教你用python爬取唯品会商品信息,详细教程,仅供学习。
Posted 主打Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了教你用python爬取唯品会商品信息,详细教程,仅供学习。相关的知识,希望对你有一定的参考价值。
教你用python爬取唯品会商品信息,详细教程,仅供学习。
代码展示
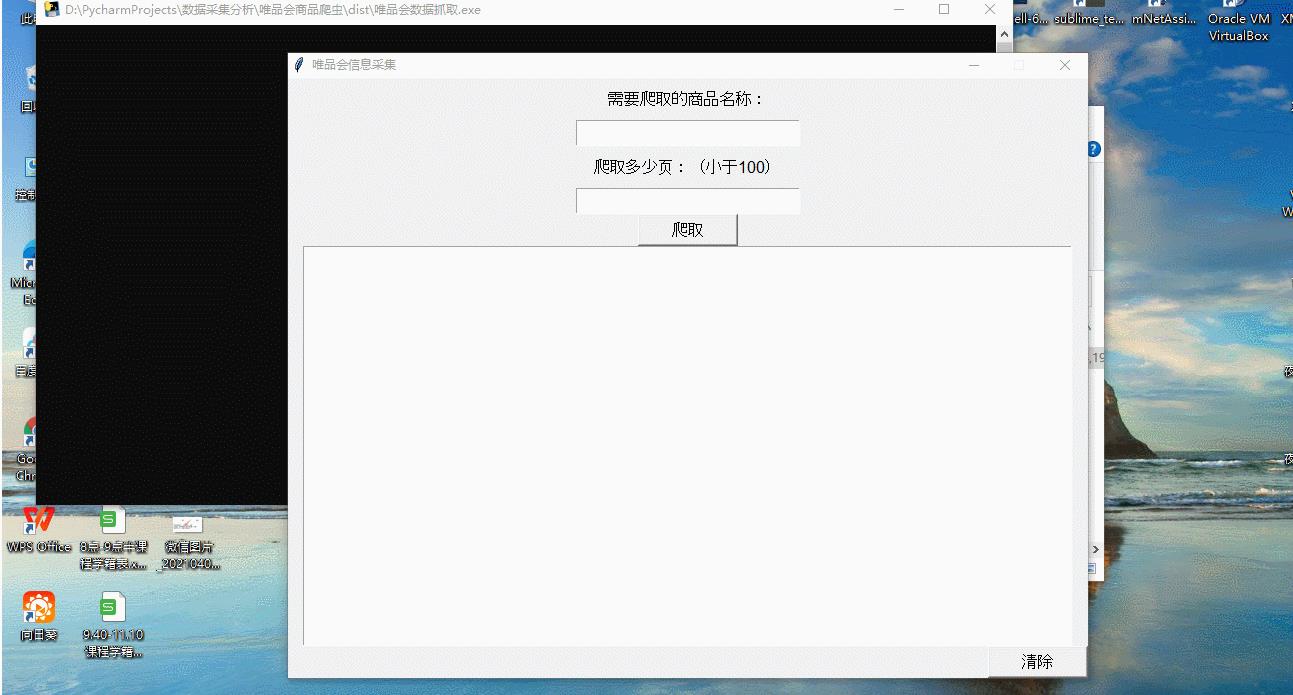
运行结束来个照
