字典树的算法实现(附Java源码)
Posted 飞人01_01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字典树的算法实现(附Java源码)相关的知识,希望对你有一定的参考价值。
字典树(前缀树)算法实现
前言
字典树,又称单词查找树,是一个典型的 一对多的字符串匹配算法。“一”指的是一个模式串,“多”指的是多个模板串。字典树经常被用来统计、排序和保存大量的字符串。它利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较。
字典树有3个基本性质:
1、根节点不包含字符,其余的每个节点都包含一个字符;
2、从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
3、每个节点的所有子节点包含的字符都不相同。
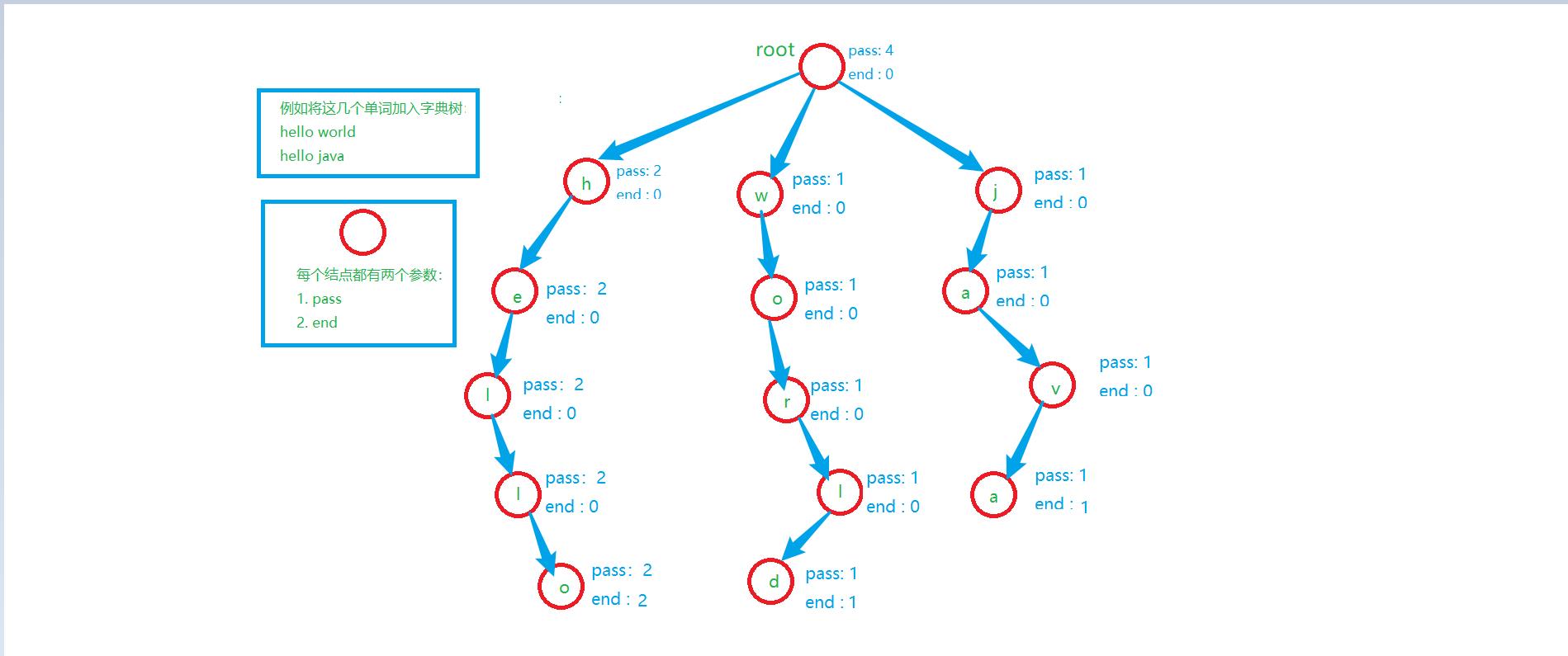
pass参数:代表从这个点经过的单词数量。root根即就是整棵树有多少单词。
end参数: 代表在这个点结束的单词有几个。例如: 上图有两个 hello,在o结点的end参数就是2。
实现的基本功能: 增删查。
算法解析
首先是结点的参数:
public class Node {
public int pass;
public int end;
public Node[] nexts; //下一个字母的地址
public Node() {
pass = 0;
end = 0;
nexts = new Node[26]; //这里我们就以小写字母为例
}
}
下面就是基本功能的实现:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
String[] arr = {"hello", "hello"};
Trie root = new Trie();
for (int i = 0; i < arr.length; i++) {
root.addWord(arr[i]);
}
//root.delWord("hello");
Scanner sc = new Scanner(System.in);
String s = sc.nextLine();
if (root.searchWord(s) != 0) {
System.out.println("该字典树有这个" + s + " 单词");
}
}
public static class Node {
public int pass;
public int end;
public Node[] nexts; //下一个字母的地址
public Node() {
pass = 0;
end = 0;
nexts = new Node[26];
}
}
public static class Trie {
private Node root;
public Trie() {
root = new Node();
}
//增加
public void addWord(String str) {
char[] arr = str.toCharArray();
root.pass++;
Node node = root;
for (char s : arr) {
int index = s - 'a'; //以相应的ASCII码值差值,进行数组的下标存储
if (node.nexts[index] == null) {
node.nexts[index] = new Node();
}
node = node.nexts[index];
node.pass++; //经过这个结点,pass就加1
}
node.end++;
}
//删除
public void delWord(String str) {
//删除之前,应该查询一下这颗树有没有这个单词
while (searchWord(str) != 0) {
char[] arr = str.toCharArray();
Node node = root;
node.pass--;
for (int i = 0; i < str.length(); i++) {
int index = arr[i] - 'a';
node = node.nexts[index];
node.pass--;
}
node.end--;
}
}
//查找
public int searchWord(String str) {
if (str == null) {
return 0;
}
char[] arr = str.toCharArray();
Node node = root;
for (int i = 0; i < str.length(); i++) {
int index = arr[i] - 'a';
if (node.nexts[index] == null) {
return 0;
}
node = node.nexts[index];
}
return node.end; //返回最后那一个结点的end值即可
}
}
}
以上是关于字典树的算法实现(附Java源码)的主要内容,如果未能解决你的问题,请参考以下文章