死磕 Redis----- 主从复制:全量复制和部分复制
Posted chenssy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了死磕 Redis----- 主从复制:全量复制和部分复制相关的知识,希望对你有一定的参考价值。
原文:https://www.topjava.cn/category/1391389927996002304 『chenssy』
在上篇博客【死磕 Redis】— 主从复制(一) 提到,主从节点在数据同步阶段,主节点会根据当前状态的不同执行不同复制操作,包括:全量复制 和 部分复制,这篇博文将详细介绍这两种情况。
- 全量复制:用于首次复制或者其他不能进行部分复制的情况。全量复制是一个非常重的操作,一般我们都要规避它
- 部分复制:用于从节点短暂中断的情况(网络中断、短暂的服务宕机)。部分复制是一个非常轻量级的操作,因为它只需要将中断期间的命令同步给从节点即可,相比于全量复制,它显得更加高效。
在 Redis 2.8 以前,从节点向主节点发送 sync 命令请求同步数据,此种方式是全量复制。在 Redis 2.8 以后,Redis 支持部分复制,发送的命令是 psync。
全量复制
全量复制的流程图如下:
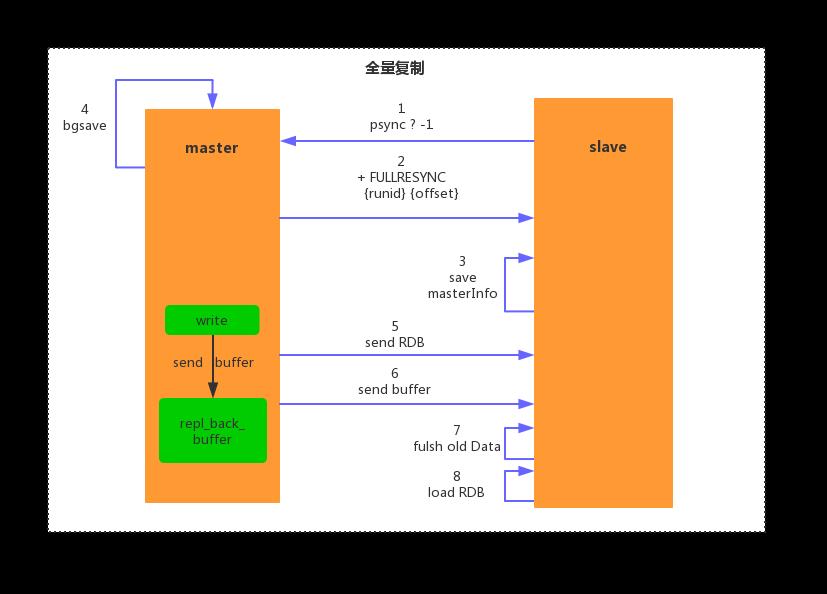
- 由于是第一次进行数据同步,从节点并不知道主节点的 runid,所以发送 psync ? -1
- 主节点接收从节点的命令后,判定是进行全量复制,所以回复 +FULLRESYNC ,同时也会将自身的 runid 和 偏移量发送给从节点,响应为
+FULLRESYNC {runid} {offset} - 从节点接受主节点的响应后,会保存主节点的 runid 和 偏移量 offset。打印日志如下:
62760:S 16 May 2019 21:24:36.818 * Trying a partial resynchronization (request cf2836e6d8f3628c81b3ebb36fea4410f21f05b0:1).