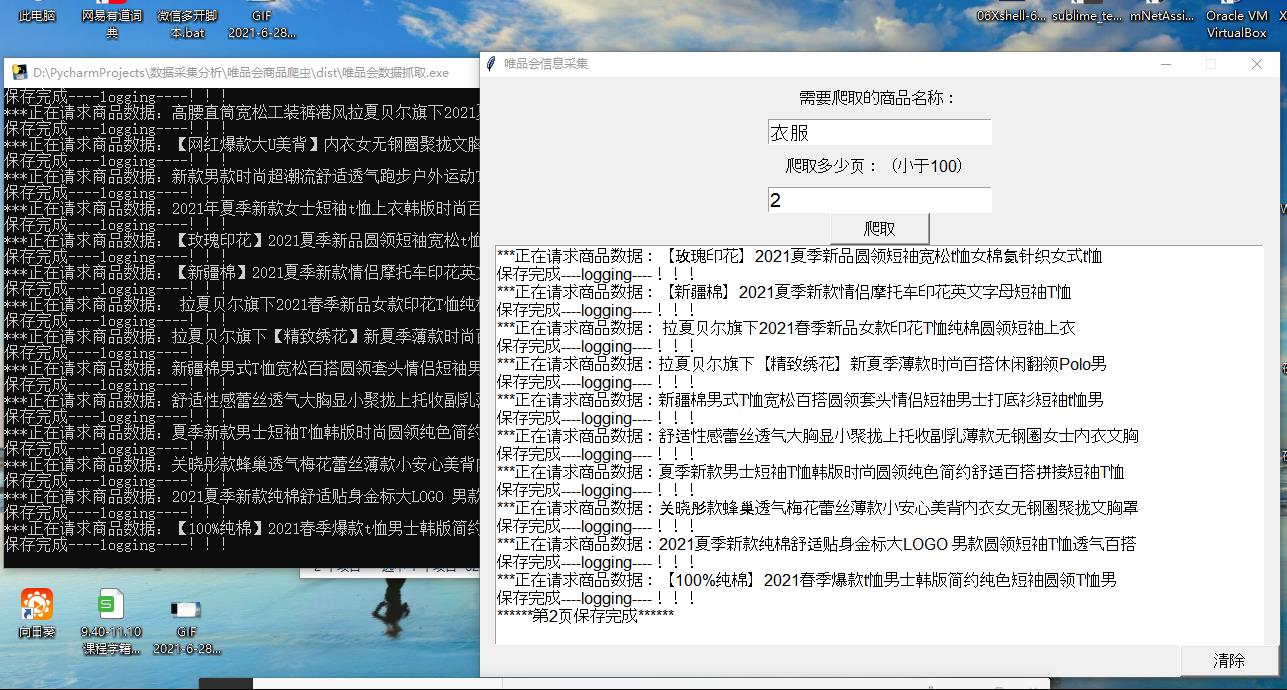
信息保存到表格中
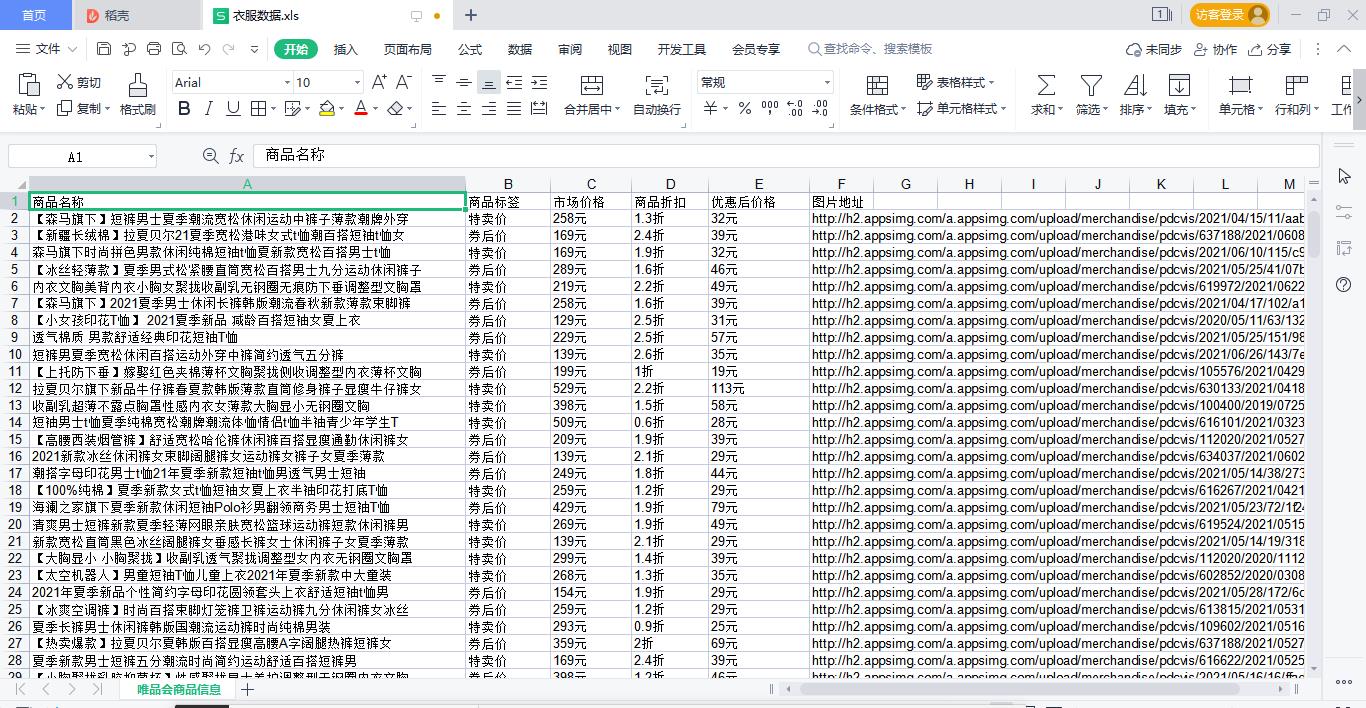
工具使用
开发环境
python3.6
Windows10
开发工具
pycharm
工具包
re,os, tkinter,xlwt
开发思路
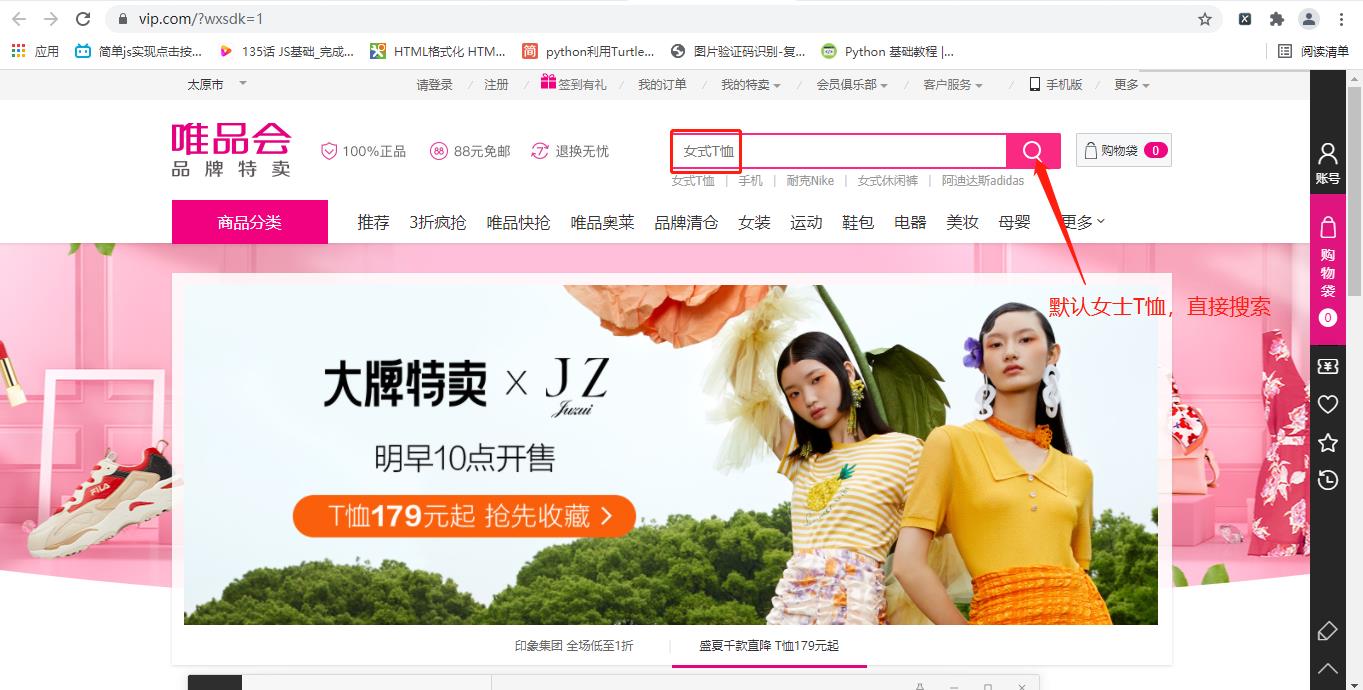
1.进入百度搜索唯品会,进入唯品会的官网,默认女士T恤,直接点击搜索进入如下
