心算法登场!
因为我们既要让选择的广播台可以覆盖全美50州,同时又要广播台的数量尽可能少,所以我们可在选择广播台时优先选择可覆盖最多未覆盖州的广播台,即便这个广播台覆盖了一些已经被覆盖的州也无妨。这样就可以以更快的速度将全部的州覆盖,从而实现广播台数量尽可能少的目标。
这么说可能有些拗口,其实很好理解,我们通过一个简单的例子来理解该贪心算法的精髓。假设现在只有9个州(A,B,C,D,E,F,G,H,I)和5个广播台(1,2,3,4,5),广播台对各州的覆盖情况如图(1)所示。
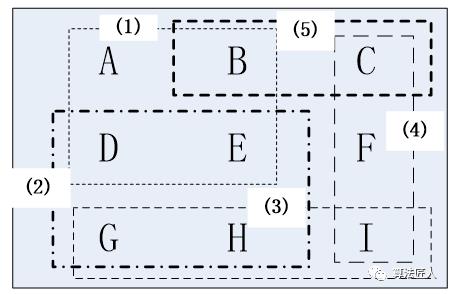
图(1)广播台覆盖各州的情况
如图(1)所示,格广播台对各州的覆盖关系如下:
(1)--> A、B、D、E
(2)-->D、E、G、H
(3)-->G、H、I
(4)-->C、F、I
(5)-->B、C
现在要找出尽可能少的广播台,同时又要全部覆盖这9个州,我们可以使用贪心策略来解决这个问题。
1、最初9个州无一被覆盖,所以未覆盖的州为{A,B,C,D,E,F,G}
2、然后选择可覆盖最多未覆盖州的广播台。因为广播台(1)(2)均可覆盖4个州,广播台(3)(4)均可覆盖3个州,广播台(5)可覆盖2个州,所以选择(1)(2)都是可以的,这里选择广播台(1)。于是未覆盖的州变为{C,F,I,G,H},如图(2)所示。
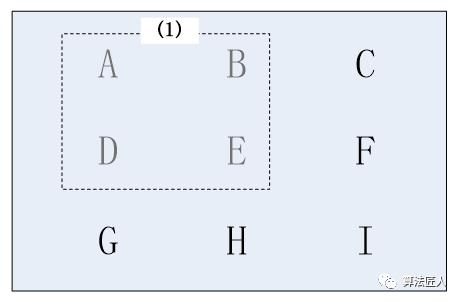
图(2) 选择广播台(1)后覆盖了A、B、D、E四个州
3、接下来要选择能覆盖{C,F,I,G,H}中最多州的那个广播台。我们可通过计算交集的办法来找出这个广播台。广播台(2)可覆盖的州为{D,E,G,H},而集合{D,E,G,H}与{C,F,I,G,H}的交集为{G,H},这说明广播台(2)仅可覆盖未被覆盖的州中的2个州G和H。按照同样的方法计算,广播台(3)可覆盖的未覆盖的州为{G,H,I}×{C,F,I,G,H}={G,H,I};广播台(4)可覆盖的未覆盖的州为{C,F,I}×{C,F,I,G,H}={C,F,I};广播台(5)可覆盖的未覆盖的州为{C,F,I,G,H}×{B,C}={C}。所以可选择广播台(3)或广播台(4),它们都可以覆盖3个未被覆盖的州。这里选择广播台(3),于是未覆盖的州变为{C,F},如图(3)所示。
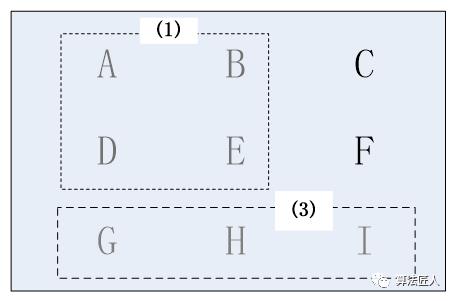
图(3) 选择广播台(3)后覆盖了G、H、I三个州
4、接下来要选择能覆盖{C,F}中最多州的那个广播台。我们同样用计算交集的方法来找出这个广播台。此时还剩下广播台(2)(4)(5),我们分别计算它可覆盖州的集合与未覆盖州的集合{C,F}的交集。广播台(2)可覆盖的未覆盖的州为{D,E,G,H}×{C,F}=null;广播台(4)可覆盖的未覆盖的州为{C,F,I}×{C,F}={C,F};广播台(5)可覆盖的未覆盖的州为{B,C}×{C,F}={C}。显然广播台(4)可覆盖最多未覆盖的州,因此选择广播台(4)。如图(4)所示。
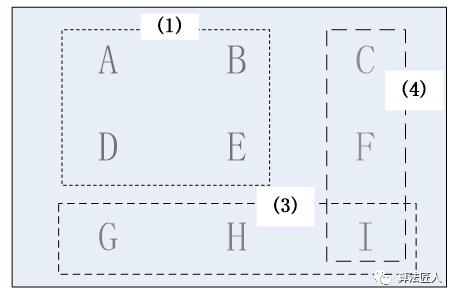
图(4) 选择广播台(4)后覆盖了C、F、I三个州
至此全部的9个州都被广播台(1)(3)(4)覆盖。
在上述计算过程中,利用贪心策略逐步找出最优的广播台组合,从而既实现了9个州全覆盖,又选择了最少的州数。可以看出,在使用贪心算法解决问题时并不从问题的整体最优解出发,而是只“贪心”地着眼于当下,只要每次选取的广播台可以最大限度地覆盖未覆盖的州即可。这种方法要比上面介绍的逐一穷举可能解,在从中找出最优解的方法高效很多。贪心算法的时间复杂度为O(n2),其中n为广播台的个数。这就是贪心算法的优势所在。
另外,使用贪心算法求解问题得到的答案可能并不唯一。例如本题,如果最开始我们选择的不是广播台(1)而是广播台(2),那么使用该贪心策略得到的结果就是(2)(4)(1),这个结果同样可以覆盖9个州。如图(5)所示。
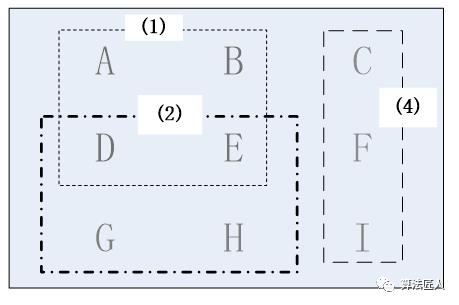
图(5) 最开始选择广播台(2)最终得到的结果
下面给出本题完整的代码。
public class SetCover {
public static HashSet<String> getBestBroadCasts(HashSet<String> allStatesSet,
