Flink1.12-四大基石详解
Posted 一只楠喃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink1.12-四大基石详解相关的知识,希望对你有一定的参考价值。
Flink之所以能这么流行,离不开它最重要的四个基石:Checkpoint、State、Time、Window。

Flink-Window
在流处理应用中,数据是连续不断的,有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。
在这种情况下,我们必须定义一个窗口(window),用来收集最近1分钟内的数据,并对这个窗口内的数据进行计算。
1.1 按照time和count分类
time-window:时间窗口:根据时间划分窗口,如:每xx分钟统计最近xx分钟的数据
count-window:数量窗口:根据数量划分窗口,如:每xx个数据统计最近xx个数据

1.2 按照slide和size分类
窗口有两个重要的属性: 窗口大小size和滑动间隔slide,根据它们的大小关系可分为:
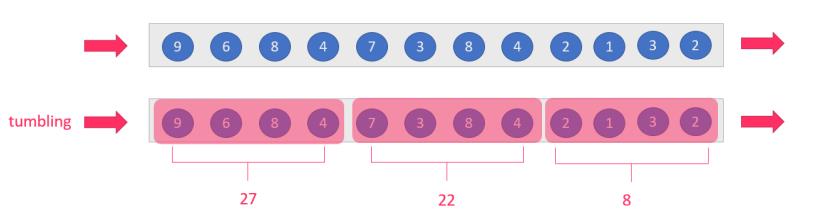
tumbling-window:滚动窗口:size=slide,如:每隔10s统计最近10s的数据
sliding-window:滑动窗口:size>slide,如:每隔5s统计最近10s的数据
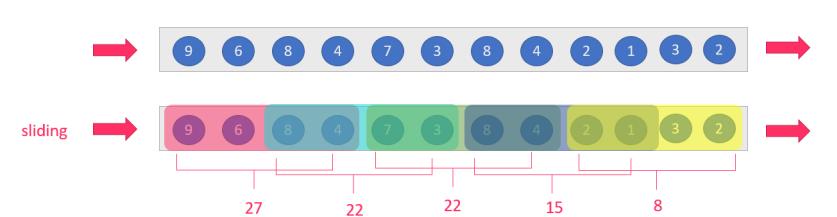
注意:当size<slide的时候,如每隔15s统计最近10s的数据,那么中间5s的数据会丢失,所有开发中不用
1.3 总结
按照上面窗口的分类方式进行组合,可以得出如下的窗口:
1.基于时间的滚动窗口tumbling-time-window–用的较多
2.基于时间的滑动窗口sliding-time-window–用的较多
3.基于数量的滚动窗口tumbling-count-window–用的较少
4.基于数量的滑动窗口sliding-count-window–用的较少
注意:Flink还支持一个特殊的窗口:Session会话窗口,需要设置一个会话超时时间,如30s,则表示30s内没有数据到来,则触发上个窗口的计算
1.4 案例演示-基于时间的滚动和滑动窗口
需求:
nc -lk 9999
有如下数据表示:
信号灯编号和通过该信号灯的车的数量
9,3
9,2
9,7
4,9
2,6
1,5
2,3
5,7
5,4
需求1:每5秒钟统计一次,最近5秒钟内,各个路口通过红绿灯汽车的数量–基于时间的滚动窗口
需求2:每5秒钟统计一次,最近10秒钟内,各个路口通过红绿灯汽车的数量–基于时间的滑动窗口
代码实现:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
/**
* Author SKY
* Desc 演示基于时间的滚动和滑动窗口
*/
public class WindowDemo_1_2 {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> lines = env.socketTextStream("node1", 9999);
//TODO 2.transformation
SingleOutputStreamOperator<CartInfo> carDS = lines.map(new MapFunction<String, CartInfo>() {
@Override
public CartInfo map(String value) throws Exception {
String[] arr = value.split(",");
return new CartInfo(arr[0], Integer.parseInt(arr[1]));
}
});
//注意: 需求中要求的是各个路口/红绿灯的结果,所以需要先分组
//carDS.keyBy(car->car.getSensorId())
KeyedStream<CartInfo, String> keyedDS = carDS.keyBy(CartInfo::getSensorId);
// * 需求1:每5秒钟统计一次,最近5秒钟内,各个路口通过红绿灯汽车的数量--基于时间的滚动窗口
//keyedDS.timeWindow(Time.seconds(5))
SingleOutputStreamOperator<CartInfo> result1 = keyedDS
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum("count");
// * 需求2:每5秒钟统计一次,最近10秒钟内,各个路口通过红绿灯汽车的数量--基于时间的滑动窗口
SingleOutputStreamOperator<CartInfo> result2 = keyedDS
//of(Time size, Time slide)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5)))
.sum("count");
//TODO 3.sink
//result1.print();
result2.print();
//TODO 4.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class CartInfo {
private String sensorId;//信号灯id
private Integer count;//通过该信号灯的车的数量
}
}
1.5 案例演示-基于数量的滚动和滑动窗口
需求:
需求1:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现5次进行统计–基于数量的滚动窗口
需求2:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现3次进行统计–基于数量的滑动窗口