2.右侧滚动条一直下拉,滑动到下面的时候页面会自动刷新出商品的数据,这里就体现了ajax交互,说明商品的信息是存放在json接口中,接着拉到底就可以发现翻页的按钮了,如下
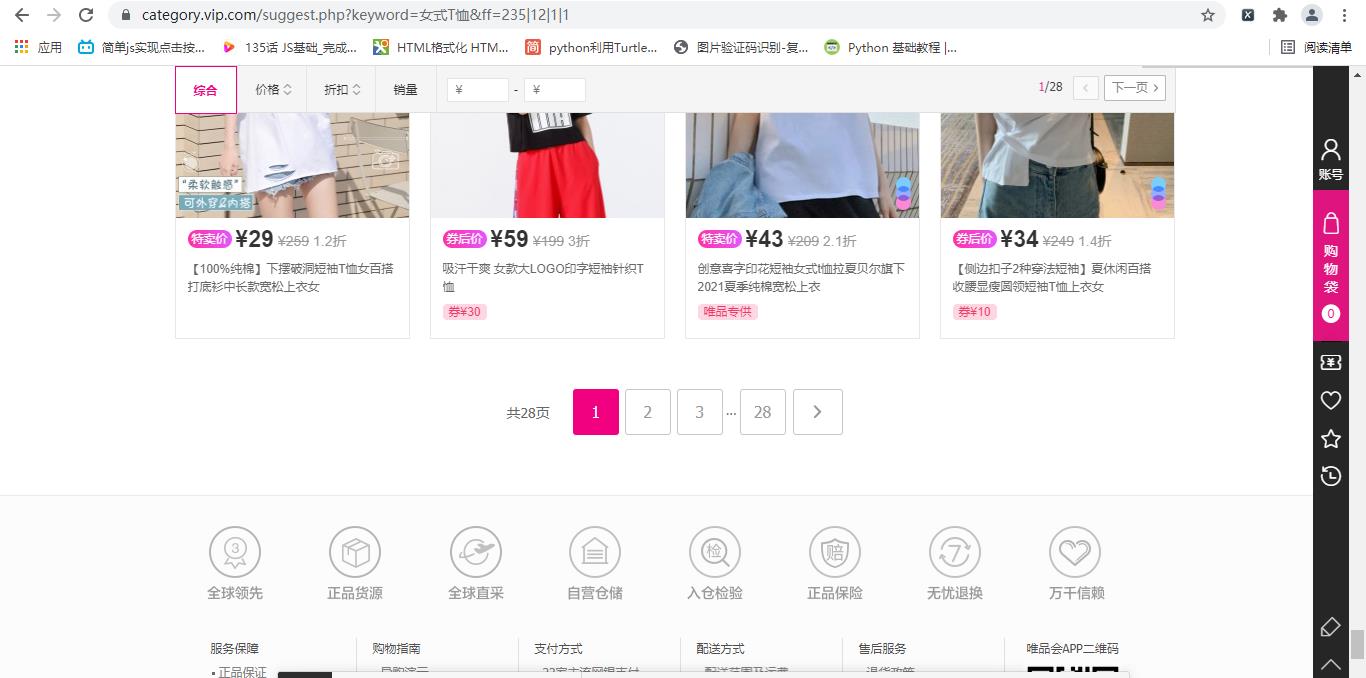
3.右击检查,按照步骤操作, 6步骤里的方框为该页商品的id
拿回start_url = r’https://mapi.vip.com/vips-mobile/rest/shopping/pc/search/product/rank?’