LinkedHashMap<String, HashSet<String>> broadCasts ) {
HashSet<String> bestbroadCasts = new HashSet<String>();
String bestBroadCast = "";
//外层循环控制将所有州allStatesSet全部覆盖掉
while (allStatesSet.size()>0) {
//内层循环遍历每一个广播站,得到其对应覆盖的州
//然后计算这些州与剩余未覆盖州的交集
//选出其中可覆盖最多未覆盖州对应的那个广播站,将其放到bestbroadCasts集合里
HashSet<String> maxCovered = new HashSet<String>();
for (HashMap.Entry<String, HashSet<String>> map: broadCasts.entrySet()) {
HashSet<String> set = map.getValue(); //得到该广播站可覆盖的州的集合
//计算该广播站可覆盖的州与剩余未覆盖州的交集
HashSet<String> covered = new HashSet<String>();
covered.clear();
covered.addAll(set);
covered.retainAll(allStatesSet);
//for循环结束后,maxCovered中保存可覆盖的最多未覆盖的州
//bestBroadCast中保存对应的广播站的名字
if (covered.size() > maxCovered.size()) {
maxCovered = covered;
bestBroadCast = map.getKey();
//System.out.println("covered " + covered);
System.out.println("maxCovered " + maxCovered);
System.out.println("bestBroadCast " + bestBroadCast);
}
}
bestbroadCasts.add(bestBroadCast); //将bestBroadCast加入bestbroadCasts
//计算allStatesSet与maxCovered的差集,这样allStatesSet会缩小,将剩下尚未被覆盖的州
allStatesSet.removeAll(maxCovered);
}
return bestbroadCasts;
}
public static void main(String[] args) {
//初始化allStates,存放所有需要覆盖的州
String[] allStates = {"mt", "wa", "or", "id", "nv", "ut","ca","az"};
//将字符串数组转换为集合HashSet
HashSet<String> allStatesSet = new HashSet<String>(Arrays.asList(allStates));
//创建一个HashMap broadCasts,存放广播台和每个广播台可覆盖的州
LinkedHashMap<String, HashSet<String>> broadCasts
= new LinkedHashMap<String, HashSet<String>>();
//初始化broadCasts
broadCasts.put("kone",new HashSet<String>(Arrays.asList("id", "nv","ut")));
broadCasts.put("ktwo",new HashSet<String>(Arrays.asList("wa", "id","mt")));
broadCasts.put("kthree",new HashSet<String>(Arrays.asList("or", "nv","ca")));
broadCasts.put("kfour",new HashSet<String>(Arrays.asList("nv","ut")));
broadCasts.put("kfive",new HashSet<String>(Arrays.asList("ca","az")));