代码实现:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Author SKY
* Desc 演示基于数量的滚动和滑动窗口
*/
public class WindowDemo_3_4 {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> lines = env.socketTextStream("node1", 9999);
//TODO 2.transformation
SingleOutputStreamOperator<CartInfo> carDS = lines.map(new MapFunction<String, CartInfo>() {
@Override
public CartInfo map(String value) throws Exception {
String[] arr = value.split(",");
return new CartInfo(arr[0], Integer.parseInt(arr[1]));
}
});
//注意: 需求中要求的是各个路口/红绿灯的结果,所以需要先分组
//carDS.keyBy(car->car.getSensorId())
KeyedStream<CartInfo, String> keyedDS = carDS.keyBy(CartInfo::getSensorId);
// * 需求1:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现5次进行统计--基于数量的滚动窗口
SingleOutputStreamOperator<CartInfo> result1 = keyedDS
.countWindow(5)
.sum("count");
// * 需求2:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现3次进行统计--基于数量的滑动窗口
SingleOutputStreamOperator<CartInfo> result2 = keyedDS
.countWindow(5,3)
.sum("count");
//TODO 3.sink
//result1.print();
result2.print();
//TODO 4.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class CartInfo {
private String sensorId;//信号灯id
private Integer count;//通过该信号灯的车的数量
}
}
1.6 案例演示-会话窗口
需求:设置会话超时时间为10s,10s内没有数据到来,则触发上个窗口的计算。
代码实现:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
/**
* Author SKY
* Desc 演示会话窗口
*/
public class WindowDemo_5 {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> lines = env.socketTextStream("node1", 9999);
//TODO 2.transformation
SingleOutputStreamOperator<CartInfo> carDS = lines.map(new MapFunction<String, CartInfo>() {
@Override
public CartInfo map(String value) throws Exception {
String[] arr = value.split(",");
return new CartInfo(arr[0], Integer.parseInt(arr[1]));
}
});
//注意: 需求中要求的是各个路口/红绿灯的结果,所以需要先分组
//carDS.keyBy(car->car.getSensorId())
KeyedStream<CartInfo, String> keyedDS = carDS.keyBy(CartInfo::getSensorId);
//需求:设置会话超时时间为10s,10s内没有数据到来,则触发上个窗口的计算(前提是上一个窗口得有数据!)
SingleOutputStreamOperator<CartInfo> result = keyedDS.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.sum("count");
//TODO 3.sink
result.print();
//TODO 4.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class CartInfo {
private String sensorId;//信号灯id
private Integer count;//通过该信号灯的车的数量
}
}
Flink-Time与Watermaker
2.1 Time的分类
事件时间EventTime: 事件真真正正发生产生的时间
摄入时间IngestionTime: 事件到达Flink的时间
处理时间ProcessingTime: 事件真正被处理/计算的时间
2.2 EventTime的重要性
示例一
– 假设,你正在去往地下停车场的路上,并且打算用手机点一份外卖。选好了外卖后,你就用在线支付功能付款了,这个时候是11点59分。恰好这时,你走进了地下停车库,而这里并没有手机信号。因此外卖的在线支付并没有立刻成功,而支付系统一直在Retry重试“支付”这个操作。当你找到自己的车并且开出地下停车场的时候,已经是12点01分了。这个时候手机重新有了信号,手机上的支付数据成功发到了外卖在线支付系统,支付完成。
在上面这个场景中你可以看到,支付数据的事件时间是11点59分,而支付数据的处理时间是12点01分
问题:
如果要统计12之前的订单金额,那么这笔交易是否应被统计?