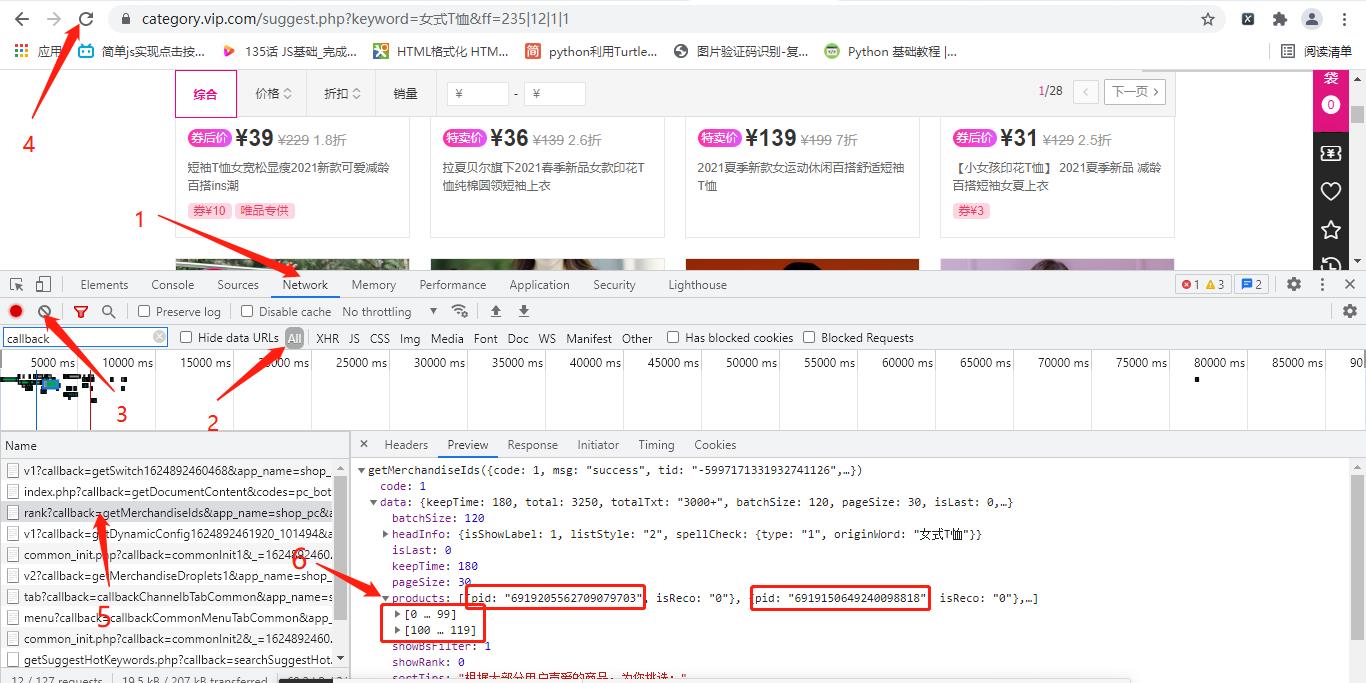
4.继续抓包,找到商品信息对应的数据包,拿回请求的url地址和参数(参数中加入商品的id,这也是为什么要拿回来商品的id)
goods_info_url = ‘https://mapi.vip.com/vips-mobile/rest/shopping/pc/product/module/list/v2?’
