涛思数据TDengine征稿— ❤️ TDengine 的两大技术创新详解❤️ (建议收藏)
Posted 英雄哪里出来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了涛思数据TDengine征稿— ❤️ TDengine 的两大技术创新详解❤️ (建议收藏)相关的知识,希望对你有一定的参考价值。
- 本文正在参与“拥抱开源|涛思数据TDengine有奖征稿:投稿地址。
文章目录
一、前言
本文将介绍 TDengine 的数据模型。这是 TDengine 的两大技术创新。

二、引例
1、智能电表
- 首先,我们来看一个例子。
- 现在的电表都智能化,中国的智能电表是每隔 15 分钟采集一次,一天采集 96 条。如图所示,代表了三个智能电表的数据:
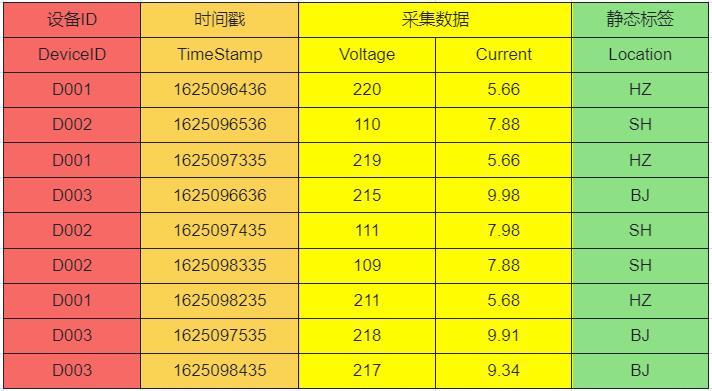
- 这三个设备分别为 D001、D002、D003 ;
2、数据列
- 列数据由 设备号、时间戳、采集数据(电流、电压)、静态标签(区域)组成。
3、数据列分析
对这些数据列进行一个分析,得到:
1)数据是按照时序采集的,且所有数据都带有时间戳;
2)数据是结构化的,并且主要以数字型为主;
3)带有静态标签,例如区域,虽然写的是字符串 HZ,但是完全可以一个数字来代替;
4)数据的时间是无法准确获得的,因为网络延迟等各种原因,采集的时间,到达服务器的时间都是不确定的,因为要同步每个传感器的时间是极其困难的,一般要通过 GPS 才能同步,但是这个其实没有必要这么精确;虽然这么多因素导致时间戳出现误差,但是两条数据的相对时间是可以控制的;
- 根据以上的四点,TDEngine 设计出了一个数据模型,即 一个采集点用一张表。也就是三个设备分成了三张表,如下:
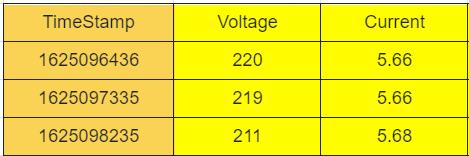
- 第一张表,设备号 D001,地点是 HZ,表数据如下:
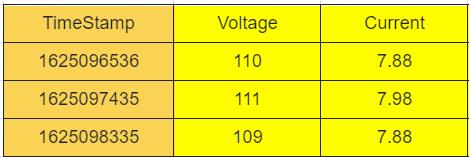
- 第二张表,设备号 D002,地点是 SH,表数据如下:
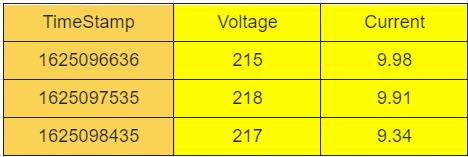
- 第三张表,设备号 D003,地点是 BJ,表数据如下:
- 就是基于这样一个思想,我们来分析一下这样做有哪些好处。
三、技术创新一
- 第一个技术创新是:一个数据采集点一张表。
1、好处
一个数据采集点一张表的好处有以下几个:
1)对于一张表来说,所有数据都是按照时间戳有序的,那么我们就不需要关注断网、网络延迟、同步不准确等问题,因为对于一个设备来说,数据的相对顺序总是不会错的。
2)由于数据都是按照时间戳有序的,数据的写入变成了简单的追加操作。
3)设备ID、静态标签 不需要存储,因为每张表代表一个设备,每个设备的地点以及其它静态信息一定是固定的。
4)每个数值按列的变化范围更小。例如,某个电表在 220V 范围附近波动,某个电表在 110V 范围附近波动,如果把几个电表的数据混合在一起,这个波动范围就很大,但是如果分开,波动范围就会很小。
2、按块存储
- 每张表的记录是按块存储的。如图所示:

- 具体如下:
- 1)每个数据块含有一定数量的记录;
- 2)每个数据块都带有预计算;
- 3)每个数据块都带有 schema ,即数据库的组织和结构;
- 4)一张表会有多个数据块;
- 这样,根据时间索引,很快就能找到某个范围内的数据块。
3、列式存储
- 块内的数据,是采用列式存储的。