答案:
应该被统计,因为该数据的真真正正的产生时间为11点59分,即该数据的事件时间为11点59分,
事件时间能够真正反映/代表事件的本质! 所以一般在实际开发中会以事件时间作为计算标准
示例二
一条错误日志的内容为:
2020-11:11 22:59:00 error NullPointExcep --事件时间
进入Flink的时间为2020-11:11 23:00:00 --摄入时间
到达Window的时间为2020-11:11 23:00:10 --处理时间
问题:
对于业务来说,要统计1h内的故障日志个数,哪个时间是最有意义的?
答案:
EventTime事件时间,因为bug真真正正产生的时间就是事件时间,只有事件时间才能真正反映/代表事件的本质!
示例三
某 App 会记录用户的所有点击行为,并回传日志(在网络不好的情况下,先保存在本地,延后回传)。A用户在 11:01:00 对 App 进行操作,B用户在 11:02:00 操作了 App,但是A用户的网络不太稳定,回传日志延迟了,导致我们在服务端先接受到B用户的消息,然后再接受到A用户的消息,消息乱序了。
问题:
如果这个是一个根据用户操作先后顺序,进行抢购的业务,那么是A用户成功还是B用户成功?
答案:
应该算A成功,因为A确实比B操作的早,但是实际中考虑到实现难度,可能直接按B成功算,也就是说,实际开发中希望基于事件时间来处理数据,但因为数据可能因为网络延迟等原因,出现了乱序,按照事件时间处理起来有难度!
总结
实际开发中我们希望基于事件时间来处理数据,但因为数据可能因为网络延迟等原因,出现了乱序或延迟到达,那么可能处理的结果不是我们想要的甚至出现数据丢失的情况,所以需要一种机制来解决一定程度上的数据乱序或延迟到底的问题!也就是我们接下来要学习的Watermaker水印机制/水位线机制。
2.3什么是Watermark?
Watermaker就是给数据再额外的加的一个时间列
也就是Watermaker是个时间戳!
2.4如何计算Watermaker?
Watermaker = 数据的事件时间 - 最大允许的延迟时间或乱序时间
注意:后面通过源码会发现,准确来说:Watermaker = 当前窗口的最大的事件时间 - 最大允许的延迟时间或乱序时间
这样可以保证Watermaker水位线会一直上升(变大),不会下降。
2.5 图解Watermaker

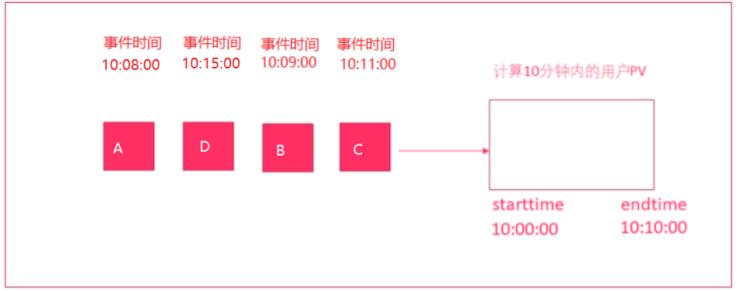

2.6 Watermaker案例演示
需求:
有订单数据,格式为: (订单ID,用户ID,时间戳/事件时间,订单金额)
要求每隔5s,计算5秒内,每个用户的订单总金额
并添加Watermaker来解决一定程度上的数据延迟和数据乱序问题。
代码实现:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
import java.util.Random;
import java.util.UUID;
/**
* Author SKY
* Desc 演示基于事件时间的窗口计算+Watermaker解决一定程度上的数据乱序/延迟到达的问题
*/
public class WatermakerDemo01 {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStreamSource<Order> orderDS = env.addSource(new SourceFunction<Order>() {
private boolean flag = true;
@Override
public void run(SourceContext<Order> ctx) throws Exception {
Random random = new Random();
while (flag) {
String orderId = UUID.randomUUID().toString();
int userId = random.nextInt(2);
int money = random.nextInt(101);
//随机模拟延迟
long eventTime = System.currentTimeMillis() - random.nextInt(5) * 1000;
ctx.collect(new Order(orderId, userId, money, eventTime));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
flag = false;
}
});
//TODO 2.transformation
//老版本API
/*DataStream<Order> watermakerDS = orderDS.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<Order>(Time.seconds(3)) {//最大允许的延迟时间或乱序时间
@Override
public long extractTimestamp(Order element) {
return element.eventTime;
//指定事件时间是哪一列,Flink底层会自动计算:
//Watermaker = 当前最大的事件时间 - 最大允许的延迟时间或乱序时间
}
});*/
//注意:下面的代码使用的是Flink1.12中新的API
//每隔5s计算最近5s的数据求每个用户的订单总金额,要求:基于事件时间进行窗口计算+Watermaker
//env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);//在新版本中默认就是EventTime
//设置Watermarker = 当前最大的事件时间 - 最大允许的延迟时间或乱序时间
SingleOutputStreamOperator<Order> orderDSWithWatermark = orderDS.assignTimestampsAndWatermarks(
WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(3))//指定maxOutOfOrderness最大无序度/最大允许的延迟时间/乱序时间
.withTimestampAssigner((order, timestamp) -> order.getEventTime())//指定事件时间列
);
SingleOutputStreamOperator<Order> result = orderDSWithWatermark.keyBy(Order::getUserId)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.sum("money");
//TODO 3.sink
result.print();
//TODO 4.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Order {
private String orderId;
private Integer userId;
private Integer money;
private Long eventTime;
}
}
2.7 Allowed-Lateness案例演示-严重数据的乱序和延迟问题处理