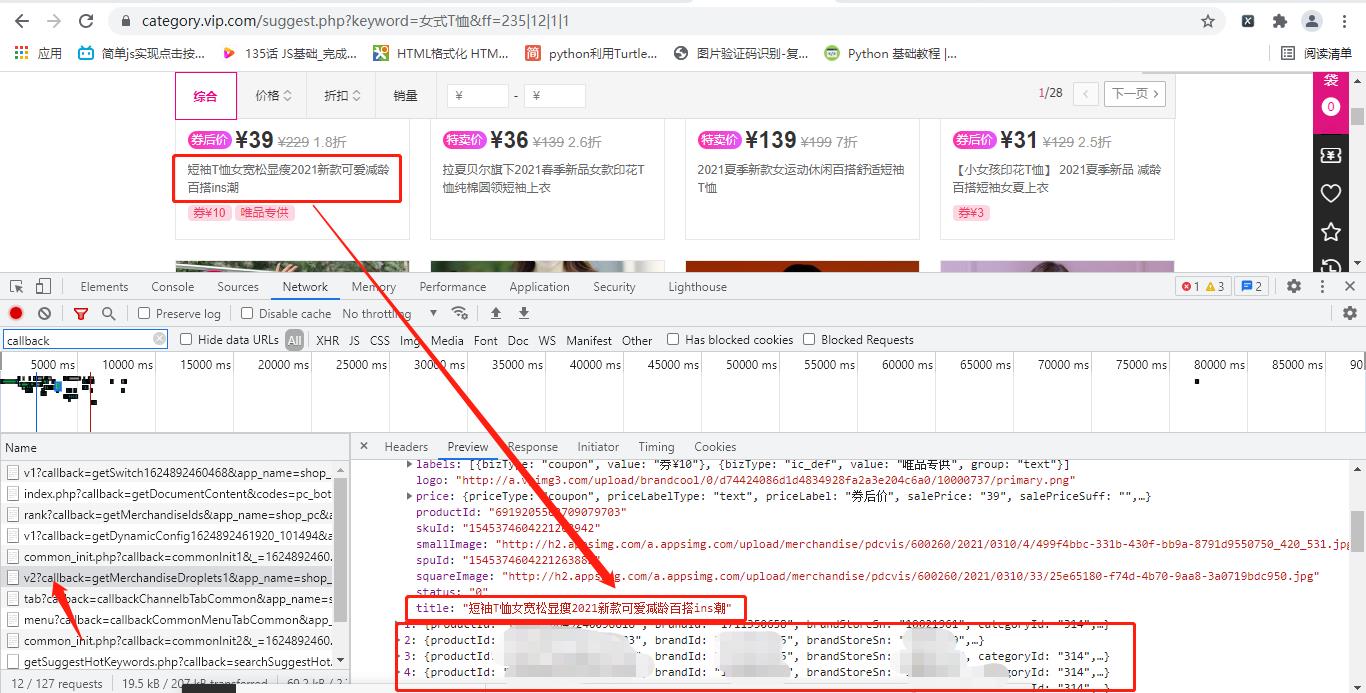
5,翻页 全部的商品的id又存放在第二个rank文件中,首先请求一下这个链接文件,获取商品id信息,然后再重新组合url,最终获取商品详细的信息
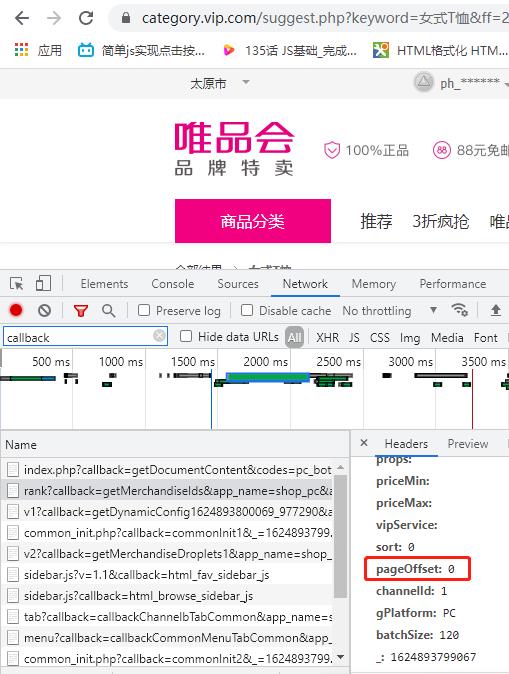
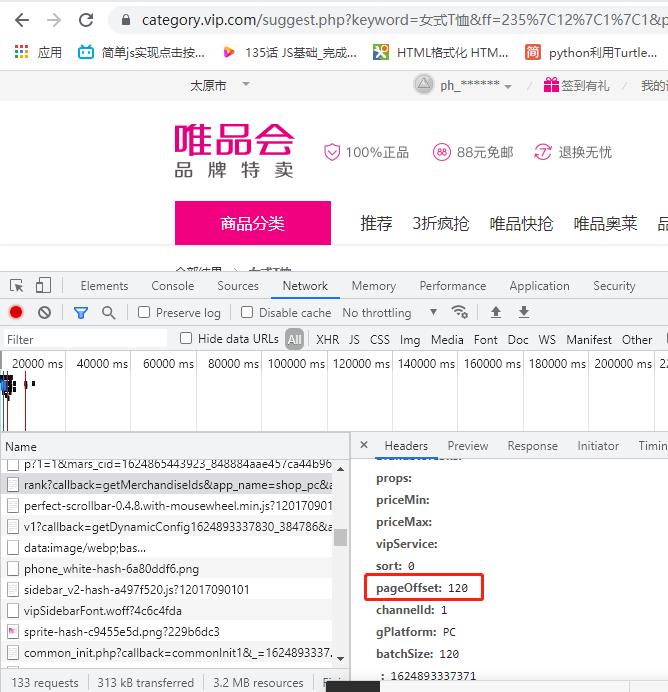
可以发现pageOffset参数是变化的 变化是120
6.保存数据,模板可以拿去用
def save_data(self, data, user_name):
'''
保存数据
'''
os_path_1 = os.getcwd() + '/数据/'
if not os.path.exists(os_path_1):
os.mkdir(os_path_1)
os_path = os_path_1 + user_name + '数据.xls'
if not os.path.exists(os_path):
# 创建新的workbook(其实就是创建新的excel)
workbook = xlwt.Workbook(encoding='utf-8')
# 创建新的sheet表
worksheet1 = workbook.add_sheet("唯品会商品信息", cell_overwrite_ok=True)
borders = xlwt.Borders() # Create Borders
"""定义边框实线"""
borders.left = xlwt.Borders.THIN
borders.right = xlwt.Borders.THIN
borders.top = xlwt.Borders.THIN
borders.bottom = xlwt.Borders.THIN
borders.left_colour = 0x40
borders.right_colour = 0x40
borders.top_colour = 0x40
borders.bottom_colour = 0x40
style = xlwt.XFStyle() # Create Style
style.borders = borders # Add Borders to Style