62760:S 16 May 2019 21:24:36.820 * Full resync from master: a7113788690a86b166cf978b874b3c6056167b54:0
从节点尝试部分复制,请求节点的runid 为 cf2836e6d8f3628c81b3ebb36fea4410f21f05b0,offset:1,但是主节点告知从节点是全量复制,runid:a7113788690a86b166cf978b874b3c6056167b54,offset:1。
4. 主节点响应从节点命令后,会执行 bgsave,将生成的 RDB 文件保存在本地。打印日志如下:
62743:M 16 May 2019 21:24:36.819 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'cf2836e6d8f3628c81b3ebb36fea4410f21f05b0', my replication IDs are '0156844c881cf978fa35de7deeb9f85ef7cd1b0e' and '0000000000000000000000000000000000000000')
62743:M 16 May 2019 21:24:36.819 * Starting BGSAVE for SYNC with target: disk
62743:M 16 May 2019 21:24:36.820 * Background saving started by pid 62770
62770:C 16 May 2019 21:24:36.821 * DB saved on disk
62743:M 16 May 2019 21:24:36.884 * Background saving terminated with success
主节点接受从节点的部分请求,但是 runid 不一致,进行全量复制,返回 +FULLRESYNC,并将自身的 runid 和 offset 返回给从节点。
5. 主节点将生成的 RDB 文件发送给从节点,从节点接收后保存在本地直接将其作为数据文件,如果从节点本地有 RDB 文件,则从节点会先清空 RDB 文件。从节点打印日志如下:
62760:S 16 May 2019 21:24:36.885 * MASTER <-> REPLICA sync: receiving 234 bytes from master
62760:S 16 May 2019 21:24:36.886 * MASTER <-> REPLICA sync: Flushing old data
62760:S 16 May 2019 21:24:36.886 * MASTER <-> REPLICA sync: Loading DB in memory
62760:S 16 May 2019 21:24:36.886 * MASTER <-> REPLICA sync: Finished with success
- 如果从节点还开启了 AOF,则还会进行 AOF 重写,日志如下:
62760:S 16 May 2019 21:24:36.887 * Background append only file rewriting started by pid 62771
62760:S 16 May 2019 21:24:36.911 * AOF rewrite child asks to stop sending diffs.