需求:
有订单数据,格式为: (订单ID,用户ID,时间戳/事件时间,订单金额),要求每隔5s,计算5秒内,每个用户的订单总金额,并添加Watermaker来解决一定程度上的数据延迟和数据乱序问题。并使用OutputTag+allowedLateness解决数据丢失问题
代码实现:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
import java.util.Random;
import java.util.UUID;
/**
* Author SKY
* Desc 演示基于事件时间的窗口计算+Watermaker解决一定程度上的数据乱序/延迟到达的问题
* 并使用outputTag + allowedLateness来解决数据丢失问题(解决迟到/延迟严重的数据的丢失问题)
*/
public class WatermakerDemo03 {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStreamSource<Order> orderDS = env.addSource(new SourceFunction<Order>() {
private boolean flag = true;
@Override
public void run(SourceContext<Order> ctx) throws Exception {
Random random = new Random();
while (flag) {
String orderId = UUID.randomUUID().toString();
int userId = random.nextInt(2);
int money = random.nextInt(101);
//随机模拟延迟-有可能会很严重
long eventTime = System.currentTimeMillis() - random.nextInt(20) * 1000;
ctx.collect(new Order(orderId, userId, money, eventTime));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
flag = false;
}
});
//TODO 2.transformation
//注意:下面的代码使用的是Flink1.12中新的API
//每隔5s计算最近5s的数据求每个用户的订单总金额,要求:基于事件时间进行窗口计算+Watermaker
//env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);//在新版本中默认就是EventTime
//设置Watermarker = 当前最大的事件时间 - 最大允许的延迟时间或乱序时间
SingleOutputStreamOperator<Order> orderDSWithWatermark = orderDS.assignTimestampsAndWatermarks(
WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(3))//指定maxOutOfOrderness最大无序度/最大允许的延迟时间/乱序时间
.withTimestampAssigner((order, timestamp) -> order.getEventTime())//指定事件时间列
);
//业务操作
//TODO 准备一个outputTag用来存放迟到严重的数据
OutputTag<Order> seriousLateOutputTag = new OutputTag<Order>("seriousLate", TypeInformation.of(Order.class));
SingleOutputStreamOperator<Order> result1 = orderDSWithWatermark
.keyBy(Order::getUserId)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(3))
.sideOutputLateData(seriousLateOutputTag)
.sum("money");
DataStream<Order> result2 = result1.getSideOutput(seriousLateOutputTag);
//TODO 3.sink
result1.print("正常的/迟到不严重数据");
result2.print("迟到严重的数据并丢弃后单独收集的数据");
//TODO 4.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Order {
private String orderId;
private Integer userId;
private Integer money;
private Long eventTime;
}
}
Flink-State状态管理
状态的分类
从Flink是否接管角度:可以分为
ManagedState(托管状态) ,RawState(原始状态)
两者的区别如下:
1.从状态管理方式的方式来说,Managed State 由 Flink Runtime 管理,自动存储,自动恢复,在内存管理上有优化;而 Raw State 需要用户自己管理,需要自己序列化,Flink 不知道 State 中存入的数据是什么结构,只有用户自己知道,需要最终序列化为可存储的数据结构。
2.从状态数据结构来说,Managed State 支持已知的数据结构,如 Value、List、Map 等。而 Raw State只支持字节数组 ,所有状态都要转换为二进制字节数组才可以。
3.从推荐使用场景来说,Managed State 大多数情况下均可使用,而 Raw State 是当 Managed State 不够用时,比如需要自定义 Operator 时,才会使用 Raw State。
在实际生产中,都只推荐使用ManagedState。
Managed State 分为两种,Keyed State 和 Operator State
(Raw State都是Operator State)
Keyed State 代码示例
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Author SKY
* Desc 使用KeyState中的ValueState获取流数据中的最大值/实际中可以使用maxBy即可
*/
public class StateDemo01_KeyState {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<Tuple2<String, Long>> tupleDS = env.fromElements(
Tuple2.of("北京", 1L),
Tuple2.of("上海", 2L),
Tuple2.of("北京", 6L),
Tuple2.of("上海", 8L),
Tuple2.of("北京", 3L),
Tuple2.of("上海", 4L)
);
//TODO 2.transformation
//需求:求各个城市的value最大值