"""居中写入设置"""
al = xlwt.Alignment()
al.horz = 0x02 # 水平居中
al.vert = 0x01 # 垂直居中
style.alignment = al
# 合并 第0行到第0列 的 第0列到第13列
'''基本详情13'''
# worksheet1.write_merge(0, 0, 0, 13, '基本详情', style)
excel_data_1 = ('商品名称', '商品标签', '市场价格', '商品折扣', '优惠后价格', '图片地址')
for i in range(0, len(excel_data_1)):
worksheet1.col(i).width = 2560 * 3
# 行,列, 内容, 样式
worksheet1.write(0, i, excel_data_1[i], style)
workbook.save(os_path)
# 判断工作表是否存在
if os.path.exists(os_path):
# 打开工作薄
workbook = xlrd.open_workbook(os_path)
# 获取工作薄中所有表的个数
sheets = workbook.sheet_names()
for i in range(len(sheets)):
for name in data.keys():
worksheet = workbook.sheet_by_name(sheets[i])
# 获取工作薄中所有表中的表名与数据名对比
if worksheet.name == name:
# 获取表中已存在的行数
rows_old = worksheet.nrows
# 将xlrd对象拷贝转化为xlwt对象
new_workbook = copy(workbook)
# 获取转化后的工作薄中的第i张表
new_worksheet = new_workbook.get_sheet(i)
for num in range(0, len(data[name])):
new_worksheet.write(rows_old, num, data[name][num])
new_workbook.save(os_path)
print('保存完成----logging----!!!')