62771:C 16 May 2019 21:24:36.912 * Parent agreed to stop sending diffs. Finalizing AOF...
62771:C 16 May 2019 21:24:36.913 * Concatenating 0.00 MB of AOF diff received from parent.
62771:C 16 May 2019 21:24:36.913 * SYNC append only file rewrite performed
62760:S 16 May 2019 21:24:36.918 * Background AOF rewrite terminated with success
62760:S 16 May 2019 21:24:36.919 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
62760:S 16 May 2019 21:24:36.919 * Background AOF rewrite finished successfully
从上面过程我们就可以看出,全量复制是一个非常重的操作过程,它的开销主要有:
- 主节点执行 bgsave 过程,在持久化那篇博客中我们知道该过程是非常消耗 CPU、内存(页表复制)、硬盘 IO 的
- 主节点发送 RDB 给从节点的网络开销
- 从节点清空 RBD 文件(如果有)和加载 RDB 文件,同时该过程是阻塞的,无法响应客户端命令
- 如果从节点开启了 AOF,则还有 bgrewriteaof 的开销
所以,我们需要尽可能避免全量复制,当然第一次建立连接数据同步是必不可免的,但是其他的情况我们是可以避免的。
第一次建立连接进行数据同步是全量复制,还有以下几种情况也是全量复制:
- 从节点发送 psync {runid} {offset} 时,runid 与当前主节点的 runid 不匹配则进行全量复制
- 从节点所需要同步数据的偏移量 offset 不在复制积压缓冲区中,也会进行全量复制,关于复制积压缓冲区,我们下面详细分析。
部分复制
既然全量复制这么重,效率又比较低,那么优秀的 Redis 开发者一定会提供更加优秀的复制流程,因此在 Redis 2.8 开始提供了部分复制,用于处理网络中断的数据同步。在分析部分复制之前,我们需要先弄清楚三个概念:
- 复制偏移量
- 复制积压缓冲区
- 运行 ID(runid)
复制偏移量
主从节点都维护这一个复制偏移量(offset),它代表着当前节点接受数据的字节数,主节点表示接收客户端的字节数,从节点表示接收主节点的字节数,比如从节点接收主节点传来的 N 个字节数据时,从节点的 offset 会增加 N。
偏移量的作用非常大,它是用来衡量主从节点数据是否一直的唯一标准,如果主从节点的 offset 相等,表明数据一直,否则表明数据不一致。在不一致的情况下,可以根据两个节点的 offset 找出从节点的缺少的那部分数据。比如,主节点的 offset 是 500,从节点的 offset 是 400,那么主节点在进行数据传输时只需要将 401 ~ 500 传递给从节点即可,这就是部分复制。
从节点通过心跳每秒都会将自身的偏移量告知主节点,所以主节点会保存从节点的偏移量。同时,主节点处理完命令后,会将命令的字节长度累加到自身的偏移量中,如下图:
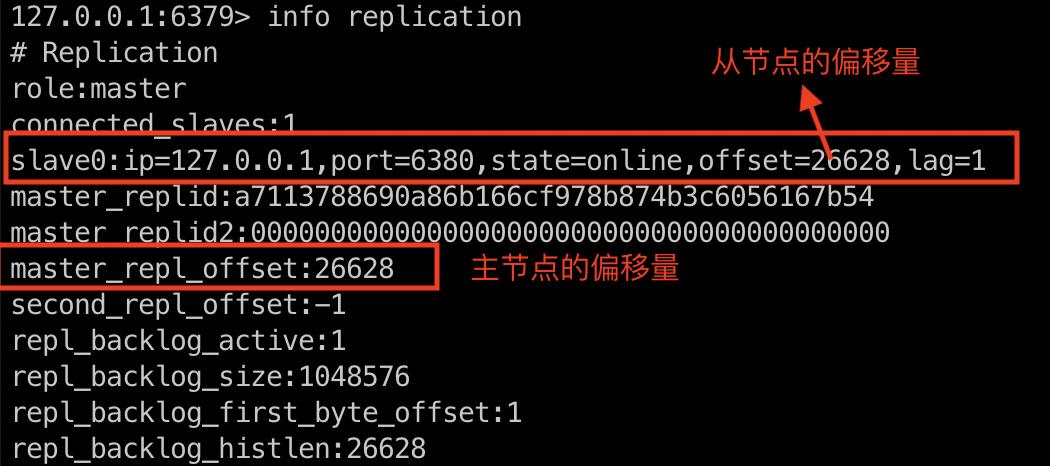
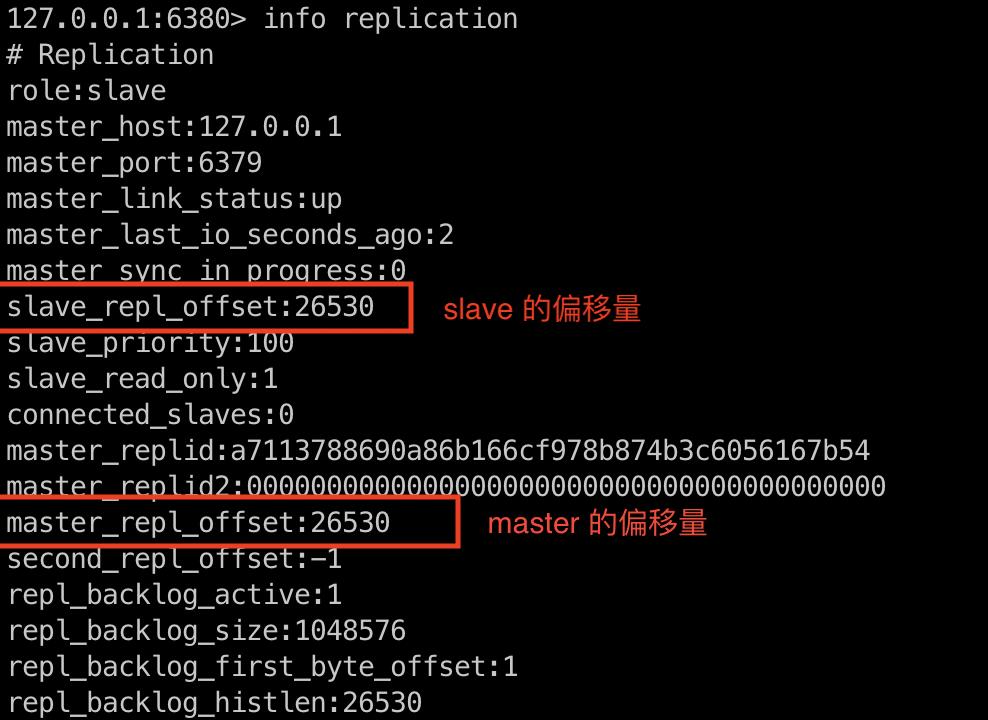