- 像普通的 mysql、Oracle 这种数据库,数据是按行存储的,即一行一行的存,存完再存下一行,如图所示:
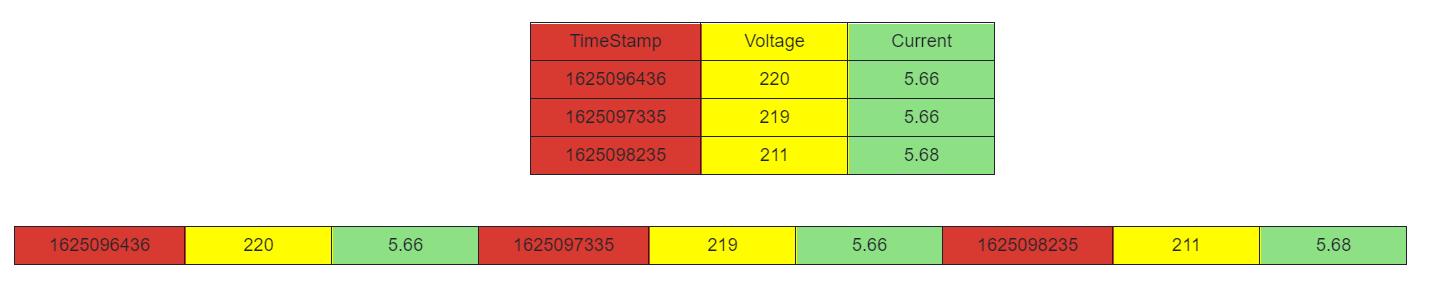
- TDEngine 则不然,它采用列式存储,即一列一列的存,存完再存下一列,如下图所示:
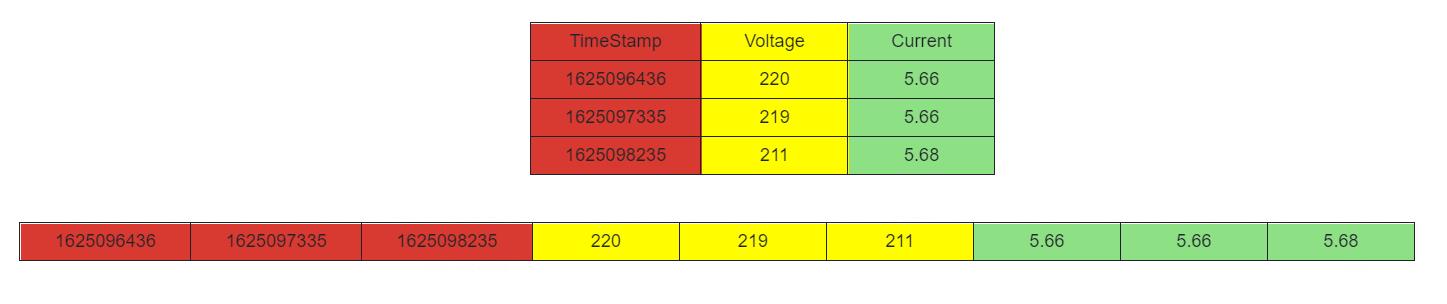
- 这样一来,时间、电压、电流、相位 各自存储在一起。
4、列式存储的优点
- 这样做有什么好处呢?
- 1)提高压缩率;同一列的数据类型相近,根据不同类型的数据,可以采用特定的压缩算法,达到最好的效果;如果用行式存储,由于不知道是什么数据类型,所以只能采用通用的压缩算法。
- 2)大幅度提高分析性能;物联网的数据要分析的时候往往是分析某一个物理量在某个时间段的变化,这种存储方式,相同的物理量在内存中是连续的,所以我们读取出来的时候,能够一下子获取到一个范围中所有的数据。
5、数据模型的三大策略
- 根据以上的分析,我们得出 TDEngine 数据模型的三大策略:
- 1)一个数据采集点采用一张表;
- 2)一张表的数据按块连续存储;
- 3)数据块内的数据采用列式存储;
- 这样保证了单个数据采集点的插入和查询效率是最高的。
6、坏处
- 一个数据采集点一张表的坏处是:由于物联网的数据的表的数据特别大,对于两张表的数据难以聚合,但是聚合数据又是我们需要的,这是 TDEngine 这个引擎的一个巨大技术挑战。这就牵涉到 TDEngine 的第二个技术创新。
四、技术创新二
- 第二个技术创新是:利用超级表对多个数据采集点进行高效聚合。
1、超级表
- 1)定义采集的物理量的数据结构 schema;
- 2)定义静态标签的数据结构 schema;
- 3)以超级表为模板,表的 schema 就是超级表的采集量 schema;
- 4)给静态标签指定具体值;
2、超级表举例
1)模板
- 我们为智能电表这个设备类型,建立一个超级表,采集数据有电流和电压,静态标签是区域,语句如下:
create table st (ts timestamp, curremt float, voltage int) tags (location binary(20));
2)继承表
- 然后,以 st 为模板,创建三个继承表,如下:
create table t1 using st tags( HZ );
create table t2 using st tags( SH );
create table t3 using st tags( BJ );
3) 查询
- 那么,我要查询 HZ 地区的电压平均值就可以这么写:
Select avg(voltage) from st where location = "HZ";
3、标签存储
1)存储策略
- 标签的存储策略如下:
- 1)单独存储,和时序数据分开;
- 2)采用 Key-Value 型存储,便于增删改操作;
- 3)每个数据采集点一条标签记录;
- 4)标签记录集中在一起存储,并建有索引;
2)好处
- 1)和典型的 NOSQL数据库相比,不用重复存储,大幅节省空间;
- 2)做多维聚合分析时,先过滤标签,找到需要聚合的数据采集点,大幅减少聚合的数据集合;
- 3)标签记录总条数等于采集点数目,但是总量不大,完全可以内存中处理掉,进一步提升查询效率;
以上是关于涛思数据TDengine征稿— ❤️ TDengine 的两大技术创新详解❤️ (建议收藏)的主要内容,如果未能解决你的问题,请参考以下文章