最后代码打包一下就可以发给客户了(pyinstaller)

源码展示:
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter as tk
import re, xlwt, os, xlrd
from xlutils.copy import copy
from requests_html import HTMLSession
session = HTMLSession()
class WPHSpider(object):
def __init__(self):
"""定义可视化窗口,并设置窗口和主题大小布局"""
self.window = tk.Tk()
self.window.title('唯品会信息采集')
self.window.geometry('800x600')
"""创建label_user按钮,与说明书"""
self.label_user = tk.Label(self.window, text='需要爬取的商品名称:', font=('Arial', 12), width=30, height=2)
self.label_user.pack()
"""创建label_user关联输入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""创建label_passwd按钮,与说明书"""
self.label_passwd = tk.Label(self.window, text="爬取多少页:(小于100)", font=('Arial', 12), width=30, height=2)
self.label_passwd.pack()
"""创建label_passwd关联输入"""
self.entry_passwd = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_passwd.pack(after=self.label_passwd)
"""创建Text富文本框,用于按钮操作结果的展示"""
self.text1 = tk.Text(self.window, font=('Arial', 12), width=85, height=22)
self.text1.pack()
"""定义按钮1,绑定触发事件方法"""
self.button_1 = tk.Button(self.window, text='爬取', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定义按钮2,绑定触发事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
self.start_url = r'https://mapi.vip.com/vips-mobile/rest/shopping/pc/search/product/rank?'
self.goods_info_url = 'https://mapi.vip.com/vips-mobile/rest/shopping/pc/product/module/list/v2?'
self.headers = {
'cookie': '输入登录后的你的cookie值',
'referer': '',
'user-agent': ''
}
def parse_hit_click_1(self):
"""定义触发事件1,调用main函数"""
user_name = self.entry_user.get()
pass_wd = int(self.entry_passwd.get())
self.request_start_url_get_pid(user_name, pass_wd)
def request_start_url_get_pid(self, user_name, pass_wd):
'''
请求获取 pid
'''
print('------------------------------------------' + '\\n')
for page in range(1, pass_wd+1):
self.params_pid = {
"callback": "getMerchandiseIds",
"app_name": "shop_pc",
"app_version": "4.0",
"warehouse": "VIP_HZ",
"fdc_area_id": "104103101",
"client": "pc",
"mobile_platform": "1",
"province_id": "104103",
"api_key": "70f71280d5d547b2a7bb370a529aeea1",
"user_id": "",
"mars_cid": "1613809051869_ecad06e028e7248cee802bb1c6414931",
"wap_consumer": "a",
"standby_id": "nature",
"keyword": user_name,
"lv3CatIds": "",
"lv2CatIds": "",
"lv1CatIds": "",
"brandStoreSns": "",
"props": "",
"priceMin": "",
"priceMax": "",
"vipService": "",
"sort": "0",
"pageOffset": (page-1)*120,
"channelId": "1",
"gPlatform": "PC",
"batchSize": "120",
"_": "1613809204088",
}
response_pid = session.get(self.start_url, headers=self.headers, params=self.params_pid).content.decode()
for pid in re.findall(r'"pid":"(.*?)"', response_pid):
# pprint(pid)
self.request_goods_info_url(pid, user_name, pass_wd)
self.text1.insert("insert", r'******第{}页保存完成******'.format(page))
self.text1.insert("insert", '\\n')
def request_goods_info_url(self, pid, user_name, pass_wd):
'''
请求获取商品信息数据
'''
self.params_info = {
"callback": "getMerchandiseDroplets3",
"app_name": "shop_pc",
"app_version": "4.0",
"warehouse": "VIP_HZ",
"fdc_area_id": "104103101",
"client": "pc",
"mobile_platform": "1",
"province_id": "104103",
"api_key": "70f71280d5d547b2a7bb370a529aeea1",
"user_id": "449181505",
"mars_cid": "1613809051869_ecad06e028e7248cee802bb1c6414931",
"wap_consumer": "b",
"productIds": "{}".format(pid),
"scene": "search",