从节点每次接受到主节点发送的命令后,也会累加到自身的偏移量中,主节点,如下图
复制积压缓冲区
复制积压缓冲区是一个由主节点维护的缓存队列,它具有如下几个特点:
- 由主节点维护
- 固定大小,默认为 1MB,配置参数为:repl-backlog-size
- 是一个先进先出的队列
在命令传播节点,主节点除了将写命令传递给从节点,也会将写命令写入到复制积压缓冲区中,当做一个备份,用于在部分复制流程中。由于它是先进先出的队列,且大小固定,所以他只能保存主节点最近执行的写命令,当主从节点的 offset 相差较大时,超出了复制积压缓冲区的范围,则无法进行部分复制,只能进行全量复制了,所以为了能够提高网络中断引起的全量复制,我们需要认真评估复制积压缓冲区的大小,将其适当调大,比如网络中断时间是 60s,主节点每秒接收的写命令为 100KB,则复制积压缓冲区的平均大小应该为 6MB,所以我们可以将其大小设置为 6MB,甚至是 10MB,来保证绝大多数中断情况下都可以使用部分复制。
运行 ID(runid)
每个 Redis 节点在启动时都会生成一个运行 ID,即 runid,该 ID 用于唯一标识 Redis 节点,它是一个由 40 位随机的十六进制的字符组成的字符串,通过 info server 命令可以查看节点的 runid,如下:
127.0.0.1:6379> info server
...
run_id:e88221d68ce96fc28c2f2b3afbf3495ea6de512a
...
主从节点在初次建立连接进行全量复制时(从节点发送 psync ? -1),主节点会将自己的 runid 告知给从节点,从节点将其保存起来。当主从节点断开重连时,从节点会将这个 runid 发送给主节点,主节点会根据从节点发送的 runid 来判断选择何种复制:
- 如果从节点发送的 runid 与当前主节点的 runid 一致时,主节点则尝试进行部分复制,当然能不能进行部分复制还要看偏移量是否在复制积压缓冲区
- 如果从节点发送的 runid 与当前主节点的 runid 不一致时,则进行全量复制
部分复制
当主从节点在命令传播节点发生了网络中断,出现数据丢失情况,则从节点会向主节点请求发送丢失的数据,如果请求的偏移量在复制积压缓冲区中,则主节点就将剩余的数据补发给从节点,保持主从节点数据一致,由于补发的数据一般都会比较小,所以开销相当于全量复制而言也会很小,流程如下:
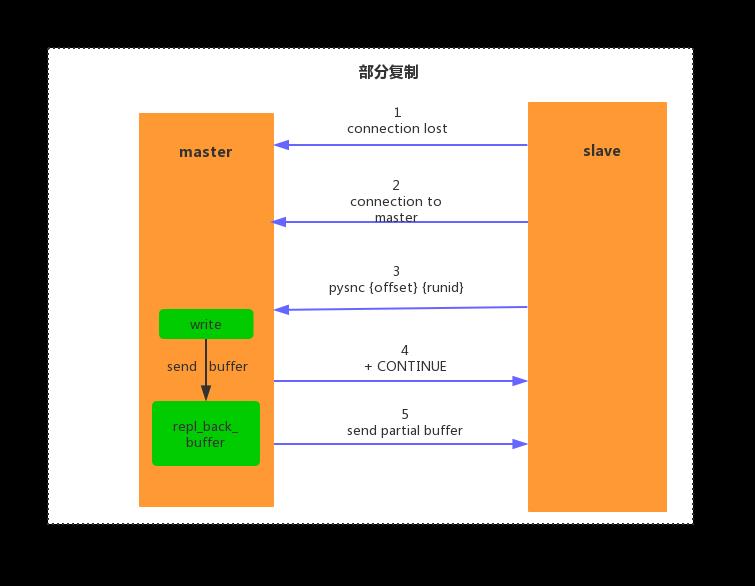
- 当主从节点出现网络闪退时,如果超过了 repl-timeout 时间,主节点会认为从节点出现故障不可达,打印日志如下:
-- master
2496:M 19 May 2019 10:06:02.970 # Connection with replica 127.0.0.1:6391 lost.
--slave
2655:S 19 May 2019 10:21:59.515 * Connecting to MASTER no:6390
2655:S 19 May 2019 10:21:59.516 # Unable to connect to MASTER: Undefined error: 0
- 由于主节点没有宕机,所以他依然会响应客户端命令,当然这些命令也不会丢失,都会存储在复制积压缓冲区中,默认 1MB。
- 当主从直接回复连接,从节点再次连接主节点,打印日志如下:
2655:S 19 May 2019 10:22:00.082 * REPLICAOF 127.0.0.1:6390 enabled (user request from 'id=6 addr=127.0.0.1:55985 fd=7 name= age=11 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=42 qbuf-free=32726 obl=0 oll=0 omem=0 events=r cmd=slaveof')
2655:S 19 May 2019 10:22:00.527 * Connecting to MASTER 127.0.0.1:6390
2655:S 19 May 2019 10:22:00.527 * MASTER <-> REPLICA sync started
2655:S 19 May 2019 10:22:00.528 * Non blocking connect for SYNC fired the event.
2655:S 19 May 2019 10:22:00.528 * Master replied to PING, replication can continue...
这里一定要注意:不要关闭从节点然后启动,这样是模拟不出来的,一定是要执行 slaveof no one 命令,因为重启从节点,他的 master_replid 会丢失,在请求的时候因为 runid 不一致而导致全量复制,当然你也选择将 slaveof 写入到配置文件中再重启,这样也可以进行部分复制。
4. 当主从建立连接后,由于从节点保存了主节点的 runid 和 offset ,所以只需要发送命令 psync {runid} {offset}即可,从节点打印日志如下:
2655:S 19 May 2019 10:22:00.529 * Trying a partial resynchronization (request dfa92dd668e0c6c3447af0d502b6ee4b0b07d75d:2268).
可以看到请求的 runid:dfa92dd668e0c6c3447af0d502b6ee4b0b07d75d,offset:2268
5. 主节点接受从节点的 psync 命令,会先核对请求的 runid 是否和自身的的 runid 一致,如果一致,说明该从节点复制的当前主节点。然后查看请求的 offset 是否在复制积压缓冲区,如果在则进行部分复制,否则进行全量复制,部分复制回复 +CONTINUE 响应,从节点接受回复后,打印日志如下:
2655:S 19 May 2019 10:22:00.530 * Successful partial resynchronization with master.
2655:S 19 May 2019 10:22:00.530 * MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.
- 在进行部分复制时,主节点只需要根据 offset 将复制积压缓冲区的数据补发给从节点即可,主节点打印日志如下:
2496:M 19 May 2019 10:22:00.529 * Replica 127.0.0.1:6391 asks for synchronization
2496:M 19 May 2019 10:22:00.529 * Partial resynchronization request from 127.0.0.1:6391 accepted. Sending 183 bytes of backlog starting from offset 2268.