//调用getBestBroadCasts函数得到广播台信息
System.out.println(getBestBroadCasts(allStatesSet,broadCasts));
}
}
为了简化问题的规模,上述代码仅实现了表1所示的5个广播台和所覆盖的8个州的情形。而且在本代码中多采用HashSet,HashMap结构存放数据,这样做的目的是为了充分利用Java容器类的方法,使操作更加方便。
在main方法中首先定义了一个字符串数组allStates用来存放8个州的名字,然后将该字符串数组转换成为一个HashSet集合allStatesSet。然后创建了一个HashMap对象broadCasts,用来存放每个广播台以及该广播台对应的所能覆盖的州的信息。例如广播台”kone”可覆盖的州为"id", "nv","ut",那么就将字符串”kone”作为broadCasts中一项的key值,将由"id", "nv","ut"组成的HashSet作为该key对应的value。最后调用函数getBestBroadCasts()计算最优的广播台选择方案。
函数HashSet<String> getBestBroadCasts(HashSet<String> allStatesSet, LinkedHashMap<String, HashSet<String>> broadCasts ) 的作用就是利用贪心算法计算算最优的广播台选择方案。该函数的返回值为一个HashSet<String>的对象,里面将保存选取的广播台的名字。该函数包含两个参数,即为前面讲到的allStatesSet和broadCasts。
在函数getBestBroadCasts()内部通过一个二重循环实现贪心法查找最优广播台组合。外层循环的执行条件是allStatesSet.size()>0,也就是说只要allStatesSet中存储的州还没有被选中的广播台全部覆盖,就继续执行下去。因此外层的while循环控制将所有州allStatesSet全部覆盖掉。内层循环将遍历Hashmap broadCasts中保存的每一个广播站,并得到其对应覆盖的州,然后计算这些州与剩余的未覆盖州的交集,从中选出可覆盖最多未覆盖州对应的那个广播站,并将其放到bestbroadCasts集合里。当一次内层循环执行完毕后,就可以选出一个广播台,该广播台可覆盖最多的未覆盖州。每当执行完一次内层for循环后,还要执行allStatesSet.removeAll(maxCovered);目的是为了将已覆盖的州从集合allStatesSet中移除,这样allStatesSet中始终保存的是尚未覆盖的州。当allStatesSet.size()==0时表明所有的州都已被选中的广播台覆盖,所以外层循环就可以结束。
最终集合bestbroadCasts中将会保存选中的广播台信息,并作为返回值返回给主调函数。
上述代码的执行结果如图(6)所示
图(6)程序的执行结果
需要指出的是,由于贪心算法每一步都只考虑局部的最优解,所以在处理某些问题上可能得不到整体的最优解。从严格意义上讲,要使用贪心算法得到最优解,该问题应具备以下性质。
(1)贪心选择性质
所谓贪心选择性质就是指所求解问题的整体最优解可以通过一系列局部最优解得到。例如上述的“找钱问题”中,当前状态下最优的选择就是使找过硬币后剩余的零钱数(还亏欠顾客的零钱数)最接近于0,所以每次找钱都要选择面值尽可能大的硬币,这样硬币的总数才会更少。
(2)最优子结构性质
当一个问题的最优解包含着它的子问题的最优解时,则称该问题具有最优子结构性质。上述“找钱问题”就是典型的具有最优子结构性质。
在实践中,要判断一个问题是否具备以上两种性质则需要严格的数学证明。因此虽然贪心算法简单且易于实现,但是理论上在使用贪心算法解决问题之前,要对问题本身进行深入透彻的分析和证明,以确保使用贪心算法可以得到整体最优解。
然而经验告诉我们,实际应用中许多问题都可以使用贪心算法得到最优解,即使贪心算法得不到问题的最优解,最终的结果也是最优解的很好的近似解。所以在解决一般性问题时,我们可以大胆尝试使用贪心算法。
我们熟悉的哈夫曼编码算法,以及前面章节中介绍的最小生成树的Prim算法和Kruskal算法,以及计算图的单源最短路径的Dijkstra算法等都是基于贪心算法的思想设计出来的算法。
以上是关于解密贪心算法——最高效的近似算法的主要内容,如果未能解决你的问题,请参考以下文章