"standby_id": "nature",
"extParams": '{"stdSizeVids":"","preheatTipsVer":"3","couponVer":"v2","exclusivePrice":"1","iconSpec":"2x"}',
"context": "",
"_": "1613810807777",
}
response_info = session.get(self.goods_info_url, headers=self.headers, params=self.params_info).content.decode()
# pprint(response_info)
self.parse_get_info(response_info, user_name, pass_wd)
def parse_get_info(self, response_info, user_name, pass_wd):
'''
解析获取商品信息字段
'''
names = re.findall(r'"title":"(.*?)"', response_info)
price_labels = re.findall(r'"priceLabel":"(.*?)"', response_info)
market_prices = re.findall(r'"marketPrice":"(.*?)"', response_info)
discounts = re.findall(r'"saleDiscount":"(.*?)"', response_info)
sale_prices = re.findall(r'"salePrice":"(.*?)"', response_info)
image_urls = re.findall(r'"squareImage":"(.*?)"', response_info)
# print(names, price_labels, market_prices, discounts, sale_prices, image_urls, sep='| ')
print(r'***正在请求商品数据:{}'.format(names[0]))
self.text1.insert("insert", r'***正在请求商品数据:{}'.format(names[0]))
self.text1.insert("insert", '\\n')
for name, price_label, market_price, discount, sale_price, image_url in zip(names, price_labels, market_prices, discounts, sale_prices, image_urls):
a = [name, price_label, market_price+'元', discount, sale_price+'元', image_url]
b = {"唯品会商品信息": a}
self.save_data(b, user_name)
def save_data(self, data, user_name):
'''
保存数据
'''
os_path_1 = os.getcwd() + '/数据/'
if not os.path.exists(os_path_1):
os.mkdir(os_path_1)
os_path = os_path_1 + user_name + '数据.xls'
if not os.path.exists(os_path):
# 创建新的workbook(其实就是创建新的excel)
workbook = xlwt.Workbook(encoding='utf-8')
# 创建新的sheet表
worksheet1 = workbook.add_sheet("唯品会商品信息", cell_overwrite_ok=True)
borders = xlwt.Borders() # Create Borders
"""定义边框实线"""
borders.left = xlwt.Borders.THIN
borders.right = xlwt.Borders.THIN
borders.top = xlwt.Borders.THIN
borders.bottom = xlwt.Borders.THIN
borders.left_colour = 0x40
borders.right_colour = 0x40
borders.top_colour = 0x40
borders.bottom_colour = 0x40
style = xlwt.XFStyle() # Create Style
style.borders = borders # Add Borders to Style
"""居中写入设置"""
al = xlwt.Alignment()
al.horz = 0x02 # 水平居中
al.vert = 0x01 # 垂直居中
style.alignment = al
# 合并 第0行到第0列 的 第0列到第13列
'''基本详情13'''
# worksheet1.write_merge(0, 0, 0, 13, '基本详情', style)
excel_data_1 = ('商品名称', '商品标签', '市场价格', '商品折扣', '优惠后价格', '图片地址')
for i in range(0, len(excel_data_1)):
worksheet1.col(i).width = 2560 * 3
# 行,列, 内容, 样式
worksheet1.write(0, i, excel_data_1[i], style)
workbook.save(os_path)
# 判断工作表是否存在
if os.path.exists(os_path):
# 打开工作薄
workbook = xlrd.open_workbook(os_path)
# 获取工作薄中所有表的个数
sheets = workbook.sheet_names()
for i in range(len(sheets)):
for name in data.keys():
worksheet = workbook.sheet_by_name(sheets[i])
# 获取工作薄中所有表中的表名与数据名对比
if worksheet.name == name:
# 获取表中已存在的行数
rows_old = worksheet.nrows
# 将xlrd对象拷贝转化为xlwt对象
new_workbook = copy(workbook)
# 获取转化后的工作薄中的第i张表
new_worksheet = new_workbook.get_sheet(i)
for num in range(0, len(data[name])):
new_worksheet.write(rows_old, num, data[name][num])
new_workbook.save(os_path)
print('保存完成----logging----!!!')
self.text1.insert("insert", '保存完成----logging----!!!')
self.text1.insert("insert", '\\n')
def parse_hit_click_2(self):
"""定义触发事件2,删除文本框中内容"""
self.entry_user.delete(0, "end")
self.en以上是关于教你用python爬取唯品会商品信息,详细教程,仅供学习。的主要内容,如果未能解决你的问题,请参考以下文章