从日志中,我们可以看出主节点发送了 183 个字节数据给从节点。
psync 命令的执行过程
在 Redis 2.8 以前一直都是通过命令 sync 进行全量复制,但是 Redis 2.8 以后都是通过命令 psync 进行全量复制和部分复制了,所以我们有必要了解下 psync 命令的执行过程,如下图:
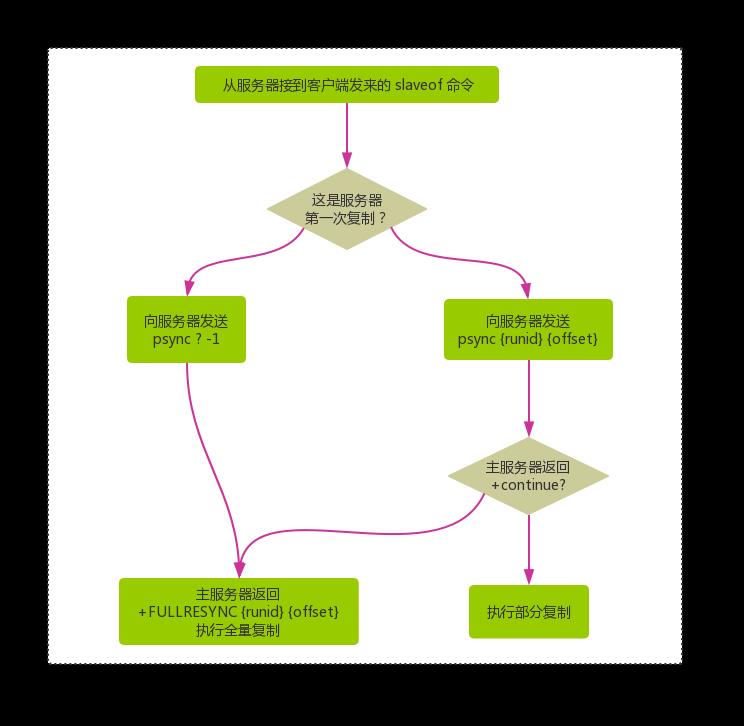
- 首先从节点根据当前状态来决定如何调用 psync 命令
- 如果主从节点从未建立过连接或者之间执行过
slave of none,则从节点发送命令psync ? -1,向主节点请求全量复制。 - 如果主从节点建立过连接,则发送命令
psync {runid} {offset}尝试部分复制,具体是全量还是部分复制,则需要根据主节点的情况来确定
- 如果主从节点从未建立过连接或者之间执行过
- 主节点则根据自身情况来做出不同的响应:
- 如果主节点的版本低于 2.8 ,则响应 -ERR,从节点接受该回复后发送 sync 进行全量复制
- 如果主节点发现请求的命令为
psync ? -1, 则判定该从节点是第一次进行连接,则响应+FULLRESYNC <runid> <offset>,进行全量复制 - 如果主节点比对命令请求的 runid 和自身的 runid 不一致或者一致,但是请求的 offset 不在复制积压缓冲区中,则响应
+FULLRESYNC <runid> <offset>进行全量复制 - 如果主节点比对命令请求的 runid 和自身的 runid 一致,且 offset 也在复制积压缓冲区,则响应
+CONTINUE进行部分复制
到这里,全量复制和部分复制已经介绍完毕了,相信各位对其有了比较深入的理解,下篇小编将分析主从复制的应用和需要注意的地方。
参考资料
- 《Redis 开发与运维》
- 《Redis 设计与实现》
- https://www.cnblogs.com/kismetv/p/9236731.html
以上是关于死磕 Redis----- 主从复制:全量复制和部分复制的主要内容,如果未能解决你的问题,请参考以下文章