//实际中使用maxBy即可
DataStream<Tuple2<String, Long>> result1 = tupleDS.keyBy(t -> t.f0).maxBy(1);
//学习时可以使用KeyState中的ValueState来实现maxBy的底层
DataStream<Tuple3<String, Long, Long>> result2 = tupleDS.keyBy(t -> t.f0).map(new RichMapFunction<Tuple2<String, Long>, Tuple3<String, Long, Long>>() {
//-1.定义一个状态用来存放最大值
private ValueState<Long> maxValueState;
//-2.状态初始化
@Override
public void open(Configuration parameters) throws Exception {
//创建状态描述器
ValueStateDescriptor stateDescriptor = new ValueStateDescriptor("maxValueState", Long.class);
//根据状态描述器获取/初始化状态
maxValueState = getRuntimeContext().getState(stateDescriptor);
}
//-3.使用状态
@Override
public Tuple3<String, Long, Long> map(Tuple2<String, Long> value) throws Exception {
Long currentValue = value.f1;
//获取状态
Long historyValue = maxValueState.value();
//判断状态
if (historyValue == null || currentValue > historyValue) {
historyValue = currentValue;
//更新状态
maxValueState.update(historyValue);
return Tuple3.of(value.f0, currentValue, historyValue);
} else {
return Tuple3.of(value.f0, currentValue, historyValue);
}
}
});
//TODO 3.sink
//result1.print();
//4> (北京,6)
//1> (上海,8)
result2.print();
//1> (上海,xxx,8)
//4> (北京,xxx,6)
//TODO 4.execute
env.execute();
}
}
OperatorState 代码示例
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.util.Iterator;
/**
* Author SKY
* Desc 使用OperatorState中的ListState模拟KafkaSource进行offset维护
*/
public class StateDemo02_OperatorState {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);//并行度设置为1方便观察
//下面的Checkpoint和重启策略配置先直接使用,下次课学
env.enableCheckpointing(1000);//每隔1s执行一次Checkpoint
env.setStateBackend(new FsStateBackend("file:///D:/ckp"));
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//固定延迟重启策略: 程序出现异常的时候,重启2次,每次延迟3秒钟重启,超过2次,程序退出
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(2, 3000));
//TODO 1.source
DataStreamSource<String> ds = env.addSource(new MyKafkaSource()).setParallelism(1);
//TODO 2.transformation
//TODO 3.sink
ds.print();
//TODO 4.execute
env.execute();
}
//使用OperatorState中的ListState模拟KafkaSource进行offset维护
public static class MyKafkaSource extends RichParallelSourceFunction<String> implements CheckpointedFunction {
private boolean flag = true;
//-1.声明ListState
private ListState<Long> offsetState = null; //用来存放offset
private Long offset = 0L;//用来存放offset的值
//-2.初始化/创建ListState
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Long> stateDescriptor = new ListStateDescriptor<>("offsetState", Long.class);
offsetState = context.getOperatorStateStore().getListState(stateDescriptor);
}
//-3.使用state
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (flag){
Iterator<Long> iterator = offsetState.get().iterator();
if(iterator.hasNext()){
offset = iterator.next();
}
offset += 1;
int subTaskId = getRuntimeContext().getIndexOfThisSubtask();
ctx.collect("subTaskId:"+ subTaskId + ",当前的offset值为:"+offset);
Thread.sleep(1000);
//模拟异常
if(offset % 5 == 0){
throw new Exception("bug出现了.....");
}
}
}
//-4.state持久化
//该方法会定时执行将state状态从内存存入Checkpoint磁盘目录中
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
offsetState.clear();//清理内容数据并存入Checkpoint磁盘目录中
offsetState.add(offset);
}
@Override
public void cancel() {
flag = false;
}
}
}
以上是关于Flink1.12-四大基石详解的主要内容,如果未能解决你的问题,请参考以下文章